1 专用向量数据库应对未来业务挑战
向量数据库 = 向量检索 + 数据库
向量数据库大致可以分为 2 部分:向量数据的检索,以及向量数据的存储和管理。
向量数据库的性能,比如高 QPS、低延时等,使得业务能够更快的响应用户的查询请求,提供更流畅的使用体验。想要提高向量数据库的性能,首先可以采用更新的向量检索算法,其中各类优异的向量检索算法,通常能够通过各类插件被快速应用。想要进一步提升业务性能,则只有回到数据库的架构和核心层面,设计一款专门为向量数据设计的数据库产品。
同时,随着大模型在业务应用范围不断扩大,向量数据库将从支持业务创新,转变为企业成熟业务体系中的一部分。这对向量数据库的企业级能力要求会越来越全面,比如权限管理、数据加密、备份与恢复、异地多活等。另外,数据规模在不断增长,数据类型日益复杂,这将对以单体数据库为支撑的技术架构提出挑战。
面向向量数据设计、支持大规模弹性扩展、提供企业级能力……这些都意味着我们需要设计一款专用的向量数据库,以便应对 AI 原生应用不断发展带来的挑战。
2 从数据库内核开始设计,为向量数据而生
今年 2 月底,百度智能云推出了一款专用的向量数据库产品 VDB。
在 VDB 1.0 版本中,我们全新设计了数据库内核,使得产品的性能更好,资源开销更低,支持百亿级别的弹性伸缩。相比同类开源产品,VDB 1.0 的 QPS 在不同线程下平均时延最低,性能提升 40~60%。
VDB 1.0 的数据库内核的技术特点如下:
- 分布式架构:基于 bRaft 协议库构建,通过了 TLA+ 形式化验证和混沌测试,支持快速故障切换,具备高可靠和高可用的特性;
- 存储引擎:针对向量数据特性设计的列存引擎。对于一行具有多个向量字段的场景,不同的向量字段的数据能够进行有效地隔离,各自进行存储和索引,能够更精细地管理各自的资源开销。对于标量字段,可通过列式压缩进一步降低存储开销;
