故障特征提取就是从振动信号中提取时、频域统计特征,并利用能量值、谱峭度、幅值等指标,提取出故障特征集。对故障特征值进行全面准确地提取,是提高诊断精度的关键,也是整个滚动轴承故障诊断过程中较困难的部分。
一些常见的时域特征和频域特征计算如下:


此外:
时域特征
时域特征提取 - Data螺丝钉的文章 - 知乎
https://zhuanlan.zhihu.com/p/398752292
频域特征:
信号进行频域分析,能提取哪些特征,有什么物理意义呢? - Xinquan的回答 - 知乎
https://www.zhihu.com/question/60550840/answer/177778560
能量特征(小波包子频带能量)
分形特征
熵特征
XSpecEn:两个序列之间的交叉谱熵(cross-spectral entropy)
XSampEn:两个序列之间的交叉样本熵(cross-sample entropy)
参考论文:Physiological time-series analysis using approximate entropy and sample entropy
XPermEn:两个序列之间的交叉排列熵(cross-permutation entropy)
参考论文:The coupling analysis of stock market indices based on cross-permutation entropy
XMSEn:两个序列之间的多尺度交叉熵(multiscale cross-entropy)
参考论文:Multiscale cross entropy: a novel algorithm for analyzing two time series
XK2En:两个序列之间的交叉Kolmogorov熵(cross-Kolmogorov (K2) entropy)
XFuzzEn:两个序列之间的交叉模糊熵(cross-fuzzy entropy)
参考论文:Cross-fuzzy entropy: A new method to test pattern synchrony of bivariate time series
XDistEn:两个序列之间的交叉分布熵(cross-distribution entropy)
参考论文:Analysis of financial stock markets through the multiscale cross-distribution entropy based on the Tsallis entropy
XDistEn:两个序列之间的交叉条件熵(corrected cross-conditional entropy)
参考论文:Conditional entropy approach for the evaluation of the coupling strength
XApEn:两个序列之间的交叉近似熵(cross-approximate entropy)
参考论文:Randomness and degrees of irregularity
SyDyEn:符号动力熵(symbolic dynamic entropy)
参考论文:A fault diagnosis scheme for planetary gearboxes using modified multi-scale symbolic dynamic entropy and mRMR feature selection.
SpecEn:单一序列的谱熵(spectral entropy)
参考论文:A spectral entropy method for distinguishing regular and irregular motion of Hamiltonian systems.
SlopEn:斜率熵(Slope Entropy)
SampEn2D:数据矩阵的二维样本熵(bidimensional sample entropy of a data matrix)
SampEn:单一序列的样本熵(sample entropy)
rXMSEn:细化多尺度交叉熵(refined multiscale cross-entropy)
PhasEn:相位熵(phase entropy)
PermEn2D:二维排列熵( bidimensional permutation entropy)
IncrEn:增量熵(increment entropy)
hXMSEn:两个序列的层次交叉熵(hierarchical cross-entropy)
GridEn:网格分布熵(gridded distribution entropy)
EspEn2D:二维Espinosa 熵(bidimensional Espinosa entropy)
DispEn2D:二维色散熵(bidimensional dispersion entropy)
cXMSEn:复合多尺度交叉熵(composite multiscale cross-entropy)
CoSiEn:余弦相似熵(cosine similarity entropy )
