简单的示例:
在PyTorch中,可以使用nn.Module类来定义神经网络模型。以下是一个示例的神经网络模型定义的代码:
import torch
import torch.nn as nnclass MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()# 定义神经网络的层和参数self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)self.relu = nn.ReLU()self.maxpool = nn.MaxPool2d(kernel_size=2, stride=2)self.fc1 = nn.Linear(32 * 14 * 14, 128)self.fc2 = nn.Linear(128, 10)self.softmax = nn.Softmax(dim=1)def forward(self, x):x = self.conv1(x)x = self.relu(x)x = self.maxpool(x)x = x.view(x.size(0), -1)x = self.fc1(x)x = self.relu(x)x = self.fc2(x)x = self.softmax(x)return x
在上面的示例中,定义了一个名为MyModel的神经网络模型,继承自nn.Module类。在__init__方法中,我们定义了模型的层和参数。具体来说:
- 代码定义了一个卷积层,输入通道数为1,输出通道数为32,卷积核大小为3x3,步长为1,填充为1。
- 定义了一个ReLU激活函数,用于在卷积层之后引入非线性性质。
- 定义了一个最大池化层,池化核大小为2x2,步长为2。
- 定义了一个全连接层,输入大小为32x14x14(经过卷积和池化后的特征图大小),输出大小为128。
- 定义了另一个全连接层,输入大小为128,输出大小为10。
- 定义了一个softmax函数,用于将模型的输出转换为概率分布。
在forward方法中,定义了模型的前向传播过程。具体来说:
x = self.conv1(x): 将输入张量传递给卷积层进行卷积操作。x = self.relu(x): 将卷积层的输出通过ReLU激活函数进行非线性变换。x = self.maxpool(x): 将ReLU激活后的特征图进行最大池化操作。x = x.view(x.size(0), -1): 将池化后的特征图展平为一维,以适应全连接层的输入要求。x = self.fc1(x): 将展平后的特征向量传递给第一个全连接层。x = self.relu(x): 将第一个全连接层的输出通过ReLU激活函数进行非线性变换。x = self.fc2(x): 将第一个全连接层的输出传递给第二个全连接层。x = self.softmax(x): 将第二个全连接层的输出通过softmax函数进行归一化,得到每个类别的概率分布。
这个示例展示了一个简单的卷积神经网络模型,适用于处理单通道的图像数据,并输出10个类别的分类结果。可以根据自己的需求和数据特点来定义和修改神经网络模型。
接下来将用于实际的数据集进行训练:
以下是基于CIFAR10数据集的神经网络训练模型:
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from nn_mode import *#准备数据集
train_data=torchvision.datasets.CIFAR10(root='../chap4_Dataset_transforms/dataset',train=True,transform=torchvision.transforms.ToTensor())
