目录
引言
1 迁移学习
1.1 什么是迁移学习
1.2 迁移学习能解决什么问题
1.3 迁移学习面临的三个问题
1.3.1 何时迁移
1.3.2 何处迁移
1.3.3 如何迁移
1.4 迁移学习的分类
1.4.1 按照学习方式的划分
1.4.2 按照使用方法的划分
2 Restnet网络
2.1 Restnet介绍
2.2 Restnet网络结构
3 迁移学习代码实现
3.1 数据集介绍
3.2 预训练模型下载
3.3 基于pytorch使用Restnet预训练模型进行迁移学习
3.4 基于pytorch不进行迁移学习的情况下进行网络训练
4 总结
引言
本项目在Restnet预训练模型的基础上,通过迁移学习构建了水果分类识别模型,经过30epochs训练,实现了模型的快速收敛,准确率达到了96%以上。通过此项目实战,我们进一步熟悉了如何在预训练模型的基础上进行迁移学习,构建新的深度学习模型。技术伙伴们可参考本项目增加数据分类或使用其他数据集,通过迁移学习构建新的分类识别模型。
1 迁移学习
1.1 什么是迁移学习
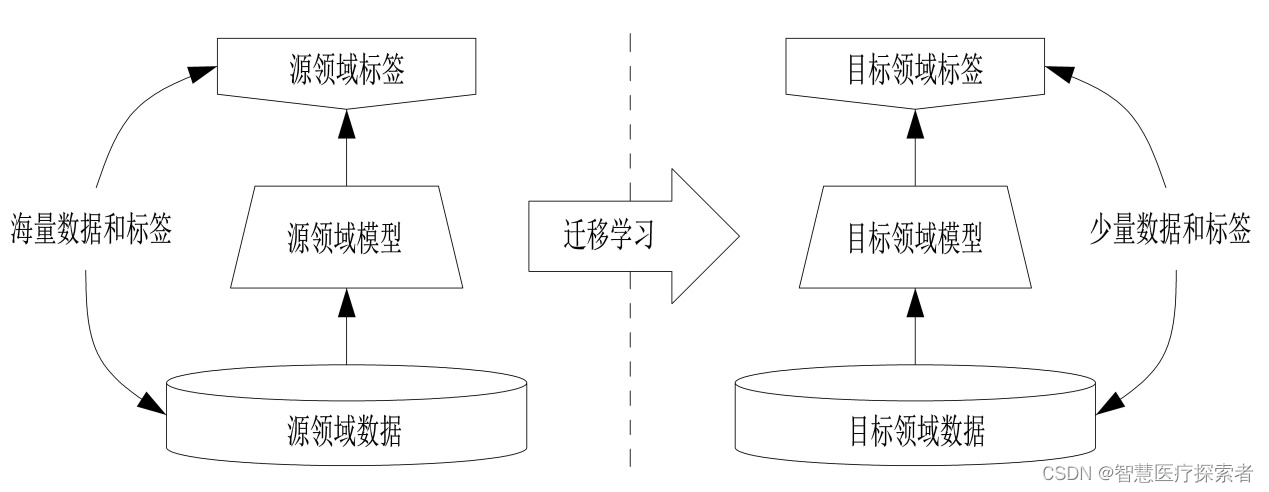
迁移学习(Transfer Learning)是一种机器学习方法,就是把为任务 A 开发的模型作为初始点,重新使用在为任务 B 开发模型的过程中。迁移学习是通过从已学习的相关任务中转移知识来改进学习的新任务,虽然大多数机器学习算法都是为了解决单个任务而设计的,但是促进迁移学习的算法的开发是机器学习社区持续关注的话题。

迁移学习通俗来讲就是学会举一反三的能力,通过运用已有的知识来学习新的知识,其核心是找到已有知识和新知识之间的相似性,通过这种相似性的迁移达到迁移学习的目的。世间万事万物皆有共性,如何合理地找寻它们之间的相似性,进而利用这个桥梁来帮助学习新知识,是迁移学习的核心问题。
1.2 迁移学习能解决什么问题
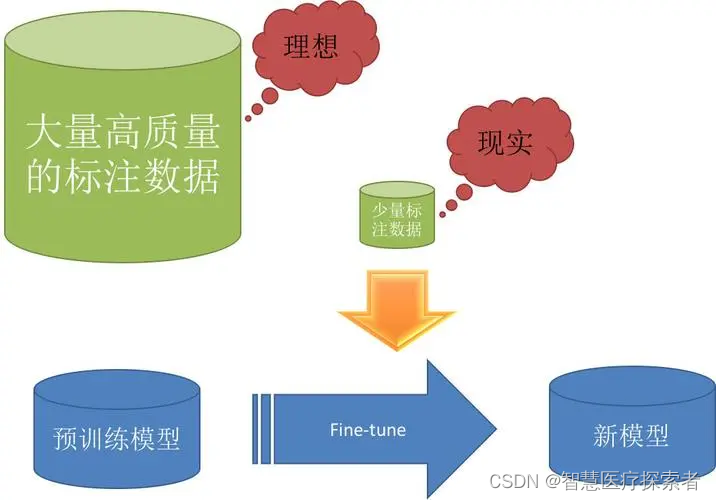
当前的人工智能技术大多需要有大量高质量的数据支撑,使用实验室构造的数据可以一定程度上解决这一难题,满足基本的训练需求。然而,到了实际的局点上使用的时候,往往会因为构造数据与实际数据的差异而导致预测的结果不够准确。这一问题的出现,给AI算法提出了新的要求——在充分利用实验室构造数据的基础上,也要在局点真实数据上获得很好的结果。“ 迁移学习 ”作为一种解决方法帮助我们在有限数据集上训练得到一个需要海量数据训练效果的模型,起到事半功倍的效果。
迁移学习的应用往往不限于特定的领域,只要该问题满足迁移学习的场景,就可以尝使用迁移学习来解决。计算机视觉、文本分类、行为识别、自然语言处理、室内定位、视频监控、舆情分析、人机交互等领域都可以使用到迁移学习的技术。
1.3 迁移学习面临的三个问题
1.3.1 何时迁移
何时迁移对应于迁移学习的可能性和使用迁移学习的原因. 值得注意的是, 此步骤应该发生在迁移学习的第一步. 给定待学习的目标,我们首先要做的便是判断当时的任务是否适合进行迁移学习
1.3.2 何处迁移
判断当时的任务适合迁移学习之后, 第二步要解决的是从何处进行迁移. 这里何处我们可以使用what和where来表达便于理解. what, 指的是要迁移什么知识,这些知识可以是神经网络权值, 特征变化矩阵某些参数等; 而where指的是要从那个地方进行迁移, 这些地方可以是某个源域, 某个神经元, 某个随机森林的树等.
1.3.3 如何迁移
这一步是绝大多数迁移学习方法的着力点. 给定待学习的源域和目标域, 这一步则是要学习最优的迁移学习方法以达到最好的性能.
1.4 迁移学习的分类
1.4.1 按照学习方式的划分
- 基于样本的迁移学习(Instance based Transfer Learning):对不同的样本给予不同的权重,样本越相似,权重越高。高权重样本优先级更高,完成迁移。
- 基于特征的迁移学习(Feature based Transfer Learning):是对特征进行变换。假设源域和目标域的特征原来不在一个空间,或者说它们在原来那个空间上不相似,那我们就想办法把它们变换到一个空间里面,最小化二者对应点的距离,完成迁移
- 基于模型的迁移学习(Model based Transfer Learning):就是重新利用模型里的参数。该类方法在神经网络里面用的特别多,因为神经网络的结构可以直接进行迁移。比finetune就是模型参数迁移的很好的体现。
- 基于关系的迁移学习:发掘相似场景的关系,两组中如果有一组源域和目标域的关系可确定,可以迁移到另一组上。比如老师上课、学生听课就可以类比为公司开会的场景,这种类比就是一种关系的迁移。
1.4.2 按照使用方法的划分
- 微调(Finetune):将别人训练好的网络模型修改后用于自己的。用预训练的网络权值代替随机初始化权值
- 混合特征提取(Fixed Feature Extractor):将预训练网络作为新任务特征提取,也就是新模型的前几层用预训练网络做替换
2 Restnet网络
2.1 Restnet介绍
深度学习在图像分类、目标检测、语音识别等领域取得了重大突破,但是随着网络层数的增加,梯度消失和梯度爆炸问题逐渐凸显。随着层数的增加,梯度信息在反向传播过程中逐渐变小,导致网络难以收敛。同时,梯度爆炸问题也会导致网络的参数更新过大,无法正常收敛。
为了解决这些问题,ResNet提出了一个创新的思路:引入残差块(Residual Block)。残差块的设计允许网络学习残差映射,从而减轻了梯度消失问题,使得网络更容易训练。
下图是一个基本残差块。它的操作是把某层输入跳跃连接到下一层乃至更深层的激活层之前,同本层输出一起经过激活函数输出。

2.2 Restnet网络结构
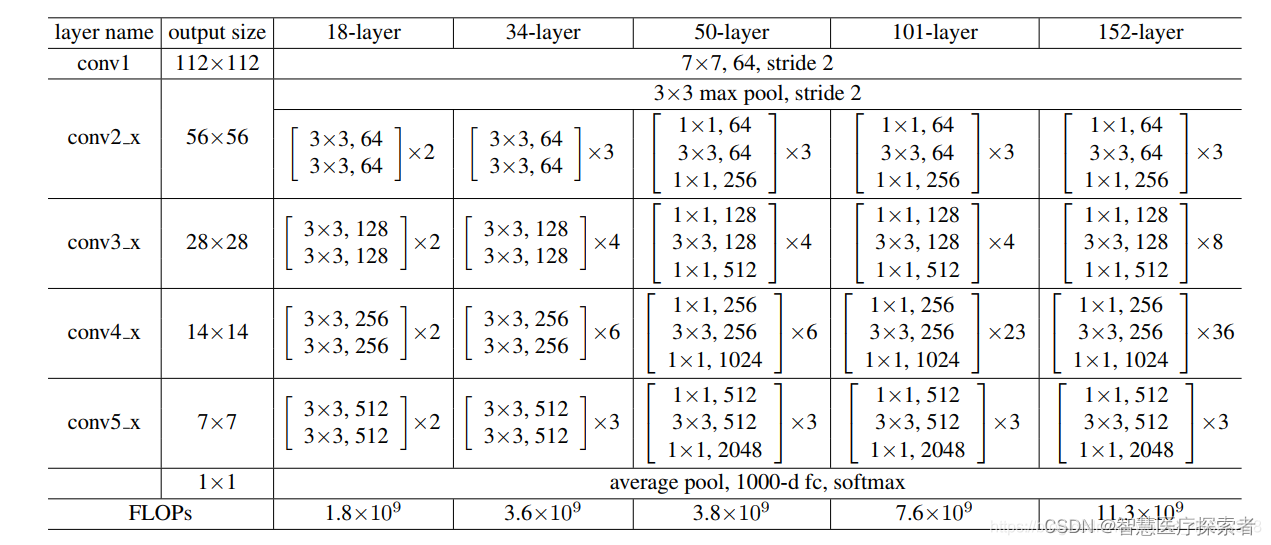
ResNet的经典网络结构有:ResNet-18、ResNet-34、ResNet-50、ResNet-101、ResNet-152几种,其中,ResNet-18和ResNet-34的基本结构相同,属于相对浅层的网络,后面3种属于更深层的网络,其中RestNet50最为常用。
3 迁移学习代码实现
3.1 数据集介绍
在数据集目录下,存放着10个文件夹,文件夹名称为水果类型,每个文件夹包含几百到几千张此类水果的图片,如下图所示:

以apple文件夹为例,内容如下:

下载地址:第一个包,第二个包
两个数据包下载完成后,都解压到/opt/dataset/fruit目录下,完成后如下所示:
# ll fruit/
总用量 508
drwxr-xr-x 2 root root 36864 8月 2 16:35 apple
drwxr-xr-x 2 root root 24576 8月 2 16:36 apricot
drwxr-xr-x 2 root root 40960 8月 2 16:36 banana
drwxr-xr-x 2 root root 20480 8月 2 16:36 blueberry
drwxr-xr-x 2 root root 45056 8月 2 16:37 cherry
drwxr-xr-x 2 root root 12288 8月 2 16:37 citrus
drwxr-xr-x 2 root root 49152 8月 2 16:38 grape
drwxr-xr-x 2 root root 16384 8月 2 16:38 lemon
drwxr-xr-x 2 root root 36864 8月 2 16:39 litchi
drwxr-xr-x 2 root root 49152 8月 2 16:39 mango3.2 预训练模型下载
预训练模型下载地址如下:
model_urls = {'resnet18': 'https://download.pytorch.org/models/resnet18-f37072fd.pth','resnet34': 'https://download.pytorch.org/models/resnet34-b627a593.pth','resnet50': 'https://download.pytorch.org/models/resnet50-0676ba61.pth','resnet101': 'https://download.pytorch.org/models/resnet101-63fe2227.pth','resnet152': 'https://download.pytorch.org/models/resnet152-394f9c45.pth','resnext50_32x4d': 'https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth','resnext101_32x8d': 'https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth','wide_resnet50_2': 'https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth','wide_resnet101_2': 'https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth',}下载restnet50的模型,存放到/opt/models目录下
