1【线程与进程的区别、协程】
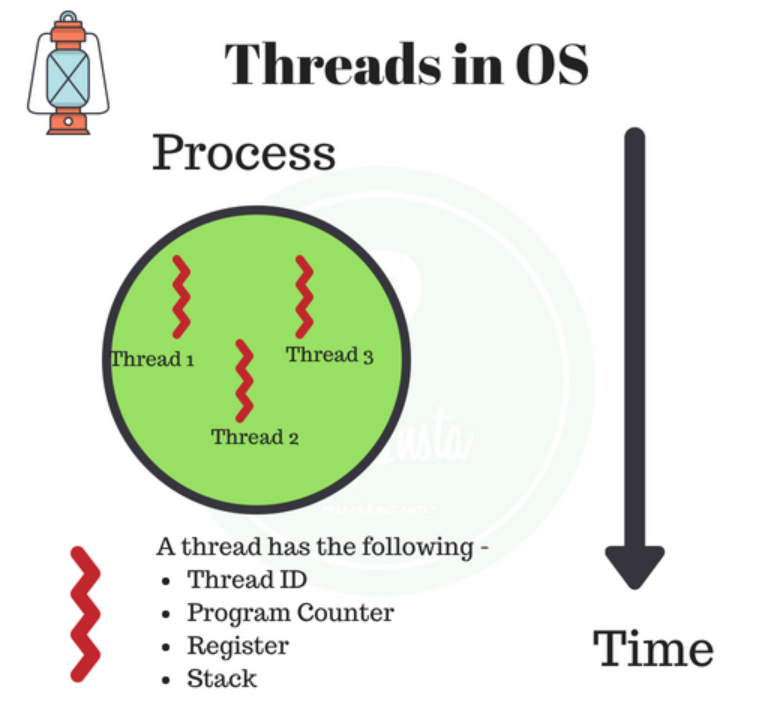
【1】 进程跟线程
进程(Process)和 线程(Thread)是操作系统的基本概念, 但是它们比较抽象, 不容易掌握。关于多进程和多线程,教科书上对经典的一句话“进程是资源分配的最小单位, 线程是CPU调度的最小单位。”
线程是程序中一个单一的顺序控制流程。
进程内一个相对独立的、可调度的执行的单元,是系统独立调度和分派CPU的基本单位指运行中的程序的调度单位。
在单个程序中同时运行多个线程完成不同的工作,称为多线程
【2】线程与进程的区别可以归纳为:
-
地址空间和其他资源(如打开文件):进程间互相独立, 同一进程的各线程间共享。某进程期内的线程在其他进程不可见。
-
通信:进程间通信IPC, 线程间可以直接读写进程数据段 (如全局变量)来进行通信--------需要进程同步和互斥手段的辅助, 以保证数据的一致性。
-
调度和切换: 线程上下文切换比进程上下文切换要快得多。
-
在多线程OS中, 进程不是一个可执行行的实体。
2【多线程和多进程的比较】
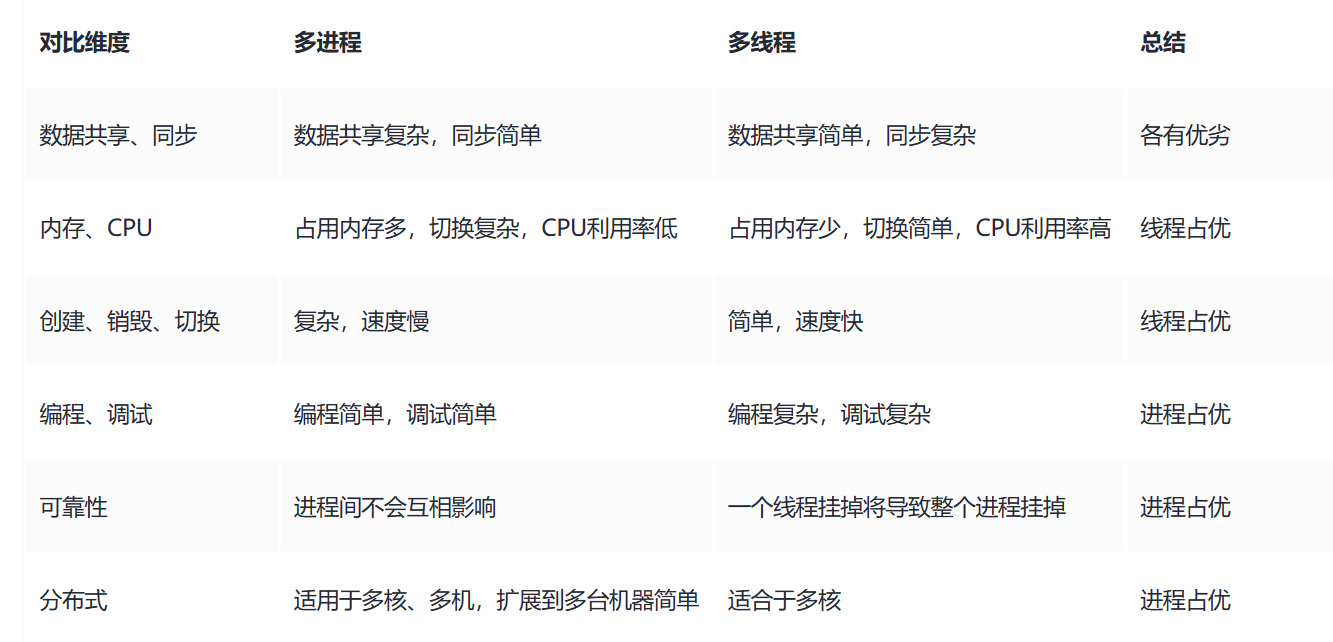
总结: 进程和线程可以类比为火车和车厢
-
线程在进程下行进(单纯的车厢无法运行)
-
一个进程可以包含多个线程(一辆火车可以有多个车厢)
-
不同进程间数据很难共享(一辆火车上的乘客很难换到另一辆火车, 比如站点换乘)
-
同一进程下不同线程间数据很易共享(A车厢换到B车厢很容易)
-
进程要比线程消耗更多的计算机资源(采用多列火车相比多个车厢更消耗资源)
-
进程间不会相互影响,一个线程挂掉了将会导致整个进程挂掉(一列火车火车不会影响到另一列火车, 但是如果一列火车上的一节车厢着火了,将会影响到该躺火车的所有车厢)
-
进程可以拓展到多机,进程最多适合多核(不同火车可以开在多个轨道上,统一火车的车厢不能在行进的不同的轨道上)
-
进程使用的内存地址可以上锁, 即一个线程使用某写共享内存是,其他线程必须等他结束, 才能使用这一块内存。 (比如火车上的洗手间)-“互斥锁(mutex)”
-
进程使用的内存地址可以限定使用量(比如火车上的餐厅,最多只允许多少人进入,如果满了需要在门口等,等有人出来了才能进去)-“信号量(semaphore)”
