目录
1.介绍
2.使用
1.seaborn官网:
2.安装
3.基础用法
4.导入数据
5.分析基金数据
1.绘制每个月收盘价的趋势线
2.计算涨跌幅
3.设置统计基点
4.分布图:分析涨跌幅数量
5.箱型图
6.回归图
7.热力图
1.介绍
1.与matplotlib区别

2.基于matplotlib进行开发的,更高效更高阶的绘制图表
2.使用
1.seaborn官网:
seaborn: statistical data visualization — seaborn 0.13.2 documentation
2.安装
pip install seaborn
3.基础用法
import matplotlib.pyplot as plt import matplotlib as mpl import numpy as np import pandas as pd import seaborn as sns# 模拟数据,50行4列 sample = pd.DataFrame(np.random.random(200).reshape(50, 4), columns=["a", "b", "c", "d"]) #设置全局样式样式 sxtyle:背景颜色 sns.set(sxtyle="dark")#直接赋值 sns.scatterplot(data=sample)plt.show()
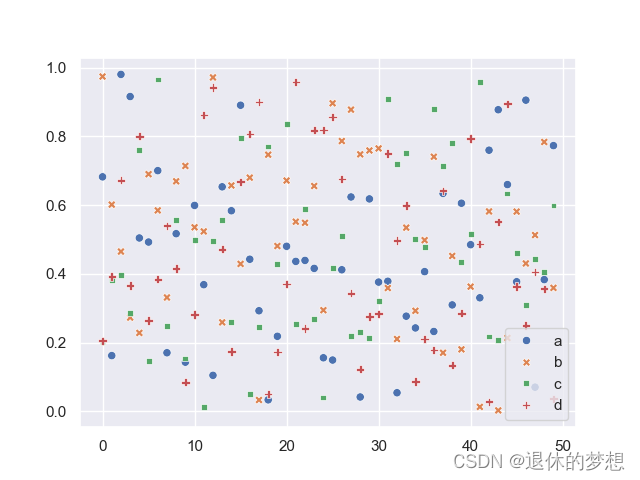
4.导入数据
1. 模拟数据 seaborn中默认自带的可测试数据集
# 模拟数据 seaborn中默认自带的可测试数据集 names=sns.get_dataset_names() print(names)
['anagrams', 'anscombe', 'attention', 'brain_networks', 'car_crashes', 'diamonds', 'dots', 'dowjones', 'exercise', 'flights', 'fmri', 'geyser', 'glue', 'healthexp', 'iris', 'mpg', 'penguins', 'planets', 'seaice', 'taxis', 'tips', 'titanic']
- anscombe:Anscombe 的四重奏数据集,包含四个具有相同统计属性的数据集,但它们的图形表示截然不同。
- attention:一个关于注意力缺陷/多动障碍(ADHD)的研究数据集,包含年龄、性别、智商和注意力得分等信息。
- car_crashes:关于汽车碰撞的数据集,包括天气、道路条件、速度等因素。
- diamonds:钻石价格数据集,包含钻石的多个属性(如重量、颜色、清晰度等)和价格。
- dots:一个简单的二维点数据集,用于演示散点图。
- flares:关于太阳耀斑的数据集,包含时间、位置、大小等信息。
- flights:关于航班延误的数据集,包括起飞和到达时间、延误时间等。
- fmri:功能性磁共振成像数据集,用于神经科学研究。
- games:一个关于视频游戏的数据集,包含游戏类型、评分、发行年份等信息。
- iris:鸢尾花数据集,包含三种鸢尾花的各种测量数据,常用于分类算法演示。
- line_tips:一个关于餐厅小费的数据集,包括账单金额、就餐人数、小费金额等。
- load_dataset:这不是一个数据集,而是一个函数,用于加载 Seaborn 提供的多个数据集。
- penguins:企鹅数据集,包含企鹅的多种测量数据,如体型、喙长等。
- planets:关于太阳系行星的数据集,包括质量、轨道周期等属性。
- tips:与
line_tips类似,但可能包含不同的变量或格式。 - titanic:泰坦尼克号相关数据
2.分析泰坦尼克号数据
