系列文章目录
速通C语言系列
速通C语言第一站 一篇博客带你初识C语言 http://t.csdn.cn/N57xl
速通C语言第二站 一篇博客带你搞定分支循环 http://t.csdn.cn/Uwn7W
速通C语言第三站 一篇博客带你搞定函数 http://t.csdn.cn/bfrUM
速通C语言第四站 一篇博客带你学会数组 http://t.csdn.cn/Ol3lz
速通C语言第五站 一篇博客带你详解操作符 http://t.csdn.cn/OOUBr
速通C语言第六站 一篇博客带你掌握指针初阶 http://t.csdn.cn/7ykR0
速通C语言第七站 一篇博客带你掌握数据的存储 http://t.csdn.cn/qkerU
速通C语言第八站 一篇博客带你掌握指针进阶 http://t.csdn.cn/m95FK
速通C语言第八.五站 指针进阶题目练习 http://t.csdn.cn/wWC2x
速通C语言第九站 字符相关函数及内存函数 http://t.csdn.cn/YyBBM
速通C语言第十站 自定义类型 http://t.csdn.cn/jsGJ7
速通C语言第十一站 动态内存开辟 http://t.csdnimg.cn/necjp速通C语言第十二站 文件操作 http://t.csdnimg.cn/PSxs3
感谢佬们支持!
文章目录
- 系列文章目录
- 前言
- 一、程序的翻译环境和执行环境
- 二、详解C语言的编译+链接
- 1 编译环境
- 2 运行环境
- 三、预处理详解
- 1 预处理符号
- 2 #define定义符号
- 3 #define定义宏
- 宏的声明方式
- #define替换规则
- #和##
- 带副作用的宏参数
- 宏和函数的对比
- 4 命令约定
- 5 命令行参数
- 6 条件编译
- 单分支
- 多个分支
- 判断是否被定义
- 嵌套指令
- 7 文件包含
- 嵌套文件包含
- 8 其他预处理指令
- 总结
前言
上篇博客带大家看了文件的相关操作,这篇博客将是速通C语言的最后一篇,预处理,相比之前几篇来看这节有些太底层,可能对C语言初学者有些晦涩,大家有个印象即可(但这并不意味着不重要),通过之后的学习中再来看就会轻松很多啦
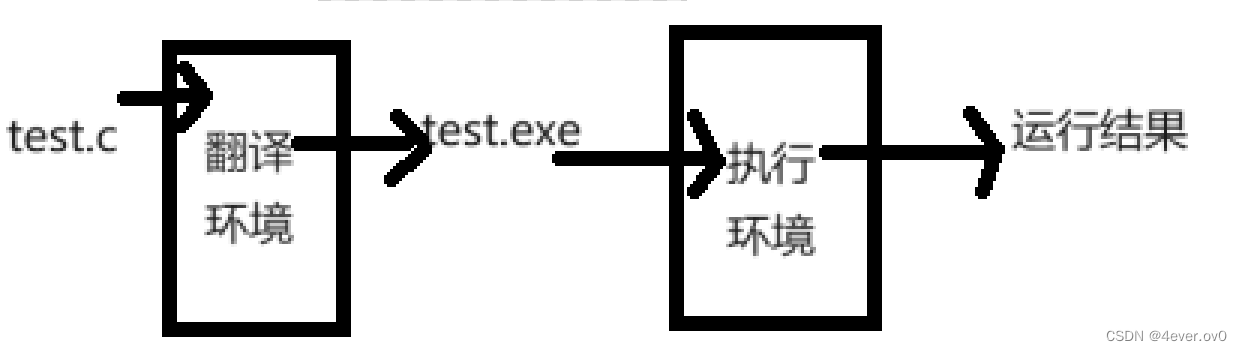
一、程序的翻译环境和执行环境
在ANSIC(C语言国际标准)的任何实现中,我们写的代码会通过两个环境
翻译环境 :用于将我们写的代码转换成计算机能识别的可执行的机器指令(二进制序列)
执行环境:用于执行代码
画个简易的图来看是这样的
二、详解C语言的编译+链接
翻译环境分为两个步骤,编译+链接
