目录
一、实验
1.环境
2.Linux 部署 HDFS 分布式集群
3.Linux 使用 HDFS 文件系统
二、问题
1.ssh-copy-id 报错
2. 如何禁用ssh key 检测
3.HDFS有哪些配置文件
4.hadoop查看版本报错
5.启动集群报错
6.hadoop 的启动和停止命令
7.上传文件报错
8.HDFS 使用命令
一、实验
1.环境
(1)主机
表1 主机
| 主机 | 架构 | 软件 | 版本 | IP | 备注 |
| hadoop | NameNode SecondaryNameNode | hadoop | 2.7.7 | 192.168.204.50 | |
| node01 | DataNode | hadoop | 2.7.7 | 192.168.204.51 | |
| node02 | DataNode | hadoop | 2.7.7 | 192.168.204.52 | |
| node03 | DataNode | hadoop | 2.7.7 | 192.168.204.53 |
(2)安全机制
查看
[root@localhost ~]# sestatus
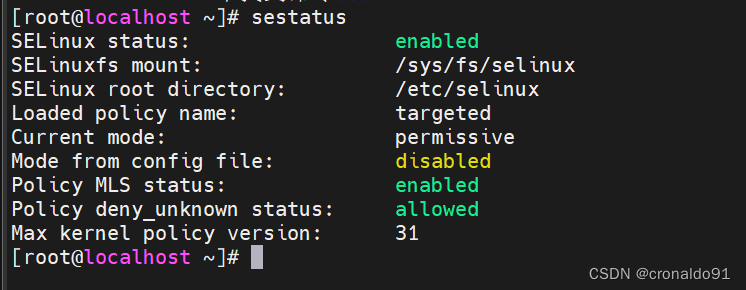
关闭
[root@localhost ~]# vim /etc/selinux/config
……
SELINUX=disabled
……

再次查看(需要reboot重启)
[root@localhost ~]# sestatus

(3)防火墙
关闭
[root@localhost ~]# systemctl stop firewalld
[root@localhost ~]# systemctl mask firewalld

(4)安装java
[root@localhost ~]# yum install -y java-1.8.0-openjdk-devel.x86_64

查看
[root@localhost ~]# jps
hadoop

node01

node02

node03

(5)域名主机名
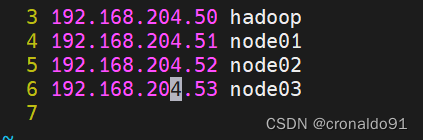
[root@localhost ~]# vim /etc/hosts
……
192.168.205.50 hadoop
192.168.205.51 node01
192.168.205.52 node02
192.168.205.53 node03
![]()
(6)修改主机名
[root@localhost ~]# hostnamectl set-hostname 主机名
[root@localhost ~]# bash




(7)hadoop节点创建密钥
[root@hadoop ~]# mkdir /root/.ssh
[root@hadoop ~]# cd /root/.ssh/
[root@hadoop .ssh]# ssh-keygen -t rsa -b 2048 -N ''

(8)添加免密登录
[root@hadoop .ssh]# ssh-copy-id -i id_rsa.pub hadoop[root@hadoop .ssh]# ssh-copy-id -i id_rsa.pub node01[root@hadoop .ssh]# ssh-copy-id -i id_rsa.pub node02[root@hadoop .ssh]# ssh-copy-id -i id_rsa.pub node03




2.Linux 部署 HDFS 分布式集群
(1)官网
https://hadoop.apache.org/查看版本
https://archive.apache.org/dist/hadoop/common/(2)下载
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
(3) 解压
tar -zxf hadoop-2.7.7.tar.gz
(3)移动
mv hadoop-2.7.7 /usr/local/hadoop
(4)更改权限
chown -R root.root hadoop

(5)验证版本
(需要修改环境配置文件hadoop-env.sh 申明JAVA安装路径和hadoop配置文件路径)
修改配置文件
[root@hadoop hadoop]# vim hadoop-env.sh



验证
[root@hadoop hadoop]# ./bin/hadoop version

(6)修改节点配置文件
[root@hadoop hadoop]# vim slaves

修改前:

修改后:
node01node02node03
(7)查看官方文档
https://hadoop.apache.org/docs/指定版本
https://hadoop.apache.org/docs/r2.7.7/
查看核心配置文件
https://hadoop.apache.org/docs/r2.7.7/hadoop-project-dist/hadoop-common/core-default.xml文件系统配置参数:

数据目录配置参数:

(8)修改核心配置文件
[root@hadoop hadoop]# vim core-site.xml
![]()
修改前:

修改后:
<configuration><property><name>fs.defaultFS</name><value>hdfs://hadoop:9000</value><description>hdfs file system</description></property><property><name>hadoop.tmp.dir</name><value>/var/hadoop</value></property></configuration>

(9)查看HDFS配置文件
https://hadoop.apache.org/docs/r2.7.7/hadoop-project-dist/hadoop-hdfs/hdfs-default.xmlnamenode:

![]()
副本数量:

(10)修改HDFS配置文件
[root@hadoop hadoop]# vim hdfs-site.xml
![]()
修改前:

修改后:
<configuration><property><name>dfs.namenode.http-address</name><value>hadoop:50070</value><name>dfs.namenode.secondary.http-address</name><value>hadoop:50090</value><name>dfs.replication</name><value>2</value></property>
</configuration>

(11) 查看同步
[root@hadoop ~]# rpm -q rsync

同步
[root@hadoop ~]# rsync -aXSH --delete /usr/local/hadoop node01:/usr/local/
[root@hadoop ~]# rsync -aXSH --delete /usr/local/hadoop node02:/usr/local/
[root@hadoop ~]# rsync -aXSH --delete /usr/local/hadoop node03:/usr/local/

(12)初始化hdfs
[root@hadoop ~]# mkdir /var/hadoop

(13)查看命令
[root@hadoop hadoop]# ./bin/hdfs
Usage: hdfs [--config confdir] [--loglevel loglevel] COMMANDwhere COMMAND is one of:dfs run a filesystem command on the file systems supported in Hadoop.classpath prints the classpathnamenode -format format the DFS filesystemsecondarynamenode run the DFS secondary namenodenamenode run the DFS namenodejournalnode run the DFS journalnodezkfc run the ZK Failover Controller daemondatanode run a DFS datanodedfsadmin run a DFS admin clienthaadmin run a DFS HA admin clientfsck run a DFS filesystem checking utilitybalancer run a cluster balancing utilityjmxget get JMX exported values from NameNode or DataNode.mover run a utility to move block replicas acrossstorage typesoiv apply the offline fsimage viewer to an fsimageoiv_legacy apply the offline fsimage viewer to an legacy fsimageoev apply the offline edits viewer to an edits filefetchdt fetch a delegation token from the NameNodegetconf get config values from configurationgroups get the groups which users belong tosnapshotDiff diff two snapshots of a directory or diff thecurrent directory contents with a snapshotlsSnapshottableDir list all snapshottable dirs owned by the current userUse -help to see optionsportmap run a portmap servicenfs3 run an NFS version 3 gatewaycacheadmin configure the HDFS cachecrypto configure HDFS encryption zonesstoragepolicies list/get/set block storage policiesversion print the versionMost commands print help when invoked w/o parameters.

(14)格式化hdfs
[root@hadoop hadoop]# ./bin/hdfs namenode -format



查看目录
[root@hadoop hadoop]# cd /var/hadoop/
[root@hadoop hadoop]# tree .
.
└── dfs└── name└── current├── fsimage_0000000000000000000├── fsimage_0000000000000000000.md5├── seen_txid└── VERSION3 directories, 4 files

(15) 启动集群
查看目录
[root@hadoop hadoop]# cd ~
[root@hadoop ~]# cd /usr/local/hadoop/
[root@hadoop hadoop]# ls

启动
[root@hadoop hadoop]# ./sbin/start-dfs.sh

查看日志(新生成logs目录)
[root@hadoop hadoop]# cd logs/ ; ll

查看jps
[root@hadoop hadoop]# jps

datanode节点查看(node01)


datanode节点查看(node02)


datanode节点查看(node03)


(16)查看命令
[root@hadoop hadoop]# ./bin/hdfs dfsadmin
Usage: hdfs dfsadmin
Note: Administrative commands can only be run as the HDFS superuser.[-report [-live] [-dead] [-decommissioning]][-safemode <enter | leave | get | wait>][-saveNamespace][-rollEdits][-restoreFailedStorage true|false|check][-refreshNodes][-setQuota <quota> <dirname>...<dirname>][-clrQuota <dirname>...<dirname>][-setSpaceQuota <quota> [-storageType <storagetype>] <dirname>...<dirname>][-clrSpaceQuota [-storageType <storagetype>] <dirname>...<dirname>][-finalizeUpgrade][-rollingUpgrade [<query|prepare|finalize>]][-refreshServiceAcl][-refreshUserToGroupsMappings][-refreshSuperUserGroupsConfiguration][-refreshCallQueue][-refresh <host:ipc_port> <key> [arg1..argn][-reconfig <datanode|...> <host:ipc_port> <start|status>][-printTopology][-refreshNamenodes datanode_host:ipc_port][-deleteBlockPool datanode_host:ipc_port blockpoolId [force]][-setBalancerBandwidth <bandwidth in bytes per second>][-fetchImage <local directory>][-allowSnapshot <snapshotDir>][-disallowSnapshot <snapshotDir>][-shutdownDatanode <datanode_host:ipc_port> [upgrade]][-getDatanodeInfo <datanode_host:ipc_port>][-metasave filename][-triggerBlockReport [-incremental] <datanode_host:ipc_port>][-help [cmd]]Generic options supported are
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-fs <local|namenode:port> specify a namenode
-jt <local|resourcemanager:port> specify a ResourceManager
-files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster
-libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.
-archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines.The general command line syntax is

(17)验证集群
查看报告,发现3个节点
[root@hadoop hadoop]# ./bin/hdfs dfsadmin -report
Configured Capacity: 616594919424 (574.25 GB)
Present Capacity: 598915952640 (557.78 GB)
DFS Remaining: 598915915776 (557.78 GB)
DFS Used: 36864 (36 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0-------------------------------------------------
Live datanodes (3):Name: 192.168.204.53:50010 (node03)
Hostname: node03
Decommission Status : Normal
Configured Capacity: 205531639808 (191.42 GB)
DFS Used: 12288 (12 KB)
Non DFS Used: 5620584448 (5.23 GB)
DFS Remaining: 199911043072 (186.18 GB)
DFS Used%: 0.00%
DFS Remaining%: 97.27%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Thu Mar 14 10:30:18 CST 2024Name: 192.168.204.51:50010 (node01)
Hostname: node01
Decommission Status : Normal
Configured Capacity: 205531639808 (191.42 GB)
DFS Used: 12288 (12 KB)
Non DFS Used: 6028849152 (5.61 GB)
DFS Remaining: 199502778368 (185.80 GB)
DFS Used%: 0.00%
DFS Remaining%: 97.07%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Thu Mar 14 10:30:18 CST 2024Name: 192.168.204.52:50010 (node02)
Hostname: node02
Decommission Status : Normal
Configured Capacity: 205531639808 (191.42 GB)
DFS Used: 12288 (12 KB)
Non DFS Used: 6029533184 (5.62 GB)
DFS Remaining: 199502094336 (185.80 GB)
DFS Used%: 0.00%
DFS Remaining%: 97.07%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Thu Mar 14 10:30:18 CST 2024

(18)web页面验证
http://192.168.204.50:50070/
http://192.168.204.50:50090/
http://192.168.204.51:50075/
(19)访问系统

目前为空

3.Linux 使用 HDFS 文件系统
(1)查看命令
[root@hadoop hadoop]# ./bin/hadoop
Usage: hadoop [--config confdir] [COMMAND | CLASSNAME]CLASSNAME run the class named CLASSNAMEorwhere COMMAND is one of:fs run a generic filesystem user clientversion print the versionjar <jar> run a jar filenote: please use "yarn jar" to launchYARN applications, not this command.checknative [-a|-h] check native hadoop and compression libraries availabilitydistcp <srcurl> <desturl> copy file or directories recursivelyarchive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archiveclasspath prints the class path needed to get thecredential interact with credential providersHadoop jar and the required librariesdaemonlog get/set the log level for each daemontrace view and modify Hadoop tracing settingsMost commands print help when invoked w/o parameters.

