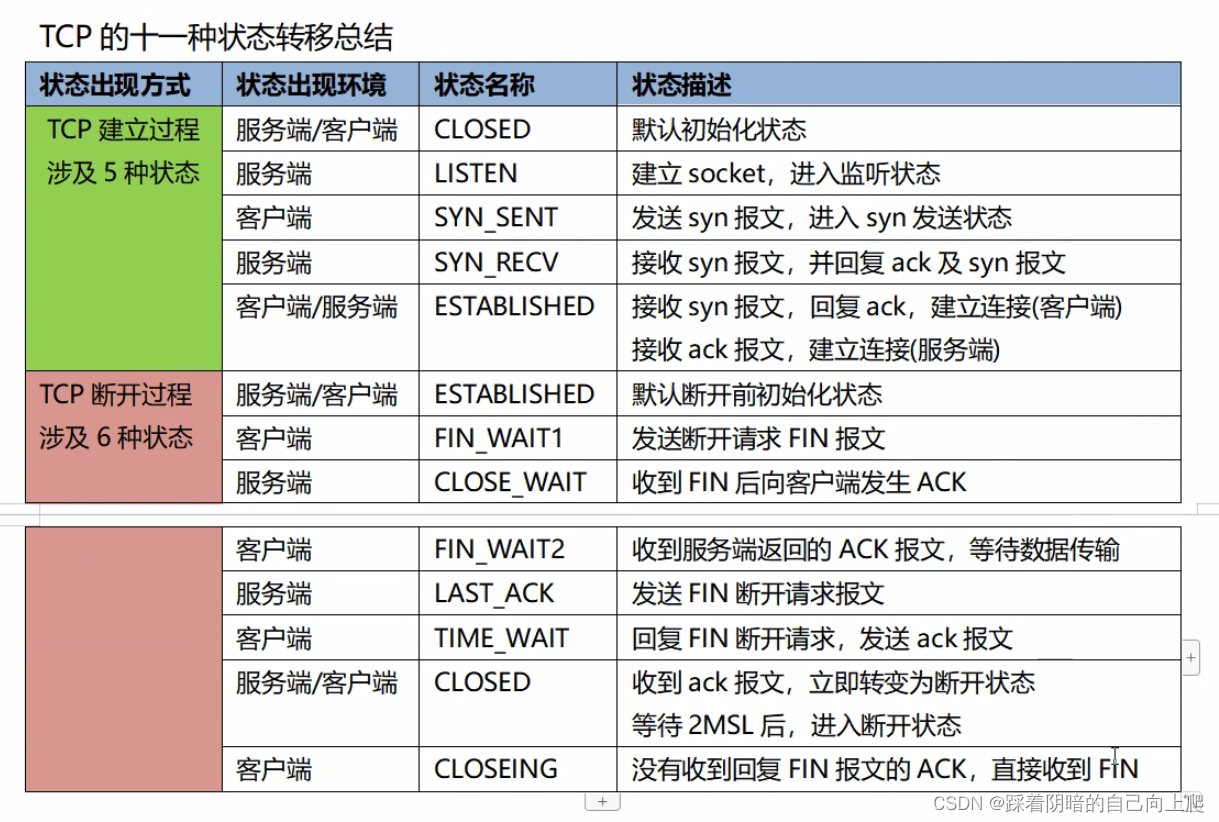
声明:本文章是根据网上资料,加上自己整理和理解而成,仅为记录自己学习的点点滴滴。可能有错误,欢迎大家指正。
一. 神经网络
1. 神经网络的发展
先了解一下神经网络发展的历程。从单层神经网络(感知器)开始,到包含一个隐藏层的两层神经网络,再到多层的深度神经网络,一共有三次兴起过程。详见下图。
随着神经网络的发展,其表示性能越来越强。从单层神经网络,到两层神经网络,再到多层神经网络,下图说明了,随着网络层数的增加,以及激活函数的调整,神经网络所能拟合的决策分界平面的能力。
可以看出,随着层数增加,其非线性分界拟合能力不断增强。图中的分界线并不代表真实训练出的效果,更多的是示意效果。神经网络的研究与应用之所以能够不断地火热发展下去,与其强大的函数拟合能力是分不开关系的。
2. 什么是神经网络
神经网络是一种模拟人脑的神经网络以期能够实现类人工智能的机器学习技术。芬兰计算机科学家Teuvo Kohonen对神经网络定义为:“神经网络,是一种由具有自适应性的简单单元构成的广泛并行互联的网络,它的组织结构能够模拟生物神经系统对真实世界所作出的交互反应。”
下面是一个经典的神经网络。这是一个包含三个层次的神经网络。
- 红色的是输入层(输入节点):从外部世界提供信息。在输入节点中,不进行任何的计算——仅向隐藏节点传递信息
- 紫色的是中间层(也叫隐藏层或隐藏节点):隐藏层和外部世界没有直接联系(由此得名)。这些节点进行计算,并将信息从输入节点传递到输出节点。
- 绿色的是输出层(输出节点):负责计算,并从网络向外部世界传递信息。
输入层有3个输入单元,隐藏层有4个单元,输出层有2个单元。

注意:
- 设计一个神经网络时,输入层与输出层的节点数往往是固定的,中间层则可以自由指定;
- 神经网络结构图中的拓扑与箭头代表着预测过程时数据的流向,跟训练时的数据流有一定的区别;
- 结构图里的关键不是圆圈(代表“神经元”),而是连接线(代表“神经元”之间的连接)。每个连接线对应一个不同的权重(其值称为权值),这是需要训练得到的。
