Wikidata 本地部署
Github:https://github.com/NP-NET-research/wdel 欢迎来 star && fork && issue ~~
有问题可以通过邮箱:xuzhengfei-email@qq.com 联系我~~
文章目录
- Wikidata 本地部署
- 1、Wikidata 简介
- 1.1 Wikidata 数据结构
- 1.2 Wikidata数据转储
- 2. SPARQL引擎
- 2.1 Qlever
- 2.2 qlever-control
- 3. Wikidata导入QLever
- 4. Wikidata SPARQL查询
1、Wikidata 简介
Wikidata(维基数据)是一个由维基媒体基金会支持的开放内容项目,旨在创建一个免费、开放、协作的多语言知识图谱。它于2012年推出,并成为维基媒体项目的一部分。Wikidata的目标是收集、组织和连接全球范围内的结构化数据,使其能够在维基百科和其他维基媒体项目以及其他应用程序中使用。
1.1 Wikidata 数据结构

Wikidata的数据结构是基于实体-属性-值(Entity-Property-Value)的三元组模型。下面是一些关键的概念:
- 实体(Entity):实体代表现实世界中的一个独特事物,如人物、地点、概念等。每个实体都有一个唯一的标识符,称为QID(如Q42)。实体可以关联各种属性和值。
- 属性(Property):属性定义了实体和其值之间的关系。它描述了实体的某个方面或特征。每个属性都有一个唯一的标识符,称为PID(如P31表示“实例/类别”)。属性可以有不同的数据类型,包括字符串、数字、日期等。
- 值(Value):值是与实体的属性相关联的信息。这些值可以是简单的数据类型(如字符串或数字),也可以是其他实体的引用。例如,一个人物实体的出生日期属性的值可以是一个日期。
- 语句(Statement):语句是描述实体、属性和值之间关系的基本单位。每个语句由实体、属性和值组成,形成一个三元组。语句还可以包含其他信息,如参考文献、来源等。
- 引用(Reference): 引用提供了关于语句数据来源的额外信息。它包括引用的来源、时间戳等详细信息,有助于确保数据的可靠性和透明度。
- 限定修饰符(Qualifier):限定修饰符是用于修改语句的额外信息。它们提供了对语句中特定值的进一步描述,例如,为出生日期提供精确到天的信息。
- 数据类型: Wikidata支持不同的数据类型,包括字符串、数量、日期、坐标等。这些数据类型有助于确保数据的一致性和可查询性。
Wikidata在RDF格式中表示语句(Statement)有两种形式:truthy(真实的)语句和full(完整的)语句。
-
Truthy Statements(真实的语句):
- Truthy语句表示具有给定属性的最佳非弃用级别的语句。如果存在属性P2的首选语句,那么只有P2的首选语句将被视为真实的。否则,所有P2的正常级别语句都被视为真实的。
- Truthy语句的谓词(predicate)使用前缀
wdt:,后接属性名称(例如,wdt:P2)。对象是语句的简单值,忽略限定修饰符(qualifiers)。 - 如果值具有简单值规范化(目前仅适用于外部ID),则规范化值将在
wdtn:前缀下列出,例如,wdtn:P2。
-
Full Statements(完整的语句):
- Full语句表示系统中关于语句的所有数据。Full语句被表示为单独的节点,使用前缀
wds:和语句的ID(例如,wds:Q3-4cc1f2d1-490e-c9c7-4560-46c3cce05bb7)。语句ID的格式和含义没有保证。 - 语句与实体的关联使用带有前缀
p:和属性名称的谓词(例如,p:P2)。
- Full语句表示系统中关于语句的所有数据。Full语句被表示为单独的节点,使用前缀
在这两种形式中,Truthy语句更关注于表示具有最佳级别的、非弃用的语句,而Full语句则提供了有关语句在系统中的所有数据的更全面的信息。这些语句的表示方式和使用的前缀有助于在RDF格式中区分它们。
1.2 Wikidata数据转储
Wikidata的数据可以通过不同的方式进行转储(dump),使其以文件形式可供下载和使用。这些数据转储是以某个特定的时间点创建的快照,通常以定期发布的形式提供。以下是一些常见的Wikidata数据转储:
-
JSON格式转储: Wikidata提供了以JSON格式存储的数据转储,其中包含所有实体、属性和语句的信息。这是一个结构化的文本格式,易于解析和处理。你可以从Wikidata的数据转储页面下载这些文件。