# coding:utf-8import matplotlib.pyplot as plt
import matplotlib as mpl
import numpy as np
import pandas as pd
import seaborn as sns# 模拟数据 seaborn中默认自带的可测试数据集
names = sns.get_dataset_names()sample = sns.load_dataset("titanic")
print(sample.columns)
#绘制散点图:
# x:为船票价格fare,
# y:年龄age;
# hue:进行类别数据拆分,如是否存活:survived
# style:区分类别数据,如男女
sns.scatterplot(data=sample,x=sample["fare"],y="age",hue="survived",style="sex")plt.show()
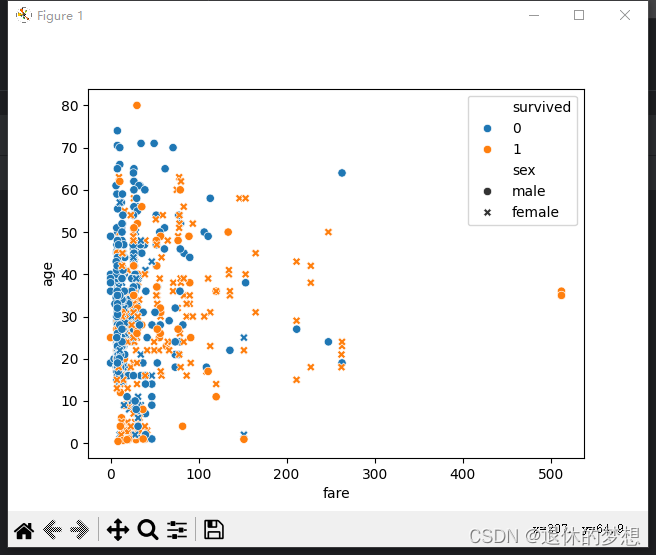
5.分析基金数据
1.绘制每个月收盘价的趋势线
# coding:utf-8import matplotlib.pyplot as plt
import matplotlib as mpl
import numpy as np
import pandas as pd
import seaborn as snsmpl.rcParams["font.family"] = "FangSong" # 设置字体
mpl.rcParams["axes.unicode_minus"] = False # 正常显示负号# 基金分析
sample = pd.read_csv("index_close_price.csv", index_col="date")
# 更名称
sample.rename(columns={"000016.XSHG": "上证50", "000905.XSHG": "中证500", "000300.XSHG": "沪深300", "399673.XSHE": "创业板50"},inplace=True)#调整index日期为日期类型
sample.index=pd.to_datetime(sample.index)
#调整日期频率:日>月,数据为每个月第一天的数据
bymonth=sample.resample("M").first()#绘制每个月收盘价的趋势线
sns.lineplot(bymonth)plt.show()
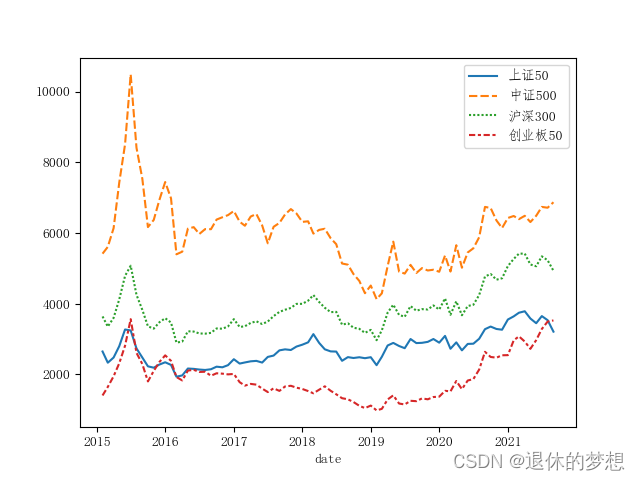
2.计算涨跌幅
# coding:utf-8import matplotlib.pyplot as plt
import matplotlib as mpl
import numpy as np
import pandas as pd
import seaborn as snsmpl.rcParams["font.family"] = "FangSong" # 设置字体
mpl.rcParams["axes.unicode_minus"] = False # 正常显示负号# 基金分析
sample = pd.read_csv("index_close_price.csv", index_col="date")
# 更名称
sample.rename(columns={"000016.XSHG": "上证50", "000905.XSHG": "中证500", "000300.XSHG": "沪深300", "399673.XSHE": "创业板50"},inplace=True)# 调整index日期为日期类型
sample.index = pd.to_datetime(sample.index)
