经常被问到进程的调度算法有哪些,什么先进先出、短进程优先、时间片轮转、多级反馈多列等等算法能说一大堆?那具体的,linux内核使用了什么样的算法,且来探究一下。
本文所引用源码基于linux内核2.6.34版本。
目录
调度器类
从 schedule() 开始
pick_next_task()
三种调度器类
完全公平调度算法
时间记账
公平的pick_next_task()
总结
调度器类
首先要明确的是,linux并不仅仅使用一种调度算法,而是多种。具体的,内核中以调度器类的方式提供多种调度算法。这样做的目的是为了让不同类型的进程有选择性的使用不同的调度算法。
从 schedule() 开始
schedule() 是内核调度的入口函数。例如当一个进程调用read之类的阻塞方法而数据没有就绪时,内核就会通过 schedule() 函数触发调度,将自己挂到等待队列中,寻找一个新进程去运行。schedule() 的实现在 kernel/sched.c 文件中,它会停止当前正在运行的进程,并找到下一个待运行的进程去调度执行。
void __sched schedule(void)
{// 清除当前进程的重调度标识clear_tsk_need_resched(prev);// 将旧进程从运行队列中移除if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) {if (unlikely(signal_pending_state(prev->state, prev)))prev->state = TASK_RUNNING;elsedeactivate_task(rq, prev, 1);switch_count = &prev->nvcsw;}// 调度前的处理钩子pre_schedule(rq, prev);// 将当前进程放回运行or等待队列,并选择下一个要运行的进程put_prev_task(rq, prev);next = pick_next_task(rq);// 执行上下文切换及更新统计信息if (likely(prev != next)) {sched_info_switch(prev, next);perf_event_task_sched_out(prev, next);rq->nr_switches++;rq->curr = next;++*switch_count;context_switch(rq, prev, next); /* unlocks the rq */} elseraw_spin_unlock_irq(&rq->lock);// 调度后的处理钩子post_schedule(rq);
}schedule() 虽然函数体比较长,但其做的事情比较简单,最重要的事情就是 pick_next_task() 和 context_switch() 啦。我们需要具体看一下它是怎么pick next的~
pick_next_task()
pick_next_task() 会根据优先级,从高到低依次检查每一个调度器类,并且从最高优先级的一个调度器类中,选择最高优先级的一个进程出来。
/** 选择优先级最高的task*/
static inline struct task_struct *
pick_next_task(struct rq *rq)
{const struct sched_class *class;struct task_struct *p;/** 优化:如果所有的运行态的任务都属于cfs调度器的运行队列* 那么这里就可以直接调用cfs调度器的方法*/if (likely(rq->nr_running == rq->cfs.nr_running)) {// fair_sched_class:cfs调度器p = fair_sched_class.pick_next_task(rq);if (likely(p))return p;}// sched_class_highest:取最高优先级的调度器类class = sched_class_highest;for ( ; ; ) {p = class->pick_next_task(rq);if (p)return p;/** 永远不会走到这里,因为idle调度器总会返回一个task*/returns a non-NULL p:class = class->next;}
}调度器类 sched_class 的定义如下,其中定义了一个指向下一优先级调度器类的一个指针,以及多个函数指针,分别用以执行不同的操作。这也是kernel中使用面向对象思想的体现。
struct sched_class {// 指向下一个sched_class的指针,用于支持调度类的层次结构const struct sched_class *next;// 将任务(进程或线程)添加到运行队列void (*enqueue_task) (struct rq *rq, struct task_struct *p, int wakeup,bool head);// 从运行队列中移除任务void (*dequeue_task) (struct rq *rq, struct task_struct *p, int sleep);// 使当前任务放弃CPU,让其他任务有机会运行void (*yield_task) (struct rq *rq);// 检查当前任务是否应该被抢占(即被其他任务中断)void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags);// 从运行队列中选择下一个要运行的任务struct task_struct * (*pick_next_task) (struct rq *rq);// 将前一个任务(即刚刚被抢占或完成的任务)放回运行队列void (*put_prev_task) (struct rq *rq, struct task_struct *p);// 设置当前任务为运行队列的当前任务void (*set_curr_task) (struct rq *rq);...
