Diffusion Models视频生成-博客汇总
前言:MovieFactory是第一个全自动电影生成模型,可以根据用户输入的文本信息自动扩写剧本,并生成电影级视频。其中针对预训练的图像生成模型与视频模型之间的gap提出了微调方法非常值得借鉴。这篇博客详细解读一下这篇论文《MovieFactory: Automatic Movie Creation from Text using Large Generative Models for Language and Images》
目录
贡献概述
方法详解
整体流程
文本扩展
空间微调
时间训练
音频生成
论文和代码
个人感悟
贡献概述
这是第一个全自动电影生成模型,我们的方法使用户能够使用简单的文本输入创建具有平滑转换的字幕电影,产生了仅限于单一质量场景的无声音视频。首先利用 ChatGPT 将用户提供的文本扩展为用于电影生成的详细顺序脚本。然后通过视觉生成和音频检索将脚本在视觉上和声学地带入生活。
通过两阶段过程扩展了预训练的文本到图像扩散模型的能力。第一阶段采用空间微调来弥合预训练图像模型和新的视频数据集之间的差距。第二阶段引入时间学习来捕获物体运动。在音频方面,利用复杂的检索模型来选择和对齐与电影情节和视觉内容相对应的音频元素。
作者自己总结的三点贡献:
- 提出了 MovieFactory,这是一个电影生成框架,允许用户通过简单地使用文本输入来创建高清 (3072×1280)、电影风格(超宽格式)和多场景电影以及伴随声音。
- 引入了一种两阶段训练策略来处理图像和视频数据集之间的视觉域转移。域感知归一化和额外的空间层使模型能够生成高质量的视觉内容,即使在对质量有限的视频数据集进行训练时。
- 展示了在大规模 AI 模型在自动生成电影领域的巨大潜力,为 AI 生成的内容引入了新颖且有前途的应用领域。
方法详解
整体流程
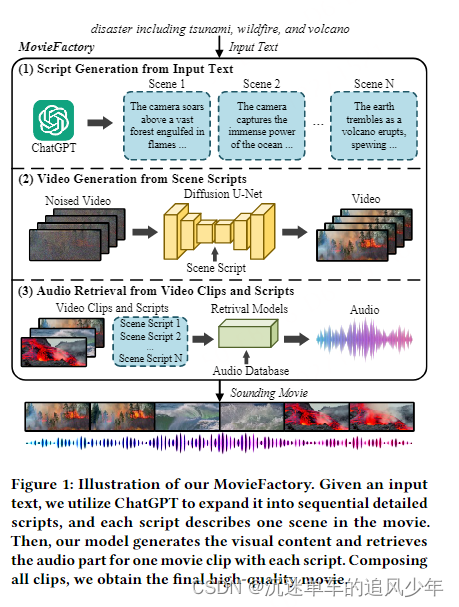
第一步:利用 ChatGPT 将输入文本扩展为顺序详细的脚本。
第二步:视频生成。第一阶段采用空间微调来弥合预训练图像模型和新的视频数据集之间的差距。第二阶段引入时间学习来捕获物体运动。
第三步:配音。用每个脚本检索一个电影片段的音频部分,组合所有并剪辑。
文本扩展
作者用chatgpt来写剧本,使用的prompt是:
"Write a sequence of prompts, using for movie generation for AI. Requirements: 1) each prompt only serves for one scene lasting for about 2 seconds; 2) each prompt contains clear subjects and detailed descriptions; 3) each prompt contains texts like "4K" and "high resolution" for leading high-quality generation; 4) the transition of each scene is very smooth; 5) no other character appears in this movie. The movie is about [User Input]"
空间微调
现有的大规模视频数据集在分辨率和视觉质量方面受到限制,还有的包含水印。而且预训练模型专门针对生成方形视觉内容进行了优化,因为它是在方形图像(高度:宽度=11)上训练的。尽管分辨率的微小调整对视觉内容和质量的影响可以忽略不计,但纵横比的显着变化(例如从 1:1 过渡到 2.35:1)可能会导致生成不稳定,其特征是内容重影和重复。Video LDM表明,使用低质量的视频数据来微调预先训练的层将不可避免地损害生成性能。
作者固定原始模型并插入额外的层以适应分布变化。在 U-Net 块中每个 Up 或 Down 块之前添加了一个修改后的 ResBlk 和注意力层。在修改后的 ResBlk 中添加了一个可学习的域感知归一化来指定和拟合不同的空间分布。

这种设计有两个优点:
1)可以完全保留预训练中的整个知识,因此仍然可以生成不包含在视频数据集中的内容和场景;
2)可以在新模块中拟合多个分布,解决了下一个时间训练中的分布外问题,同时保持同时生成高质量的图片的能力。
时间训练
使模型在模型能够在目标分布中生成图像后学习物体的运动。继之前的工作之后,我们在每个预训练的空间层之后添加时间层。具体来说在每个预训练的空间 ResBlk 之后添加了一个具有 1D 卷积的时间 ResBlk。类似地在每个空间注意力之后添加了一个时间注意力,它与空间注意力共享相同的超参数。与预训练的空间注意不同,在Video LDM的基础上,将sinusoidal embeddings添加到特征中作为时间序列的位置编码。
音频生成
不懂音频,略。
论文和代码
代码无
https://arxiv.org/abs/2306.07257
个人感悟
1、在用chatgpt进行剧本创作那里,我在其他modelscope agent看到过类似的功能,不过那里的实现使用了qwen微调后实现的。作者在本文中并没有写微调相关的部分。
2、空间微调那里,为什么不用lora或者直接用adapter呢?作者改了一个类似adapter思想的东西,让人感觉有点……多少也引用一下喂
3、解决等长宽比到不同长宽比的地方没有看到更详细的解释,也没代码,这块比较疑惑。如何在这两种不同长宽比的数据集上进行微调?