3、什么是神经元
上面说的“简单单元”,其实就是神经网络中的最基本元素——神经元(neuron)模型。在生物神经网络中,每个神经元与其它神经元,通过突触联接。神经元之间的“信息”传递,属于化学物质传递的。当它“兴奋(fire)”时,就会向与它相连的神经元发送化学物质(神经递质, neurotransmiter),从而改变这些神经元的电位;如果某些神经元的电位超过了一个“阈值(threshold)”,那么,它就会被“激活(activation)”,也就是“兴奋”起来,接着向其它神经元发送化学物质,犹如涟漪,就这样一层接着一层传播,如图所示。

神经元模型是一个包含输入,输出与计算功能的模型。输入可以类比为神经元的树突,而输出(是否被激活)可以类比为神经元的轴突,计算则可以类比为细胞核。如图所示。
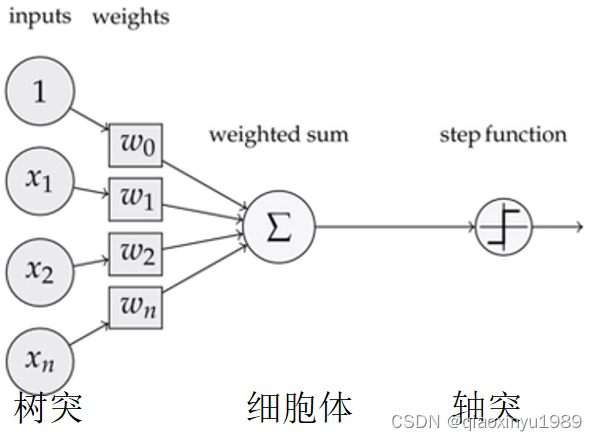
然而,有的小伙伴还是感觉很抽象, 下面从一个逻辑与(AND)的例子形象说起。
(1)逻辑与(AND)
在计算机中,存储的是0和1。计算机有很多对这种01操作的运算,其中有一种运算叫做逻辑与,在编程中运算符通常表示为&。两个数与
&
| | |
| 0 | 0 | 0 |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 1 | 1 |
然后我们要解决的问题是,怎么让神经元根据这四组数据自己学习到这种规则。我们需要做的是让一个神经元根据这四个数据学习到逻辑与的规则。也就是说,将(,

我们让神经元能够学习到将(0,1)、(0,0)、(1,0)这些点分类为0,将(1,1)这个点分类为1。更直观的讲就是神经元得是像图中的这条直线一样,将四个点划分成两类。在直线左下是分类为0,直线右上分类为1。在人工智能范畴的的神经元它本质是一条直线,这条直线将数据划分为两类。与生物意义上的神经元可谓是千差万别。你可以理解为它是受到生物意义上的神经元启发,然后将它用来形象化数学公式。既然神经元它在数学意义上就是一条直线那么,怎么表示呢?
学计算机一个很重要的思维就是:任何一个系统都是由输入、输出、和处理组成。
我们在了解神经元也是一样,在本文中的需求是知道一个坐标(,输出这个坐标的分类y。,
)
我们按照计算机的输入输出思维整理下思路:
输入:
,
输出:
处理:自己学习到从
到的一种映射方法
我们知道输入输出,并且我们知道它是直线,那么我们就可以描述这个问题了。
我们继续看上面的图,在直线的右上方是&
=1
&
=0
。由于啊,在神经元里面大家喜欢把
,
,把常数项命名为
。这些都是约定俗成,所以大家记忆下就好。在本文中,用下面这个公式
表示图中的那条绿色的直线。
根据高中知识,一条直线将平面划分成两半,它可以用如下方式来描述所划分的两个半平面。
- 左下:
,即当
- 右上:
,即当
其实,就是神经元,一个公式而已。是不是觉得神经元的神秘感顿时消失?大家平常看到的那种图只不过是受生物启发而画的,用图来描述这个公式而已。我们画个图来表示神经元,这种画图方法是受到生物启发。而求解图中的参数则从来都是数学家早就知道的方法(最小二乘法)
然后,前面提到过,神经元的形象化是受到生物启发。所以我们先介绍下怎么启发的。
生物意义上的神经元,有突触(输入),有轴突(输出),有细胞核(处理)。并且神经元传输的时候信号只有两个正离子和负离子。这和计算机1和0很类似。
总结下,神经元有
突触(输入),有轴突(输出),有细胞核(处理)。如下图

咱们把上面这个神经元的数学表达式写一下对比下,。以后啊,大家见到神经元就用这种方式理解就可以。
(2)梯度下降(Gradient)
现在问题来了,现在我们有三个参数
我们可以将神经元用公式表示为:,其中未知参数是
这就得想个办法去量化它对吧。在物理界有个东西叫做误差。我们神经元不就是一个函数么,我们要做的是让这个函数尽可能的准确模拟逻辑与(&)这个功能。假设逻辑与(&)可以表示成一个函数
。那么用物理界的术语,我可以称呼
为真实值(参考量值),
为测量值(也常被称作观测值/实际值)。真实值和测量值之间的误差可以两者相减并平方来量化。(绝对误差 = | 测量值 -真实值 |)
其实,本文中的非常简单。就四个点而已。上一个表就可以改为:
| | |
| 0 | 0 | 0 |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 1 | 1 |
这样我们就得到了神经元的误差函数,它的自变量是
注意了:误差函数(error) =代价函数(cost function) =目标函数(objective function) =损失函数(loss function),这三个词可以随意替换的。所以你们在其他地方看到这三个词就都替换成误差函数就可以,别被概念搞蒙了。
损失函数就是一个自变量为算法的参数,函数值为误差值的函数。梯度下降就是找让误差值最小时候这个算法对应的参数。
本文中误差函数可以这么写。但右边没有
代入,展开后可以写成这个样子:
这时右边有了的最小值点呢?我们如果是只看
的话,它是个过原点的二次函数。如果综合看
,
,它像口锅。如果看
注意: 最小值点含有两个意思。一是:求自变量
再次强调:我们要求的是的最小值很明显,它就是0。它是个完全平方嘛肯定>=0。
那怎么求这个误差函数的最小值点呢?
数学家想到了一个办法叫做梯度下降。梯度下降是一个可以让计算机自动求一个函数最小值时,找到它的自变量值就可以了。注意梯度下降只关心自变量值,不关心函数值。这儿你迷糊也没关系,看到后面回头看这句话就懂了。反正梯度下降它做的事就是找自变量。
接下来咱们一起来学习下啥是梯度下降?啥是梯度?为何下降?梯度下降为了能求得最优参数?
- 啥是梯度?梯度就是导数,大家见到“梯度”就把它替换成导数就可以。在多维情况下梯度也是导数只不过是个向量,这个向量每个元素是一个偏导数。
- 为何下降?因为在数学里面(因为神经网络优化本来就是数学问题),在数学里面优化一般只求最小值点。那么有些问题要求最大值点怎么办?答:“在前面加负号”。简单粗暴就解决了。好继续回答为何下降,因为是求最小值点,那么这个函数肯定就像一口锅,我们要找的就是锅底的那个点在哪,然后我们当然要下降才能找到最小值点啦。
- 为何梯度下降能求最优参数?因为只有知道梯度下降怎么做的,才知道为何它能求最优参数。所以接下来要介绍的是,
梯度下降如何实现利用负梯度进行下降的。
再次总结下,我们需要让计算机求的参数是梯度下降求最优的的吧。会求
其它的几个参数都是一样的求法。
那梯度下降怎么做到求最优的呢?(最优指的是误差函数
此时取最小)
它采取的一个策略是猜。没错,就是猜。简单粗暴。不过它是理性的猜。说的好听点叫做理性的去估计。我们前面提到了误差函数关于是一个二次函数,假设长下面这样。
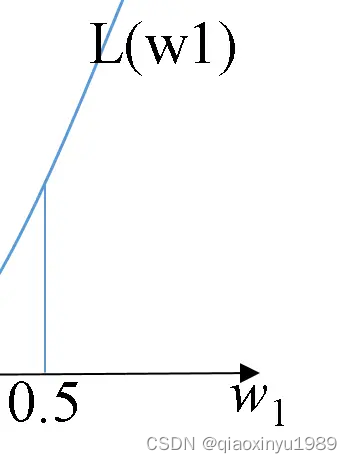
但计算机不知道它长这样啦。它只能看到局部。首先一开始它随便猜,比如猜=0.5吧。我们前面提到了计算机它只知道局部。为何呢?你想,我现在取值是
=0.5,我可以增大一点点或减小一点点
,这样我当然只知道
=0.5这周围的误差函数值啦。
现在按照你的直觉,猜一猜猜一猜,你觉得最优的到底比0.5大还是比0.5小?
我想我们答案应该是一样的,肯定比0.5小。因为往右边走,即让比0.5大的话,它的误差函数是增长的。也就是在
=0.5周围时候,
越大,误差越大。
其实梯度下降就是让计算机这么猜,因为计算机判断速度快嘛。猜个上万次就很容易猜到最优值。
回顾下我们怎么猜的?
我们是直觉上觉得,这个增大误差函数是增加的。那这个怎么用理性思考呢?这个时候就可以用高中所学的判断函数单调性的方法了:求一阶导数啊。即:“一阶导数>0,函数单调递增,函数值随自变量的增大而增大”。
所以,我们只需要让计算机判断当前猜的这个点导数是大于0还是小于0. 该点一阶导数大于0的话,这个局部是单调递增的,增大的值,误差函数值会增大。因此就得减小
的值;同理,如果一阶导数小于0 ,那么这个局部是单调递减的,我们增大
的值可以降低误差函数值。
总结规律:
导数>0, 减小
的值。 导数<0,增大
可以发现,
学习率。(从这里可以看出学习率肯定小于1的)因此可以这么表示:下次要猜的
学习率一般设置0.001,0.01,0.03等慢慢增大,如果计算机猜了很久没猜到证明得让它放开步子猜了,就增大它。
现在我们知道梯度下降干嘛了吧,它就是理性的猜最优值。那什么时候结束猜的过程呢?我们看下图,发现它最优值的那个地方导数也是0.那么我们只需要判断误差函数对的导数是否接近0就可以。比如它绝对值小于0.01我们就认为已经到了最优点了。

误差函数是这个:. 对
求导,得到导函数
.
现在总结下梯度下降(采用的是很常用的随机梯度下降)的步骤:
①初始化
②{遍历样本(逐个样本更新参数)
③{ 将样本
,和标签
,代入损失函数对
下次要猜的
}
然后我们就可以得到最优的
对于剩下的,
他们是一样的,都是利用让计算机猜。大家参考
怎么求的吧。
注意了,因为我们是二分类问题,虽然我们想让它直接输出0和1,但是很抱歉。它只能输出接近0和接近1的小数。为了方便编程,我们用-1代替0。也就是说只要神经元输出负数我们认为它就是输出0. 因为直接判断它是否接近0和是否接近1编程会更麻烦
注意了,因为我们是二分类问题,虽然我们想让它直接输出0和1,但是很抱歉。它只能输出接近0和接近1的小数。为了方便编程,我们用-1代替0。也就是说只要神经元输出负数我们认为它就是输出0. 因为直接判断它是否接近0和是否接近1编程会更麻烦
注意了,大家以后也会发现很多数据集二分类问题都会用1和-1而不用0.这是为了编程方便。我们只需要判断正负就可以知道是哪个分类。而不是需要判断是接近0还是接近1
好现在我们知道神经元的数学表达和怎么画它的形象化的图了。那么不如我们用编程也表达下它吧?
(3)实例演示
整体思路:
神经# 单层神经元 求f=x1&x2,f值的划分(即1划一组,0划一组) # 即求误差△=|测量值-参考值|=|w1*x1+w2*x2+b-g(x1,x2)|的值最小 # 即求△的导数 ≈ 0,如对w1求导: 2*(w1*x1+w2*x2+b-g(x1,x2))*x1 ≈ 0
训练函数:
import numpy as np# train :训练样本
# 输入 data 用于训练的数据样本,样本格式为[x1,x2,g(x1,x2)]
# 输入 epoch 数据训练的次数
# 输入 learn_rate # 设置学习率,防止猜的步子太大
# 输入 g_pred 预测值 g(x1,x2)
# 返回 weights 权重
# 返回 biases 偏置
def train(data, g_pred, n_epoch=1000, learn_rate=0.01):n_sample, n_feature = data.shape # 获得样本的数量(行)和数据的特征(列)# 第一步: 初始化w和b的值,随便取w和b的值。weights = np.random.randn(n_feature) # 随机设置权重,即初始化w,随便取w的值biases = np.random.randn() # 初始化b,随便取b的值# 第二步 训练样本for _ in range(n_epoch):for i in range(n_sample): # 逐个样本更新权重# 其中 i=[x1,x2,g(x1,x2)],为data数据中一行# 分别求w1、w2、b在(x1,x2,g(x1,x2))处的导函数值y_pred = np.dot(weights, data[i]) + biases # 计算预测值,即 f=w*x+b的值d_weights = (y_pred - g_pred[i]) * 2 * data[i] # 误差 =(测量值-预测值)^2,对误差取导数=2*(w*x+b-g(x1,x2))*wd_biases = (y_pred - g_pred) * 2loss = np.square(y_pred) # 计算损失的平方# 设置猜数环节:下次猜的数 = 本次猜的数 - 学习率*导数值weights_next = weights - learn_rate * d_weightsbiases_next = biases - learn_rate# 更新各自参数weights = weights_nextbiases = biases_nextreturn weights, biases定义神经元
# 定义 神经元
# 经过训练,我们期望它的返回值是x1&x2
# 即:返回值是 w1*x1+w2*x2 + b > 0? 1:0;
def f(data, weights, biases):c = 1 if np.dot(weights, data) + biases > 0 else 0return c整体流程
import numpy as np
import matplotlib.pyplot as pltdata = np.array([[0, 0], [0, 1], [1, 0], [1, 1]]) # x1,x2的四个元素
g_real = np.array([-1, -1, -1, -1]) # 四个真实值
weights, biases = train(data, g_real) # 自定义的训练函数,让神经元自己根据四条数据学习逻辑与的规则
#打印相关值,看是否正确
print(weights, biases)
print("0&0", f(data[0], weights, biases))
print("0&1", f(data[1], weights, biases))
print("1&0", f(data[2], weights, biases))
print("1&1", f(data[3], weights, biases))# 绘制训练后的图像
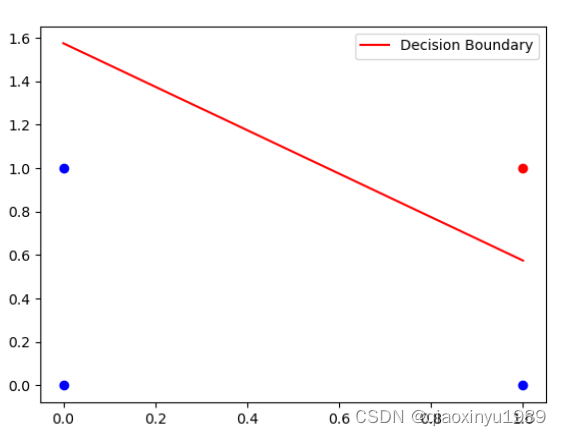
x1 = data[:, 0] # 提取第1列的值
x2 = -(weights[0] * x1 + biases) / weights[1]
plt.plot(x1, x2, 'r', label='Decision Boundary')
n_sample, n_feature = data.shape # 获得样本的数量(行)和数据的特征(列)
for i in range(data.shape[0]):if f(data[i], weights, biases) == 0:plt.plot(data[i, 0], data[i, 1], 'bo')else:plt.plot(data[i, 0], data[i, 1], 'ro')plt.legend()
plt.show()
运行的结果:

参考:易懂的神经网络理论到实践(1):单个神经元+随机梯度下降学习逻辑与规则 - 知乎 (zhihu.com)