};三种调度器类
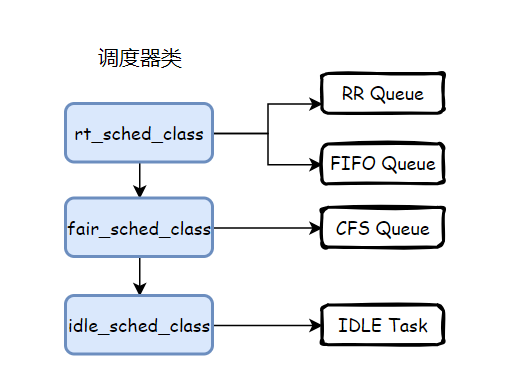
根据 next 指针的指向,很容易找到 kernel 支持的几种调度器类:
- rt_sched_class:实时调度器类,优先级最高:分为RR算法、FIFO算法。RR为一种基于时间片的FIFO算法,按入队顺序先进先出的执行。FIFO即为简单的先进先出算法。
- fair_sched_class:完全公平(cfs)调度器类,完全公平调度算法。
- idle_sched_class:空闲调度器类,优先级最低,只有当系统中没有其它优先级更高的任务时,才会调度到。
根据调度器器的种类,也就能看出,从调度的角度来讲,kernel 将进程分为三种类型,分别为实时进程、普通进程以及空闲进程。通过 ps 命令可以查看 linux 环境中不同进程的优先级及采用的调度算法:
LC0:~$ ps -eo pid,cls,sched,pri,comm | grep "FF\|RR\|IDL"16 FF 1 139 migration/017 FF 1 90 idle_inject/039 FF 1 90 watchdogd1776 IDL 5 0 tracker-miner-f
LC0:~$ ps -eo pid,cls,sched,pri,comm | grep "TS" | head -n11 TS 0 19 systemd
LC0:~$ 其中 FF 为实时调度算法中的FIFO;TS 表示 "Time Sharing",即为时间共享调度策略,也即 CFS 完全公平调度算法,旨在公平地分配CPU时间给所有进程;IDL 即空闲调度策略。由于 IDL 调度器只是用来在无可运行进程调度时使用,所以其只管理一个 idle 进程,并没有使用到运行队列。
完全公平调度算法
CFS 调度算法的设计基于一个简单的理念而来:进程调度的效果应该如同系统具备一个理想中的完美多任务处理器。在这种系统中,每个task均能公平的获得 (1/可运行进程数) 的处理器时间比。
理论上,如果能把时间片分隔为无限小,那么就可以做到平均分配给每个进程相同的运行时间,也就能做到完全公平。然而实际上,一方面cpu的时钟周期不是无限小的,并且任务的切换是有代价的,时间片粒度细到一定程度,CPU 只能忙于切换进程的上下文,而无暇执行实际的任务了。
现实如何?CFS 充分考虑了这种切换带来的开销,允许每个进程运行一段时间、循环轮转、选择运行最少的进程作为下一个运行进程。这里的运行最少也不是简单的根据时间片来计算了,而是一个时间片的加权值:处理器时间比。nice 值在 CFS 中被作为进程获得处理器运行比的权重:nice值越高,进程可获得的处理器时间比也就越小,反之。
时间记账
即使 CFS 不是按时间片,而是按时间比来调度进程,但其仍然必需维护每个进程运行的时间记账,并据此确保每个进程只在分配给它的处理器时间内运行。
在 linux/sched.h 中定义了时间记账的结构体——调度实体:
struct sched_entity {// 实体的负载权重,用于调度决策struct load_weight load;// 红黑树节点,用于快速查找和插入调度实体struct rb_node run_node;// 链表节点,将实体组织成链表struct list_head group_node;// 指示实体是否在调度队列上unsigned int on_rq;// 记录实体开始执行的时间u64 exec_start;// 记录实体执行的总时间u64 sum_exec_runtime;// 虚拟运行时间,即加权后的执行时间u64 vruntime;// 上一次计算时的 sum_exec_runtime 值u64 prev_sum_exec_runtime;// 实体最后一次被唤醒的时间u64 last_wakeup;...
