Pytorch从零开始实战——Pix2Pix理论与实战
本系列来源于365天深度学习训练营
原作者K同学
文章目录
- Pytorch从零开始实战——Pix2Pix理论与实战
- 内容介绍
- 数据集加载
- 模型实现
- 开始训练
- 总结
内容介绍
Pix2Pix是一种用于用于图像翻译的通用框架,即图像到图像的转换。它在生成对抗网络的框架下进行训练。Pix2Pix的目标是将输入图像转换为输出图像,例如将黑白线稿转换为彩色图像,或者将地图转换为卫星图像等。Pix2Pix模型的训练通常需要大量的配对数据,即包含输入图像与相应输出图像的数据集。
图像内容:指的是图像的固有内容,它是区分不同图像的依据。
图像域:指在特定上下文中所涵盖的一组图像的集合,这些图像通常具有某种相似性或共同特征。图像域可以用来表示一类具有共同属性或内容的图像。在图像处理和计算机视觉领域,图像域常常被用于描述参与某项任务或问题的图像集合。
图像翻译:是将一个物体的图像表征转换为该物体的另一个表征,例如根据皮包的轮廓图得到皮包的彩色图。也就是找到一个函数,能让域A的图像映射到域B,从而实现图像的跨域转换。
Pix2Pix的三个核心技术:
基于CGAN的损失函数:CGAN是Conditional Generative Adversarial Network的缩写,它将条件信息(如输入图像)作为生成器和判别器的输入,以帮助生成器生成更加逼真的输出。Pix2Pix使用了基于条件GAN的损失函数来指导生成器生成与目标图像更加接近的输出。
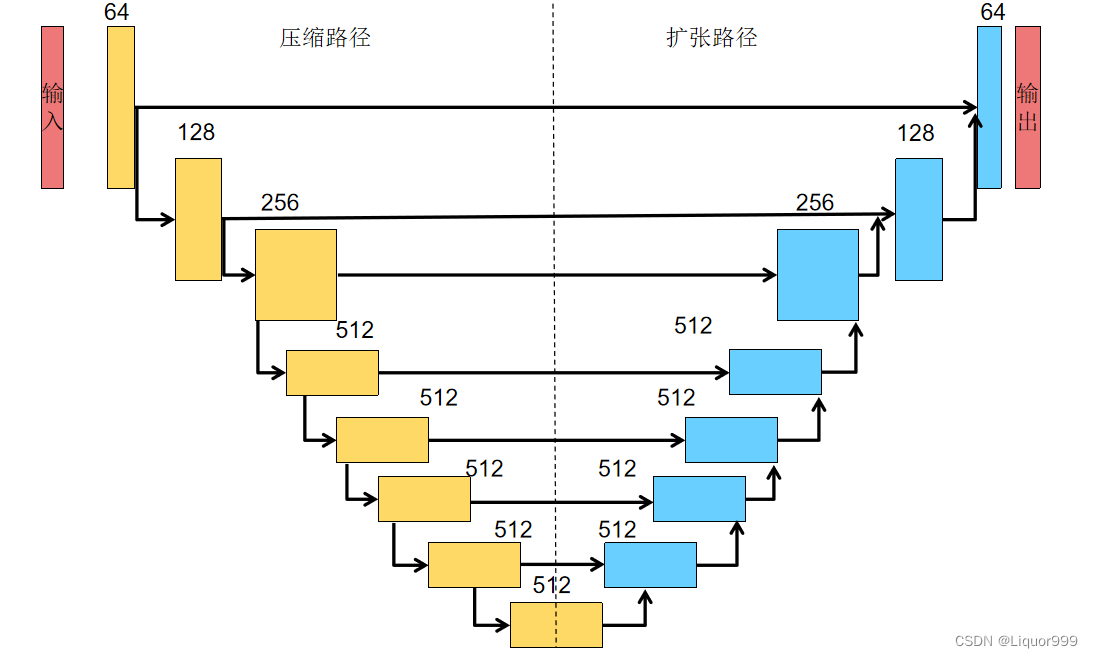
基于U-Net的生成器:U-Net是一种用于图像分割的卷积神经网络结构,它由编码器和解码器组成,通过跳跃连接将低级特征与高级特征相结合,有助于保留更多的图像细节。Pix2Pix中的生成器采用了U-Net结构,以实现图像到图像的转换。
下图为Pix2Pix的生成器的网络结构。
基于PatchGAN的判别器:PatchGAN是一种判别器的设计,对图像中的局部区域进行分类。Pix2Pix提出了将输入图像分成个图像块,这有助于提高模型对细节的感知,并使得判别器更能够捕捉到图像的局部结构信息。Pix2Pix使用了基于PatchGAN的判别器来评估生成的图像的真实度。
数据集加载
定义了一个自定义的数据集类ImageDataset,用于加载图像数据集。
import glob
import random
import os
import numpy as np
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transformsclass ImageDataset(Dataset):def __init__(self, root, transforms_=None, mode="train"):self.transform = transforms.Compose(transforms_)self.files = sorted(glob.glob(os.path.join(root, mode) + "/*.*"))if mode == "train":self.files.extend(sorted(glob.glob(os.path.join(root, "test") + "/*.*")))def __getitem__(self, index):img = Image.open(self.files[index % len(self.files)])w, h = img.sizeimg_A = img.crop((0, 0, w / 2, h))img_B = img.crop((w / 2, 0, w, h))if np.random.random() < 0.5:img_A = Image.fromarray(np.array(img_A)[:, ::-1, :], "RGB")img_B = Image.fromarray(np.array(img_B)[:, ::-1, :], "RGB")img_A = self.transform(img_A)img_B = self.transform(img_B)return {"A": img_A, "B": img_B}def __len__(self):return len(self.files)
模型实现
下面代码定义了一个U-Net生成器和一个PatchGAN鉴别器。
import torch.nn as nn
import torch.nn.functional as F
import torch
def weights_init_normal(m):classname = m.__class__.__name__if classname.find("Conv") != -1:torch.nn.init.normal_(m.weight.data, 0.0, 0.02)elif classname.find("BatchNorm2d") != -1:torch.nn.init.normal_(m.weight.data, 1.0, 0.02)torch.nn.init.constant_(m.bias.data, 0.0)UNetDown 类和 UNetUp 类:这些类定义了 U-Net 结构中的下采样和上采样部分的层次。UNetDown 类用于定义 U-Net 的下采样部分,它包括卷积层、归一化层、激活函数层和丢弃层。UNetUp 类定义了 U-Net 的上采样部分,它包括转置卷积层、归一化层、激活函数层和丢弃层。
GeneratorUNet 类:这是整个 U-Net 生成器的定义。它利用了之前定义的 UNetDown 和 UNetUp 类来构建一个完整的 U-Net 网络。在 init方法中,它初始化了 U-Net 的各个层次,并在 forward 方法中定义了数据在网络中的传播方式。