test_data=torchvision.datasets.CIFAR10(root='../chap4_Dataset_transforms/dataset',train=False,transform=torchvision.transforms.ToTensor())
#输出数据集的长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print(train_data_size)
print(test_data_size)
#加载数据集
train_loader=DataLoader(dataset=train_data,batch_size=64)
test_loader=DataLoader(dataset=test_data,batch_size=64)
#创建神经网络
sjnet=Sjnet()#损失函数
loss_fn=nn.CrossEntropyLoss()
#优化器
learn_lr=0.01#便于修改
YHQ=torch.optim.SGD(sjnet.parameters(),lr=learn_lr)#设置训练网络的参数
train_step=0#训练次数
test_step=0#测试次数
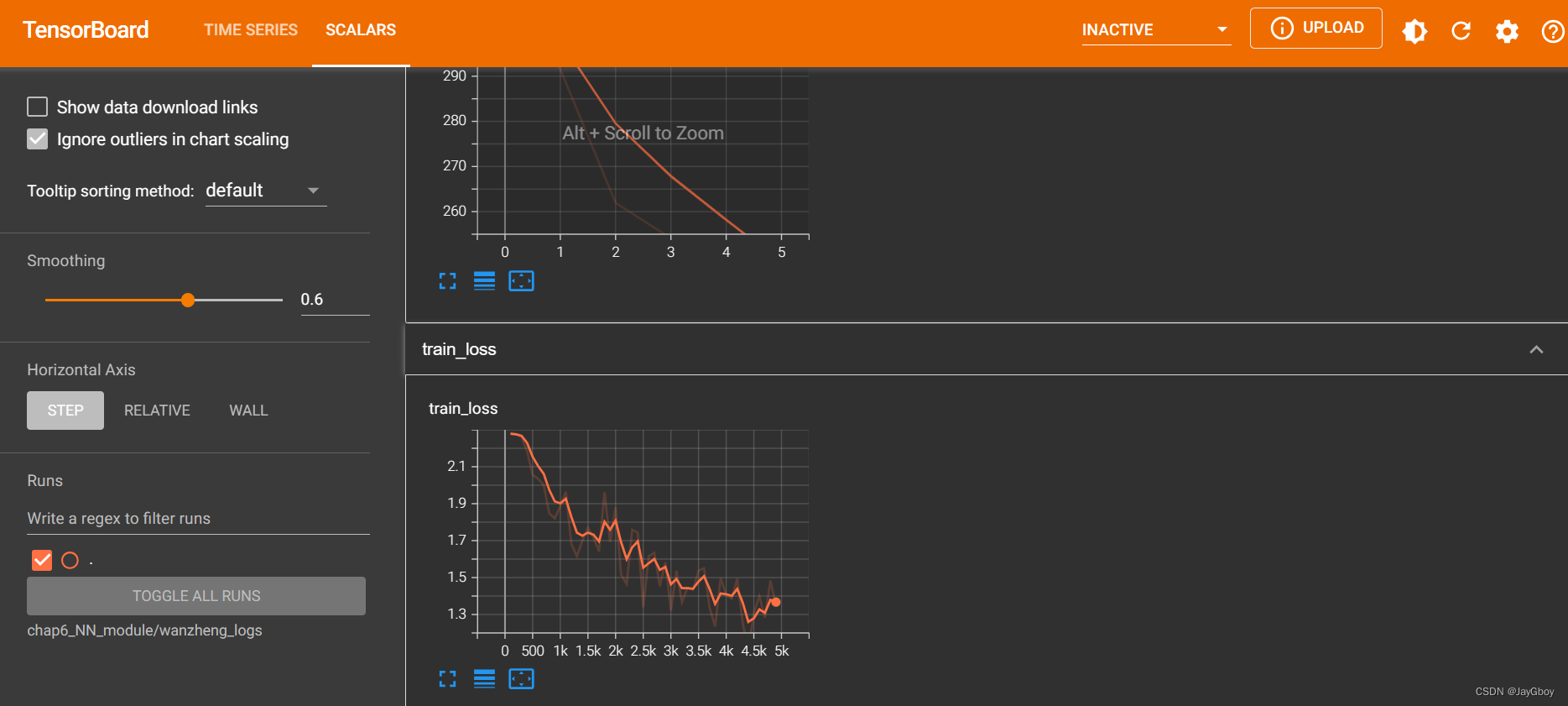
epoch=10#训练轮数writer=SummaryWriter('wanzheng_logs')for i in range(epoch):print("第{}轮训练".format(i+1))#开始训练for data in train_loader:imgs,targets=dataoutputs=sjnet(imgs)loss=loss_fn(outputs,targets)#优化器YHQ.zero_grad() # 将神经网络的梯度置零,以准备进行反向传播loss.backward() # 执行反向传播,计算神经网络中各个参数的梯度YHQ.step() # 调用优化器的step()方法,根据计算得到的梯度更新神经网络的参数,完成一次参数更新train_step =train_step+1if train_step%100==0:print('训练次数为:{},loss为:{}'.format(train_step,loss))writer.add_scalar('train_loss',loss,train_step)#开始测试total_loss=0with torch.no_grad():#上下文管理器,用于指示在接下来的代码块中不计算梯度。for data in test_loader:imgs,targets=dataoutputs = sjnet(imgs)loss = loss_fn(outputs, targets)#使用损失函数 loss_fn 计算预测输出与目标之间的损失。total_loss=total_loss+loss#将当前样本的损失加到总损失上,用于累积所有样本的损失。print('整体测试集上的loss:{}'.format(total_loss))writer.add_scalar('test_loss', total_loss, test_step)test_step = test_step+1torch.save(sjnet,'sjnet_{}.pth'.format(i))print("模型已保存!")writer.close()其神经网络训练以及测试时的损失值使用TensorBoard进行展示,如图所示: