docker知识:
比如写了个项目,并且在本地调试没有任务问题,这时候你想在另外一台电脑或者服务器运行,那么你需要在另外一台电脑或者服务器配置相同的软件,比如数据库,web服务器,必要的插件和库等等,而且你还不能保证软件一定能够运行起来,因为别人用的可能是完全不同的操作系统,即便同样使用linux系统,每个发行版也会有不同的区别,为了模拟完全相同的本地开发环境。
我们想到可以用虚拟机,但是虚拟机需要运行整个操作系统,不但体积臃肿,内存占用高,程序性能也会受到影响,这时候我们的docker就派上用场。
docker容器
docker在概念上与虚拟机非常相似,但却轻量很多,不会去模拟底层硬件,只会为每个应用提供完全隔离的运行环境,你可以在环境中配置不同的工具软件,并且不同环境之间相互不影响。
这个“环境”在docker中也被称做container(容器)
讲到这里我们就不得不提docker 中夫人三个重要的概念:dockerfile,镜像(image)和container(容器)
镜像(image)
你可以把它理解成一个虚拟机的快照,里面包含了你需要部署的应用程序以及它关联的所有库,通过镜像,我们可以创造不同的容器,
这里的容器就像以台台运行起来的虚拟机,里面运行了你的应用程序,每个容器 是独立运行的,他们相互之间不影响
dockerfile
dockerfile:就像是一个自动化脚本,它主要用来创建我们的镜像,这个过程就好比在虚拟机安装操作系统和软件一样,只不过是通过dockerfile这个自动化脚本完成
dockerfile文件创建:首先我们在应用的根目录创建一个dockerfile文件,第一行我们需要用FROM指令指定一个基础镜像 例如python3.8,这样可以帮我们节省很多软件安装.免去我们安装Python的步骤
2.通过WORKDIR /app创建工作目录,如果目录不存在docker 会自动帮你创建,这样可以避免使用绝对路径或者手动cd切换路径,增加程序的可读性
3.之后可以调用COPY命令将所有的程序拷贝到DOCKER镜像中COPY <本地路径><目标路径>:
COPY . . 第一个“.”代表程序的根目录下的所有文件,第二个参数代表docker 镜像中的路径,这里的“.”代表当前的工作路径,也就是之前指定的/app目录
4.之后RUN指令允许我们在创建镜像时运行任意的shell指令,因为用的是linux镜像,例如RUN pip install -r requirement.txt来安装Python程序的所有关联的库
5.通过以上的所有指令我们就可以完成一个docker 镜像的创建
6.在dockerfile的最后,我们用CMD指令来指定当docker容器运行起来后要执行的命令,例如python app.py 运行python脚本
要主要容器和镜像的区别,RUN是创建镜像的时候使用的,而CMD是运行容器时候使用的,到这里我们的dockerfile自动化脚本就完成了
7.接下来我们可以使用docker build指令来创建一个镜像 -t指定镜像的名字后面的点则代表,在当前目录寻找这个dockerfile例如:docker build -t my_image .
