Elasticsearch从入门到精通-03基本语法学习
👏作者简介:大家好,我是程序员行走的鱼
📖 本篇主要介绍和大家一块学习一下ES基本语法,主要包括索引管理、文档管理、映射管理等内容
1.1 了解Restful
ES对数据进行增、删、改、查是以Restful方式对服务端发送请求的,所以在我们学习基本语法之前先了解一下Restful是什么?
REST 指的是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是RESTful。Web 应用程序最重要的 REST 原则是,客户端和服务器之间的交互在请求之间是无状态的。从客户端到服务器的每个请求都必须包含理解请求所必需的信息。如果服务器在请求之间的任何时间点重启,客户端不会得到通知。此外,无状态请求可以由任何可用服务器回答,这十分适合云计算之类的环境。客户端可以缓存数据以改进性能。
在服务器端,应用程序状态和功能可以分为各种资源。资源是一个有趣的概念实体,它向客户端公开。资源的例子有:应用程序对象、数据库记录、算法等等。每个资源都使用 URI (Universal Resource Identifier) 得到一个唯一的地址。所有资源都共享统一的接口,以便在客户端和服务器之间传输状态。使用的是标准的 HTTP 方法,比如 GET、PUT、POST 和DELETE。
在 REST 样式的 Web 服务中,每个资源都有一个地址。资源本身都是方法调用的目标,方法列表对所有资源都是一样的。这些方法都是标准方法,包括 HTTP GET、POST、PUT、DELETE,还可能包括 HEAD 和 OPTIONS。简单的理解就是,如果想要访问互联网上的资源,就必须向资源所在的服务器发出请求,请求体中必须包含资源的网络路径,以及对资源进行的操作(增删改查)。
1.2 Elasticsearch的数据格式
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。为了方便大家理解,我们将 Elasticsearch 里存储文档数据和关系型数据库MySQL 存储数据的概念进行一个类比
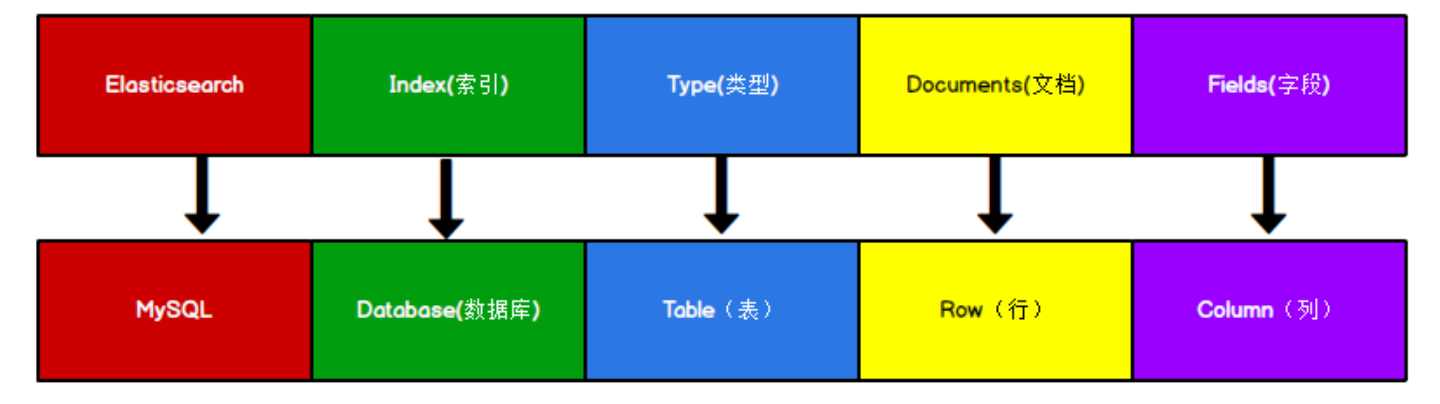