我们写的.c文件都会单独的经过编译器,得到各自的目标文件(windows下为.obj结尾的文件,Linux下为.o结尾,目标文件有其特定的格式,叫elf格式)
然后链接器会链接一些链接库(比如我们用的库函数所在的库),在和这些目标文件链接生成了.exe的可执行文件(它的格式也是elf格式)。
举个例子,我们建立一个test.c和add.c
写一点代码以后ctrl+F5可以发现,生成了.exe的文件

查看一下代码所在路径,会发现两个.obj的目标文件

编译环境
其中编译又可以分为三步
1 预编译(预处理)
预处理很简单,主要做4个事:删注释;#define定义的宏替换;头文件展开;条件编译
通过这步,我们的.c文件会变为.i文件
2 编译
众所周知,我们的C语言代码得底层是汇编代码,而这一步将通过语法分析,词法分析,
语义汇总,符号汇总等操作将我们的代码转变为汇编代码
通过这步,我们在上一阶段得到的.i文件会变为.s文件
3 汇编
这一步将我们上面得到的汇编代码转变为二进制序列,并生成符号表
通过这步,我们最终得到了那个.o文件
希望这么多复杂的概念没有吓到你,
我们写一波代码看一下,为了方便查看中间文件,我们使用gcc编译器,并使用命令行操作
#include<stdio.h>#define m 5//只是一行注释struct S
{char c;int a;
};int main()
{struct S s;int max=m;printf("%d\n",max);return 0;
}第一步预处理,我们用-E选项
gcc -E test.c -o test.i打开test.i文件,发现它很长
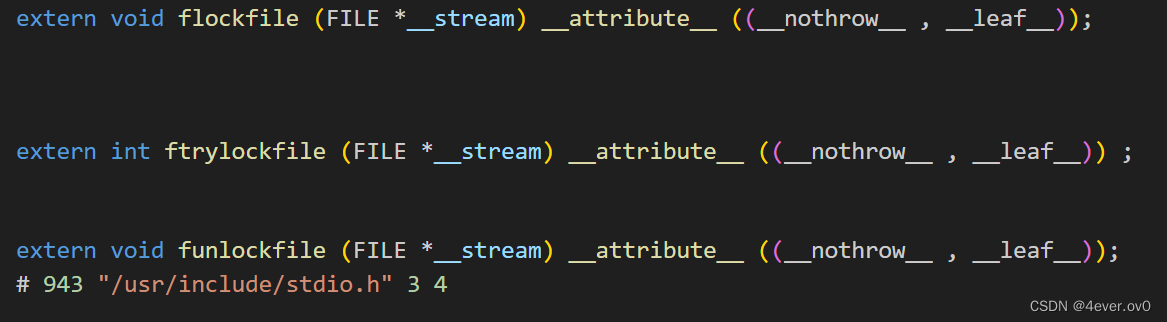
(这里截取部分),虽然我们别的看不懂,但是我们认识extern void 函数名
(f lockfile,f trylockfile,f unlockfile我们可知是对文件的加锁,尝试加锁及解锁,很多锁诸如互斥锁,读写锁自旋锁等一般都提供lock、trylock、unlock三个函数;听不懂就当我没说哈),
所以这个是函数的声明,所以实际上这一大段是我们展开的头文件stdio.h
然后在最下面,我们找到了我们写的代码
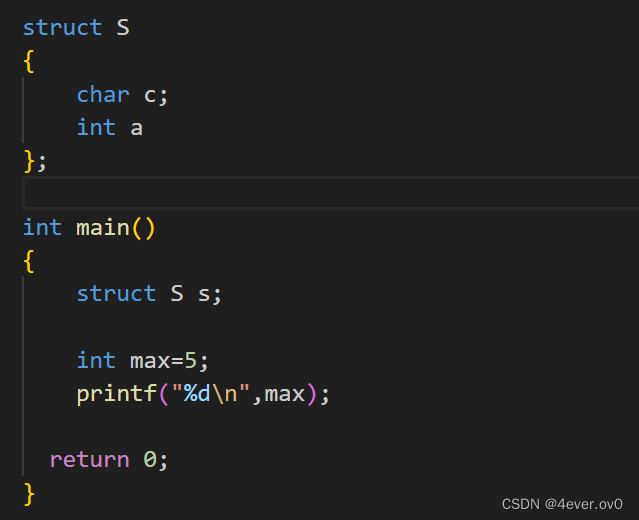
仔细看,我们定义的宏m背替换成了5,而且我们刚刚写的注释也被删掉了
下来要进行编译,用-S选项
gcc -S test.i -o test.s此时查看这个test.s,发现里面真的是汇编
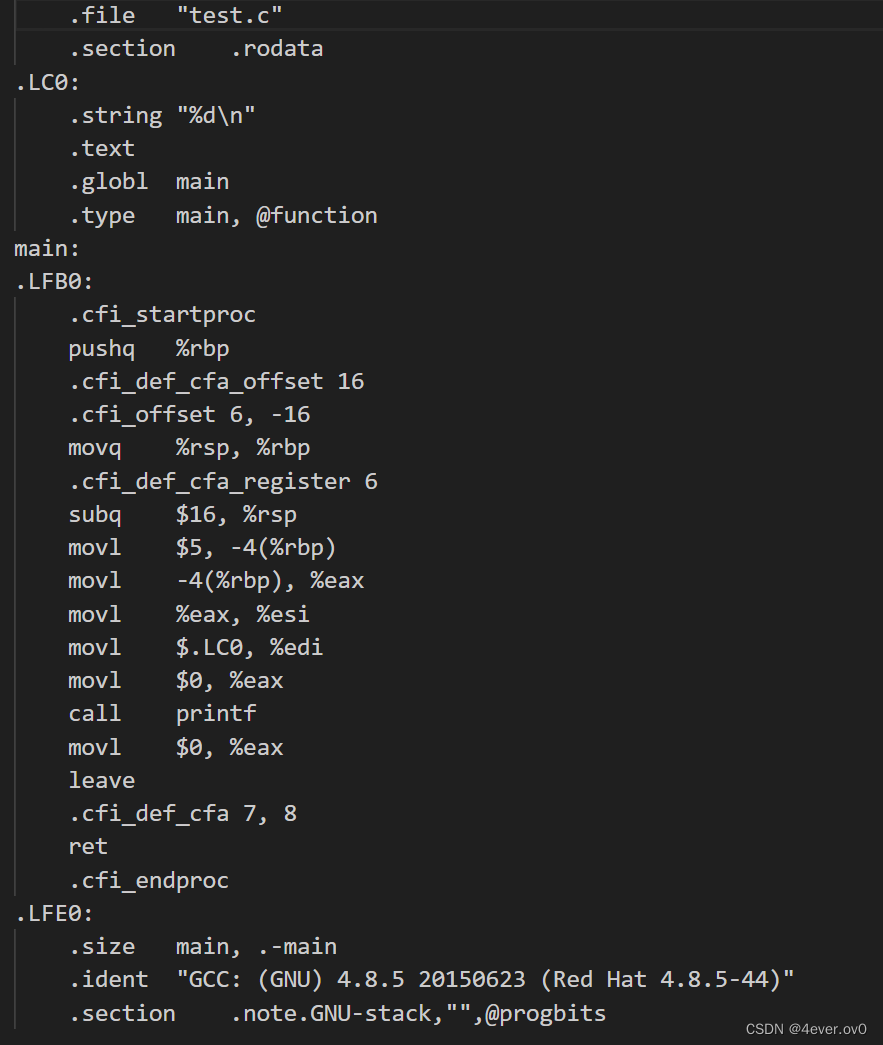