3.3 基于pytorch使用Restnet预训练模型进行迁移学习
水果识别模型在Restnet的基础上,增加一个全连接层,将Restnet预训练模型的2048输出变换到对应的水果分类数量的输出。
import torch
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import datetime
import numpy as npfrom torchvision.datasets import ImageFolder
from torchvision import transforms
from torchvision.models import resnet50
from sklearn.model_selection import train_test_split# 图像变换
transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]), ])
# 加载数据集
dataset = ImageFolder('/opt/dataset/fruit', transform=transform)# 划分训练集与测试集
train_dataset, valid_dataset = train_test_split(dataset, test_size=0.2, random_state=10)batch_size = 64
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
test_loader = DataLoader(dataset=valid_dataset, batch_size=batch_size, shuffle=True, drop_last=True)restnet_pretrained_path = '/opt/models/resnet50-0676ba61.pth'
checkpoint_path = '/opt/checkpoint/fruit_reg.pth'
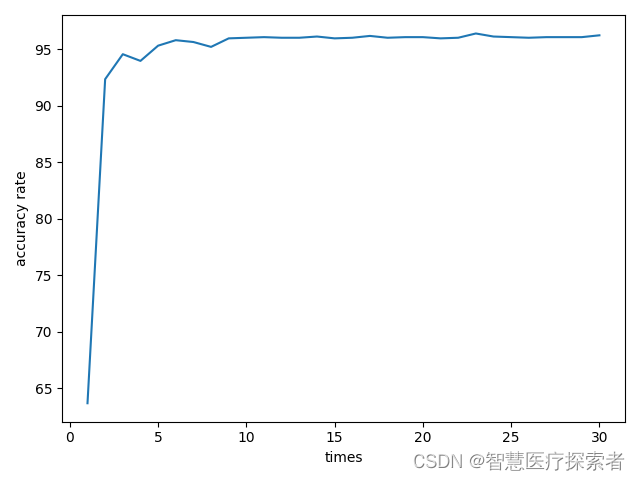
checkpoint_resume = Falseif __name__ == "__main__":# 加载预训练模型model = resnet50()model.load_state_dict(torch.load(restnet_pretrained_path))# 替换最后一层全连接层,构建新的网络,实现迁移学习num_classes = len(dataset.classes)in_features = model.fc.in_featuresmodel.fc = torch.nn.Linear(in_features, num_classes)# 模型训练device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model.to(device)criterion = torch.nn.CrossEntropyLoss()optimizer = torch.optim.SGD(model.parameters(), lr=0.0001, momentum=0.9)num_epochs = 30accuracy_rate = []for epoch in range(num_epochs):print('Epoch [{}/{}], start'.format(epoch + 1, num_epochs))for inputs, labels in train_loader:inputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch + 1, num_epochs, loss.item()))# 