class UNetDown(nn.Module):def __init__(self, in_size, out_size, normalize=True, dropout=0.0):super(UNetDown, self).__init__()layers = [nn.Conv2d(in_size, out_size, 4, 2, 1, bias=False)]if normalize:layers.append(nn.InstanceNorm2d(out_size))layers.append(nn.LeakyReLU(0.2))if dropout:layers.append(nn.Dropout(dropout))self.model = nn.Sequential(*layers)def forward(self, x):return self.model(x)class UNetUp(nn.Module):def __init__(self, in_size, out_size, dropout=0.0):super(UNetUp, self).__init__()layers = [nn.ConvTranspose2d(in_size, out_size, 4, 2, 1, bias=False),nn.InstanceNorm2d(out_size),nn.ReLU(inplace=True),]if dropout:layers.append(nn.Dropout(dropout))self.model = nn.Sequential(*layers)def forward(self, x, skip_input):x = self.model(x)x = torch.cat((x, skip_input), 1)return xclass GeneratorUNet(nn.Module):def __init__(self, in_channels=3, out_channels=3):super(GeneratorUNet, self).__init__()self.down1 = UNetDown(in_channels, 64, normalize=False)self.down2 = UNetDown(64, 128)self.down3 = UNetDown(128, 256)self.down4 = UNetDown(256, 512, dropout=0.5)self.down5 = UNetDown(512, 512, dropout=0.5)self.down6 = UNetDown(512, 512, dropout=0.5)self.down7 = UNetDown(512, 512, dropout=0.5)self.down8 = UNetDown(512, 512, normalize=False, dropout=0.5)self.up1 = UNetUp(512, 512, dropout=0.5)self.up2 = UNetUp(1024, 512, dropout=0.5)self.up3 = UNetUp(1024, 512, dropout=0.5)self.up4 = UNetUp(1024, 512, dropout=0.5)self.up5 = UNetUp(1024, 256)self.up6 = UNetUp(512, 128)self.up7 = UNetUp(256, 64)self.final = nn.Sequential(nn.Upsample(scale_factor=2),nn.ZeroPad2d((1, 0, 1, 0)),nn.Conv2d(128, out_channels, 4, padding=1),nn.Tanh(),)def forward(self, x):# U-Net generator with skip connections from encoder to decoderd1 = self.down1(x)d2 = self.down2(d1)d3 = self.down3(d2)d4 = self.down4(d3)d5 = self.down5(d4)d6 = self.down6(d5)d7 = self.down7(d6)d8 = self.down8(d7)u1 = self.up1(d8, d7)u2 = self.up2(u1, d6)u3 = self.up3(u2, d5)u4 = self.up4(u3, d4)u5 = self.up5(u4, d3)u6 = self.up6(u5, d2)u7 = self.up7(u6, d1)return self.final(u7)
discriminator_block 函数:这个函数定义了 PatchGAN 判别器中的一个“块”,包括一个卷积层、一个归一化层和一个 LeakyReLU 激活函数。
Discriminator 类:这是整个 PatchGAN 判别器的定义。它由一系列卷积层和 LeakyReLU 激活函数层组成,用于从图像对中提取特征,并输出一个判别值,表示输入图像对是真实对还是生成对。
class Discriminator(nn.Module):def __init__(self, in_channels=3):super(Discriminator, self).__init__()def discriminator_block(in_filters, out_filters, normalization=True):"""Returns downsampling layers of each discriminator block"""layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]if normalization:layers.append(nn.InstanceNorm2d(out_filters))layers.append(nn.LeakyReLU(0.2, inplace=True))return layersself.model = nn.Sequential(*discriminator_block(in_channels * 2, 64, normalization=False),*discriminator_block(64, 128),*discriminator_block(128, 256),*discriminator_block(256, 512),nn.ZeroPad2d((1, 0, 1, 0)),nn.Conv2d(512, 1, 4, padding=1, bias=False))def forward(self, img_A, img_B):# Concatenate image and condition image by channels to produce inputimg_input = torch.cat((img_A, img_B), 1)return self.model(img_input)开始训练
主要功能包括:
1.解析命令行参数:使用argparse.ArgumentParser()解析命令行参数,包括训练所需的超参数、数据集名称等。
2.定义生成器和判别器模型:使用之前定义的GeneratorUNet和Discriminator类创建模型。
3.配置优化器:使用Adam优化器来优化生成器和判别器的参数。
4.加载数据集:使用PyTorch的DataLoader加载训练和验证数据集。