此时在简单来看看那4个操作(大家有兴趣的话可以看一看一本书叫《编译原理》或者
《程序员的自我修养》)
语法分析是看你有没有语法错误
词法分析是将代码拆成一个个符号的
语义分析是比如看你写的是分支还是循环等等
符号汇总是把全局看到的符号,函数名做一下汇总,将在下一个步骤中起作用
最后一步要用-c选项
gcc -c test.s test.o由于得到的是二进制相关的内容,我们看不懂
其中,他做了一个事情叫生成符号表,这个事情是和上一阶段的符号汇总有联系的
为了演示何为符号表,我们换个代码,生成其目标文件
#include<stdio.h>int g_val=2024;int add(int x,int y)
{return x+y;
}int main()
{int x=0;int y=10;int ret=add(x,y);return 0;
}
我们想看懂elf格式的目标文件,可以用readelf工具,带上选项-s,就可以显示符号表啦
readelf -s test.o其中,我们的全局变量和函数都在符号表中
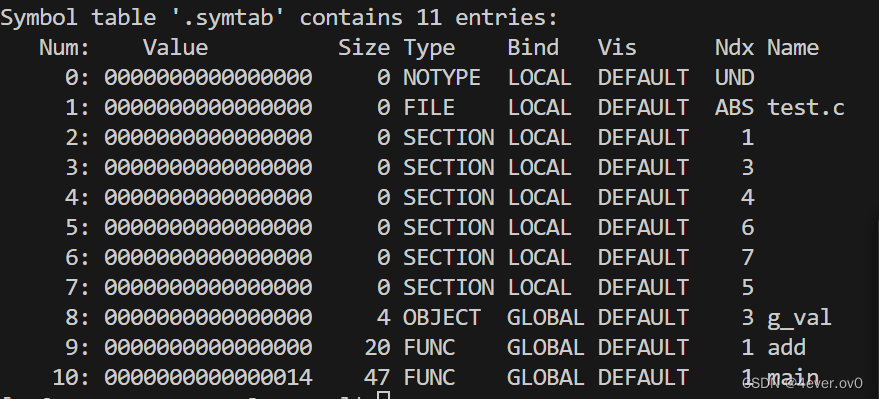
所以,符号汇总就是把我们代码中的函数,全局变量进行汇总
形成符号表就是用其地址和名字形成一个表格,比如下面我画的这个
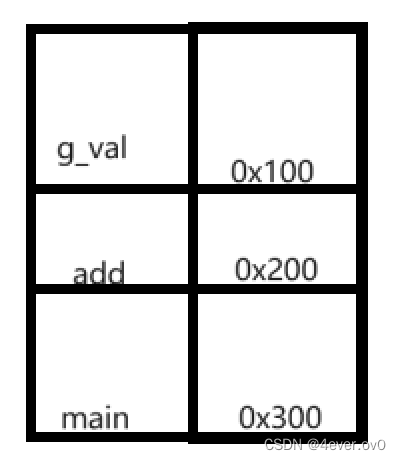 (此时3个符号都是有效地址。就是说我们能通过地址找到这个符号)
(此时3个符号都是有效地址。就是说我们能通过地址找到这个符号)
我们再给一波例子
这次我们给两个文件
add.c
int add(int x,int y)
{return x+y;
}test.c
//声明外部符号
extern int add(int x,int y);int main()
{int x=0;int y=10;int ret=add(x,y);return 0;
}
由于每个源文件都会单独得到一个目标文件,所以这次我们有两个目标文件
add.o的符号表
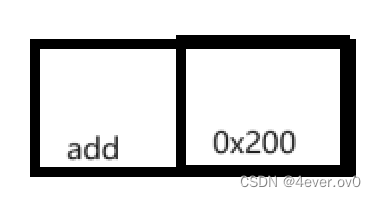
test.c的符号表
这个时候就不一样了,由于add函数在test.c只有一个声明,所以它的地址在哪,我不到啊
所以只能给一个无效地址0x000

然后链接阶段会做两个事
1是合并段表
刚才我们说到生成的目标文件是elf格式,所谓elf格式就是文件分为好几段
然后我们的可执行程序.exe也是elf格式,合并段表就是将目标文件中相同的段合并到一起
(常见的段有哪些请参考《程序员的自我修养》第451页)
2是符号表的合并和符号表的重定位
这个时候就用用到我们上面的第二个例子了,两个目标文件都有add的地址,用哪个?