ES 里的 Index 可以看做一个库,而 Types 相当于表,Documents 则相当于表的行。这里 Types 的概念已经被逐渐弱化,Elasticsearch 6.X 中,一个 index 下已经只能包含一个type,Elasticsearch 7.X 中, Type 的概念已经被删除了。
1.3 索引操作
1)创建索引
语法:put /索引名
示例:

{
“acknowledged”【响应结果】: true, # true 操作成功
“shards_acknowledged”【分片结果】: true, # 分片操作成功
“index”【索引名称】: “shopping”
}
注意:创建索引库的分片数(7.0.0之后)默认1片,在 7.0.0 之前的 Elasticsearch 版本中,默认 5 片
当然ES是不允许我们重复创建索引的,如果重复创建索引出报以下错误:
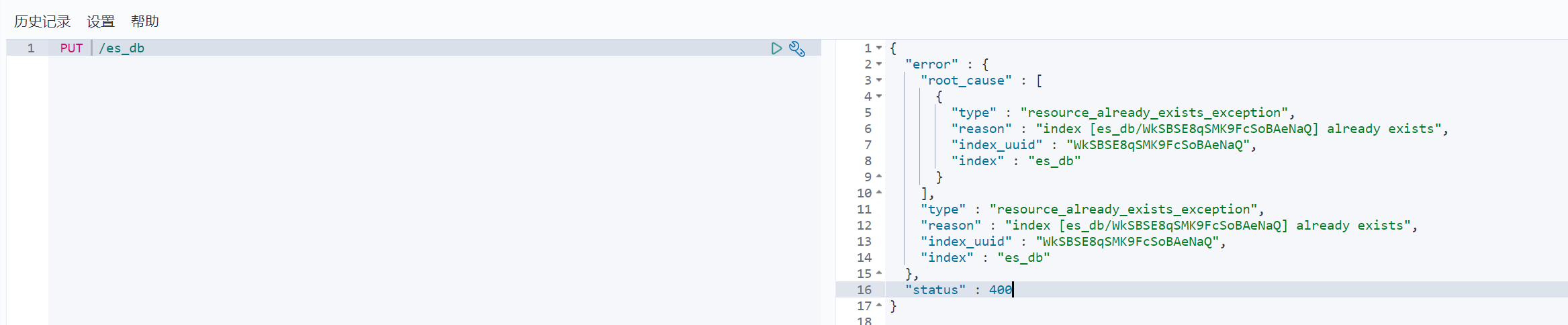
2)查询索引
语法:GET /索引名
示例:
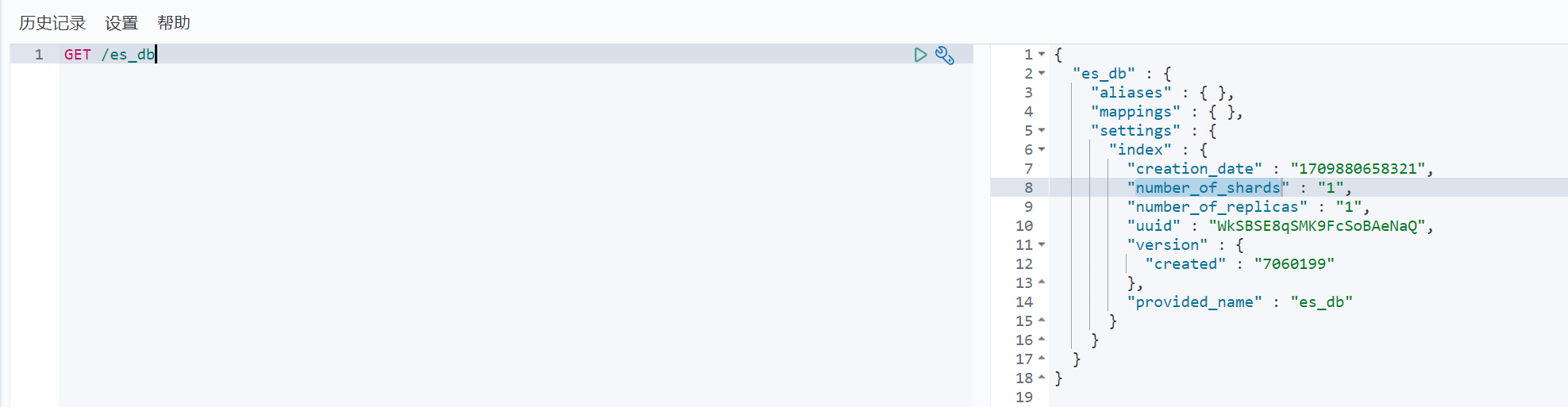
{"es_db": { //索引名"aliases": {}, //别名"mappings": {},//映射"settings": {//设置"index": { //【设置 - 索引"creation_date": "1669733081007",//设置 - 索引 - 创建时间"number_of_shards": "1",//设置 - 索引 - 主分片数量"number_of_replicas": "1",//设置 - 索引 - 副分片数量"uuid": "qhr5DAFeSrOGex2vElBwag", //设置 - 索引 - 唯一标识"version": { //设置 - 索引 - 版本"created": "7080099"},"provided_name": "shopping" //设置 - 索引 - 名称}}}
}
3)查询所有索引
语法:GET /_cat/indices?v
这里请求路径中的_cat 表示查看的意思,indices 表示索引,所以整体含义就是查看当前 ES服务器中的所有索引,就好像 MySQL 中的 show tables 的感觉.