# 调整日期频率:日>月,数据为每个月第一天的数据
bymonth = sample.resample("M").first()
# 绘制每个月收盘价的趋势线
#sns.lineplot(bymonth)# 方式一 计算涨跌幅
# 收益率(涨跌幅)=(期末值-期初值)/期末值
# bymonth.shift(1) 获取上一条数据
#byrate = (bymonth - bymonth.shift(1)) / bymonth.shift(1)#方式二
byrate = bymonth.pct_change()
print("byrate:",byrate)
#绘制涨跌幅
sns.lineplot(byrate)plt.show()
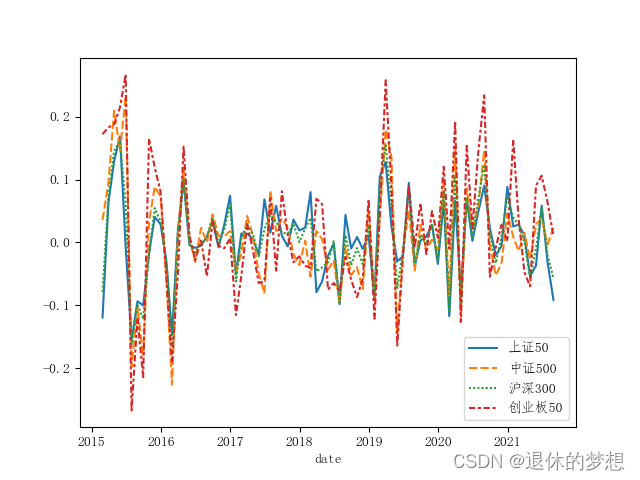
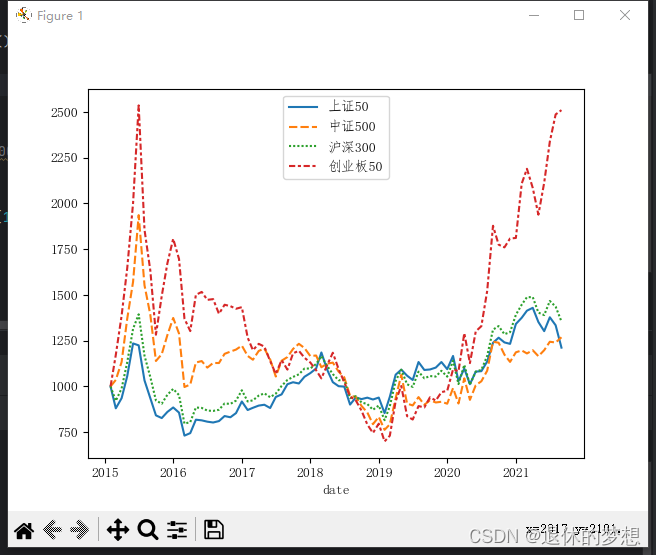
3.设置统计基点
1. 由于4只基金基点不一致,所以涨跌幅看起来不清晰,如果设置统计基点就可以明显看出来;
# coding:utf-8import matplotlib.pyplot as plt
import matplotlib as mpl
import numpy as np
import pandas as pd
import seaborn as snsmpl.rcParams["font.family"] = "FangSong" # 设置字体
mpl.rcParams["axes.unicode_minus"] = False # 正常显示负号# 基金分析
sample = pd.read_csv("index_close_price.csv", index_col="date")
# 更名称
sample.rename(columns={"000016.XSHG": "上证50", "000905.XSHG": "中证500", "000300.XSHG": "沪深300", "399673.XSHE": "创业板50"},inplace=True)# 调整index日期为日期类型
sample.index = pd.to_datetime(sample.index)
# 调整日期频率:日>月,数据为每个月第一天的数据
bymonth = sample.resample("M").first()
# 绘制每个月收盘价的趋势线
#sns.lineplot(bymonth)# 方式一 计算涨跌幅
# 收益率(涨跌幅)=(期末值-期初值)/期末值
# bymonth.shift(1) 获取上一条数据
#byrate = (bymonth - bymonth.shift(1)) / bymonth.shift(1)#方式二
byrate = bymonth.pct_change()
print("byrate:",byrate)
#绘制涨跌幅
#sns.lineplot(byrate)#统一基点:假如每个基金初始值为1000,收盘价=基点*(1+涨跌幅)
bases=byrate
bases.iloc[0]=1000
bases.iloc[1:]=1+bases.iloc[1:]
bases=bases.cumprod()
sns.lineplot(bases)plt.show()
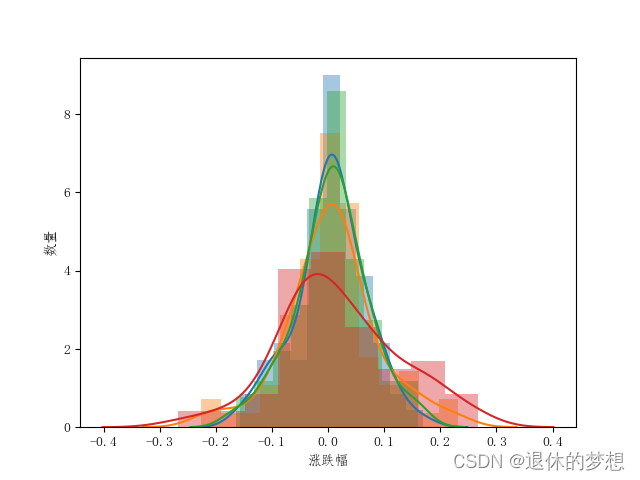
4.分布图:分析涨跌幅数量
# coding:utf-8import matplotlib.pyplot as plt
import matplotlib as mpl
import numpy as np
import pandas as pd
import seaborn as snsmpl.rcParams["font.family"] = "FangSong" # 设置字体