5.定义损失函数:定义了GAN损失和像素级别的L1损失。
6.训练过程:使用双重循环进行训练,其中外层循环遍历每个epoch,内层循环遍历每个batch。在每个batch内,首先训练生成器,然后训练判别器。训练过程中,会打印损失信息以及训练的进度。
7.保存模型和生成示例图像:在每个epoch结束时,会保存生成器和判别器的模型参数,并周期性地生成一些示例图像以供可视化和评估模型效果。
import argparse
import time
import datetime
import sysimport torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torch.autograd import Variablefrom models import *
from datasets import *import torch.nn as nn
import torch.nn.functional as F
import torchparser = argparse.ArgumentParser()
parser.add_argument("--epoch", type=int, default=0, help="epoch to start training from")
parser.add_argument("--n_epochs", type=int, default=100, help="number of epochs of training")
parser.add_argument("--dataset_name", type=str, default="data_facades", help="name of the dataset")
parser.add_argument("--batch_size", type=int, default=1, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--decay_epoch", type=int, default=100, help="epoch from which to start lr decay")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--img_height", type=int, default=256, help="size of image height")
parser.add_argument("--img_width", type=int, default=256, help="size of image width")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=500, help="interval between sampling of images from generators"
)
parser.add_argument("--checkpoint_interval", type=int, default=-1, help="interval between model checkpoints")
opt = parser.parse_args()
print(opt)os.makedirs("images/%s" % opt.dataset_name, exist_ok=True)
os.makedirs("saved_models/%s" % opt.dataset_name, exist_ok=True)cuda = True if torch.cuda.is_available() else False# Loss functions
criterion_GAN = torch.nn.MSELoss()
criterion_pixelwise = torch.nn.L1Loss()# Loss weight of L1 pixel-wise loss between translated image and real image
lambda_pixel = 100# Calculate output of image discriminator (PatchGAN)
patch = (1, opt.img_height // 2 ** 4, opt.img_width // 2 ** 4)# Initialize generator and discriminator
generator = GeneratorUNet()
discriminator = Discriminator()if cuda:generator = generator.cuda()discriminator = discriminator.cuda()criterion_GAN.cuda()criterion_pixelwise.cuda()if opt.epoch != 0:# Load pretrained modelsgenerator.load_state_dict(torch.load("saved_models/%s/generator_%d.pth" % (opt.dataset_name, opt.epoch)))discriminator.load_state_dict(torch.load("saved_models/%s/discriminator_%d.pth" % (opt.dataset_name, opt.epoch)))
else:# Initialize weightsgenerator.apply(weights_init_normal)discriminator.apply(weights_init_normal)# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))# Configure dataloaders
transforms_ = [transforms.Resize((opt.img_height, opt.img_width), Image.BICUBIC),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]dataloader = DataLoader(ImageDataset("./%s" % opt.dataset_name, transforms_=transforms_),batch_size=opt.batch_size,shuffle=True,num_workers=opt.n_cpu,