3【(为什么有了GIL锁还要互斥锁)】
是一种CPython解释器中使用的机制, 它保证统一时刻只有一个线程执行Python字节码。 这个锁的存在是为了简化CPython 的实现,因为Cpython 在设计之初并不考虑多线程的执行。
【1】注意:
GIL(全局解释器)只存在于CPython解释器中,同时Python解释器的一个特定实现。其他编程语言和环境没有这个概念。
因此在这些环境中可以自由的使用多线程来实现并进行计算。
【2】多线程环境中, Python虚拟机的执行方法:
-
设置GIL
-
切换到一个线程去执行
-
运行直至指定数量的字节码指令,或者线程主动让出控制(可以调用sleep(2))
-
把线程设置为睡眠状态
-
解锁GIL
-
再次重复以上所有步骤
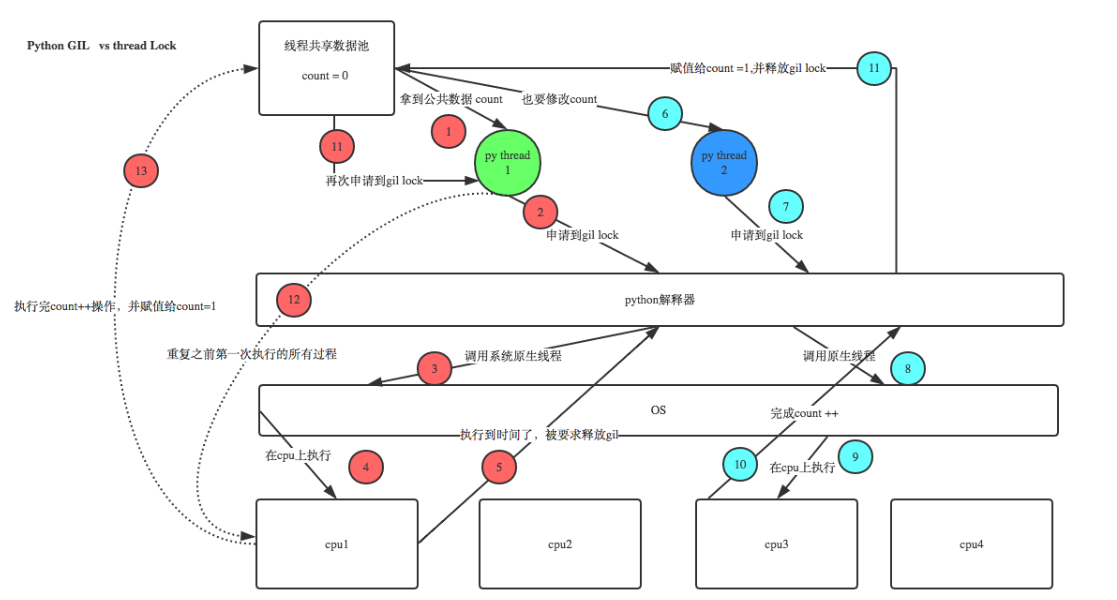
在单核CPU上,数百次的间隔检查才会导致一次线程切换。在多核CPU上,存在严重的线程颠簸(thrashing)。而每次释放GIL锁,线程进行锁竞争、切换线程,会消耗资源。单核下多线程,每次释放GIL,唤醒的那个线程都能获取到GIL锁,所以能够无缝执行,但多核下,CPU0释放GIL后,其他CPU上的线程都会进行竞争,但GIL可能会马上又被CPU0拿到,导致其他几个CPU上被唤醒后的线程会醒着等待到切换时间后又进入待调度状态,这样会造成线程颠簸(thrashing),导致效率更低。
在单核CPU上,由于只要一个核心执行代码,每次是否GIL后唤醒的线程都能够立即获取到GIL锁,因此可以实现无缝执行。
然而,在多核CPU上,由于存在多个核心同时执行代码,当一个核心释放GIL锁后,其他核心上的线程会竞争获取GIL锁。虽然GIL可能会马上又被原来持有的核心获取到,但其他核心上被唤醒后的线程会进入待调度状态等待切换时间。这样的竞争和切换过程可能导致线程颠簸(thrashing),从而降低性能效率。
简单的来说就是先到先的锁机制。单核可以实现无缝执行。多核则不行。
4【Python的多进程multiprocessing】
【1】前言
借助这个multiprocessing,你可以轻松完成从单进程到并发执行的转换。multiprocessing支持子进程、通信和共享数据、执行不同形式的同步,提供了Process、Queue、Pipe、Lock等组件。
