在现代web开发中,JavaScript (JS) 是不可或缺的一部分,它使我们能够为网页赋予交互性和动态性。其中,DOM(文档对象模型)技术在前端开发中起着至关重要的作用。本篇博客将带领前端初学者深入理解JavaScript DOM技术,为你构建坚实的基础。
1. DOM简介
1.1 什么是DOM
文档对象模型(Document Object Model,简称 DOM),是 W3C 组织推荐的处理可扩展置标语言的标准编程接口。DOM 把整个页面映射为一个多层的节点结构,HTML 或 XML 页面中的每个组成部分都是某种类型的节点,这些节点又包含着不同类型的数据。
W3C DOM 由以下三部分组成:
- 核心 DOM - 针对任何结构化文档的标准模型
- XML DOM - 针对 XML 文档的标准模型
- HTML DOM - 针对 HTML 文档的标准模型
通过 DOM 接口,应用程序可以在任何时候访问文档中的任何一部分数据,因此,这种利用 DOM 接口的机制也被称作随机访问机制。
1.2 DOM级别
DOM0
DOM0(即第 0 级 DOM),实际上指的是未形成标准的试验性质的初级阶段的 DOM。由于 DOM0 在 W3C 进行标准备化之前出现,还处于未形成标准的初期阶段,这时 Netscape 和 Microsoft 各自推出自己的第四代浏览器,自此 DOM 便开始出现各种问题。
DHTML
DHTML 是 Dynamic HTML(动态 HTML)的简称。DHTML 并不是一项新技术,而是将 HTML、CSS、JavaScript 技术组合的一种描述。即:
- 利用 HTML 把网页标记为各种元素
- 利用 CSS 设置元素样式及其显示位置
- 利用 JavaScript 操控页面元素和样式
利用 DHTML,看起来可以很容易的控制页面元素,并实现原本很复杂的效果(如:通过改变元素位置实现动画)。但事实并非如此,因为没有规范和标准,两种浏览器对相同功能的实现的确完全不一样。为了保持程序的兼容性,程序员必须写一些探查代码以检测 JavaScript 是运行于哪种浏览器之下,并提供与之对应的脚本。JavaScript 陷入了前所未有的混乱,DHTML 也因此在人们心中留下了很差的印象。
DOM1
在浏览器厂商进行浏览器大战的同时,W3C 结合各厂商的优点推出了一个标准化的 DOM,并于 1998 年 10 月完成了第一级 DOM,即:DOM1。W3C 将 DOM 定义为一个与平台和编程语言无关的接口,通过这个接口程序和脚本可以动态的访问和修改文档的内容、结构和样式。
DOM1 级主要定义了 HTML 和 XML 文档的底层结构。在 DOM1 中,DOM 由两个模块组成:
- DOM Core(DOM 核心):规定了基于 XML 的文档结构标准,通过这个标准简化了对文档中任意部分的访问和操作。
- DOM HTML:则在 DOM 核心的基础上加以扩展,添加了针对 HTML 的对象和方法,如:JavaScript 中的 Document 对象。
DOM2
在 DOM1 的基础上 DOM2 引入了更多的交互能力,也支持了更高级的 XML 特性。DOM2 将 DOM 分为更多具有联系的模块。DOM2 级在原来 DOM 的基础上又扩充了鼠标、用户界面事件、范围、遍历等细分模块,而且通过对象接口增加了对 CSS 的支持。DOM1 级中的 DOM 核心模块也经过扩展开始支持 XML 命名空间。在 DOM2 中引入了下列模块,在模块包含了众多新类型和新接口:
- DOM 视图(DOM Views):定义了跟踪不同文档视图的接口
- DOM 事件(DOM Events):定义了事件和事件处理的接口
- DOM 样式(DOM Style):定义了基于 CSS 为元素应用样式的接口
- DOM 遍历和范围(DOM Traversal and Range):定义了遍历和操作文档树的接口
DOM3
DOM3 级:进一步扩展了 DOM,引入了以统一方式加载和保存文档的方法,它在 DOM Load And Save 这个模块中定义;同时新增了验证文档的方法,是在 DOM Validation 这个模块中定义的。 DOM3 进一步扩展了 DOM,在 DOM3 中引入了以下模块:
- DOM 加载和保存模块(DOM Load and Save):引入了以统一方式加载和保存文档的方法
- DOM 验证模块(DOM Validation):定义了验证文档的方法
- DOM 核心的扩展(DOM Style):支持 XML 1.0 规范,涉及 XML Infoset、XPath 和 XML Base