};调度实体 sched_entity 这个结构的指针,存放在 task_strcut 中。sched_entity比较重要的变量则是 vruntime,它表示进程执行的加权后的时间,CFS 用这个 vruntime 帮助实现逼近理想多任务处理器的完美公平调度。
记账功能通过定时器定时调用 update_curr() 实现:
static void update_curr(struct cfs_rq *cfs_rq)
{// 获得最后一次修改load后当前任务所占用的运行总时间delta_exec = (unsigned long)(now - curr->exec_start);__update_curr(cfs_rq, curr, delta_exec);curr->exec_start = now;if (entity_is_task(curr)) {struct task_struct *curtask = task_of(curr);trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);cpuacct_charge(curtask, delta_exec);account_group_exec_runtime(curtask, delta_exec);}
}update_curr() 计算出当前进程的运行时间,保存到了 delta_exec 变量中。然后调用了 __update_curr() 。__update_curr() 根据当前可运行进程总数对运行时间进行加权计算,结果累加到 vruntime 中。
static inline void
__update_curr(struct cfs_rq *cfs_rq, struct sched_entity *curr,unsigned long delta_exec)
{curr->sum_exec_runtime += delta_exec;delta_exec_weighted = calc_delta_fair(delta_exec, curr);curr->vruntime += delta_exec_weighted;...
}static inline unsigned long
calc_delta_fair(unsigned long delta, struct sched_entity *se)
{if (unlikely(se->load.weight != NICE_0_LOAD))delta = calc_delta_mine(delta, NICE_0_LOAD, &se->load);return delta;
}// delta *= weight / lw
static unsigned long
calc_delta_mine(unsigned long delta_exec, unsigned long weight,struct load_weight *lw)
{// 近似计算出 lw->weight的倒数 + 1if (!lw->inv_weight) {if (BITS_PER_LONG > 32 && unlikely(lw->weight >= WMULT_CONST))lw->inv_weight = 1;elselw->inv_weight = 1 + (WMULT_CONST-lw->weight/2)/ (lw->weight+1);}tmp = (u64)delta_exec * weight;// SRR为对tmp低32位四舍五入并只保留tmp的高32位tmp = SRR(tmp * lw->inv_weight, WMULT_SHIFT);return (unsigned long)min(tmp, (u64)(unsigned long)LONG_MAX);
}
公平的pick_next_task()
CFS 会挑选一个 vruntime 最小的进程来作为下一个运行的进程,它通过红黑树来组织可运行进程队列,并利用其快速查找最小 vruntime 的节点。pick_next_task_fair() 是 CFS 调度器注册到调度器类中的 pick_next_task() 钩子函数。
static struct task_struct *pick_next_task_fair(struct rq *rq)
{do {se = pick_next_entity(cfs_rq);set_next_entity(cfs_rq, se);cfs_rq = group_cfs_rq(se);} while (cfs_rq);p = task_of(se);return p;
}// pick_next_entity中调用__pick_next_entity
static struct sched_entity *__pick_next_entity(struct cfs_rq *cfs_rq)
{struct rb_node *left = cfs_rq->rb_leftmost;if (!left)return NULL;return rb_entry(left, struct sched_entity, run_node);
}最小 vruntime 的节点,其实就是对应红黑树中最左侧的那个叶子节点。__pick_next_entity找到这个最左节点并返回了调度实体,pick_next_task_fair() 中通过 task_of() 找到来调度实体所属的 task_struct。
总结
linux实现了三种不同的调度器类:实时调度器、完全公平调度器、空闲调度器,分别对应实时进程、普通进程、空闲进程。实际环境中大多数进程都是普通进程,即采用完全公平调度算法。完全公平调度算法调度程序取决于运行程序消耗了多少处理器使用比,如果消耗的使用比比当前进程小,那么新进程会立刻投入运行,抢占当前进程。