当然是保留有效地址,所以最终的符号表是这样的
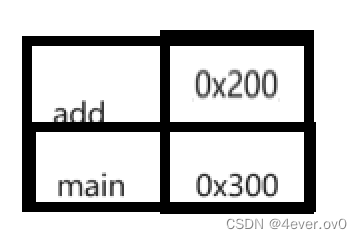 (最终就可以找到add函数的地址了)
(最终就可以找到add函数的地址了)
另外,如果我们删掉add.c中的内容,运行起来就找不到add函数了,就会报所谓链接错误

运行环境
其中,程序的执行分为4步
1 将程序加载至内存中(本质应该是加载至内存的代码段),再操作系统的环境中,这个事情由操作系统做。在独立的环境中,程序的下载必须手工安排。比如单片机
2 程序的执行便开始,接着调用main函数
3 开始执行程序代码,这个时候程序将使用一个运行时堆栈(每一次函数调用时,都会开辟一块空间,也叫建立函数栈帧),存储函数的局部变量和返回地址,程序内部也可以使用静态内存,存储静态内存的变量在整个运行过程中一直保留他们的值
这里举个例子画个图给大家具体看一下函数栈帧
#include<stdio.h>int add(int x, int y)
{return x + y;
}int main()
{int a = 10;int b = 20;int ret = add(10, 20);return 0;
}首先,函数所在的栈区具有栈的特性,即FILO(先进后出),main函数比add函数先定义,所以
main函数的地址在下面,a先定义,先入栈,b后定义,b再入栈
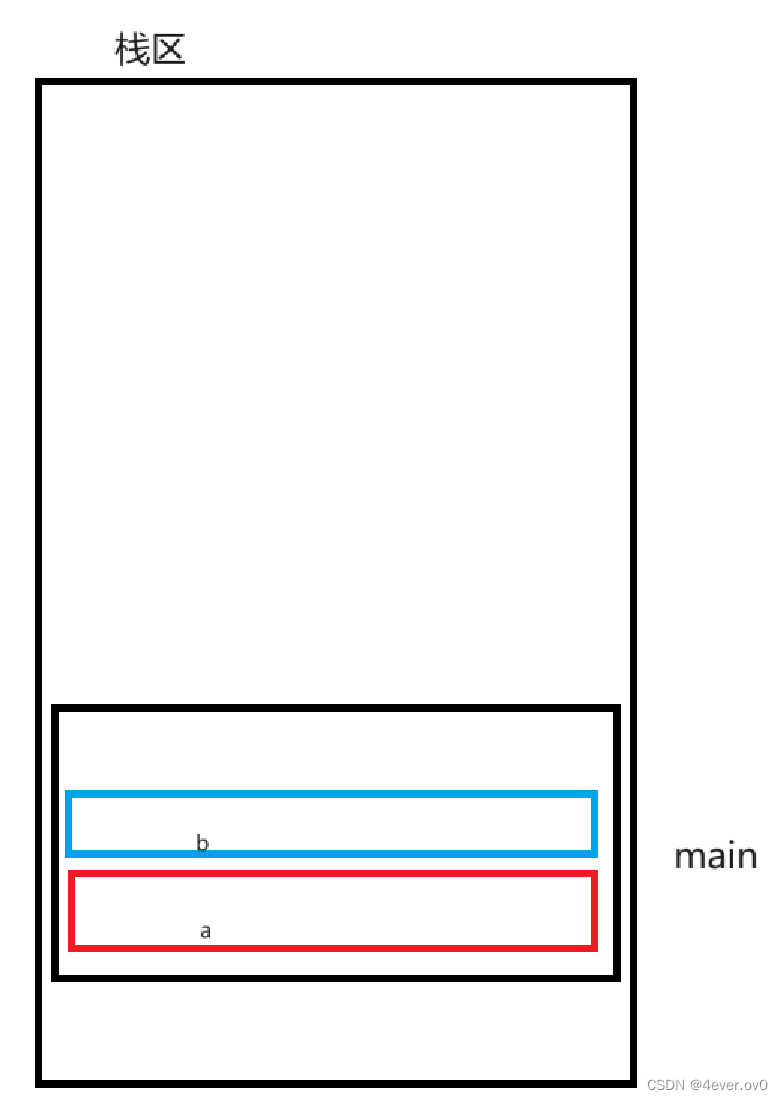
下来在定义ret那行调用了add函数,所以建立add的栈帧,并进行传参
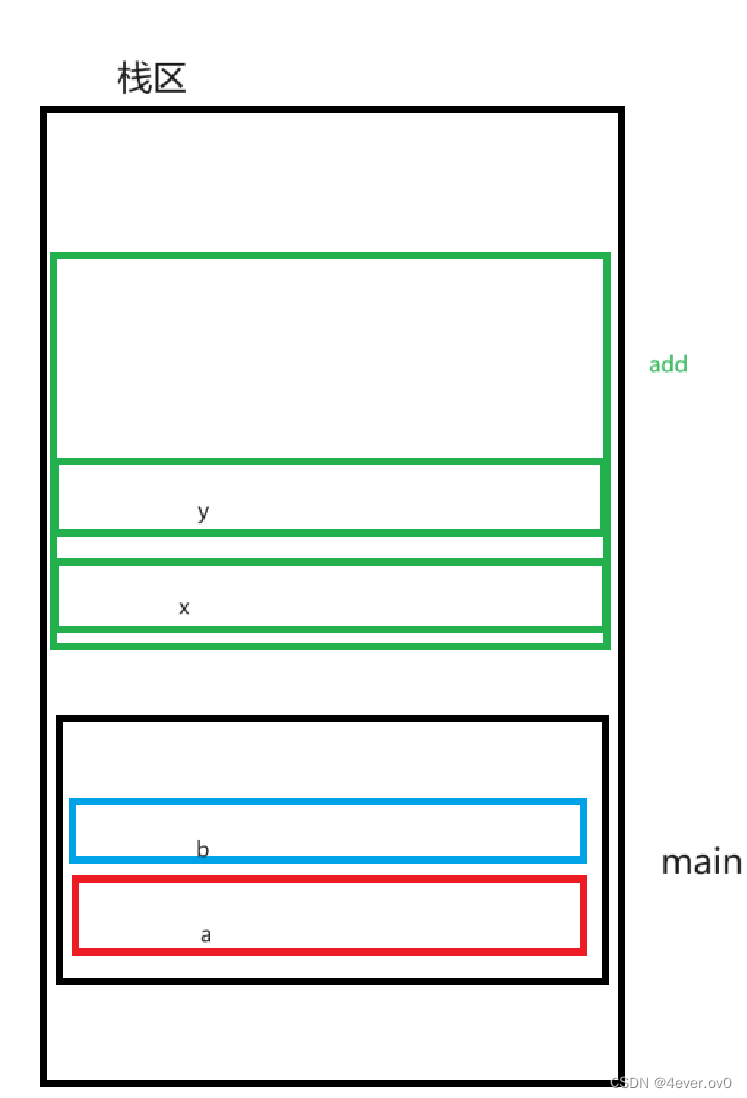
当add函数返回时,为他开辟的栈帧就被回收,
最后main函数执行完时,main的空间也回收了。
4 终止程序,main函数可能正常终止,也可能异常终止(比如程序有错误或收到某些信号等,暂时先不用关心)
三、预处理详解
1 预处理符号
指 预处理阶段就被处理的 已经定义好的这种符号(底层是#define),可以直接用
这些东西在日志中还是非常常用的
| __FILE__ | 进行编译的源文件(绝对路径) |
| __LINE__ | 当前所在行号 |
| __DATE__ | 日期 |
| __TIME__ | 时间 |
| __FUNCTION__ | 当前所在函数名 |
| __STDC__ | 如果编译器支持ANSI C 返回1,否则表示未定义 |
我们简单的用代码演示一波
int add(int x,int y)
{
printf("%s\n", __FUNCTION__);return x+y;
}int main()