【2】multiprocessing常用组件及中功能
创建管理进程模块:
-
Process(用于创建进程)
-
Pool(用于创建管理进程池)
-
Queue(用于进程通信,资源共享)
-
Value,Array(用于进程通信,资源共享)
-
Pipe(用于管道通信)
-
Manager(用于资源共享)
同步子进程模块:
-
Condition(条件变量)
-
Event(事件)
-
Lock(互斥锁)
-
RLock(可重入的互斥锁(同一个进程可以多次获得它,同时不会造成阻塞)
-
Semaphore(信号量)
【进程】Process 用于创建进程
multiprocessing模块提供了一个Process类来代表一个进程对象。
在multiprocessing中,每一个进程都用一个Process类来表示。
构造方法: Process([group [, target [, name [, args [, kwargs]]]]])
-
group: 分组,实际上不适用, 值始终为None
-
target:表示调用对象,即子进程要执行的任务,你可以传入方法名
-
name:为子进程设定名称
-
args: 要传给target函数的位置参数,以元组方式进行传入
-
kwargs:要传给target函数的字典参数,以字典方式传入
-
daemon:一个布尔值,用于设置进程是否为守护进程,守护进程会在主进程结束时会自动退出
from multiprocessing import Process
import time
def work(name, delay):print(f'启动 {name} 进程')time.sleep(delay)print(f'结束 {name} 进程')
if __name__ == '__main__':
processes = []
for i in range(5):p = Process(target = work, args=(f'工作-{i}', i))p.name = f'工作 - {i}'p.daemon = Trueprocesses.append(p)
p.start()p.join()
print('工作结束!')
#
# 启动 工作-0 进程
# 结束 工作-0 进程
# 工作结束!
# 启动 工作-1 进程
# 结束 工作-1 进程
# 工作结束!
# 启动 工作-2 进程
# 结束 工作-2 进程
# 工作结束!
# 启动 工作-3 进程
# 结束 工作-3 进程
# 工作结束!
# 启动 工作-4 进程
# 结束 工作-4 进程
# 工作结束!实例方法:
-
star():启动进程,并调用子进程中的p.run()
-
work():执行进程的target函数,通常不需要手动调用,在start() 方法内部自动调用。
-
join([timeout]):等待进程结束,可选参数timeout为超时时间,如果设置了且超过时间到达时进程仍然未结束,则会返回。
-
is_alive():返回进程是否正在执行。
-
name:进程的名称,可以通过该属性获取或设置进程的名称。
-
pid:进程的ID, 可以通过该属性获取进程的ID。
# 实例方法
import multiprocessing
import time
def worker():print(f'worker 启动 进程 {multiprocessing.current_process().name}')time.sleep(2)print(f'worker 结束 进程 {multiprocessing.current_process().name}')
if __name__ == '__main__':p = multiprocessing.Process(target=worker, name='工作进程')p.start()
print(f'这是进程的 {p.name} 是否执行 {p.is_alive()}')p.join()
print(f'这是进程的 {p.name} 是否执行 {p.is_alive()}')
print(f'结束进程{p.name} ')# 这是进程的 工作进程 是否执行 True
# worker 启动 进程 工作进程
# worker 结束 进程 工作进程
# 这是进程的 工作进程 是否执行 False
# 结束进程工作进程 【3】Pool (创建进程池)
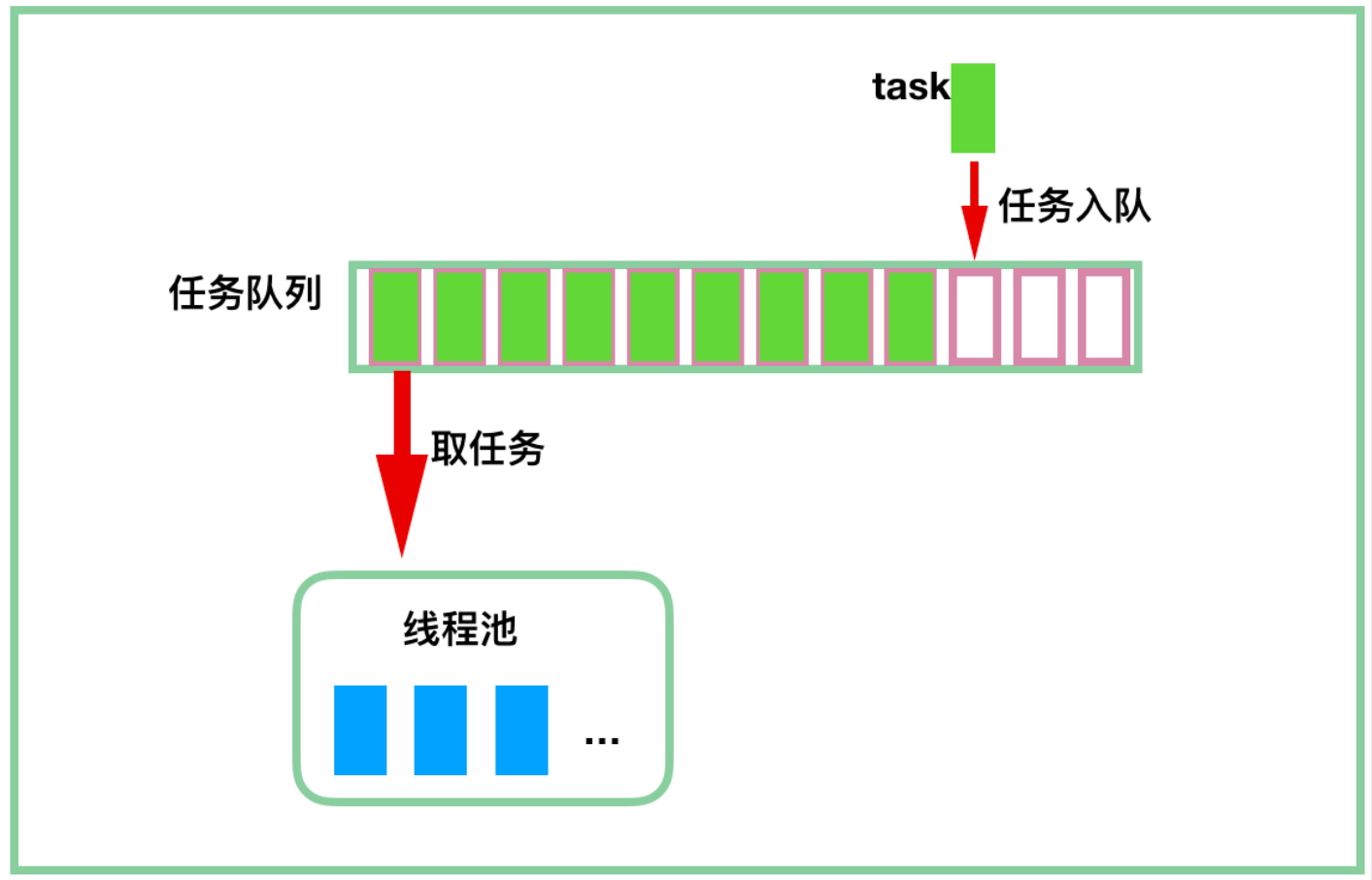
进程池是一种常见的并发编程工具,可以看作一个公共类或者公共资源,用于管理和复用进程。它提供了一种方便来创建、调度和执行多个进程, 并提供接口来提交任务、获取任务结果等操作。
在使用进程池是, 开发者可以将需要执行的任务提交给进程池,进程池会自动分配可用的进程来执行任务。这样可以避免重复创建和销毁进程的开销,提高应用程序的性能和效率。
进程池的特点:
-
可以预先创建一定数量的进程,减少创建和销毁进程的开销。
-
提高接口来提交任务, 并将任务分配给空闲的进程来执行。
-
可以限制同时执行的任务数量,以控制并发。
-
提供接口来获取任务的执行的结果。
构造方法:
Pool([processes[, initializer[, initargs[, maxtasksperchild[, context]]]]])
-
processes:指定进程池中的进程数量,默认为None,表示使用系统的 CPU 核心数; -
initializer:一个可调用对象,用于在每个子进程启动时调用,用于初始化子进程; -
initargs:一个元组,作为initializer函数的参数传递给子进程; -
maxtasksperchild:指定每个子进程最多执行的任务数,默认为None,表示不限制任务数; -
context:指定一个上下文对象,用于创建子进程,默认为None,表示使用默认的上下文对象。
进程池的实例方法:
-
apply(func, args=(), kwds={}):阻塞地提交一个任务,等待任务完成并返回结果。-
func是要执行的函数; -
args是传递给函数的位置参数,必须是一个元组; -
kwds是传递给函数的关键字参数,必须是一个字典。
-
-
map(func, iterable, chunksize=None):将一个可迭代对象中的所有元素应用到同一个函数上,并返回结果列表,按照可迭代对象中元素的顺序排列。-
func是要执行的函数; -
iterable是要处理的可迭代对象; -
chunksize是每个子进程处理的任务数量,默认为None,表示使用默认的块大小。
-
-
imap(func, iterable, chunksize=None):与map()方法类似,但是它返回一个迭代器,可以一次获取一个结果。-
func是要执行的函数; -
iterable是要处理的可迭代对象; -
chunksize是每个子进程处理的任务数量,默认为None,表示使用默认的块大小。
-
# 实例方法
import multiprocessing
def run(x):return x ** 2 ,f'跑了这些时间!'