[root@hadoop hadoop]# ./bin/hadoop fs
Usage: hadoop fs [generic options][-appendToFile <localsrc> ... <dst>][-cat [-ignoreCrc] <src> ...][-checksum <src> ...][-chgrp [-R] GROUP PATH...][-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...][-chown [-R] [OWNER][:[GROUP]] PATH...][-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>][-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>][-count [-q] [-h] <path> ...][-cp [-f] [-p | -p[topax]] <src> ... <dst>][-createSnapshot <snapshotDir> [<snapshotName>]][-deleteSnapshot <snapshotDir> <snapshotName>][-df [-h] [<path> ...]][-du [-s] [-h] <path> ...][-expunge][-find <path> ... <expression> ...][-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>][-getfacl [-R] <path>][-getfattr [-R] {-n name | -d} [-e en] <path>][-getmerge [-nl] <src> <localdst>][-help [cmd ...]][-ls [-d] [-h] [-R] [<path> ...]][-mkdir [-p] <path> ...][-moveFromLocal <localsrc> ... <dst>][-moveToLocal <src> <localdst>][-mv <src> ... <dst>][-put [-f] [-p] [-l] <localsrc> ... <dst>][-renameSnapshot <snapshotDir> <oldName> <newName>][-rm [-f] [-r|-R] [-skipTrash] <src> ...][-rmdir [--ignore-fail-on-non-empty] <dir> ...][-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]][-setfattr {-n name [-v value] | -x name} <path>][-setrep [-R] [-w] <rep> <path> ...][-stat [format] <path> ...][-tail [-f] <file>][-test -[defsz] <path>][-text [-ignoreCrc] <src> ...][-touchz <path> ...][-truncate [-w] <length> <path> ...][-usage [cmd ...]]Generic options supported are
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-fs <local|namenode:port> specify a namenode
-jt <local|resourcemanager:port> specify a ResourceManager
-files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster
-libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.
-archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines.The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions]

(2)查看文件目录
[root@hadoop hadoop]# ./bin/hadoop fs -ls /

(3)创建文件夹
[root@hadoop hadoop]# ./bin/hadoop fs -mkdir /devops

查看

查看web

(4)上传文件
[root@hadoop hadoop]# ./bin/hadoop fs -put *.txt /devops/

查看
[root@hadoop hadoop]# ./bin/hadoop fs -ls /devops/

查看web
Permission Owner Group Size Last Modified Replication Block Size Name
-rw-r--r-- root supergroup 84.4 KB 2024/3/14 11:05:33 2 128 MB LICENSE.txt
-rw-r--r-- root supergroup 14.63 KB 2024/3/14 11:05:34 2 128 MB NOTICE.txt
-rw-r--r-- root supergroup 1.33 KB 2024/3/14 11:05:34 2 128 MB README.txt
下载

(5)创建文件
[root@hadoop hadoop]# ./bin/hadoop fs -touchz /tfile
![]()
查看
[root@hadoop hadoop]# ./bin/hadoop fs -ls /

(5)下载文件
[root@hadoop hadoop]# ./bin/hadoop fs -get /tfile /tmp/
![]()
查看
[root@hadoop hadoop]# ls -l /tmp/ | grep tfile