{
add(1,2);printf("当前所在行号:%d,%s\n",__LINE__,__FUNCTION__);printf("所编译的源文件;%s",__FILE__);printf("时间:%s 日期:%s\n",__TIME__,__DATE__);//printf("%d ",__STD__);return 0;
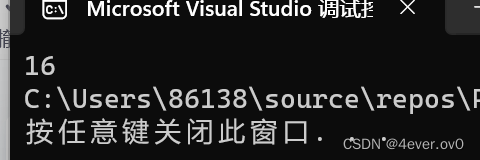
}显然,当打印__STDC__时报错为未定义的标识符

所以VS不支持ANSI C
但是gcc是支持的

2 #define定义符号
我们可以用#define定义各种东西
例:
#define m 100
//数字还可以是关键字
#define m 100
#define reg registerint main()
{reg int num=m;
return 0;
}还可以是一段代码
#define do_forever for(;;)int main()
{//reg int num=m;do_forever;return 0;
}还有更离谱的
#define CASE break; case
//相当于在写case语句的时候自动带上breakint main()
{int n=0;switch(n){CASE 1:CASE 2:CASE 3:}
}如果要定义的东西过长,我们可以拆成几行写,除了最后这一行外,每行的后面加一个"\"
称为续行符
例:
#define DEBUG_PRINT printf("file:%s\tline:%d\t\date:%s\ttime:%s\n",\__FILE__,__LINE__,__DATE__,__TIME__)
现在有这么个问题,#define 的东西能不能加分号?
#define m 100;int main()
{int a=m;return 0;
}能是肯定能,因为他底层是替换
显然在替换之后变成了
int a=100;;但是我们不建议,因为有可能会出错,毕竟你多了一个分号
3 #define定义宏
#define机制包括了一个规定,允许讲参数定义至文本中,这种方式通常称为宏/定义宏
宏的声明方式
# define name(参数列表) 内容注意这波name必须和参数列表的左括号紧挨,不能有空格
例:
#define SQUARE(X) X*Xvoid test5()
{printf("%d ", SQUARE(3));
}
啊但是
void test5()
{printf("%d ", SQUARE(3+1));
}如果是这样将打印什么呢?会是16吗?