BubbEn:气泡熵(bubble entropy)
AttnEn:注意力熵( attention entropy)
时频域特征
多分辨分析在信号处理中的应用-第1篇
https://zhuanlan.zhihu.com/p/55
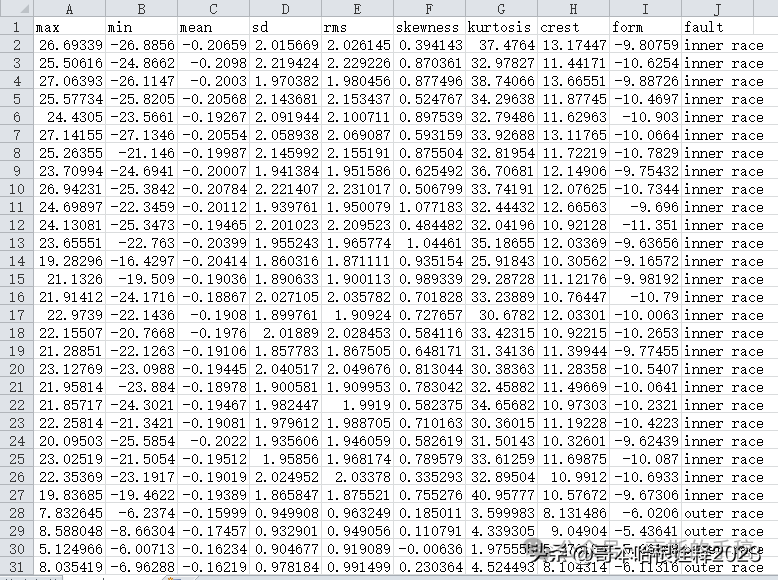
鉴于此,本项目在Python环境下采用基于机器学习(决策树,随机森林,KNN和SVM)对轴承进行故障诊断,并利用网格搜索算法对机器学习进行调优,项目所使用的数据非原始数据,是经过特征提取的(峭度等特征),训练集如下:

测试数据如下:
代码如下:
#导入相关模块
import numpy as np
import pandas as pd
import seaborn as sns
from pylab import rcParams
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn.preprocessing import OrdinalEncoder
from sklearn.preprocessing import StandardScaler#加载训练数据importing training data
train_data = pd.read_csv(r'training set.csv')#对故障类型进行编码encoding type of faults
ord_enc = OrdinalEncoder()
train_data[["fault", "fault_code"]]train_data['fault_code'].unique()#每个故障类型的数据点个数
train_data[['fault_code', 'fault']].value_counts()
#特征标准化Scaling
scaler = StandardScaler()
scaled_df = pd.DataFrame(scaler.fit_transform(train_data.iloc[:,:-2]))
scaled_df.head()#替换列名称
scaled_df.columns = train_data.drop(['fault', 'fault_code'],1).columnsscaled_train_data = pd.concat([scaled_df, train_data[['fault', 'fault_code']]], 1)
scaled_train_data## 探索性数据分析
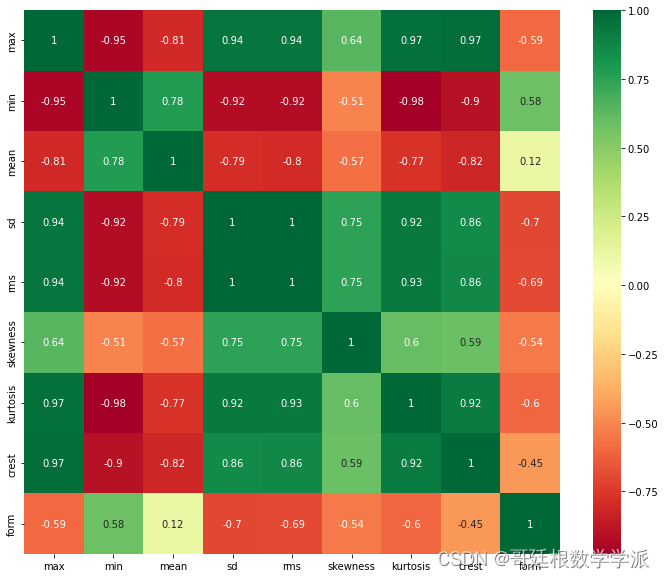
#协相关矩阵
rcParams['figure.figsize'] = 12, 10
sns.heatmap(scaled_train_data.iloc[:,:-2].corr(),annot=True,cmap='RdYlGn')
fig=plt.gcf()
plt.show()#两两关系图pairplot
rcParams['figure.figsize'] = 6, 5
sns.pairplot(scaled_train_data.drop('fault_code',1),hue='fault',palette='Dark2')
plt.show()#处理测试数据
#加载测试数据
test_data = pd.read_csv(r'testing set.csv')
test_datatest_data['fault'].value_counts()#编码
test_data["fault_code"] = ord_enc.transform(test_data[["fault"]])#数据标准化
scaled_df = pd.DataFrame(scaler.transform(test_data.iloc[:,:-2]))
scaled_df.head()#替换列名称
scaled_df.columns = test_data.drop(['fault', 'fault_code'],1).columnsscaled_test_data = pd.concat([scaled_df, test_data[['fault', 'fault_code']]], 1)
scaled_test_data#X_train训练数据
X_train = scaled_train_data.drop(['sd', 'skewness','fault','fault_code'],1)
X_train.head()
#y_train训练标签
y_train = scaled_train_data['fault_code']
y_train.head()#X_test测试数据
X_test = scaled_test_data.drop(['sd','skewness','fault','fault_code'],1)
X_test.head()#y_test测试标签
y_test = scaled_test_data['fault_code']
y_test.head()##############决策树分类