1.3 文档类型
我们说 DOM 文档对象模型是从文档中抽象出来的,DOM 操作的对象也是文档,因此我们有必要了解一下文档的类型。文档随着历史的发展演变为多种类型,如下:

GML
GML(Generalized Markup Language,通用标记语言)是 1960 年代的一种 IBM 文档格式化语言,用于描述文档的组织结构、各部件及其相互关系。GML 在文档具体格式方面,为文档员提供了一些方便,他们不必再为 IBM 的打印机格式化语言 SCRIPT 要求的字体规范、行距以及页面设计等浪费精力。这个 IBM 的 GML 包括 1960 年代的 GML 和 1980 年代的 ISIL。
SGML
SGML(Standard Generalized Markup Language,标准通用标记语言)是 1986 年基于 IBM 的 GML 制定 ISO 标准(ISO 8879)。SGML 是现时常用的超文本格式的最高层次标准,是可以定义标记语言的元语言,甚至可以定义不必采用 "<>" 的常规方式。由于 SGML 的复杂,因而难以普及。HTML 和 XML 同样衍生于 SGML,XML 可以被认为是 SGML 的一个子集,而 HTML 是 SGML 的一个应用。
HTML
HTML(HyperText Markup Language,超文本标记语言)是为“网页创建和其它可在网页浏览器中看到的信息”设计的一种标记语言。HTML 被用来结构化信息——例如标题、段落和列表等等,也可用来在一定程度上描述文档的外观和语义。1982 年,蒂姆·伯纳斯-李为使世界各地的物理学家能够方便的进行合作研究,创建了使用于其系统的 HTML。之后 HTML 又不断地扩充和发展,成为国际标准,由万维网联盟(W3C)维护。第一个正式标准是 1995 年发布的 RFC 1866(HTML 2.0)。
XML
XML(eXtensible Markup Language,可扩展标记语言)是专家们使用 SGML 精简制作,并依照 HTML 的发展经验,产生出一套使用上规则严谨,但是简单的描述数据语言。XML 在 1995 年开始有雏形,在 1998 二月发布为 W3C 的标准(XML1.0)
XHTML
XHTML(eXtensible HyperText Markup Language,可扩展超文本标记语言)的表现方式与超文本标记语言(HTML)类似,不过语法上更加严格。从继承关系上讲,HTML 是一种基于标准通用标记语言(SGML)的应用,是一种非常灵活的置标语言,而 XHTML 则基于可扩展标记语言(XML),XML 是 SGML 的一个子集。XHTML 1.0 在 2000 年 1 月 26 日成为 W3C 的推荐标准。
2. DOM节点
2.1 DOM Nodes
根据 W3C 的 HTML DOM 标准,HTML 文档中的所有内容都是节点:
- 整个文档是一个文档节点
- 每个 HTML 元素是元素节点
- HTML 元素内的文本是文本节点
- 每个 HTML 属性是属性节点
- 注释是注释节点
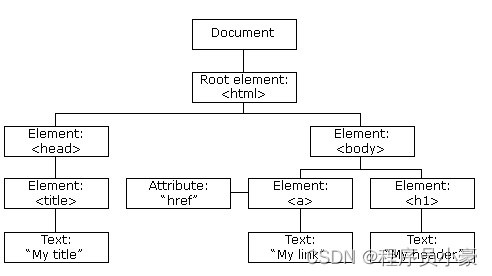
2.2 HTML DOM节点树
HTML DOM 将 HTML 文档视作树结构。这种结构被称为节点树:

2.3 节点关系
节点树中的节点彼此拥有层级关系。
我们常用父(parent)、**子(child)和同胞(sibling)**等术语来描述这些关系。父节点拥有子节点。同级的子节点被称为同胞(兄弟或姐妹)。
- 在节点树中,顶端节点被称为根(root)。
- 每个节点都有父节点、除了根(它没有父节点)。
- 一个节点可拥有任意数量的子节点。
- 同胞是拥有相同父节点的节点。
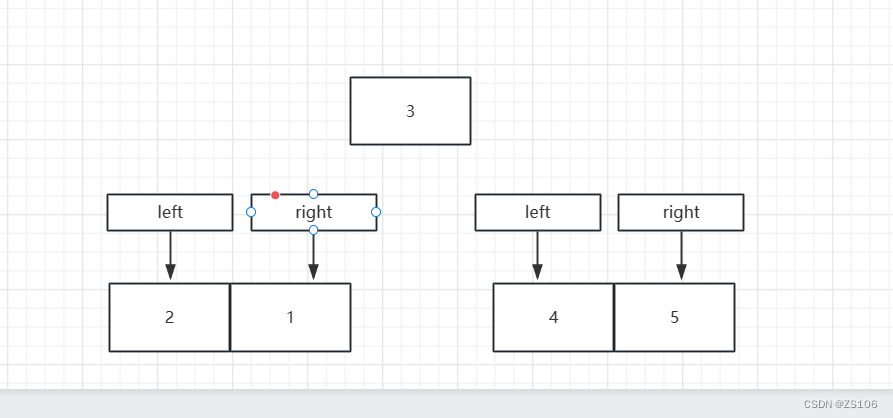
下面的图片展示了节点树的一部分,以及节点之间的关系:

2.3.1 节点关系辨认
<html><head><meta charset="utf-8"><title>DOM 教程</title></head><body><h1>DOM 课程1</h1><p>Hello world!</p></body>
</html>
从上面的 HTML 中:
<html>节点没有父节点;它是根节点<head>和<body>的父节点是<html>节点- 文本节点 “Hello world!” 的父节点是
<p>节点
并且:
<html>节点拥有两个子节点:<head>和<body><head>节点拥有两个子节点:<meta>与<title>节点<title>节点也拥有一个子节点:文本节点 “DOM 教程”<h1>和<p>节点是同胞节点,同时也是<body>的子节点
并且:
-
<head>元素是<html>元素的首个子节点 -
<body>元素是<html>元素的最后一个子节点 -
<h1>元素是<body>元素的首个子节点 -
元素是 元素的最后一个子节点
3. 查找DOM
现在我们了解了 DOM 文档是什么,接下来就可以开始获取我们的第一个 HTML 元素了。
3.1 按 ID 获取元素
getElementById() 方法用于通过其 id 获取单个元素。我们来看一个例子:
var title = document.getElementById(‘header-title’);
我们得到 id 为 header-title 的元素,并将其保存到变量中。
3.2 按类名获取元素
还可以用 getElementsByClassName() 方法获取多个对象,该方法返回一个元素数组。
var items = document.getElementsByClassName(‘list-items’);
这里我们得到类 list-items 的所有项目,并将它们保存到变量中。
3.3 按标签名称获取元素
还可以用 getElementsByClassName() 方法按标记名称获取元素。
var listItems = document.getElementsByTagName(‘li’);
这里我们获取 HTML 文档中所有得 li 元素并将它们保存到变量中。
Queryselector
querySelector()方法返回与指定的 CSS选择器匹配的第一个元素。这意味着你可以通过id、class、tag和所有其他有效的 CSS 选择器获取元素。在这里我列出了一些最常用的选项。
按 id 获取:
var header = document.querySelector(‘#header’)
按 class 获取:
var items = document.querySelector(‘.list-items’)
按标签获取:
var headings = document.querySelector(‘h1’);
获取更具体的元素:
我们还可以使用 CSS Selectors 获得更多的特定元素。
document.querySelector(“h1.heading”);
在这个例子中,我们同时搜索标记和类,并返回传递给 CSS Selector 的第一个元素。
Queryselectorall
querySelectorAll() 方法与 querySelector() 完全相同,只是它返回符合 CSS Selector 的所有元素。
var heading = document.querySelectorAll(‘h1.heading’);
在这个例子中,我们得到所有属于 heading 类的 h1 标签,并将它们存储在一个数组中。
4. DOM修改
HTML DOM 允许我们通过更改其属性来对 HTML 元素的内容和样式进行修改。
4.1 更改HTML
innerHTML 属性可用于修改 HTML 元素的内容。
document.getElementById(“#header”).innerHTML = “Hello World!”;
在这个例子中,我们得到 id 为 header 的元素,并把其内容设置为“Hello World!”。
InnerHTML 还可以把标签放入另一个标签中。
document.getElementsByTagName("div").innerHTML = "<h1>Hello World!</h1>"
在这里将 h1 标记放入所有已存在的 div 中。
4.2 更改属性的值
还可以用 DOM 更改属性的值。
document.getElementsByTag(“img”).src = “test.jpg”;
在这个例子中,我们把所有 <img/> 标签的 src 改为 test.jpg。
4.3 改变样式
要更改 HTML 元素的样式,需要更改元素的样式属性。以下是更改样式的示例语法:
document.getElementById(id).style.property = new style
接下来看一个例子,我们获取一个元素并将底部边框改为纯黑线:
document.getElementsByTag(“h1”).style.borderBottom = “solid 3px #000”;