if __name__ == '__main__':with multiprocessing.Pool(processes=4) as pool:res1 = pool.apply(run,(10,))
res2 = pool.map(run,range(10))
res3 = pool.imap(run, range(10))
for i in res3:print(i)# (0, '跑了这些时间!')
# (1, '跑了这些时间!')
# (4, '跑了这些时间!')
# (9, '跑了这些时间!')
# (16, '跑了这些时间!')
# (25, '跑了这些时间!')
# (36, '跑了这些时间!')
# (49, '跑了这些时间!')
# (64, '跑了这些时间!')
# (81, '跑了这些时间!')异步提交:
import multiprocessing
def my_func(arg):# 进程要执行的任务pass
if __name__ == "__main__":# 获取Context对象context = multiprocessing.get_context()
# 创建进程池with context.Pool(4) as pool:# 异步提交任务给进程池result = pool.apply_async(my_func, (1,))# 阻塞主进程等待任务完成output = result.get()print(output)同步提交:
import multiprocessing
def my_func(arg):# 进程要执行的任务pass
if __name__ == "__main__":# 获取Context对象context = multiprocessing.get_context()
# 创建进程池with context.Pool(4) as pool:# 同步提交任务给进程池output = pool.apply(my_func, (1,))print(output)【5】协程
综上所述:线程才是执行单位
协程的基础使用
这是 python 3.7 里面的基础协程用法,现在这种用法已经基本稳定,不太建议使用之前的语法了。
【1】yield关键字
-
yield可以保存状态
-
yield的状态保存与操作系统的保存线程状态很像,但是yield是代码级别控制的,更轻量级。
-
-
send可以把一个函数的结果传给另一个函数
-
以此实现单线程内程序之间的切换。
-
注意:单纯地切换反而会降低运行效率。
【2】创建协程的两种方法
生成器
def my_coroutine():while True:value = yield # 接收从调用方传递过来的值print('收到:', value)
# 创建生成器对象
coroutine = my_coroutine()
# 启动生成器
next(coroutine)
# 发送数据到生成器
coroutine.send('Hello')
coroutine.send('World')
# 关闭生成器
coroutine.close()asyncio库
import asyncio
async def my_coroutine():print('coroutine started')await asyncio.sleep(1)print('coroutine ended')
asyncio.run(my_coroutine()) # 使用 asyncio.run() 运行协程