from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier().fit(X_train, y_train)#预测
dt_predictions = dt_clf.predict(X_test)
print(dt_predictions)#Train Score Vs Test Score
print('Train Score:',dt_clf.score(X_train, y_train), 'Test Score:',dt_clf.score(X_test, y_test))#混淆矩阵Confusion Matrix
fig, ax = plt.subplots(figsize=(5,5))
from sklearn.metrics import plot_confusion_matrix
plot_confusion_matrix(dt_clf, X_test, y_test, ax=ax)#性能分数
from sklearn.metrics import classification_report
labels= ['outer race', 'inner race', 'healthy']
print(classification_report(y_test, dt_predictions, target_names=labels))# 根据随机搜索的结果创建参数网格
params = {'min_samples_leaf': [1, 2, 3, 4, 5, 10],'criterion': ["gini", "entropy"],'max_depth':[1, 2, 3, 4,6,8],'min_samples_split': [2, 3, 4]
}# 实例化网格搜索模型
from sklearn.model_selection import GridSearchCVdt_best_clf = GridSearchCV(estimator=dt_clf, param_grid=params, cv=4, n_jobs=-1, verbose=1, scoring = "accuracy")
dt_best_clf.fit(X_train, y_train)#最优估计参数
dt_best_clf.best_estimator_dt_best_clf = DecisionTreeClassifier(max_depth=2,min_samples_split=4 , random_state=42).fit(X_train, y_train)#预测
dt_best_predictions = dt_best_clf.predict(X_test)
print(dt_best_predictions)#Train Score Vs Test Score
print('Train Score:',dt_best_clf.score(X_train, y_train), 'Test Score:',dt_best_clf.score(X_test, y_test))#混淆矩阵
fig, ax = plt.subplots(figsize=(5,5))
plot_confusion_matrix(dt_best_clf, X_test, y_test, ax=ax)#性能分数
print(classification_report(y_test, dt_best_predictions, target_names=labels))#绘制决策树
from sklearn import tree
fig = plt.figure(figsize=(10,10))
_ = tree.plot_tree(dt_best_clf,feature_names=X_train.columns,class_names=['inner race', 'outer race', 'healthy'],filled=True)########################################随机森林分类
#导入随机森林分类器importing Random Forest Classifier
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(random_state = 2)#随机森林训练
rf_clf.fit(X_train, y_train)
#测试集预测
rf_predictions = rf_clf.predict(X_test)#Train score Vs Test score
print('Train score:',rf_clf.score(X_train, y_train), 'Test Score:',rf_clf.score(X_test, y_test))#混淆矩阵
fig, ax = plt.subplots(figsize=(5,5))
plot_confusion_matrix(rf_clf, X_test, y_test, ax=ax)#性能分数