模型验证model.eval()correct = 0total = 0with torch.no_grad():for inputs, labels in test_loader:inputs, labels = inputs.to(device), labels.to(device)outputs = model(inputs)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()accuracy = correct / total * 100accuracy_rate.append(accuracy)print('Accuracy: {:.2f}%'.format(accuracy))accuracy_rate = np.array(accuracy_rate)times = np.linspace(1, num_epochs, num_epochs)plt.xlabel('times')plt.ylabel('accuracy rate')plt.plot(times, accuracy_rate)plt.show()print(f"{datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')},accuracy_rate={accuracy_rate}")torch.save(model.state_dict(), checkpoint_path)Epoch [1/30], Loss: 1.4853 Accuracy: 63.69% Epoch [2/30], Loss: 0.2206 Accuracy: 92.35%Epoch [3/30], Loss: 0.1856 Accuracy: 94.56%Epoch [4/30], Loss: 0.1025 Accuracy: 93.97%Epoch [5/30], Loss: 0.0543 Accuracy: 95.31%Epoch [6/30], Loss: 0.0335 Accuracy: 95.80%Epoch [7/30], Loss: 0.0114 Accuracy: 95.64%Epoch [8/30], Loss: 0.0159 Accuracy: 95.20%Epoch [9/30], Loss: 0.0060 Accuracy: 95.96%Epoch [10/30], Loss: 0.0027 Accuracy: 96.01%Epoch [11/30], Loss: 0.0052 Accuracy: 96.07%Epoch [12/30], Loss: 0.0030 Accuracy: 96.01%Epoch [13/30], Loss: 0.0035 Accuracy: 96.01%Epoch [14/30], Loss: 0.0026 Accuracy: 96.12%Epoch [15/30], Loss: 0.0008 Accuracy: 95.96%Epoch [16/30], Loss: 0.0013 Accuracy: 96.01%Epoch [17/30], Loss: 0.0008 Accuracy: 96.17%Epoch [18/30], Loss: 0.0005 Accuracy: 96.01%Epoch [19/30], Loss: 0.0010 Accuracy: 96.07%Epoch [20/30], Loss: 0.0009 Accuracy: 96.07%Epoch [21/30], Loss: 0.0002 Accuracy: 95.96%Epoch [22/30], Loss: 0.0002 Accuracy: 96.01%Epoch [23/30], Loss: 0.0006 Accuracy: 96.39%Epoch [24/30], Loss: 0.0010 Accuracy: 96.12%Epoch [25/30], Loss: 0.0008 Accuracy: 96.07%Epoch [26/30], Loss: 0.0011 Accuracy: 96.01%Epoch [27/30], Loss: 0.0003 Accuracy: 96.07%Epoch [28/30], Loss: 0.0006 Accuracy: 96.07%Epoch [29/30], Loss: 0.0005 Accuracy: 96.07%Epoch [30/30], Loss: 0.0002 Accuracy: 96.23%