mpl.rcParams["axes.unicode_minus"] = False # 正常显示负号# 基金分析
sample = pd.read_csv("index_close_price.csv", index_col="date")
# 更名称
sample.rename(columns={"000016.XSHG": "上证50", "000905.XSHG": "中证500", "000300.XSHG": "沪深300", "399673.XSHE": "创业板50"},inplace=True)# 调整index日期为日期类型
sample.index = pd.to_datetime(sample.index)
# 调整日期频率:日>月,数据为每个月第一天的数据
bymonth = sample.resample("M").first()
#月涨跌幅 涨跌幅
byrate = bymonth.pct_change()
#日涨跌幅
dayrate=sample.pct_change()#绘制分布图
indexs=byrate.columns.tolist()
for i in indexs:sns.distplot(byrate[i])
plt.xlabel("涨跌幅")
plt.ylabel("数量")plt.show()
5.箱型图
1. 绘制每个基金涨跌幅的分布
# coding:utf-8import matplotlib.pyplot as plt
import matplotlib as mpl
import numpy as np
import pandas as pd
import seaborn as snsmpl.rcParams["font.family"] = "FangSong" # 设置字体
mpl.rcParams["axes.unicode_minus"] = False # 正常显示负号# 基金分析
sample = pd.read_csv("index_close_price.csv", index_col="date")
# 更名称
sample.rename(columns={"000016.XSHG": "上证50", "000905.XSHG": "中证500", "000300.XSHG": "沪深300", "399673.XSHE": "创业板50"},inplace=True)# 调整index日期为日期类型
sample.index = pd.to_datetime(sample.index)
# 调整日期频率:日>月,数据为每个月第一天的数据
bymonth = sample.resample("M").first()
#月涨跌幅 涨跌幅
byrate = bymonth.pct_change()
#日涨跌幅
dayrate=sample.pct_change()indexs=byrate.columns.tolist()#箱型图绘制
sns.boxplot(data=byrate)
#绘制散点
sns.swarmplot(data=byrate)plt.show()
由此可分析,沪深300涨跌幅是最稳定的,并且收益率也是正向的偏多

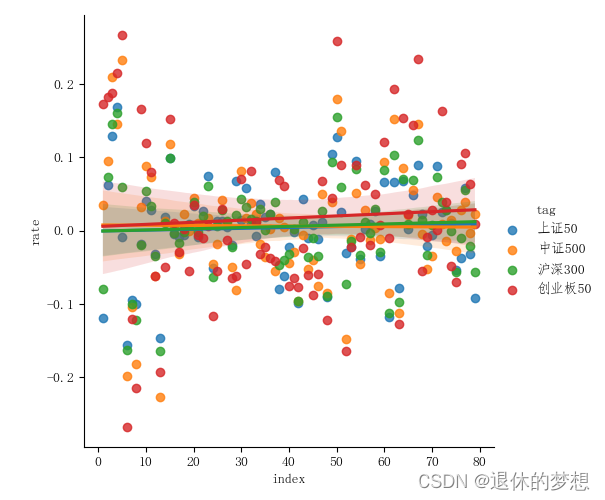
6.回归图
1. 用于做数据预测,来描述未来的走向
# coding:utf-8import matplotlib.pyplot as plt
import matplotlib as mpl
import numpy as np
import pandas as pd
import seaborn as snsmpl.rcParams["font.family"] = "FangSong" # 设置字体