)val_dataloader = DataLoader(ImageDataset("./%s" % opt.dataset_name, transforms_=transforms_, mode="val"),batch_size=10,shuffle=True,num_workers=1,
)# Tensor type
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensordef sample_images(batches_done):"""Saves a generated sample from the validation set"""imgs = next(iter(val_dataloader))real_A = Variable(imgs["B"].type(Tensor))real_B = Variable(imgs["A"].type(Tensor))fake_B = generator(real_A)img_sample = torch.cat((real_A.data, fake_B.data, real_B.data), -2)save_image(img_sample, "images/%s/%s.png" % (opt.dataset_name, batches_done), nrow=5, normalize=True)# ----------
# Training
# ----------if __name__ == '__main__':prev_time = time.time()for epoch in range(opt.epoch, opt.n_epochs):for i, batch in enumerate(dataloader):# Model inputsreal_A = Variable(batch["B"].type(Tensor))real_B = Variable(batch["A"].type(Tensor))# Adversarial ground truthsvalid = Variable(Tensor(np.ones((real_A.size(0), *patch))), requires_grad=False)fake = Variable(Tensor(np.zeros((real_A.size(0), *patch))), requires_grad=False)# ------------------# Train Generators# ------------------optimizer_G.zero_grad()# GAN lossfake_B = generator(real_A)pred_fake = discriminator(fake_B, real_A)loss_GAN = criterion_GAN(pred_fake, valid)# Pixel-wise lossloss_pixel = criterion_pixelwise(fake_B, real_B)# Total lossloss_G = loss_GAN + lambda_pixel * loss_pixelloss_G.backward()optimizer_G.step()# ---------------------# Train Discriminator# ---------------------optimizer_D.zero_grad()# Real losspred_real = discriminator(real_B, real_A)loss_real = criterion_GAN(pred_real, valid)# Fake losspred_fake = discriminator(fake_B.detach(), real_A)loss_fake = criterion_GAN(pred_fake, fake)# Total lossloss_D = 0.5 * (loss_real + loss_fake)loss_D.backward()optimizer_D.step()# --------------# Log Progress# --------------# Determine approximate time leftbatches_done = epoch * len(dataloader) + ibatches_left = opt.n_epochs * len(dataloader) - batches_donetime_left = datetime.timedelta(seconds=batches_left * (time.time() - prev_time))prev_time = time.time()# Print logsys.stdout.write("\r[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f, pixel: %f, adv: %f] ETA: %s"% (epoch,opt.n_epochs,i,len(dataloader),loss_D.item(),loss_G.item(),loss_pixel.item(),loss_GAN.item(),time_left,))# If at sample interval save imageif batches_done % opt.sample_interval == 0:sample_images(batches_done)if opt.checkpoint_interval != -1 and epoch % opt.checkpoint_interval == 0:# Save model checkpointstorch.save(generator.state_dict(), "saved_models/%s/generator_%d.pth" % (opt.dataset_name, epoch))torch.save(discriminator.state_dict(), "saved_models/%s/discriminator_%d.pth" % (opt.dataset_name, epoch))训练结果

总结
Pix2Pix模型在许多领域都有广泛的应用,可以用于许多任务,如将黑白图像转换为彩色图像、将语义标签转换为真实图像、图像超分辨率等。 由于Pix2Pix使用了生成对抗网络,生成的图像可以在一定程度上理解为真实图像与生成图像之间的差异,使得生成结果更具可解释性。
Pix2Pix的训练通常需要大量的配对数据,即包含输入图像与相应输出图像的数据集,以获得更好的性能和生成效果。
并且,Pix2Pix模型的训练较为复杂,需要精细调节超参数、选择合适的损失函数以及处理训练不稳定等问题。