经过10个epochs,模型开始收敛,30个epochs准确率变化曲线如下所示:
3.4 基于pytorch不进行迁移学习的情况下进行网络训练
import torch
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import datetime
import numpy as npfrom torchvision.datasets import ImageFolder
from torchvision import transformsfrom torchvision.models import resnet50from sklearn.model_selection import train_test_split# 图像变换
transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]), ])
# 加载数据集
dataset = ImageFolder('./data/fruit', transform=transform)# 划分训练集与测试集
train_dataset, valid_dataset = train_test_split(dataset, test_size=0.2, random_state=0)batch_size = 64
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
test_loader = DataLoader(dataset=valid_dataset, batch_size=batch_size, shuffle=True, drop_last=True)checkpoint_path = './checkpoint/fruit_reg.pth'
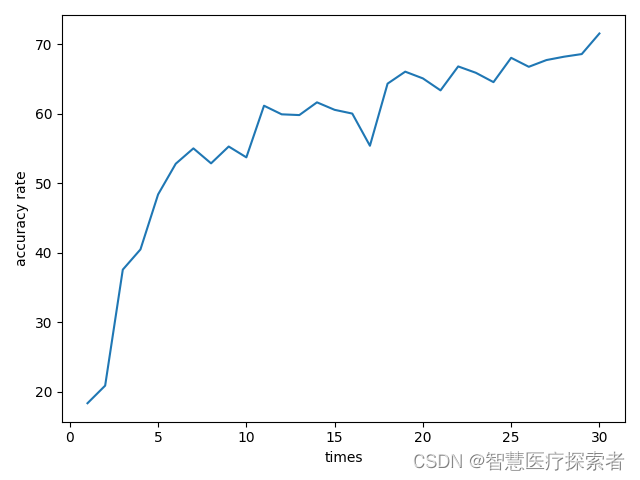
checkpoint_resume = Falseif __name__ == "__main__":# 加载预训练模型model = resnet50()# 替换最后一层全连接层,构建新的网络num_classes = len(dataset.classes)in_features = model.fc.in_featuresmodel.fc = torch.nn.Linear(in_features, num_classes)# 模型训练device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model.to(device)criterion = torch.nn.CrossEntropyLoss()optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)num_epochs = 10accuracy_rate = []for epoch in range(num_epochs):print('Epoch [{}/{}], start'.format(epoch + 1, num_epochs))for inputs, labels in train_loader:inputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch + 1, num_epochs, loss.item()))# 模型验证model.eval()correct = 0total = 0with torch.no_grad():for inputs, labels in test_loader:inputs, labels = inputs.to(device), labels.to(device)outputs = model(inputs)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()accuracy = correct / total * 100accuracy_rate.append(accuracy)print('Accuracy: {:.2f}%'.format(accuracy))accuracy_rate = np.array(accuracy_rate)times = np.linspace(1, num_epochs, num_epochs)plt.xlabel('times')plt.ylabel('accuracy rate')plt.plot(times, accuracy_rate)plt.show()print(f"{datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')},accuracy_rate={accuracy_rate}")torch.save(model.state_dict(), checkpoint_path)Epoch [1/30], Loss: 2.1676 Accuracy: 18.32%Epoch [2/30], Loss: 1.9645 Accuracy: 20.85%Epoch [3/30], Loss: 1.9394 Accuracy: 37.55%Epoch [4/30], Loss: 1.3242 Accuracy: 40.46%Epoch [5/30], Loss: 1.1633 Accuracy: 48.38%Epoch [6/30], Loss: 1.4852 Accuracy: 52.80%Epoch [7/30], Loss: 1.0438 Accuracy: 55.01%Epoch [8/30], Loss: 1.2010 Accuracy: 52.86%Epoch [9/30], Loss: 0.9826 Accuracy: 55.28%Epoch [10/30], Loss: 1.0562 Accuracy: 53.72%Epoch [11/30], Loss: 1.2049 Accuracy: 61.15%Epoch [12/30], Loss: 1.0919 Accuracy: 59.91%Epoch [13/30], Loss: 0.7103 Accuracy: 59.81%Epoch [14/30], Loss: 0.7970 Accuracy: 61.64%Epoch [15/30], Loss: 1.4505 Accuracy: 60.56%Epoch [16/30], Loss: 1.0294 Accuracy: 60.02%Epoch [17/30], Loss: 1.0225 Accuracy: 55.39%Epoch [18/30], Loss: 0.9417 Accuracy: 64.33%Epoch [19/30], Loss: 0.7826 Accuracy: 66.06%Epoch [20/30], Loss: 0.8774 Accuracy: 65.09%Epoch [21/30], Loss: 0.9671 Accuracy: 63.36%Epoch [22/30], Loss: 0.7064 Accuracy: 66.81%Epoch [23/30], Loss: 0.6465 Accuracy: 65.89%Epoch [24/30], Loss: 0.7217 Accuracy: 64.55%Epoch [25/30], Loss: 0.7089 Accuracy: 68.05%Epoch [26/30], Loss: 0.8506 Accuracy: 66.76%Epoch [27/30], Loss: 0.9541 Accuracy: 67.73%Epoch [28/30], Loss: 1.1595 Accuracy: 68.21%Epoch [29/30], Loss: 0.8493 Accuracy: 68.59%Epoch [30/30], Loss: 0.8297 Accuracy: 71.55%如果不采用迁移学习(即不加载Restnet50的预训练模型),经过30 epochs的训练后,模型并未收敛,得到的准确率曲线如下:
4 总结
本项目在Restnet50预训练模型的基础上,通过迁移学习,在水果数据上实现模型的训练和识别,经过30个epoches,在测试集上的准确率达到了96%,模型完成了快速收敛。
从训练效果来看,无论是准确率还是收敛速度,采用迁移学习后的网络都远高于未采用迁移学习的网络,充分体现了迁移学习价值。
此迁移学习训练方法可以扩展应用于其他数据集,在有限的数据集和计算资源的情况下,使用迁移学习可以快速训练出表现良好的分类识别模型。
项目完整代码:代码地址