第一次调用docker build构建镜像会比较慢,因为Docker 会下载必要的镜像文件,然后一行行的执行我们的指令,不过再次调用docker build就会快很多,因为docker 会缓存之前的每一个操作,这个在docker中也被称之为分层
8.有了镜像以后,我们通过docker run来启动一个容器例如:docker run -p 80:5000 -d my_image
这里的-p参数,他会将容器上的某一个端口,映射到本地端口,这样你才能从主机上访问容器中的应用 ,前面的80端口是我们主机上的端口,后面的5000端口是我们容器上的端口
-d 表示后台运行,不出意外的话容器运行成功
docker 相关指令:
docker ps :列举所有的容器
docker stop <容器id> :停止容器运行
docker restrart <容器id> :重启容器
docker rm <容器id> :删除容器
docker exec -it <容器id> /bin/bash 进入容器
需要注意的是我们删除一个容器时,容器里面的东西会消失,因此我们可以使用Docker提供的volume 数据卷
你可以把他 当作是一个在本地主机和不同容器中共享的文件夹,比如你在某一个容器中修改了某一个数据卷的数据,他会同时反应在其他的容器上
在启动容器的时候,我们可以通过-v指令参数指定,将数据卷挂载到容器中的某一个路径上
例如:docker run -d -p 80:5000 -v /etc: /etc1 将本地/etc目录挂载到容器/etc1目录下,向这个路径写入的任何数据都会被永久的保存到这个数据卷中
docker compose
9.之前我们讲的例子都是只涉及到单个容器,但是在实际的使用中 ,我们的应用 容器可能会涉及到多个的容器共同协作比如我们可以使用一个容器来运行web应用,另外一个容器来运行数据库,这样可以做到数据和应用逻辑的有效分离,比如当web程序宕机了,数据库依然在有效的运作,这时候我们,
只需要修复web容器即可
10.docker compose刚好可以帮我们做到这点,我们可以创建一个docker-compose.yml文件,在这个文件下,我们通过services来定义多个容器,比如定义一个web容器,来运行我们的web运用
,然后在定义一个db容器里面运行了mysql数据库,这里我们可以通过两个环境变量,指定数据库的名字和连接密码,同时在db容器中模拟还可以通过volumes指定一个数据卷来永久存放数据
定义完毕后保存文件
11.使用docker compose up -d 来运行我们所有容器 这里的-d同样是指后台运行
docker compose down . 停止并删除所有容器
docker 指令、 dockerfile、和docker compose的相关指令自行百度
K8S知识:
docker和k8s的区别和联系
docker和k8s并不是一个层面的东西,在之前的例子中,我们的应用,数据库都是运行在同一台计算机中,随着应用规模的变大,一台服务器没有办法满足我们的需求
当我们香使用一个集群的服务器来提供服务,并做到负载均衡,故障转移等,这个时候就用到k8s,k8s所做的就是将你的每个容器分发到一个集群上运行,并进行全自动化的管理,包括应用的部署和升级
k8s是谷歌的开源工具,它是介于应用服务和服务器之间的中间层,能够通过策略,协调和管理多个应用服务,只需要一个yaml文件配置,定义应用的部署信息,就能自动部署应用到各个服务器上
并且能够让他们 自动扩缩容,而且做到了挂了后在其他的服务器上自动的部署应用
k8s的架构原理:
k8s将服务器划分为2个部分,一部分叫控制平面,另外一部分是工作节点node ,简单来说,他们的关系就是老板和员工的关系,控制平面负责控制和管理各个node ,而node 则负责实际的运行各个应用 服务

master控制平面内部组件:
API server组件
1.以前我们需要登录到各个服务器上手动执行命令,现在我们只需要调用k8s提供的APi接口,就能够操作这些服务器资源,这些接口都是由API server组件提供
scheduile调度器
2.以前我们需要到处看下哪台服务器的CPU和内存资源充足,然后才能够部署应用,现在这部分决策逻辑,由scheduile调度器来完成
controller manager(控制器管理器)
3.找到服务器后,以前我们会手动创建关闭服务,现在这部分功能由controller manager(控制器管理器)来完成
ETCD
4.上面的功能都会产生一些数据,这些数据需要保存到存储层,所以还需要一个ETCD
以上就是控制平面的内部组件
node内部组件:
1.node是实际的工作节点,它既可以是实际的物理机,也可以是虚拟机,它会负责实际运行各个应用服务器。多个运用服务共享一台node上的内存和CPU资源
2.以前我们需要上传代码到服务器上,而用了k8s后,我们只需要将代码打包成容器镜像,就能一行命令将它部署,容器镜像的含义就是将应用代码和依赖的系统环境打成一个压缩包,在任意一台机器上解压运行
container runtime(容器运行时组件)
3.为了下载和部署镜像noder中会有一个container runtime,也就是容器运行时组件
pod
4.每个应用服务都可认为是一个容器,并且大多数时候我们还会给应用配置一个日志容器或者监控采集器container,这多个container共同组成一个一个的pod,pod运行在node 上
5.K8s可以将pod从某一个node调度到另一个node 上,还能以pod为单位去做重启和动态扩容或者缩容的操作,所有所POD是K8S中最小的调度单位
kubectl
6.控制平面会通过controller manager(控制器管理器)控制node创建和关闭服务,那node也得有个组件能接受到这个指令,才能去完成这个动作,这个组件叫kubectl ,它主要负责管理和监控pod
kube proxy
7.最后node中还有个kube proxy ,它负责node 的网络通信功能,有了它外部的请求就能够用被转发到pod中
ingress控制器
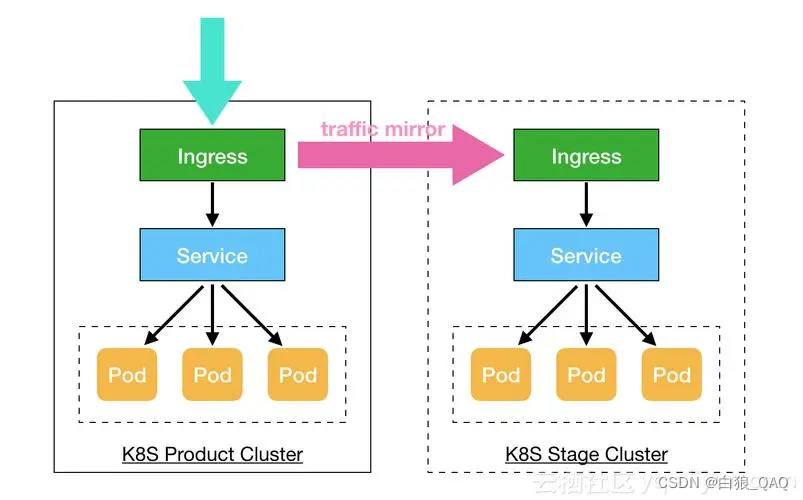
控制平面和node共同构成了一个集群,在公司中一般会构建多个集群,比如测试环境用一个集群,生产环境用另外一个集群,同时为了将 集群内部服务暴露给外部用户使用,一般还会部署一个入口控制器
比如ingress控制器,提供一个入口,让外部用户可以访问集群内部服务
kubectl 是什么?
前面提到说我们可以使用K8S提供的api去创建服务,但是问题就来了,这是需要我们自己写代码去调度这些API吗?答案是不需要
k8s为我们准备了一个命令行工具:kubectl我们只需要执行指令,它内部就会去调用k8s的API
K8S怎么部署服务?
1.首先我们需要编写yaml文件在里面定义Pod用到了哪些镜像,占用了多少内存和CPU
2.然后使用kubectl命令行工具执行kubectl apply -f xx.yaml 此时kubectl将读取和解析yaml文件,将解析后的对象通过API请求发送给K8S
3.控制平面的API Server会根据要求驱使scheduler调度器通过etcd提供的数据,找到合适的node
4.再让controller manager(控制器管理器)控制node创建服务,node 内部的kubectl组件接受到命令后,会开始基于container runtime,也就是容器运行时组件去拉去镜像,创建容器,最终完成pod创建 ,服务启动完成
5.全程只需要创建一个yaml 和执行一次kubectl指令,比以前省事太多
服务调用原理
1.以前小明直接在浏览器发送http请求就能达到我们的服务器上的nginx,然后转发到部署的服务内部
2.有了K8S后,外部请求会先到k8s集群的ingress控制器,然后再转发到K8S内某个node 的kube proxy上,再找到对应的pod后才转发到对应的内部服务中,处理请求后,结果原路返回,这就完成了一个服务调用