print(classification_report(y_test, rf_predictions, target_names=labels))#搜索参数
n_estimators = [1, 5, 10, 20, 100, 120]
max_depth = [1, 2, 3]
min_samples_split = [2, 3, 4, 6, 8]
min_samples_leaf = [ 1, 2, 3] random_grid = {'n_estimators': n_estimators,'max_depth': max_depth,'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf,}#使用随机搜索算法using RandomizedSearchCV
from sklearn.model_selection import RandomizedSearchCV
rf_best_clf = RandomizedSearchCV(estimator = rf_clf,param_distributions = random_grid,n_iter = 1000, cv = 10, verbose=5, n_jobs = -1)#训练集拟合fitting train set
rf_best_clf.fit(X_train, y_train)print ('Random grid: ', random_grid, '\n')
#输出最优参数print the best parameters
print ('Best Parameters: ', rf_best_clf.best_params_, ' \n')#测试
rf_best_clf = RandomForestClassifier(n_estimators:=100, min_samples_split= 4, min_samples_leaf=2, max_depth= 1, random_state=90).fit(X_train, y_train)
rf_best_predictions = rf_best_clf.predict(X_test)
print(rf_best_predictions)#Train score Vs test score
print('Train score:',rf_best_clf.score(X_train, y_train), 'Test score:',rf_best_clf.score(X_test, y_test))#混淆矩阵onfusion Matrix
fig, ax = plt.subplots(figsize=(5,5))
plot_confusion_matrix(rf_best_clf, X_test, y_test, ax=ax)#性能分数
print(classification_report(y_test, rf_best_predictions, target_names=labels))########################################KNN分类
#导入KNeighborsClassifier
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier()#训练集进行拟合
knn_clf.fit(X_train, y_train)
#进行预测
knn_predictions = knn_clf.predict(X_test)
print(knn_predictions)
#Train score vs test score
print('Train score:',knn_clf.score(X_train, y_train), 'Test score:',knn_clf.score(X_test, y_test))#混淆矩阵Confusion Matrix
fig, ax = plt.subplots(figsize=(5,5))
plot_confusion_matrix(knn_clf, X_test, y_test, ax=ax)
#性能分数
print(classification_report(y_test, knn_predictions, target_names=labels))
#要微调的超参数列表
leaf_size = [1, 2, 3, 4, 5]
n_neighbors = [1, 2, 3, 4, 5]
p=[1, 2, 3]#转换为字典
hyperparameters = dict(leaf_size=leaf_size, n_neighbors=n_neighbors, p=p)
#使用网格搜索算法GridSearch
knn_best_clf = GridSearchCV(knn_clf, hyperparameters, cv=10)
knn_best_clf.fit(X_train, y_train)
#输出最优超参数
print('Best leaf_size:', knn_best_clf.best_estimator_.get_params()['leaf_size'])