-
RDF格式转储: Wikidata数据也以RDF(Resource Description Framework)格式进行转储,符合W3C的标准。这些转储文件包括truthy和full语句,以及其他与语句相关的详细信息。你可以在Wikidata的数据转储页面找到RDF格式的转储文件。
-
SQL格式转储: Wikidata还提供了以SQL格式存储的转储文件,使用的是MySQL数据库格式。这允许用户将Wikidata的数据导入到本地MySQL数据库中。相关的文件可以在Wikidata的数据转储页面找到。
-
其他格式: Wikidata还提供了其他格式的转储文件,例如Turtle格式等。这些不同的格式允许用户选择适合其需求和技术栈的数据文件。
本文主要使用 RDF格式的三元组转储,文件后缀为.nt,例如latest-truthy.nt.bz2 表示只包含Truthy语句信息的所有实体数据。
2. SPARQL引擎
2.1 Qlever
QLever 是一个开源的 SPARQL 引擎,可以在单个标准 PC 或服务器上高效地索引和查询包含超过 1000 亿个三元组的超大型知识图。特别是,对于涉及大量中间或最终结果的查询,QLever 速度很快,而这对于 Blazegraph 或 Virtuoso 等引擎来说是出了名的困难。QLever 还支持搜索与知识库相关的文本以及 SPARQL 自动补全。QLever 项目地址:https://github.com/ad-freiburg/qlever
QLever相比与其他图数据库,能够快速地构建索引。再次之前我们尝试使用 Apache Jena fuseki 导入到 jena 数据引擎,数据导入持续了7天,且随着导入数据的增多,导入速度持续衰减,最终衰减到预计半年才能导入。2022年ISWC论文 Getting and hosting your own copy of Wikidata也报告了这一现象。相反地QLever只需要约17h就能构建好Wikidata的索引,完成数据导入。
2.2 qlever-control
QLever 官方提供了一个工具用以方便地配置和使用QLever。建议使用 Docker运行QLever ,这样将不必下载任何 QLever 代码(Docker 将拉取所需的映像)同时能够避免本地编译QLever 和复杂的编译环境配置。
pip install qlever
3. Wikidata导入QLever
使用Qlever将Wikidata数据的三元组数据导入到本地数据库,并进行查询。QLever的使用方法可以参考qlever-control的文档qlever-control,通过Qleverfile实现对Wikidata数据的导入和配置,本项目使用的Qleverfile如下,需要将Qleverfile文件放在对应数据目录下:
# Qleverfile for Wikidata, use with https://github.com/ad-freiburg/qlever-control
#
# qlever get-data downloads two .bz2 files of total size ~40 GB
# qlever index takes ~17 hours and ~40 GB RAM
# qlever start starts the server (takes around 30 seconds)[data]
NAME = wikidata
GET_DATA_URL = https://dumps.wikimedia.org/wikidatawiki/entities
GET_DATA_CMD = curl -LO -C - ${GET_DATA_URL}/latest-truthy.nt.bz2 ${GET_DATA_URL}/latest-lexemes.nt.bz2
INDEX_DESCRIPTION = "Full Wikidata dump from ${GET_DATA_URL} (latest-truthy.nt.bz2 and latest-lexemes.nt.bz2)"[index]
FILE_NAMES = wikidata-20231222-lexemes.nt.bz2 wikidata-20231222-truthy.nt.bz2
CAT_FILES = bzcat ${FILE_NAMES}
