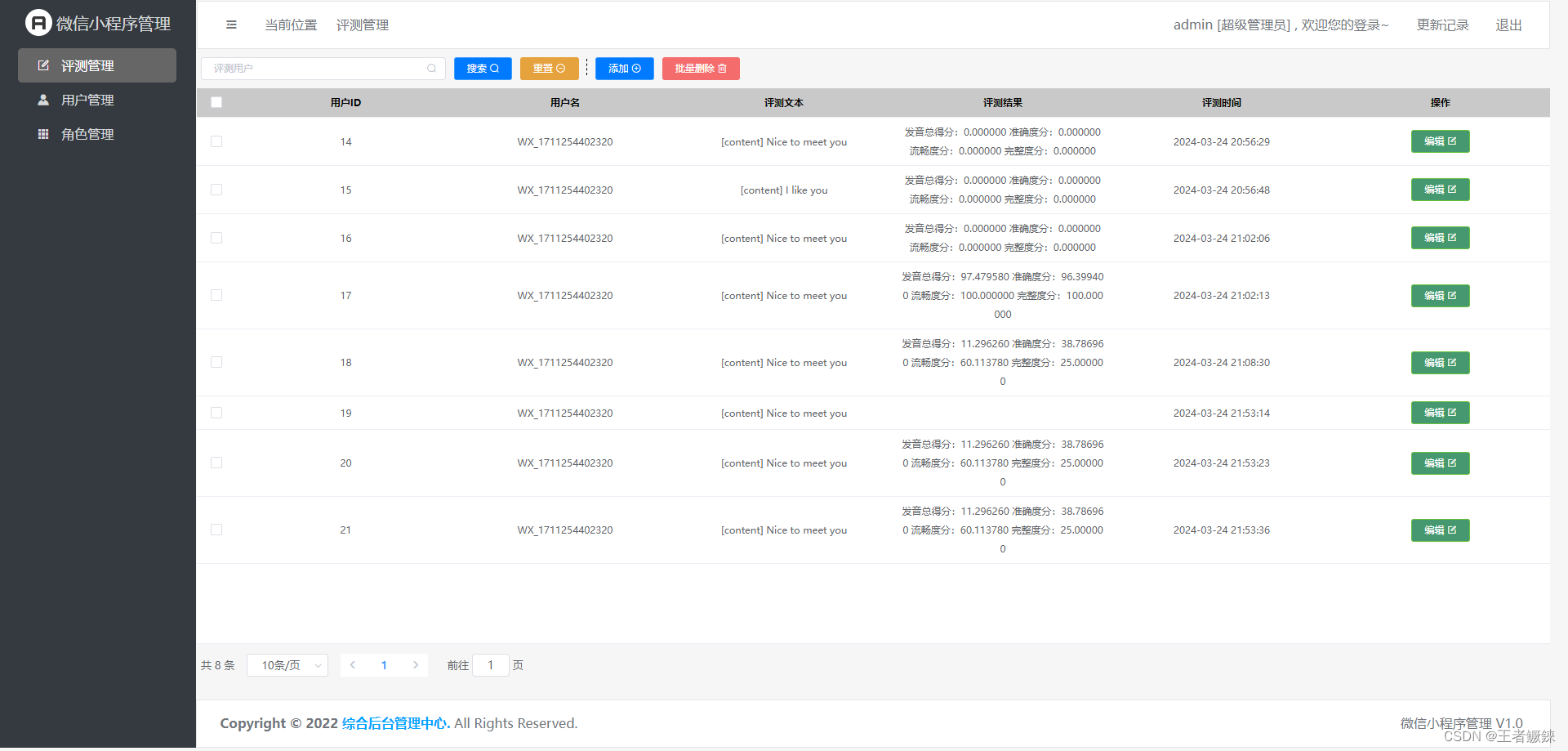
一. RAG简介
在自然语言处理(NLP)领域中,检索增强生成(Retrieval-Augmented Generation, RAG)技术巧妙地结合了信息检索与神经网络生成模型的力量,通过在生成过程中引入相关的外部信息,实现了在大规模知识库基础上的精准、多样且具有上下文关联性的文本生成。
RAG技术的目的在于提高生成模型的性能,其关键创新在于打破传统生成模型仅仅依赖自身参数预测输出的限制,转而引入检索策略获取外部知识库中的相关信息,再利用这些信息引导模型生成更准确、更具信息量的内容。这一革新极大地提升了模型在问答、对话系统、文本摘要等多种任务上的表现。
二. RAG实现流程
1、检索阶段
在RAG技术中,首先需要通过信息检索技术从外部知识库(通常是对大规模文本数据集进行索引处理后形成的数据库)中检索与输入文本相关的信息。
这通常涉及到构建倒排索引、使用BM25等排名算法对检索结果进行排序等操作。检索到的信息可以是文本片段、关键词或结构化数据等。
- 构建索引:对知识库中的每一个文档片段或句子进行编码,得到对应的向量表示,并存储在索引中,以便快速检索。
- 目标查询:给定一个输入文本(如问题),利用编码器将其转换成高维向量表示。
- 检索过程:使用高效的近似最近邻搜索算法(如Annoy、FAISS等)找出与输入向量最相似的一组文档片段。
2、融合阶段
检索到的信息需要与输入文本进行融合,以便为生成模型提供丰富的上下文。信息融合的方式可以根据具体任务进行调整,以最大限度地发挥检索信息的作用。
- 信息融合:将检索出的文档片段作为生成模型的输入、上下文或指导信号与原始输入一同输入至融合模块,如跨模态或多头注意力机制,计算每个片段对生成答案的重要程度。
- 上下文更新:根据各片段的权重综合构建一个包含了外部知识的增强上下文表示。
3、生成阶段
使用预训练的自然语言生成模型(如GPT-2、T5等),根据输入的信息生成相应的输出。
- 条件生成:将增强后的上下文输入至解码器,进行自回归式的序列生成,产出最终的回答或其他形式的文本。在生成过程中,可以利用检索到的相关信息来指导生成过程,从而提高生成内容的质量和多样性。
- 后处理:对生成的结果进行后处理,如去除重复、调整句子结构等,以获得更好的生成效果。
下面是一个基于Hugging Face Transformers库实现的RAG模型基本运行示例:
from transformers import RagTokenForGeneration, RagTokenizer# 加载预训练好的RAG模型和分词器
model = RagTokenForGeneration.from_pretrained("facebook/rag-token")