由于宏是直接替换,所以3+1并不会先计算再传参,而是先传参再计算
传上去就变成了 3+1*3+1,结果显然是7,因为乘法优先级高于加法,这显然不合预期
我们加两个括号
#define SQUARE(X) (X)*(X)
总结:由于恶心的优先级问题,我们在定义宏时往往要加很多括号
#define替换规则
1 在调用宏时,首先对参数进行检查,看看是否包含任何#define定义的符号,如果是,他们首先被替换
2 替换文本随后被插入程序原来文本中的位置。对于宏,参数名被他们的值所替换
3 最后,再次对结果文件进行扫描,看看他是否包含由#define定义的符号,如果是,就重复上述过程
例
#define MAX(X,Y) ((X)>(Y)?(X):(Y))
#define M 100int main()
{int max = MAX(101, M);return 0;
}在这个例子中,M首先被替换成100,然后MAX被替换成我们定义的宏
注意:
1 宏参数和#define定义中可以其他#define定义的常量,但是对于宏,不能递归
就比如在上面的例子中,M就时MAX的参数。
2 当预处理器搜索#define定义符号的时候,字符串常量的内容并不能被搜索
例:
#define M 100int main()
{printf("M=%d\n", M);return 0;
}在这个例子中,printf的第一个参数是const char*也就是字符串类型,所以其中的M并不会被识别到,而后面的M会被识别到
#和##
#和##可以把参数插入字符串中
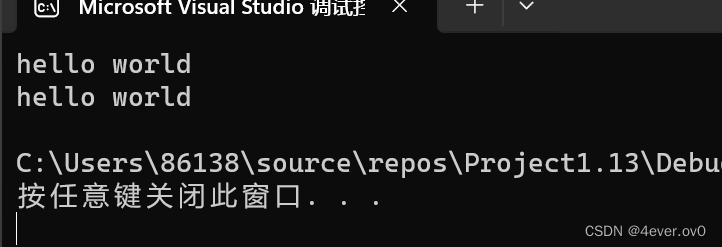
先补充一点
printf("hello world\n");printf("hello " "world\n");相比第一行,第二行有两个字符串,但是这两个字符串会连接到一起
再例:
int a=10;
//希望打印the value of a is 10
int b=20;
//希望打印the value of b is 20
int c=30;
//希望打印the value of c is 30
这三个的功能是很类似的,所以写三个printf就太冗余了
但是用函数又是不好解决的
我们传参要传a,b,c的值,但是我们不好传字符
所以我们可以试试宏
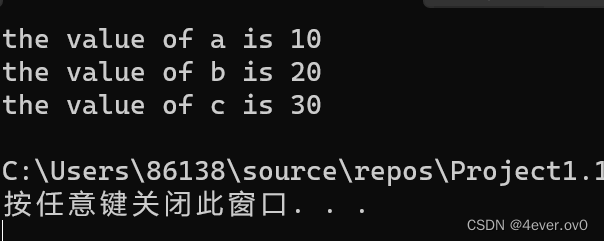
#define PRINT(X)printf("the value of "X" is "%d",X);int main()
{int a = 10;PRINT(a);int b = 20;PRINT(b);int c = 30;PRINT(c);return 0;
}但是这么写直接报错了

此时我们需要用到#
#define PRINT(X)printf("the value of "#X" is %d\n",X);
此时#的作用不是替换,#X会变成这个参数名a对应的字符串,达到了把参数插入字符串的效果。
##用于把两个符号连成一个符号
但是这样的连接必须产生一个合法的标识符,否则其结果就是未定义的
例:
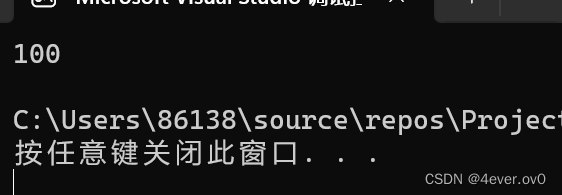
#define CAT(X,Y) X##Y
int main()
{int YiGang101 = 100;printf("%d\n", CAT(YiGang, 101));return 0;
}
带副作用的宏参数
例:
int a = 1;int b = a + 1;//b=2,a=1int b = ++a;//b=2,a=2显然,++a是有副作用的,因为它不仅改了a,还改了b,
如果像++a这样的宏参数在宏的定义中出现了不止一次,那么在你使用这个宏的时候
就会有危险
例:
#define MAX(X,Y) ((X)>(Y)?(X):(Y))int main()
{int a = 5;int b = 8;int m = MAX(a++, b++);//printf("%d %d", a, b);
}如果我们不进行打印,通过调试判断,我们会发现a=6,b=9
经过替换后变成了这样
int m = ((a++) > (b++) ? (a++) : (b++));
由于a=5,b=8,5<8,所以返回b++(此时的b++是后置,所以不执行),此时已经算判断过一次了,所以a=6,b=9
如果这时我们再打印a,b,b++就会执行
printf("%d %d", a, b);
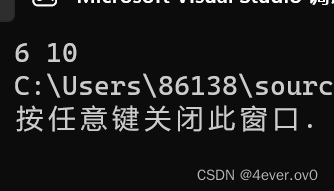
宏和函数的对比
宏通常用于执行比较简单的逻辑,比如求两个数的最大值
#define MAX(X,Y) ((X)>(Y)?(X):(Y))
如果用函数来搞,是这样的
int compare(int x, int y)
{return x > y ? x : y;
}同样的逻辑为什么用宏而不用函数?