CSS 属性需要用 camelcase 而不是普通的 css 属性名来编写。在这个例子中,我们用 borderBottom 而不是 border-bottom。
5. DOM元素的添加和删除
现在我们来看看如何添加新元素和删除现有元素。
5.1 添加元素
var div = document.createElement(‘div’);
在这里我们用了 createElement() 方法创建一个 div 元素,该方法将标记名作为参数并将其保存到变量中。之后只需要给它一些内容,然后将其插入到 DOM 文档中。
var content = document.createTextNode("Hello World!");
div.appendChild(newContent);
document.body.insertBefore(div, currentDiv);
这里用了 createTextNode() 方法创建内容,该方法用字符串作参数,然后在文档中已经存在的 div 之前插入新的 div 元素。
5.2 删除元素
var elem = document.querySelector('#header');
elem.parentNode.removeChild(elem);
本例中我们得到一个元素并使用 removeChild() 方法将其删除。
5.3 替换元素
现在让我们来看看怎样替换一个项目。
var div = document.querySelector('#div');
var newDiv = document.createElement(‘div’);
newDiv.innerHTML = "Hello World2"
div.parentNode.replaceChild(newDiv, div);
这里我们使用 replaceChild()方法替换元素。第一个参数是新元素,第二个参数是要替换的元素。
5.4 直接写入HTML输出流
还可以使用 write() 方法将 HTML 表达式和 JavaScript 直接写入 HTML 输出流。
document.write(“<h1>Hello World!</h1><p>This is a paragraph!</p>”);
我们也可以把像日期对象这样的参数传给 JavaScript 表达式。
document.write(Date());
write() 方法还可以使用多个参数,这些参数会按其出现的顺序附加到文档中。
6. DOM事件
HTML DOM 允许 Javascript 对 HTML 事件做出反应。下面列出了一些比较重要的事件:
- 鼠标点击
- 页面加载
- 鼠标移动
- 输入字段更改
6.1 分配事件
可以用标记上的属性直接在 HTML 代码中定义事件。以下是 onclick 事件的例子:
<h1 onclick=”this.innerHTML = ‘Hello!’”>Click me!</h1>
在此例中,单击按钮时,<h1/> 的文本将被改为 “Hello!”。
还可以在触发事件时调用函数,如下一个例子所示。
<h1 onclick=”changeText(this)”>Click me!</h1>
这里我们在单击按钮时调用 changeText() 方法,并将该元素作为属性传递。
还可以用 Javascript 代码为多个元素分配相同的事件。
document.getElementById(“btn”).onclick = changeText();
6.2 指定事件监听器
接下来看看怎样为 HTML 元素分配事件监听器。
document.getElementById(“btn”)addEventListener('click', runEvent);
这里我们刚刚指定了一个 click 事件,在单击 btn 元素时调用 runEvent 方法。
当然还可以把多个事件指定给单个元素:
document.getElementById(“btn”)addEventListener('mouseover', runEvent);
总结
通过本篇博客,我们已经初步了解了JavaScript DOM技术的基本概念和操作步骤。DOM允许我们使用JavaScript来动态地修改网页内容,实现交互性和动态性。希望这篇入门指南能够帮助前端新手更好地理解DOM技术,并为日后的学习和实践打下坚实的基础。在深入学习过程中,你会发现DOM的更多复杂和强大之处。
后续我们这个前端专栏还会讲述作用域、事件模型、内置对象、垃圾回收、js算法技巧等等文章,如果您感兴趣的话,欢迎点赞三连并关注我以及我的前端专栏,我们下期文章再见。