print('Best p:', knn_best_clf.best_estimator_.get_params()['p'])
print('Best n_neighbors:', knn_best_clf.best_estimator_.get_params()['n_neighbors'])
#预测
knn_best_predictions = knn_best_clf.predict(X_test)
print(knn_best_predictions)
#Train score Vs Test score
print('Train score:',knn_best_clf.score(X_train, y_train), 'Test score:',knn_best_clf.score(X_test, y_test))
#混淆矩阵Confusion Matrix
fig, ax = plt.subplots(figsize=(5,5))
plot_confusion_matrix(knn_best_clf, X_test, y_test, ax=ax)
#性能指标分数
print(classification_report(y_test, knn_best_predictions, target_names=labels))############################################SVM分类器
#导入SVM分类器并进行训练
from sklearn.svm import SVC
svm_clf = SVC(kernel='rbf')
svm_clf.fit(X_train,y_train)
#预测
svm_predictions = svm_clf.predict(X_test)
print(svm_predictions)
#train score vs test score
print('Train score:',svm_clf.score(X_train, y_train), 'Test score:',svm_clf.score(X_test, y_test))
#混淆矩阵Confusion Matrix
fig, ax = plt.subplots(figsize=(5,5))
plot_confusion_matrix(svm_clf, X_test, y_test, ax=ax)
#性能指标分数
print(classification_report(y_test, svm_predictions, target_names=labels))#超参数调优
param_grid = {'C': [0.02,0.021,0.022],'gamma': [0.8,0.7,0.6, 0.65],'kernel': ['rbf']}grid = GridSearchCV(SVC(), param_grid, refit = True, verbose = 3, cv=10)#利用网格搜索算法进行拟合训练
grid.fit(X_train, y_train)#输出最优超参数
print(grid.best_params_)print(grid.best_estimator_)
#最优SVM分类器
best_svm_clf = SVC(kernel = 'rbf', C=0.021, gamma=0.6).fit(X_train, y_train)
#最优预测
best_svm_predictions = best_svm_clf.predict(X_test)
print(best_svm_predictions)
#Train score Vs Test score
print('Train score:',best_svm_clf.score(X_train, y_train), 'Test score:',best_svm_clf.score(X_test, y_test))
#混淆矩阵Confusion Matrix
fig, ax = plt.subplots(figsize=(5,5))
plot_confusion_matrix(best_svm_clf, X_test, y_test, ax=ax)#性能指标分数
print(classification_report(y_test, best_svm_predictions, target_names=labels))
出图如下:
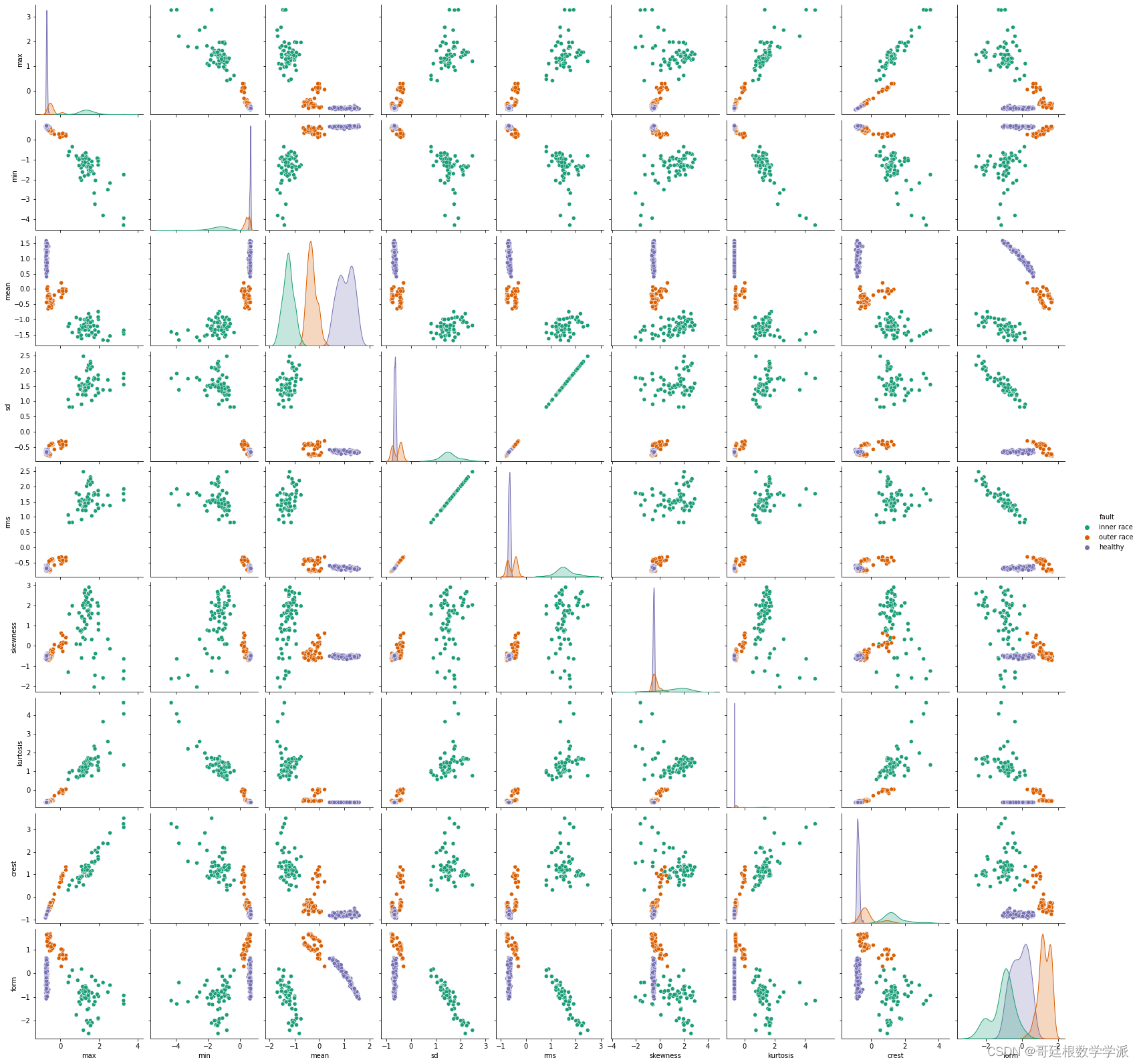
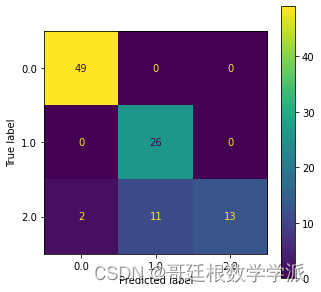
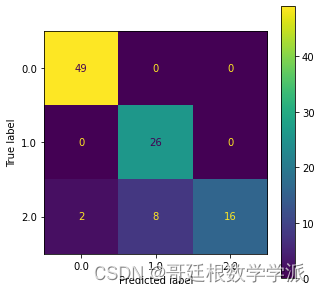

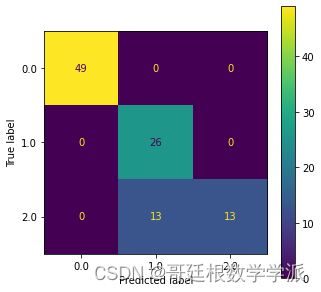

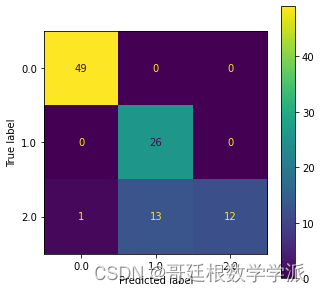

完整代码:Python环境下基于机器学习(决策树,随机森林,KNN和SVM)的轴承故障诊断
擅长领域:现代信号处理,机器学习,深度学习,数字孪生,时间序列分析,设备缺陷检测、设备异常检测、设备智能故障诊断与健康管理PHM等。