SETTINGS_JSON = { "languages-internal": ["en"], "prefixes-external": [ "<http://www.wikidata.org/entity/statement", "<http://www.wikidata.org/value", "<http://www.wikidata.org/reference" ], "locale": { "language": "en", "country": "US", "ignore-punctuation": true }, "ascii-prefixes-only": false, "num-triples-per-batch": 10000000 }
WITH_TEXT_INDEX = false
STXXL_MEMORY = 10g[server]
PORT = 7001
ACCESS_TOKEN = ${data:NAME}_832649627
MEMORY_FOR_QUERIES = 100G
CACHE_MAX_SIZE = 100G[docker]
USE_DOCKER = true
IMAGE = adfreiburg/qlever[ui]
PORT = 7000
CONFIG = wikidata
其中需要下载最新的Wikidata dump: latest-truthy.nt.bz2 和 latest-lexemes.nt.bz2,转储格式为三元组。2023年12月的Wikidata转储中包含约14.78B个三元组,导入Qlever(构建索引)大约需要17h,占用硬盘空间约400GB。
Qlever 运行方法:
# cd 到目标目录
cd target_folder
# 创建并保存Qleverfile
touch Qleverfile
# 下载数据, 也可以使用 python src/wikidata_process/qlever-control/qlever get-data
wget https://dumps.wikimedia.org/wikidatawiki/entities/latest-truthy.nt.bz2
wget https://dumps.wikimedia.org/wikidatawiki/entities/latest-lexemes.nt.bz2
# (非必需)重命名文件,与Qleverfile中文件名称一致即可
mv latest-truthy.nt.bz2 wikidata-20231222-truthy.nt.bz2
mv latest-lexemes.nt.bz2 wikidata-20231222-lexemes.nt.bz2
# 数据导入qlever
qlever index
# 启动qlever
qlever restart
# 启动SPARQL Web页面
qlever ui
4. Wikidata SPARQL查询
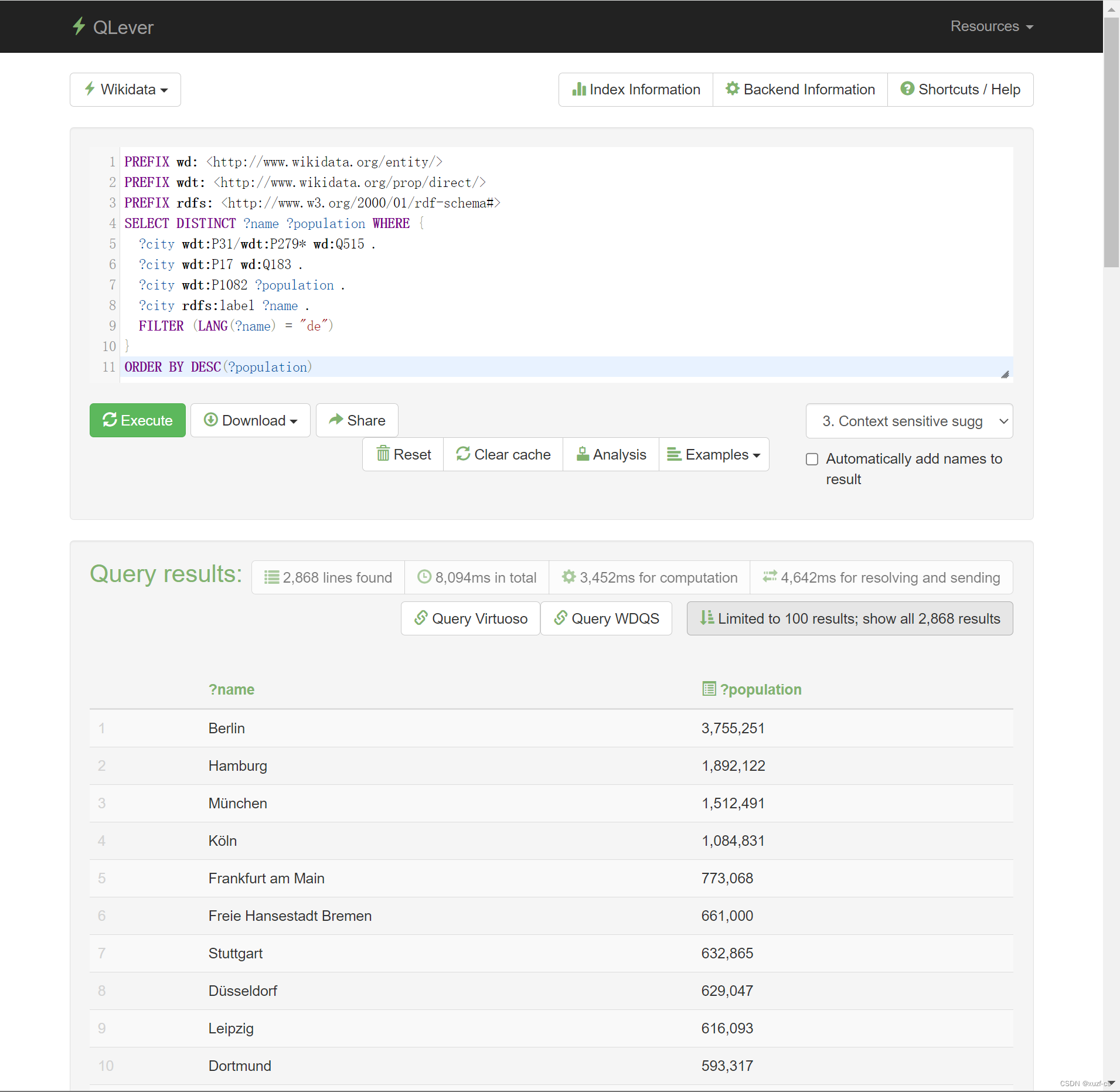
通过命令行进行Wikidata数据查询,命令模板如下,返回tsv格式文件:
curl -s http://127.0.0.1:7001 -H "Accept: text/tab-separated-values" \-H "Content-type: application/sparql-query" \--data "$sparql_query_command_line" > "$save_fpath.tsv"
eg. 查询德国各个城市的名称和人口
PREFIX wd: <http://www.wikidata.org/entity/>
PREFIX wdt: <http://www.wikidata.org/prop/direct/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT DISTINCT ?name ?population WHERE {?city wdt:P31/wdt:P279* wd:Q515 .?city wdt:P17 wd:Q183 .?city wdt:P1082 ?population .?city rdfs:label ?name .FILTER (LANG(?name) = "de")
}
ORDER BY DESC(?population)
Web页面查询:
参考文献:
- Wikibase/Indexing/RDF Dump Format
- Getting and hosting your own copy of Wikidata
- wikidata dump
- https://github.com/ad-freiburg/qlever