从底层来看,宏转汇编后长度远小于函数,所以宏更快,而且函数还有压栈的开销
在力扣的题解中为了追求速度很多小的函数会被定义成宏
而且宏无关类型,而函数必须是具体类型
宏还可以传类型,这是函数做不到的
例:
在使用malloc开辟空间时一般要这么用
malloc(10*sizeof(int));想要
malloc(int,10);但是不能传类型,我们可以定义一下宏
#define MALLOC(num,type) (type*)malloc(num*sizeof(type))int* p = MALLOC(10, int);但是宏也有缺点
1 每次使用宏的时候,一份宏的代码就插入到程序中
除非宏很短或使用次数很少,否则会大幅增长程序的长度
这个要和上面的区别开,这并不意味着宏很慢,而是因为宏时替换,所以每次用的宏
就会直接被替换,导致程序长度变长
2 宏没法调试
3 宏由于没有类型,所以不够严谨
4 宏可能会带来运算符优先级的问题,导致程序出错
这很好理解,我们定义宏的时候经常需要猛加括号
另外,C++的大佬针对于宏的缺点搞出了内联inline,在兼顾了宏的优点时几乎没有什么缺点
而且查阅C Primer Plus后发现C99已经引进了内联
再另外,C99/C11为宏提供了类似printf中的可变参数,使宏参数支持可变宏参数,
还有C11提供的泛型选择关键字_Generic和宏结合起来也是确实听不错的
大家有兴趣可以自己下来看一看,速通C语言系列先不做过多介绍
4 命令约定
一般来讲函数和宏的使用语法相似,所以语言本身没法区别
,平时的使用习惯为
宏名全部大写,但是函数不全部大写
5 命令行参数
许多C的编译器提供了一种能力,允许在命令行中定义符号,用于启动编译过程
需使用gcc的-D选项
我们在gcc上演示一波
#include<stdio.h>int main()
{int arr[m]={0};for(int i=0;i<m;i++){arr[i]=i;}for(int j=0;j<m;++j){printf("%d ",arr[j]);}return 0;
}正常编译肯定是会报错的

但是如果我们用一下-D选项
gcc test.c -o test -D m=10 -std=c99 
(成功运行)
6 条件编译
在编译的时候我们如果是否编译/放弃一条语句是很方便的,因为我们有条件编译。
简而言之就是满足条件就编译,不满足就放弃
使用场景通常是库的实现中的版本控制和跨平台
比如说如果是这个版本,就编译这一段,如果是另外一个版本,就编译下一段
再比如说线程库对于Linux下是pthread原生线程库,但是windows下就是windows自己的线程库
C++11的线程库为了兼容两个平台,其底层就是条件编译加上调用各自的线程接口。
例:
int main()
{
#ifdef PRINTprintf("SunsetShimmer\n");
#endifreturn 0;
}由于我们没有定义PRINT,所以不会打印
#define PRINTint main()
{
#ifdef PRINTprintf("SunsetShimmer\n");
#endifreturn 0;
} (成功打印)
(成功打印)
常见的条件编译指令
单分支
#if 常量表达式#endif例:
#if 1printf("hehe");
#endif运行之后
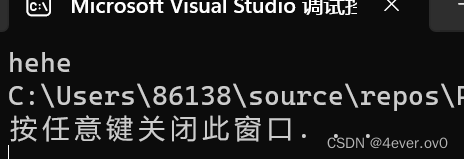
如果换成
#if 0printf("hehe");
#endif
则不能打印
由此我们得到了一种很装杯的注释一段代码的方式,只要我们将要注释的代码最前面加上
#if 0 最后加上#endif,便能完成注释的操作,也是确实挺不错的
多分支
#if 常量表达式#elif 常量表达式#else#endif简单举个例子
void test1()
{
#if 1==1printf("MoFaMaoMi");#elif 1==2printf("Nijiejiede");#elseprintf("wochihaol");#endif