# coroutine started
# coroutine ended并发、并行、同步和异步
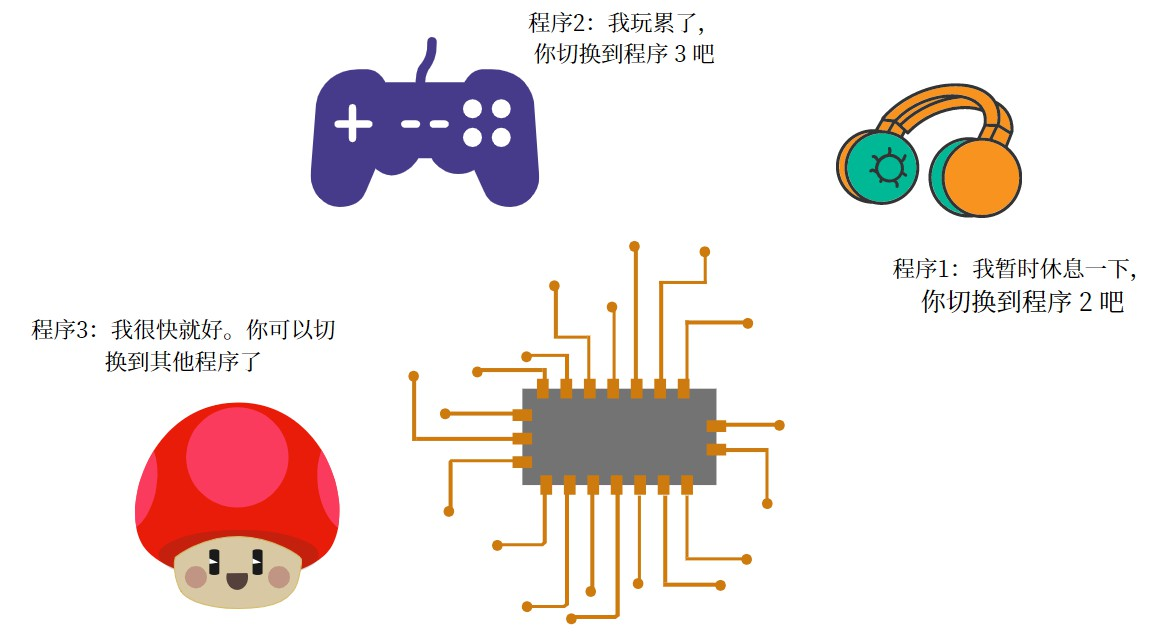
并发指的是 一个 CPU 同时处理多个程序,但是在同一时间点只会处理其中一个。并发的核心是:程序切换。
但是因为程序切换的速度非常快,1 秒钟内可以完全很多次程序切换,肉眼无法感知。
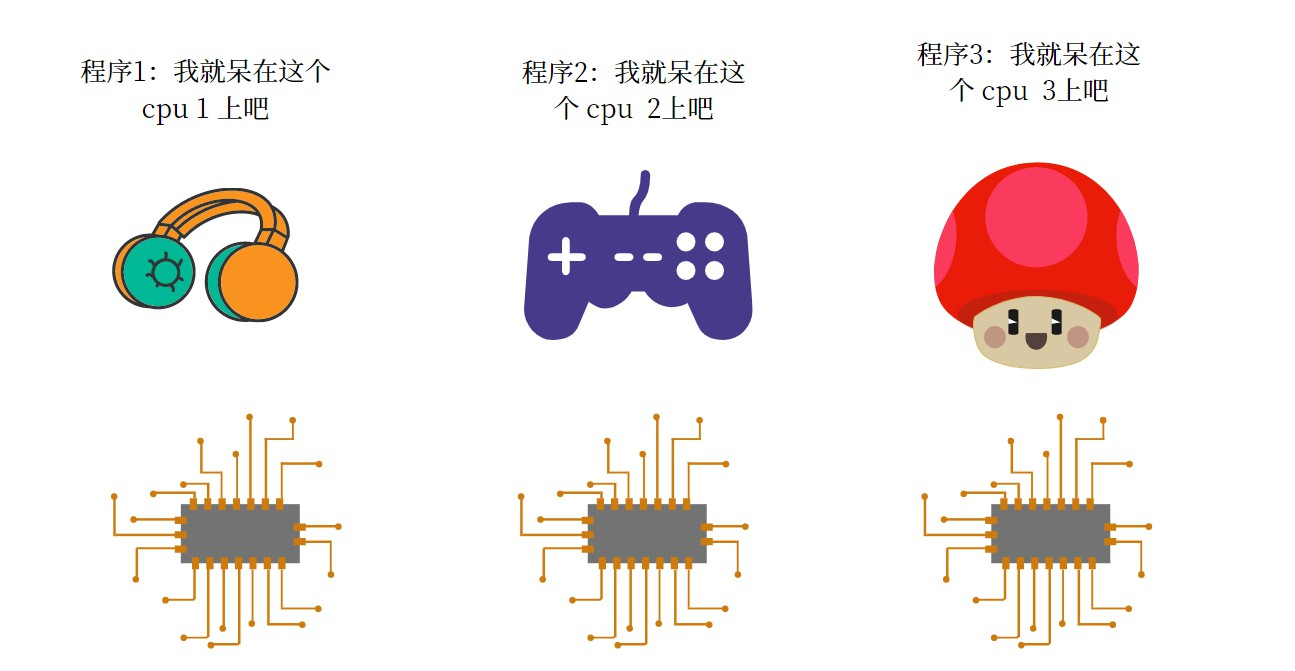
并行指的是多个 CPU 同时处理多个程序,同一时间点可以处理多个。
同步:执行 IO 操作时,必须等待执行完成才得到返回结果。 异步:执行 IO 操作时,不必等待执行就能得到返回结果。
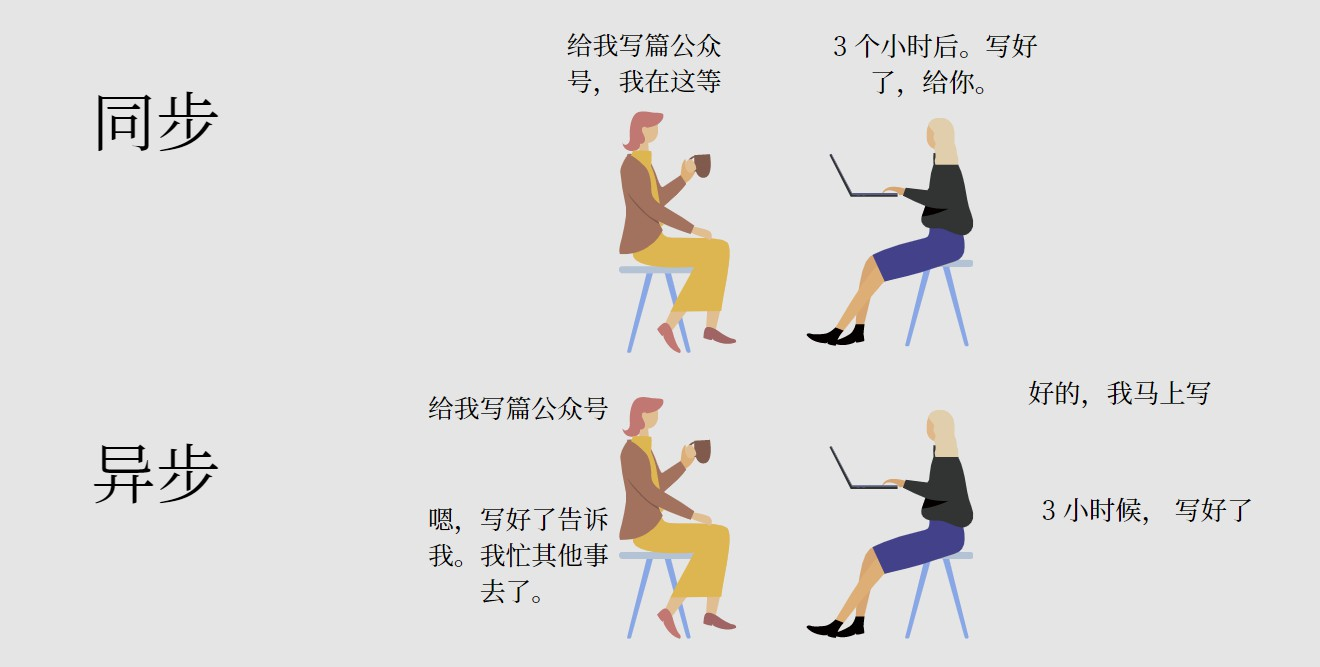
协程,线程和进程的区别
多进程通常利用的是多核 CPU 的优势,同时执行多个计算任务。每个进程有自己独立的内存管理,所以不同进程之间要进行数据通信比较麻烦。
多线程是在一个 cpu 上创建多个子任务,当某一个子任务休息的时候其他任务接着执行。多线程的控制是由 python 自己控制的。 子线程之间的内存是共享的,并不需要额外的数据通信机制。但是线程存在数据同步问题,所以要有锁机制。
协程的实现是在一个线程内实现的,相当于流水线作业。由于线程切换的消耗比较大,所以对于并发编程,可以优先使用协程。
协程的主要使用场景
协程的主要应用场景是 IO 密集型任务,总结几个常见的使用场景:
- 网络请求,比如爬虫,大量使用 aiohttp
- 文件读取, aiofile
- web 框架, aiohttp, fastapi
- 数据库查询, asyncpg, databases