槽位对齐(slot alignment)
在text2sql任务中,槽位对齐(slot alignment)通常指的是将自然语言问题中的关键信息(槽位)与数据库中的列名或API调用中的参数进行匹配的过程。这个过程中,模型需要理解问题中的词汇,并将其映射到数据库或API的相应部分。
在多模态的text2sql任务中,比如涉及到图表类型选择、API参数对齐的任务,槽位对齐可能还需要考虑如何将文本信息与图表数据、API调用所需的参数进行有效对齐。这意味着模型不仅要理解自然语言,还要能够处理和理解图表中的信息,以及如何将它们转换为正确的查询或API调用。
例如,如果用户提出了一个关于特定数据集的问题,模型需要识别出相关的槽位(如时间范围、产品类别等),然后根据这些槽位选择合适的图表类型,并确保API调用的参数与这些槽位正确对应。
OOD
在机器学习和数据科学领域,"OOD"代表"Out-of-Distribution",即分布外。分布外(Out-of-Distribution, OOD)情况指的是模型在处理那些不属于其训练数据分布的数据时所面临的问题。简单来说,就是模型遇到了它在训练过程中没有见过的新情况或数据。
在Task Classification任务中,如果考虑了OOD情况,模型就需要能够识别出那些不属于预定义分类的任务,并可能需要采取某种策略来处理这些未知或未预见的情况。例如,如果一个模型被训练来识别适合用柱状图、折线图、饼图、散点图和地图展示的五种任务类型,那么任何不适用于这五种图表类型的任务都会被视为OOD。
在实际情况中,OOD检测对于确保模型的鲁棒性和可靠性非常重要,因为它帮助模型识别并妥善处理未知或异常数据,而不是错误地分类或处理。这对于自动化系统尤其重要,因为错误地处理OOD情况可能会导致不准确的决策或意外的行为。
“TPM"问题
在数据可视化模块中,"TPM"问题通常指的是"Too Powerful Models"(过于强大的模型)问题。这个概念是指在使用大型语言模型(Large Language Models, LLMs)进行数据分析和可视化时,可能会出现的以下两个主要问题:
- 过度拟合:大型语言模型具有很高的参数量和容量,能够捕捉到数据中的复杂模式和关系。然而,这可能导致模型在训练数据上过度拟合,即模型不仅学习了数据中的真实模式,还学习到了训练数据中的噪声和特定特征。当模型应用于新的或未见过的数据时,过度拟合的模型可能无法很好地泛化,导致不准确或误导性的可视化结果。
- 缺乏可解释性:大型语言模型通常被视为"黑箱"模型,因为它们的内部决策过程和特征提取机制很难解释和理解。这导致很难解释为什么模型会生成特定的可视化结果,以及这些结果是否可靠和可信。缺乏可解释性可能会阻碍用户对模型输出结果的信任和采用。
因此,在使用大型语言模型进行数据可视化时,需要谨慎处理TPM问题,确保模型能够泛化和提供可解释的结果。这可能涉及到适当的模型正则化、验证和测试,以及开发可解释性工具和技术来解释模型的决策过程。
消融实验(Ablation Study)
消融实验(Ablation Study)是一种实验设计方法,用于评估模型或系统中各个组成部分的重要性。在消融实验中,研究者会逐步移除或“消融”模型的一部分组件或功能,然后评估这些变化对模型性能的影响。通过比较不同版本的模型性能,研究者可以确定哪些组件或功能对于模型的表现至关重要,哪些则不那么重要。
消融实验可以是通过对prompt中的问题表示进行修改,比如去掉外键信息,然后观察模型性能的变化。例如,如果原始问题包含关于数据库中表之间关系的信息(外键信息),那么在消融实验中,研究者可能会移除这些关系信息,然后评估模型在执行text2sql任务时的性能。
通过这种实验,研究者可以了解外键信息对模型性能的影响,从而得出结论,外键信息对于生成准确的SQL查询是否重要。如果去掉外键信息后模型性能显著下降,那么可以认为这些信息对于任务来说是关键因素。反之,如果性能下降不明显,则可能表明模型对其他信息更为依赖。
消融实验是理解复杂模型和系统中各个部分作用的一种有效方法,它有助于提高模型的可解释性,并指导模型改进和优化。
Z-score算法
Z-score算法,也称为标准分数(standard score)算法,是一种统计学上的方法,用于描述一个数值相对于整个数据集的平均值的位置。Z-score衡量的是原始分数和平均值之间的标准差的倍数。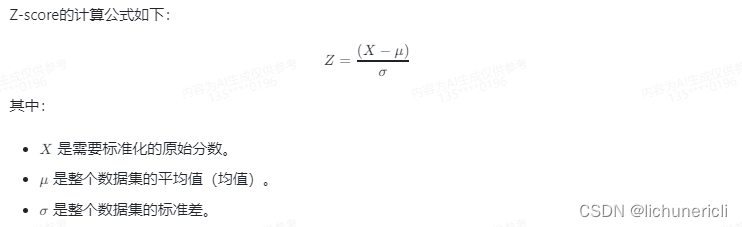
通过计算Z-score,我们可以了解一个数值相对于整个数据集是处于高于平均值还是低于平均值,以及相差了多少个标准差。Z-score的一个重要作用是将不同分布的数据转换为标准正态分布(均值为0,标准差为1的分布),这样便于比较和统计分析。
例如,如果一个学生的某门课程的Z-score是2,那么这意味着该学生的分数比平均值高出2个标准差。Z-score也可以是负数,表示分数低于平均值。Z-score的绝对值越大,表示该分数在数据集中的位置越偏离平均值。
涌现能力
大模型的涌现能力通常指的是在训练过程中,随着模型参数的增加,模型会逐渐展现出一些之前不具备的能力。这些能力可能是在模型训练初期无法预测的,但随着模型规模的扩大和训练数据的增加,这些能力逐渐显现出来。
在深度学习领域,涌现能力是一个重要的研究方向,它涉及到模型设计、训练方法、数据集等多个方面。涌现能力的出现,一方面表明了深度学习模型的强大潜力,另一方面也给模型的解释性和可控性带来了挑战。
例如,在自然语言处理领域,随着模型规模的增加,模型在语言理解、文本生成等方面的能力得到了显著提升。这些能力在一定程度上超出了模型设计者最初的预期,体现了大模型的涌现能力。