}

判断是否被定义
例:
第一种是如果定义了xxx,就执行以下语句
其写法为
#ifdef TESTprintf("test\n");
#endif和
#if defined TESTprintf("test\n");
#endif还有一种是反的,如果未定义xxx,就执行以下语句
#ifndef TESTprintf("test\n");
#endif#if! defined TESTprintf("test\n");
#endif另外,我们还有一个可以移除宏定义的指令
#undef
简单写个代码
#define M 10
void test4()
{printf("%d ", M);
#undef M//printf("%d ", M);}此时能打印
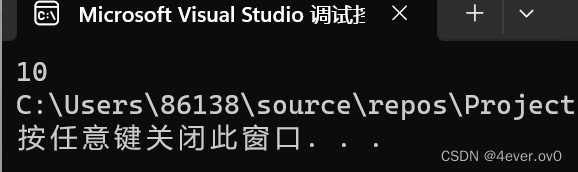
啊 但是
#define M 10
void test4()
{printf("%d ", M);
#undef Mprintf("%d ", M);}
嵌套指令
以上条件指令均可嵌套
例:这是一段简易的处理跨平台的代码
#if defined (OS_UNIX)#ifdef OPTION1unix_version_option1();#endif#ifdef OPTION2unix_version_option2();#endif#elif defined (OS_MSDOS)#ifdef OPTION2msdos_version_option2();#endif#endif7 文件包含
包含的文件具有两种
1 本地文件 #include"filename"
2 库文件 #include<filename>
其中两种不同的包含方式本质其实是查找策略的区别
<>表明直接去库的目录下找,找不到,就报错
VS下的标准头文件路径为C:\Program Files(x86) \Microsoft visual studio12.0 \ vc \include
Linux下的gcc是 /user/include
""则是先去你项目源文件所在目录查找,如果找不到,再去标准库中查找
所以按理来说,库文件是可以用""来包的,只不过他会先去项目源文件所在目录查找,再去标准库中查找,但是这样就太慢了,我们不推荐。
嵌套文件包含
嵌套文件是一种在项目中很常出现的情况
例如现在comm.h和comm.c是公共模块
现在程序员易刚写了test1.h和test1.c,其中test1.c包了头文件comm,h
同时程序员志明写了test2.h和test2.h,其中test2.c包了头文件comm,h
现在又有程序员紫瑶写了test.c,他同时包了test1.h和test2.h(如图所示)
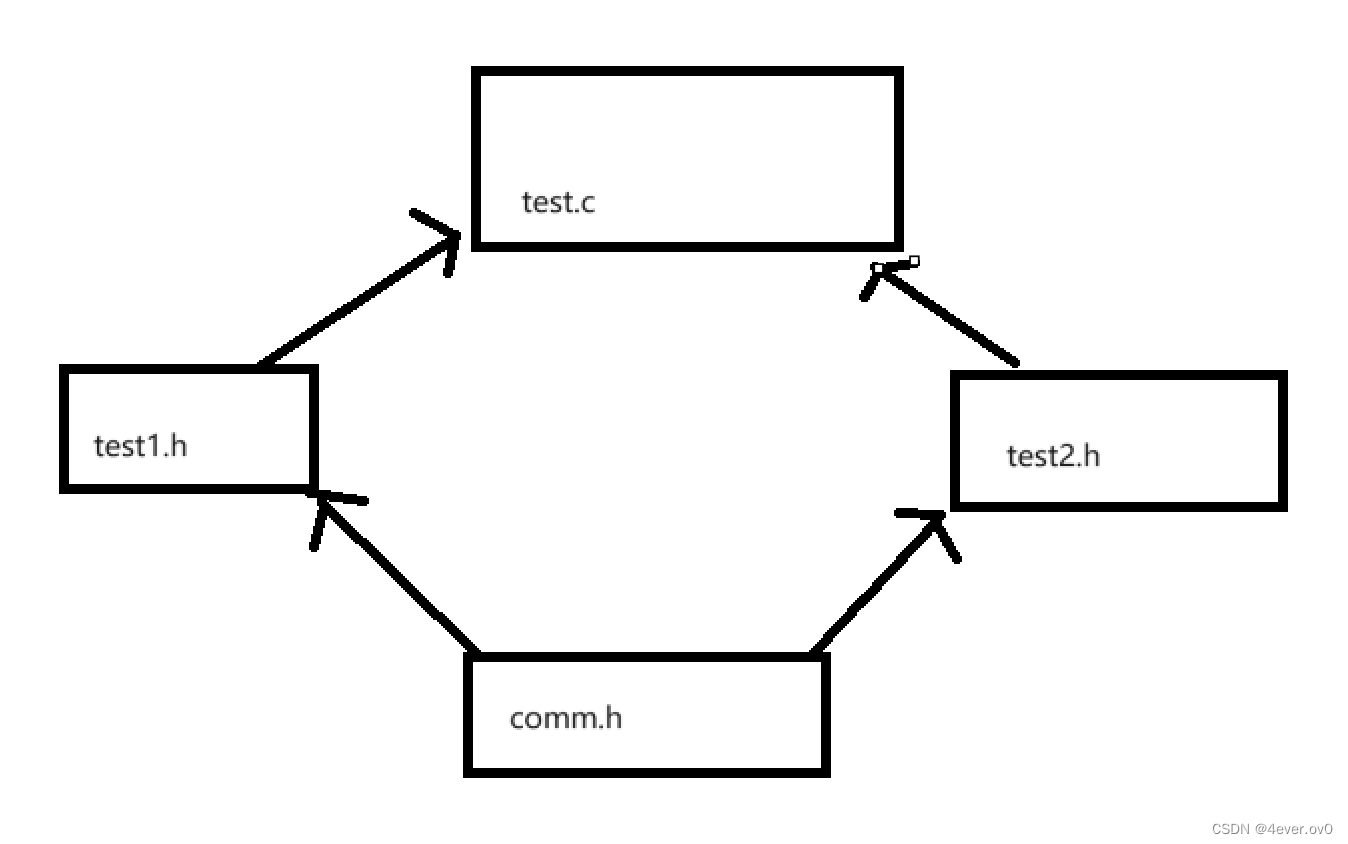
(只看图的话,很像,很像啊,经典的菱形继承,不过这里并没有所谓的数据冗余和数据二义性问题)
众所周知,我们包的头文件在预处理阶段就会展开,所以包几次头文件就会展开几次
对于很长的头文件多次展开会造成代码冗余的问题
我们有两种做法保证头文件只包一次
#pragma once还有一种较为麻烦的做法
#ifndef __TEST_H__
#define __TEST_H__……#endif // !__TEST_H显而易见,如果没包含头文件(test.h),就包含(执行下一句),如果包了,第二句就不执行
一个优秀的头文件应该有如上任意一种形式的操作
8 其他预处理指令
其他预处理指令#line #error #pragma以及别的关键字大家可以下来查查资料,没啥可讲的
速通C语言系列结束#
总结
做总结,这是速通C语言系列的最后一篇,编译链接里的陌生知识可能会劝退很多人,不过大家
不用着急,可以留到以后再看,预处理相关的东西其实还是相对比较简单的。
水平有限,还请各位大佬指正。如果觉得对你有帮助的话,还请三连关注一波。希望大家都能拿到心仪的offer哦。