实现多分支逻辑的场景通常可以使用以下几种技术手段可以选择
if-else语句switch语句- 三元运算符(只能实现2个分支的场景,本文不做讨论)
- 映射表(
std::map、数组或std::vector) - 多态(策略模式为例)
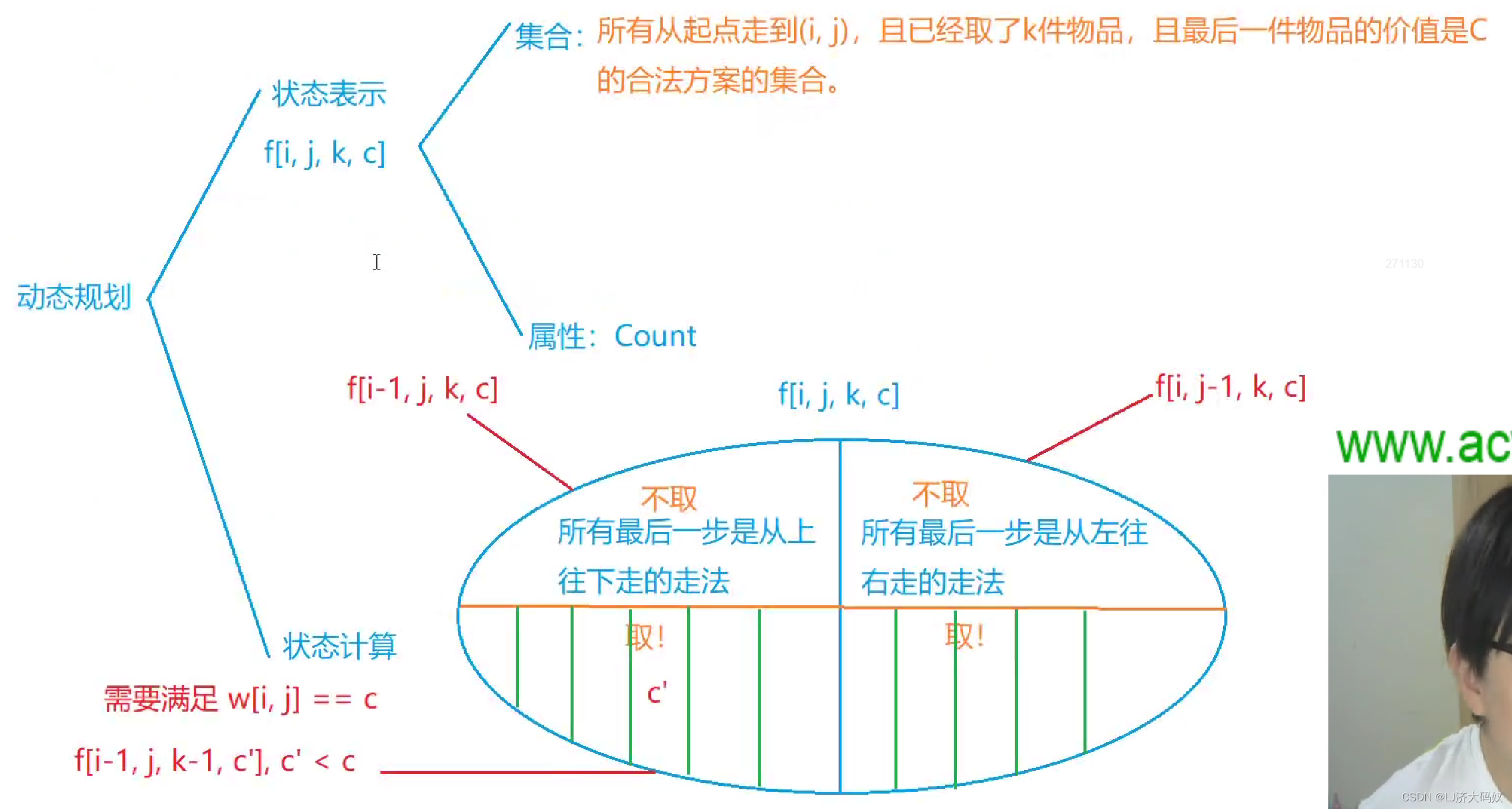
其他几种手段不必多说,多态是面向对象的一个重要概念,本文以策略模式为例比较多态与其他几种多分支技术的区别。策略模式的一般形式如下
struct Strategy {virtual void execute() = 0;
};struct ConcreteStrategy1 : Strategy {void execute() override { // code block 1 }
};struct ConcreteStrategy2 : Strategy {void execute() override { // code block 2 }
};// Context class that uses the strategy
class Context {
public:Context(Strategy& s) : strategy(s) {}void execute() { strategy.execute(); }Strategy& strategy;
};// Usage
Context context(new ConcreteStrategy1());
context.execute();在实际编码中该如何选择使用哪一种技术手段呢?我们先对这几种技术做个简单的比较
| 技术手段 | 分支条件 & 灵活性 | 动态性 | 性能 |
|---|---|---|---|
if-else语句 | 支持多种条件组合,灵活性很高 | 不支持动态扩展 | 差 |
switch语句 | 单一条件 | 不支持动态扩展 | 优 |
映射表(数组或std::vector) | 单一条件 | 可动态扩展 | 优 |
映射表(std::map) | 单一条件 | 可动态扩展 | 差 |
| 多态 | 单一条件,灵活性高 | 可动态扩展 | 优 |
分支条件
显然,if-else语句几乎在任何场景中都可以使用,因为它的分支条件很灵活而且是可以组合的。而其他几种技术的分支条件都只支持单一条件,只能根据一个变量的值选择分支,而且分支条件的变量类型也有限制
switch语句:分支条件的类型可以是 整数类型、枚举类型、字符类型几种。浮点数、字符串等无法直接作为分支条件,自定义类型重载了比较操作符后也可以作为分支条件。- 映射表(数组或
std::vector):分支条件的类型只能是整数类型,并且分支需要是紧密排列的。这种技术就是利用数组形成映射表,然后用数组下标查询分支。 - 映射表(
std::map):分支条件的类型就是std::map的key的类型。作为key的类型,要求满足严格的弱序关系(支持 < 运算符,并且且运算符定义的比较是可传递的),自定义类型重载了小于号操作符后也可以作为key。 - 多态:分支条件实际上就是子类(策略)的类型,不同子类的实例触发的分支自然是不一样的。
动态性
动态性是指运行时分支是否可变(增加分支或者减少分支),显然if-else语句和switch语句无法做到运行时可变,而其余几种则是支持的。
性能对比
关于性能我们先看一组数据。下面是不同分支数量情况下,执行500次查询的耗时情况(测试方法见本文最后的 性能数据采集方法)。

随着分支数量增加if-else语句和std::map版本的耗时逐渐增多,switch语句和多态版本的耗时则相对稳定地保持在很低的水平。
关于性能的结论很明显,但是…为什么呢?理解四种技术各自的原理后就会得到答案
if-else语句:if-else编译后汇编码对应一系列test指令,每次查询分支都会逐一测试分支条件直至成功命中后中断查询。分支越多查询的平均耗时越长。现代编译器的流水线技术还会提供分支预测能力,这有助于提升性能,但如果分支预测失败代价也会很高。
switch语句:编译器使用跳转表技术将switch语句转换为数组形式,每次查询分支相当于一次寻址操作,查询耗时理论上和分支多少没关系。
映射表(数组或std::vector):数组形式的映射表没统计在内,因为数组形式的映射表技术是编译器实现switch语句的原理,每次查询分支就是一次数组取值操作,查询耗时理论上和分支多少没关系。感兴趣的同学可以使用文末的方法自己采集数据观察。
映射表(std::map):每次查询分支实际上就是一次查表操作。std::map内部是用红黑树实现的,查询耗时与树大小有关,所以分支越多查询的平均耗时越长。
多态:c++多态是使用虚函数实现的,每次查询分支实际上对应一次查虚函数表的操作,相当于两次寻址操作,所以查询耗时理论上和分支多少没关系。
如何选择
本人原则:简单编码。在当前情形下,哪种技术用起来更简单(编码少、易读)就用哪个。另外有两个方面可能会特别注意
- 扩展性:
std::map和多态的扩展性更好,在分支量大或者分支改动频繁的情况下会优先考虑。 - 性能:分支较多时