查看web
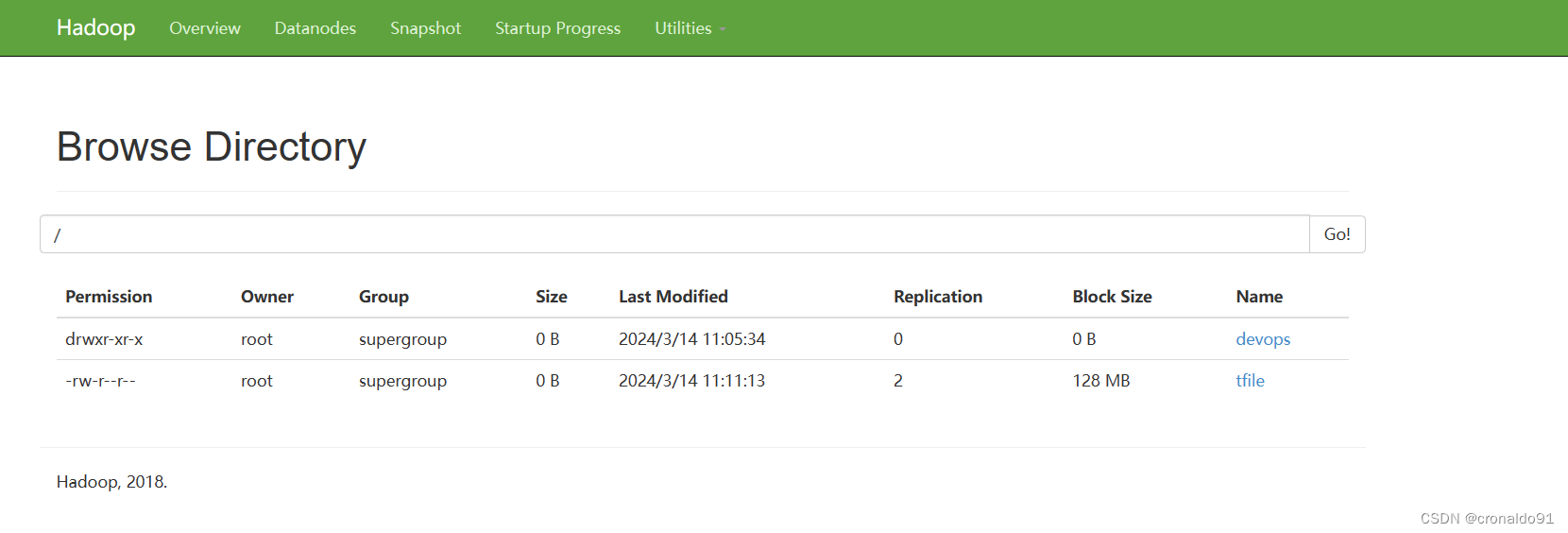
(6) 查看命令比较
之前的设置
![]()
所以查看功能相同
[root@hadoop hadoop]# ./bin/hadoop fs -ls /[root@hadoop hadoop]# ./bin/hadoop fs -ls hdfs://hadoop:9000/

另外官网默认是file ,使用的是本地文件目录
[root@hadoop hadoop]# ./bin/hadoop fs -ls file:///

二、问题
1.ssh-copy-id 报错
(1)报错
/usr/bin/ssh-copy-id: ERROR: ssh: connect to host hadoop port 22: Connection refused

(2)原因分析
主机解析错误。
(3)解决方法
修改前:

修改后:
成功:
2. 如何禁用ssh key 检测
(1)修改配置文件
[root@hadoop .ssh]# vim /etc/ssh/ssh_config
![]()
添加配置
StrictHostKeyChecking no

成功:

3.HDFS有哪些配置文件
(1)配置文件
1)环境配置文件
hadoop-env.sh2)核心配置文件
core-site.xml3)HDFS配置文件
hdfs-site.xml4)节点配置文件
slaves4.hadoop查看版本报错
(1) 报错

(2)原因分析
未申明JAVA环境。
(3)解决方法
申明JAVA环境。
查看
rpm -ql java-1.8.0-openjdk
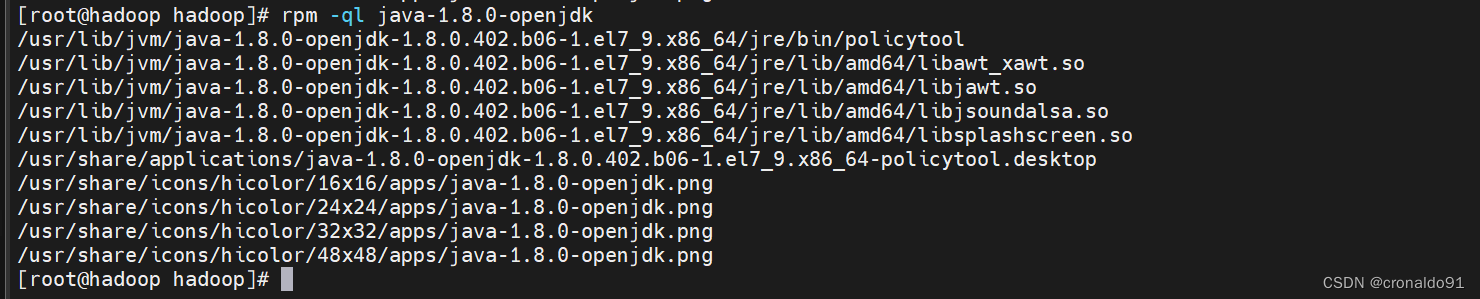
确定JAVA环境
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.402.b06-1.el7_9.x86_64/jre确定配置路径
/usr/local/hadoop/etc/hadoop修改配置文件
[root@hadoop hadoop]# vim hadoop-env.sh
修改前:


修改后:
成功:
[root@hadoop hadoop]# ./bin/hadoop version
5.启动集群报错
(1)报错
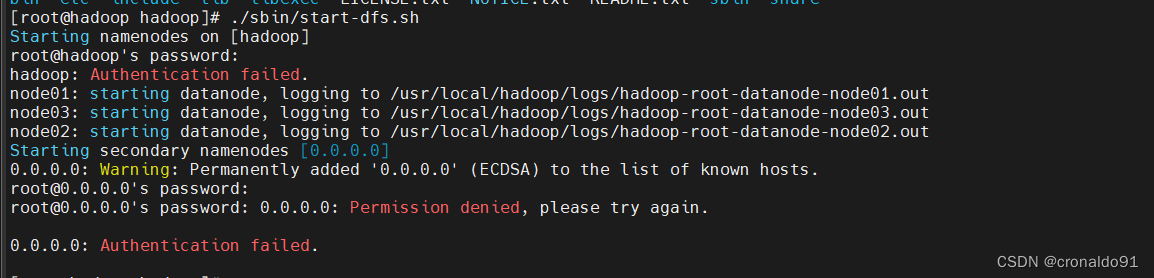
(2)原因分析
ssh-copy-id 未对本地主机验证。
(3)解决方法
ssh-copy-id 对本地主机验证。
[root@hadoop hadoop]# ssh-copy-id hadoop

如继续报错

需要停止Hadoop HDFS守护进程NameNode、SecondaryNameNode和DataNode
[root@hadoop hadoop]# ./sbin/stop-dfs.sh
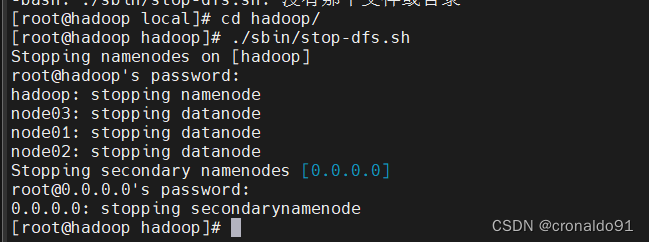
再次启动

6.hadoop 的启动和停止命令
(1)命令
sbin/start-all.sh 启动所有的Hadoop守护进程。包括NameNode、 Secondary NameNode、DataNode、ResourceManager、NodeManager
sbin/stop-all.sh 停止所有的Hadoop守护进程。包括NameNode、 Secondary NameNode、DataNode、ResourceManager、NodeManager
sbin/start-dfs.sh 启动Hadoop HDFS守护进程NameNode、SecondaryNameNode、DataNode
sbin/stop-dfs.sh 停止Hadoop HDFS守护进程NameNode、SecondaryNameNode和DataNode
sbin/hadoop-daemons.sh start namenode 单独启动NameNode守护进程
sbin/hadoop-daemons.sh stop namenode 单独停止NameNode守护进程
sbin/hadoop-daemons.sh start datanode 单独启动DataNode守护进程
sbin/hadoop-daemons.sh stop datanode 单独停止DataNode守护进程
sbin/hadoop-daemons.sh start secondarynamenode 单独启动SecondaryNameNode守护进程
sbin/hadoop-daemons.sh stop secondarynamenode 单独停止SecondaryNameNode守护进程
sbin/start-yarn.sh 启动ResourceManager、NodeManager
sbin/stop-yarn.sh 停止ResourceManager、NodeManager
sbin/yarn-daemon.sh start resourcemanager 单独启动ResourceManager
sbin/yarn-daemons.sh start nodemanager 单独启动NodeManager
sbin/yarn-daemon.sh stop resourcemanager 单独停止ResourceManager
sbin/yarn-daemons.sh stopnodemanager 单独停止NodeManager
sbin/mr-jobhistory-daemon.sh start historyserver 手动启动jobhistory
sbin/mr-jobhistory-daemon.sh stop historyserver 手动停止jobhistory7.上传文件报错
(1)报错

(2)原因分析
命令错误
(3)解决方法
使用正确命令
[root@hadoop hadoop]# ./bin/hadoop fs -put *.txt /devops/
8.HDFS 使用命令
(1)命令
ls 查看文件或目录cat 查看文件内容put 上传get 下载