示例:

字段说明:
| 表头 | 含义 |
|---|---|
| health | 当前服务器健康状态:green(集群完整) yellow(单点正常、集群不完整) red(单点不正常) |
| status | 索引打开、关闭状态 |
| index | 索引名 |
| uuid | 索引统一编号 |
| pri | 主分片数量 |
| rep | 副本数量 |
| docs.count | 可用文档数量 |
| docs.deleted | 文档删除状态(逻辑删除) |
| store.size | 主分片和副分片整体占空间大小 |
| pri.store.size | 主分片占空间大小 |
4)删除索引
语法:DELETE /索引名称
示例:

1.4 文档操作
1)创建文档
索引已经创建好了,接下来我们来创建文档,并添加数据。这里的文档可以类比为关系型数据库中的表数据,添加的数据格式为 JSON 格式
PUT /es_db/_doc/1
{"name": "张三","sex": 1,"age": 25,"address": "广州天河公园","remark": "java developer"
}PUT /es_db/_doc/2
{"name": "李四","sex": 1,"age": 28,"address": "广州荔湾大厦","remark": "java assistant"
}PUT /es_db/_doc/3
{"name": "rod","sex": 0,"age": 26,"address": "广州白云山公园","remark": "php developer"
}PUT /es_db/_doc/4
{"name": "admin","sex": 0,"age": 22,"address": "长沙橘子洲头","remark": "python assistant"
}PUT /es_db/_doc/5
{"name": "小明","sex": 0,"age": 19,"address": "长沙岳麓山","remark": "java architect assistant"
}
结果:

"_index" : "es_db",//索引"_type" : "_doc",//类型-文档"_id" : "1",//唯一标识 可以类比为 MySQL 中的主键,不指定随机生成"_version" : 1,//版本"result" : "created",//这里的 create 表示创建成功"_shards" : {//分片"total" : 2, //分片 - 总数"successful" : 1,//分片 - 成功"failed" : 0//分片 - 失败},"_seq_no" : 0,"_primary_term" : 1
}
使用put名称添加数据的时候必须指定id,使用post可以不需要添加id,系统会默认随机生成一个id
2)查看文档
查看文档时,需要指明文档的唯一性标识,类似于 MySQL 中数据的主键查询
语法: PUT /索引名称/类型/id
示例:
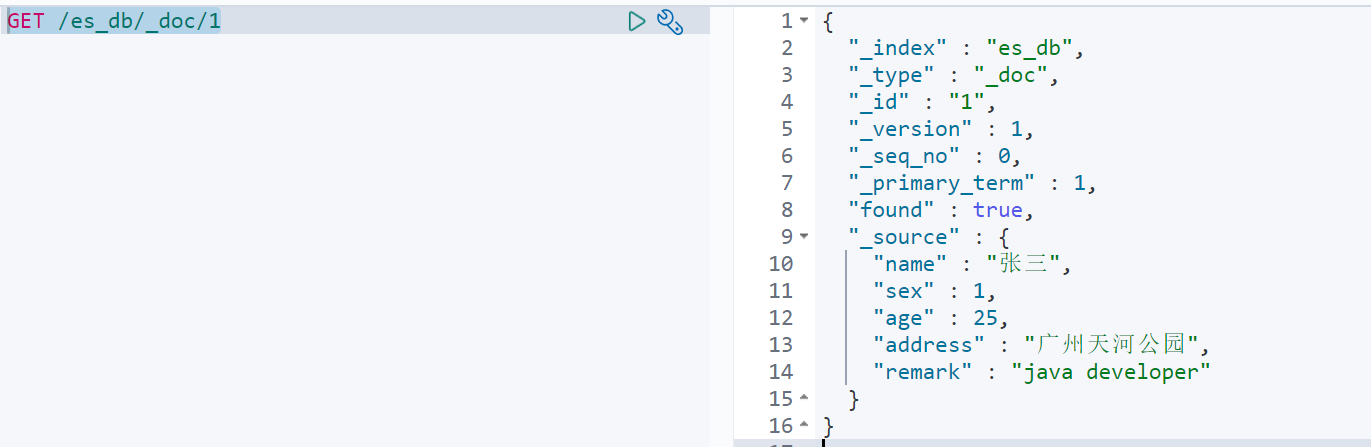
{"_index" : "es_db", //索引"_type" : "_doc",//文档类型"_id" : "1",//文档id"_version" : 1,//文档版本"_seq_no" : 0,"_primary_term" : 1,"found" : true,//查询结果 true 表示查找到,false 表示未查找到"_source" : {//文档源信息"name" : "张三","sex" : 1,"age" : 25,"address" : "广州天河公园","remark" : "java developer"}
}
3)修改文档
和新增文档一样,输入相同的 URL 地址请求,如果请求体变化,会将原有的数据内容覆盖。
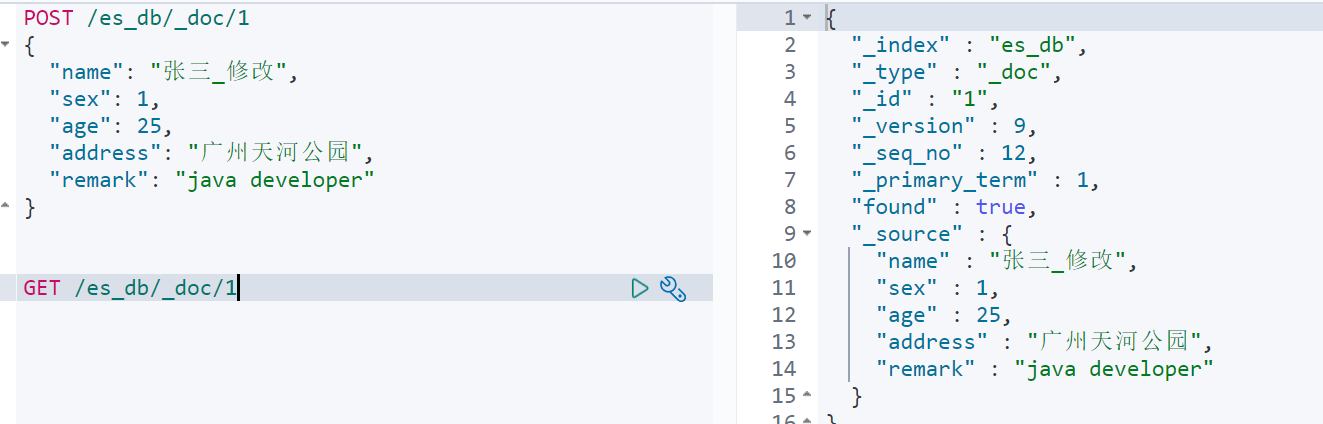
POST /es_db/_doc/1
{"name": "张三_修改","sex": 1,"age": 25,"address": "广州天河公园","remark": "java developer"
}
示例:
4)删除文档
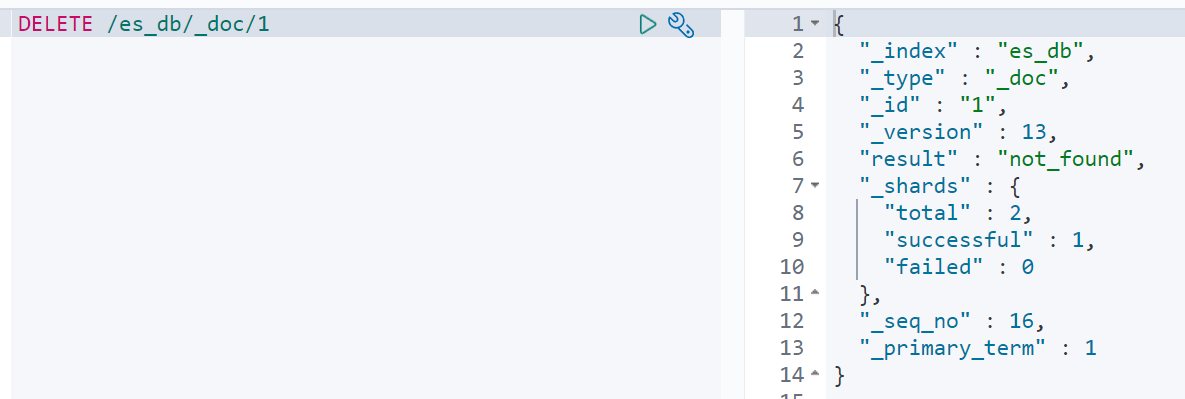
删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)。
语法: DELETE /索引名称/类型/id
示例:
5)批量获取文档
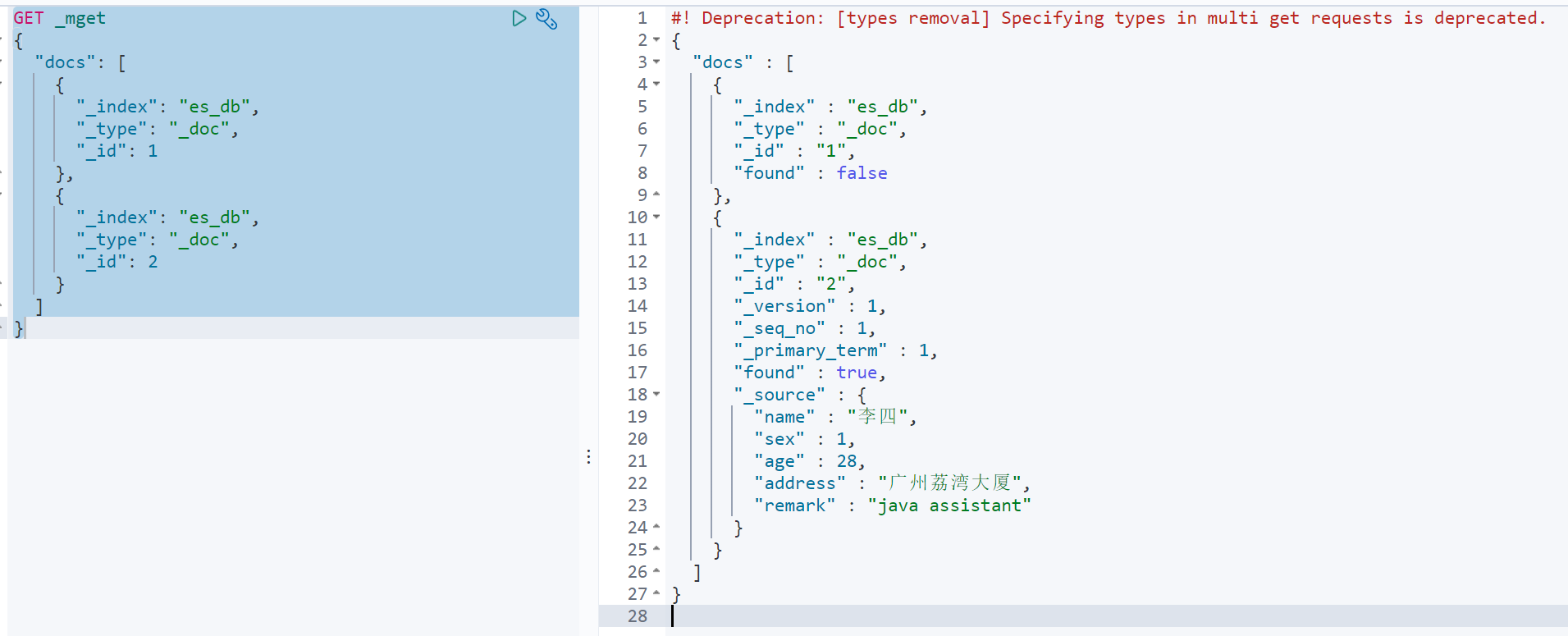
方式1:
GET _mget
{"docs": [{"_index": "es_db","_type": "_doc","_id": 1},{"_index": "es_db","_type": "_doc","_id": 2}]
}
示例:
方式2:
GET /es_db/_mget
{"docs": [{"_type": "_doc","_id": 3},{"_type": "_doc","_id": 4}]
}
示例:

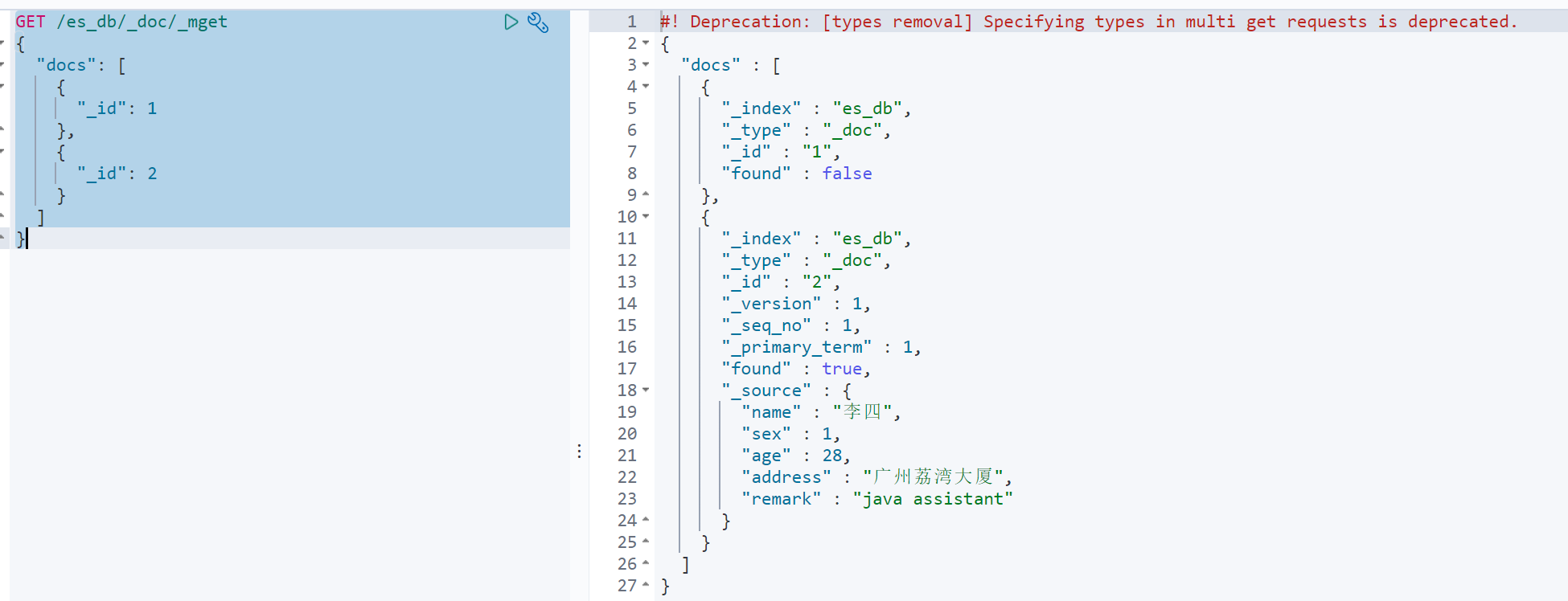
方法3:
GET /es_db/_doc/_mget
{"docs": [{"_id": 1},{"_id": 2}]
}
6)批量操作文档
格式:
批量对文档进行写操作是通过_bulk的API来实现的
- 请求方式:POST
- 请求地址:_bulk
- 请求参数:通过_bulk操作文档,一般至少有两行参数(或偶数行参数)
- 第一行参数为指定操作的类型和操作的对象
- 第二行参数才是操作的数据
{"actionName":{"_index":"indexName", "_type":"typeName","_id":"id"}}
{"field1":"value1", "field2":"value2"}
- actionName:表示操作类型,主要有create,index,delete和update
批量创建文档:
POST _bulk
{"create":{"_index":"es_db","_type":"_doc","_id":6}}
{"id":6,"name" : "李四","sex" : 1,"age" : 28,"address" : "广州荔湾大厦", "remark" : "java assistant"}
{"create":{"_index":"es_db","_type":"_doc","_id":7}}
{"id":6,"name" : "李四","sex" : 1,"age" : 28,"address" : "广州荔湾大厦", "remark" : "java assistant"}
普通创建或者全量替换INDEX
- 如果原文档不存在,则是创建
- 如果原文档存在,则是替换(全量修改原文档)
POST _bulk
{"index":{"_index":"es_db","_type":"_doc","_id":6}}
{"id":6,"name":"李四_修改"}
{"index":{"_index":"es_db","_type":"_doc","_id":8}}
{"id":8,"name":"李四","sex":1,"age":28,"address":"广州荔湾大厦","remark":"java assistant"}
批量删除:
POST _bulk
{"delete":{"_index":"es_db", "_type":"_doc", "_id":6}}
{"delete":{"_index":"es_db", "_type":"_doc", "_id":7}}
批量修改:
POST _bulk
{"update":{"_index":"es_db", "_type":"_doc", "_id":3}}
{"doc":{"name":"李四_修改"}}
{"update":{"_index":"es_db", "_type":"_doc", "_id":4}}
{"doc":{"name":"李四_修改"}}
1.5 索引映射
有了索引库,等于有了数据库中的 database。接下来就需要建索引库(index)中的映射了,类似于数据库(database)中的表结构(table)。创建数据库表需要设置字段名称,类型,长度,约束等;索引库也一样,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做映射(mapping)。ES中映射可以分为动态映射和静态映射
动态映射:
在关系数据库中,需要事先创建数据库,然后在该数据库下创建数据表,并创建表字段、类型、长度、主键等,最后才能基于表插入数据。而Elasticsearch中不需要定义Mapping映射(即关系型数据库的表、字段等),在文档写入Elasticsearch时,会根据文档字段自动识别类型,这种机制称之为动态映射。
动态映射规则如下:
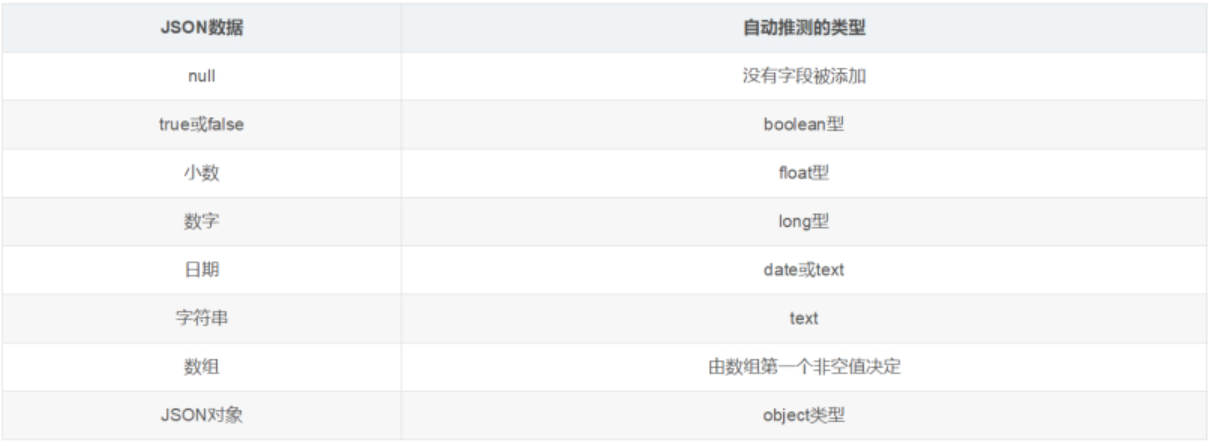
静态映射:
静态映射是在Elasticsearch中也可以事先定义好映射,包含文档的各字段类型、分词器等,这种方式称之为静态映射。
1)创建映射
创建student索引
PUT /student
创建student索引映射
语法:
PUT /student/_mapping
{"properties":{"name":{"type":"text","index":true},"sex":{"type":"text","index":false},"age":{"type":"long","index":false}}
}
映射数据说明:
-
字段名:任意填写,下面指定许多属性,例如:title、subtitle、images、price
-
type:类型,Elasticsearch 中支持的数据类型非常丰富,说几个关键的:
- String 类型,又分两种:
- text:可分词
- keyword:不可分词,数据会作为完整字段进行匹配
- Numerical:数值类型,分两类
- 基本数据类型:long、integer、short、byte、double、float、half_float
- 浮点数的高精度类型:scaled_float
- Date:日期类型
- Array:数组类型
- Object:对象
- String 类型,又分两种:
-
index:是否索引,默认为 true,也就是说你不进行任何配置,所有字段都会被索引。
- true:字段会被索引,则可以用来进行搜索
- false:字段不会被索引,不能用来搜索
-
store:是否将数据进行独立存储,默认为 false
原始的文本会存储在_source 里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source 里面提取出来的。当然你也可以独立的存储某个字段,只要设置"store": true 即可,获取独立存储的字段要比从_source 中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置。
2)修改映射
一个索引库如果创建好了索引映射,是无法直接进行修改的,会提示一下错误:
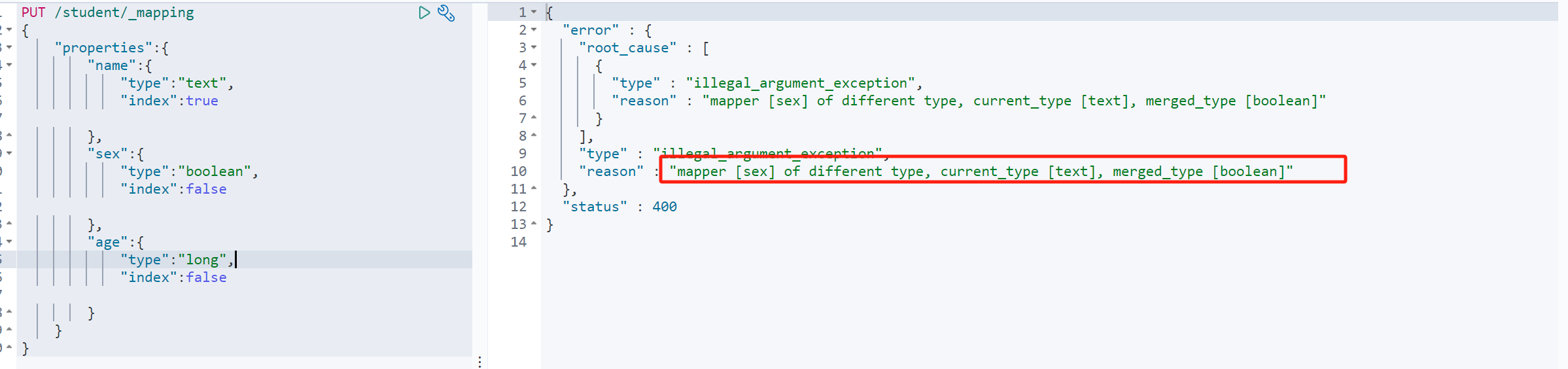
那么我们如何做一个不修改代码、不停机的前提下去做一个索引映射的调整呢?那我们接着往下看
上边我们已经为student创建过映射,现在查看下库里的数据
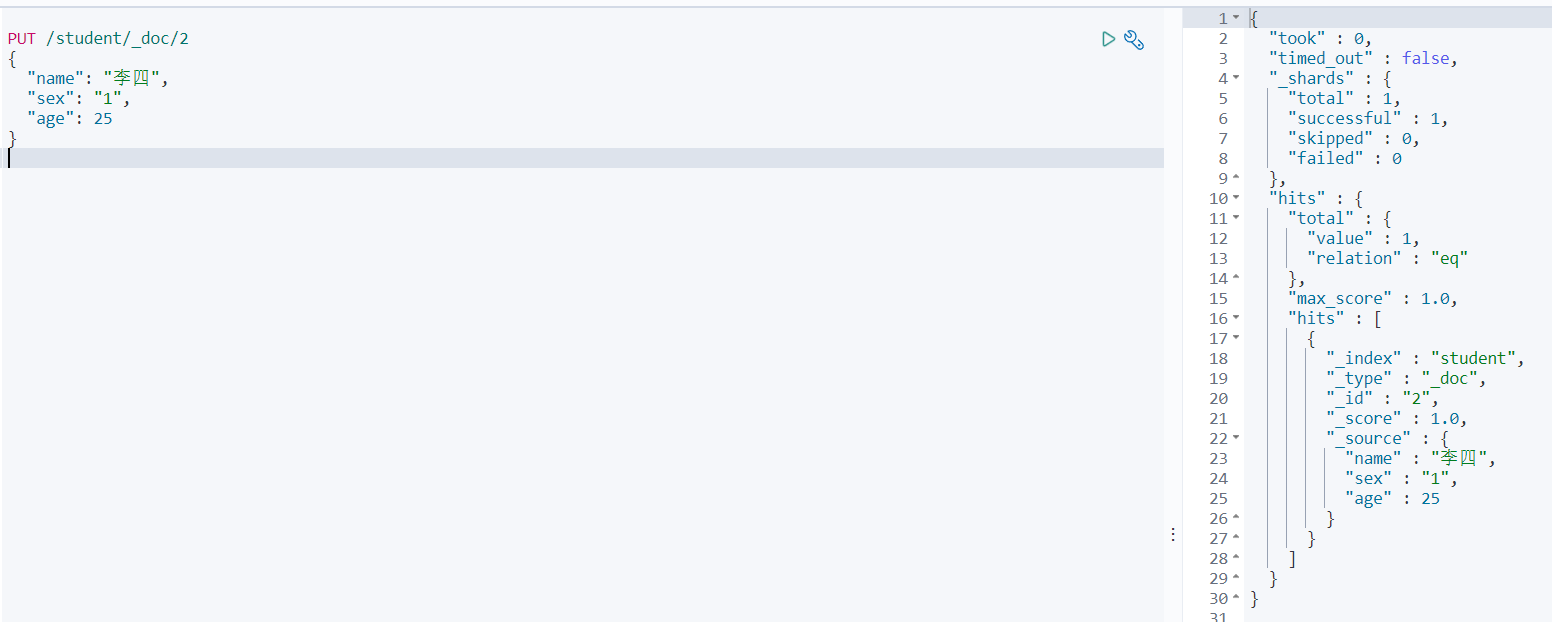