if-else语句和std::map的性能表现较差,当性能成为瓶颈的时候考虑使用其他形式替代。
性能数据采集方法
使用下面的python脚本生成不同分支数量的cpp代码,然后编译、运行并观察结果。注意编译时使用-O0选项关闭编译器优化。
import randomBASE_CODE = """
#include <stddef.h>
#include <stdio.h>
#include <vector>
#include <functional>
#include <map>
#include <chrono>
#include <thread>struct Strategy {virtual int GetValue() { return -1; }static Strategy& GetInst(int value);
} strategy_base;struct Data {Data(int value) : _value(value), strategy(Strategy::GetInst(value)) { }int _value;Strategy& strategy;
};long long CalculateElapsedTime(std::vector<Data>& input, std::function<int(const Data&)> func) {auto startTime = std::chrono::high_resolution_clock::now();std::vector<int> res(input.size());for (int index = 0; index < input.size(); ++index) {res[index] = func(input[index]);}auto endTime = std::chrono::high_resolution_clock::now();long long elapsedTime = std::chrono::duration_cast<std::chrono::microseconds>(endTime - startTime).count();return elapsedTime;
}"""def CodeIfElse(num):left = "{"right = "}"print("int TransIfElse(const Data& input) {")print(" int res = -1;")for i in range(num):branchStr = "if" if i == 0 else "else if"print(f" {branchStr} (input._value == {i}) {left}")print(f" res = {100 + i};")print(f" {right}")print(" return res;")print("}")def CodeSwitches(num):print("int TransWithSwitch(const Data& input) {")print(" int res = -1;")print(" switch(input._value) {")for i in range(num):print(f" case {i}:")print(f" res = {100 + i};")print(f" break;")print(f" default:")print(f" break;")print(" }")print(" return res;")print("}")def CodeMap(num):left = "{"right = "}"print("int TransWithSTDMap(const Data& input) {")print(" static std::map<int, int> valuMap = {")for i in range(num):print(f" {left}{i}, {100 + i}{right},")print(" };")print(" if (valuMap.find(input._value) == valuMap.end()) {")print(" return -1;")print(" }")print(" int res = valuMap[input._value];")print(" return res;")print("}")print("")def codeList(num):print("int TransWithSTVector(const Data& input) {")print(" static std::vector<int> valueVector = {")for i in range(num):print(f" {100 + i},")print(" };")print(" if (valueVector.size() <= input._value) {")print(" return -1;")print(" }")print(" return valueVector[input._value];")print("}")print("")def CodeStrategy(num):left = "{"right = "}"print(f"static const int HANDLER_INST_NUM = {num};")for i in range(num):print(f"struct SubHandler_{i} : public Strategy {left} virtual int GetValue() {left} return {100 + i}; {right}{right} strategy_{i};")print("")print("Strategy& Strategy::GetInst(int value) {")print(" if (value >= 0 && value < HANDLER_INST_NUM) {")print(" return *(&strategy_0 + value);")print(" }")print(" return strategy_base;")print("}")print("")print("int TransWithStrategy(const Data& input) {")print(" int res = input.strategy.GetValue();")print(" return res;")print("}")print("")def CodeInput(rangeRight, num):random_numbers = [random.randint(0, rangeRight + 1) for _ in range(num)]inputData = " std::vector<Data> input = { "for i in range(len(random_numbers)):if i != 0 and i % 50 == 0:inputData += "\n "inputData += f"{random_numbers[i]}, "inputData += "};"print(inputData)def code(branchNum):print(BASE_CODE)CodeIfElse(branchNum)CodeSwitches(branchNum)CodeMap(branchNum)codeList(branchNum)CodeStrategy(branchNum)print("int main() {")CodeInput(branchNum, 500)print(""" long long timeIfElse = CalculateElapsedTime(input, TransIfElse);""")print(""" printf("===> timeIfElse: %-lld us\\n", timeIfElse);""")print(""" long long timeSwitch = CalculateElapsedTime(input, TransWithSwitch);""")print(""" printf("===> timeSwitch: %-lld us\\n", timeSwitch);""")print(""" long long timeSTDMap = CalculateElapsedTime(input, TransWithSTDMap);""")print(""" printf("===> timeSTDMap: %-lld us\\n", timeSTDMap);""")print(""" long long timeVector = CalculateElapsedTime(input, TransWithSTVector);""")print(""" printf("===> timeVector: %-lld us\\n", timeVector);""")print(""" long long timeStrategy = CalculateElapsedTime(input, TransWithStrategy);""")print(""" printf("===> timeStrategy: %-lld us\\n", timeStrategy);""")print("""}""")import sys
if __name__ == "__main__":args = sys.argvbranchNumber = 2 if len(args) <= 1 else int(args[1])code(branchNumber)完整的生成代码、编译、运行命令如下
# 生成分支数为20的cpp,如需生成分支数为50的版本,将下面的20改为50即可
python3 Coder.py 20 > Main.cpp# 编译
g++ Main.cpp -std=c++11 -O0 -o test# 运行
./test