mpl.rcParams["axes.unicode_minus"] = False # 正常显示负号# 基金分析
sample = pd.read_csv("index_close_price.csv", index_col="date")
# 更名称
sample.rename(columns={"000016.XSHG": "上证50", "000905.XSHG": "中证500", "000300.XSHG": "沪深300", "399673.XSHE": "创业板50"},inplace=True)# 调整index日期为日期类型
sample.index = pd.to_datetime(sample.index)
# 调整日期频率:日>月,数据为每个月第一天的数据
bymonth = sample.resample("M").first()
# 月涨跌幅 涨跌幅
byrate = bymonth.pct_change()
# 日涨跌幅
dayrate = sample.pct_change()
# 列值
indexs = byrate.columns.tolist()# 绘制回归图
# 改变数据结构
temp = pd.DataFrame()
res = pd.DataFrame()
for c in indexs:temp["rate"] = byrate[c]temp["tag"] = ctemp["index"] = np.arange(len(byrate))res=pd.concat([res,temp],ignore_index=True)sns.lmplot(data=res, x="index", y="rate", hue="tag")plt.show()
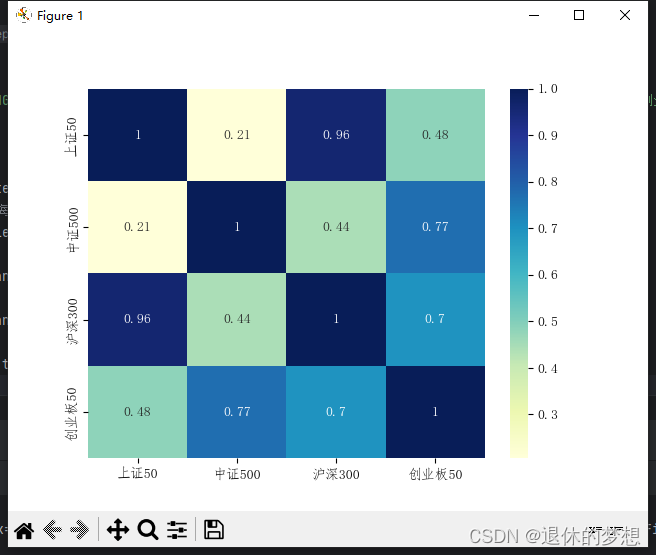
7.热力图
1. 做相关性分析,
2.如:观察不同基金之间的相关性
# coding:utf-8import matplotlib.pyplot as plt
import matplotlib as mpl
import numpy as np
import pandas as pd
import seaborn as snsmpl.rcParams["font.family"] = "FangSong" # 设置字体
mpl.rcParams["axes.unicode_minus"] = False # 正常显示负号# 基金分析
sample = pd.read_csv("index_close_price.csv", index_col="date")
# 更名称
sample.rename(columns={"000016.XSHG": "上证50", "000905.XSHG": "中证500", "000300.XSHG": "沪深300", "399673.XSHE": "创业板50"},inplace=True)# 调整index日期为日期类型
sample.index = pd.to_datetime(sample.index)
# 调整日期频率:日>月,数据为每个月第一天的数据
bymonth = sample.resample("M").first()
# 月涨跌幅 涨跌幅
byrate = bymonth.pct_change()
# 日涨跌幅
dayrate = sample.pct_change()
# 列值
indexs = byrate.columns.tolist()#计算相关性
sample_corr=sample.corr()print("sample_corr",sample_corr)
#绘制相关性
sns.heatmap(sample_corr,annot=True,cmap="YlGnBu")plt.show()