这时候我们需要把name改为keyword类型,先创建一个新的索引student1
PUT /student1
{"settings":{},"mappings":{"properties": {"age": {"type": "long","index": false},"name": {"type": "keyword","index": false},"sex": {"type": "text","index": false}}}}

开始数据迁移:
POST _reindex
{"source": {"index": "student"},"dest": {"index": "student1"}
}
删除老索引:
DELETE /student
给新索引起别名
PUT /student1/_alias/student
再看下新索引映射:
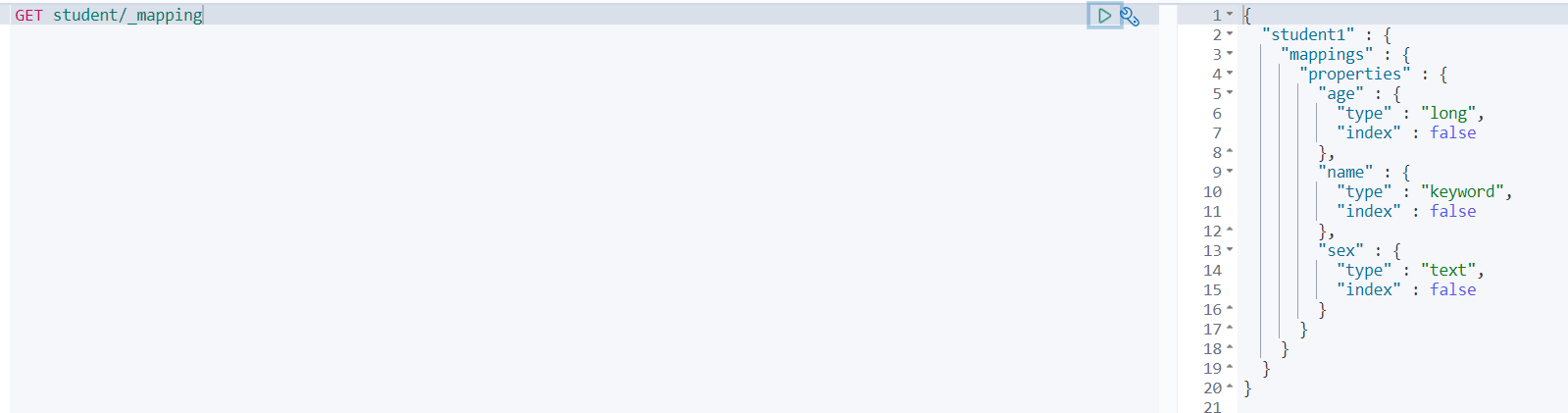
再看下新索引数据:
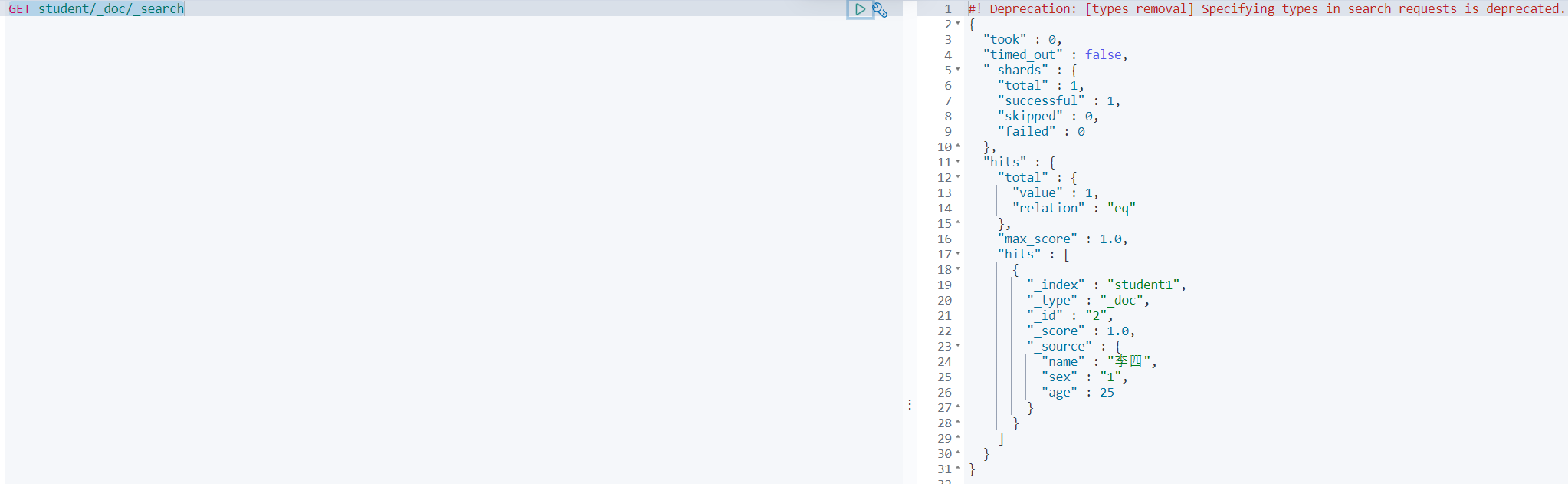
"index": false},"sex": {"type": "text","index": false}}}
}
[外链图片转存中...(img-H1Q2H8Kq-1709993484097)]开始数据迁移:```json
POST _reindex
{"source": {"index": "student"},"dest": {"index": "student1"}
}
删除老索引:
DELETE /student
给新索引起别名
PUT /student1/_alias/student
再看下新索引映射:
[外链图片转存中…(img-taiTtOom-1709993484097)]
再看下新索引数据:
[外链图片转存中…(img-K1oj3rAC-1709993484098)]
🌟至此本篇就结束了,下一篇将介绍ES高级语法DSL!



![[2024-03-09 19:55:01] [42000][1067] Invalid default value for ‘create_time‘【报错】](https://img-blog.csdnimg.cn/direct/3434d33fe79644ccb392a322885281c3.png)