- 编程框架:基于现代 C++ 语言编写,使用 bRPC 和 bthread 协程等编程框架构建,充分应用 GCC 编译器优化和 CPU 指令集优化,能够提供更高的性能和内存管理能力。
在产品功能层面,VDB 1.0 支持向量和标量混合检索,提供丰富的标量过滤条件。基于 VDB 1.0 丰富的检索方式,用户可以方便地引入更多场景。同时,VDB 1.0 支持各种数据类型,以及任意数据类型的混合,用户可以设计出更加紧凑的业务数据库表模型,简化业务架构。
如果您正在进行以下几类应用或业务的开发,比如基于大模型的知识处理、基于特性的相似性检索、NoSQL 类数据库应用等,可以尝试使用百度智能云 VDB,体验不一样的速度,以及丰富的企业级能力。
3 第一时间体验 VDB 性能狂飙
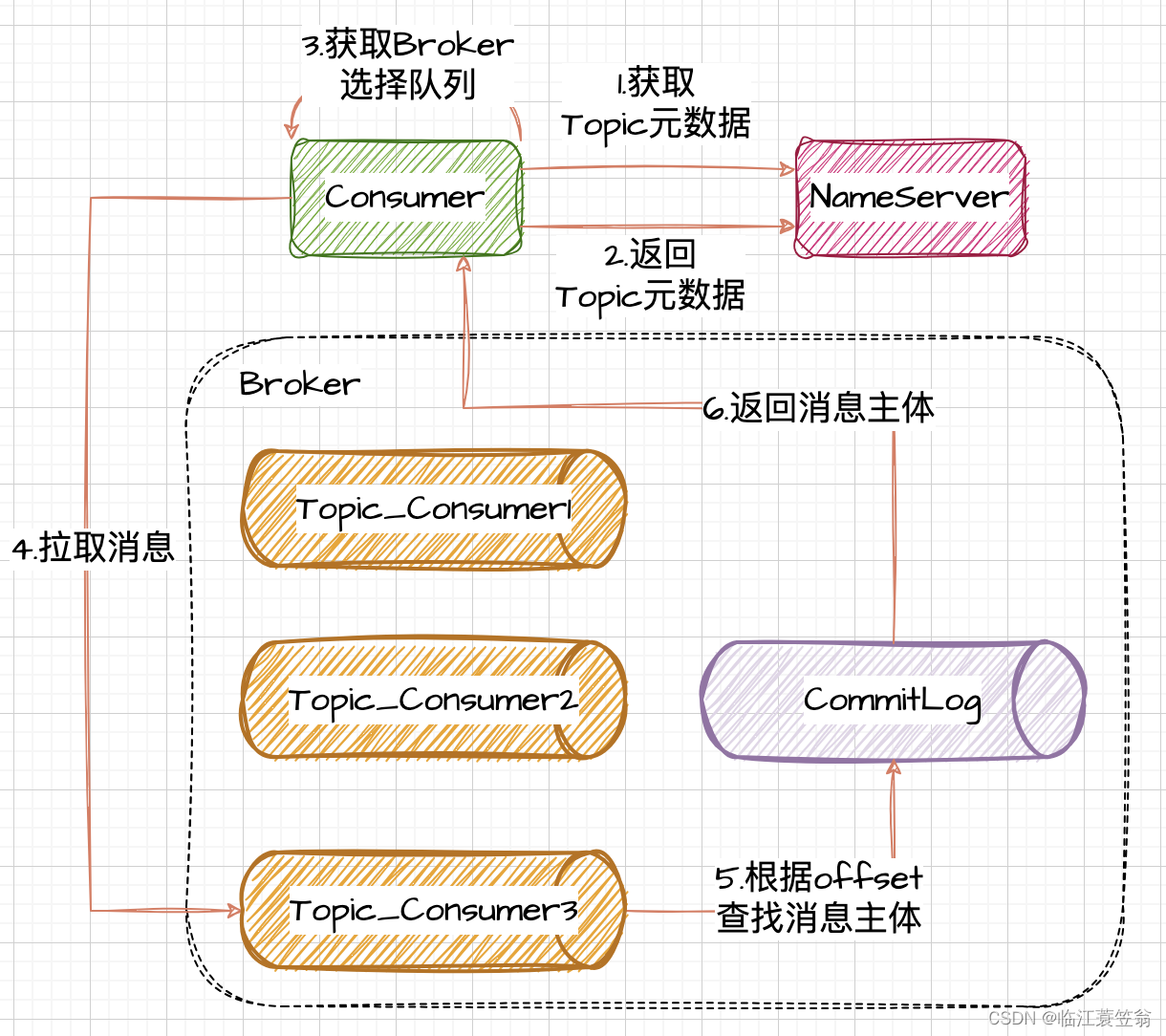
接下来,我们展示一个 VDB 1.0 在知识库场景的示例。通过「千帆大模型平台 + LangChain + VDB」的组合搭建 RAG 应用,第一时间体验 VDB 带来的业务性能提升。以下是一个 RAG 应用的典型方案架构图:
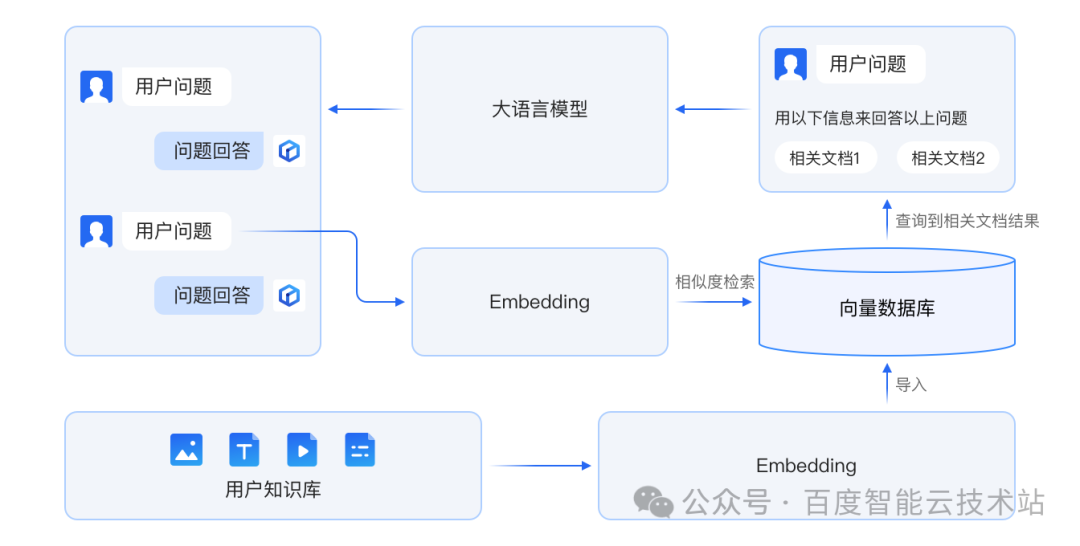
百度智能云全新设计的内核,为 VDB 的后续进化提供了一个良好的底座。在 VDB 后续版本更新中,我们将提供更全面的数据库企业级能力,集成更多的 AI 生态,成为一款为向量数据而生的专业向量数据库。


![[2024-03-09 19:55:01] [42000][1067] Invalid default value for ‘create_time‘【报错】](https://img-blog.csdnimg.cn/direct/3434d33fe79644ccb392a322885281c3.png)