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token")# 示例问题
question = "哈利·波特系列小说的作者是谁?"# 将问题进行编码
inputs = tokenizer(question, return_tensors="pt")# 使用RAG模型生成答案
outputs = model.generate(inputs["input_ids"], num_return_sequences=1)# 解码并打印生成的答案
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"答案是:{answer}")
三. RAG技术的作用与价值
RAG技术在文本生成任务中发挥了重要作用,具体体现在以下几个方面:
-
提升生成质量
通过引入外部知识库中的信息,RAG技术能够生成更加准确、丰富和具有上下文的文本。这有助于解决传统生成模型中普遍存在的重复、冗余和缺乏创意等问题。 -
增加多样性
RAG技术结合了检索和生成两种能力,使得生成的文本具有更高的多样性。检索到的不同信息可以为生成模型提供不同的输入和上下文,从而产生多样化的输出。 -
减少事实错误(缓解模型幻觉)
在知识密集型任务中,RAG技术能够通过检索外部知识库中的事实信息,减少生成文本中的事实错误。这有助于提高文本的可信度和准确性。
RAG技术的主要应用体现在那些需要大量背景知识和精确上下文理解的场景,具体包括但不限于:
- 开放域问答:面对未知领域的复杂问题,RAG模型可以即时检索相关知识并生成高质量答案。
- 对话系统:在多轮对话中,模型能依据历史对话内容检索相关信息,从而生成连贯且有深度的回应。
- 文档摘要与生成:借助知识库中的信息,模型能更好地提炼和合成文档的关键信息。
四. 补充说明
除了RAG之外,还有一些同类的混合检索与生成模型值得关注,如REALM(Retrieval-Enhanced Language Model)、KNN-LM(K Nearest Neighbor Language Model)等。它们都试图通过融合外部知识库来扩展模型的知识范围和生成能力,但在检索策略、知识融合机制以及模型架构等方面存在差异。
尽管RAG技术在文本生成任务中取得了显著成果,但仍面临一些挑战。首先,检索过程可能受到知识库质量和覆盖面的限制,导致无法找到与输入文本完全匹配的信息。其次,信息融合的方式和生成模型的性能对最终生成结果的质量具有重要影响,需要仔细设计和调整。


![[套路] 浏览器引入Vue.js场景-WangEditor富文本编辑器的使用 (永久免费)](https://img-blog.csdnimg.cn/direct/7d003533fd61452c805872c31636e5b8.png)