AI目录:sheng的学习笔记-AI目录-CSDN博客
目录
目标定位(Object localization)
定义
原理图
具体做法:
输出向量
图片中没有检测对象的样例
损失函数
编辑 特征点检测(Landmark detection)
定义:
具体做法:
目标检测(Object detection)
滑动窗口目标检测
缺陷:
滑动窗口的卷积实现(Convolutional implementation of sliding windows)
全连接层转化为卷积层
通过卷积实现滑动窗口对象检测算法
总结:
Bounding Box预测(Bounding box predictions)
YOLO算法(You only look once)
原理
确定边界框
交并比(Intersection over union)
非极大值抑制(Non-max suppression)
Anchor Boxes
候选区域(选修)(Region proposals (Optional))-R-CNN算法
完整的算法
目标定位(Object localization)
定义
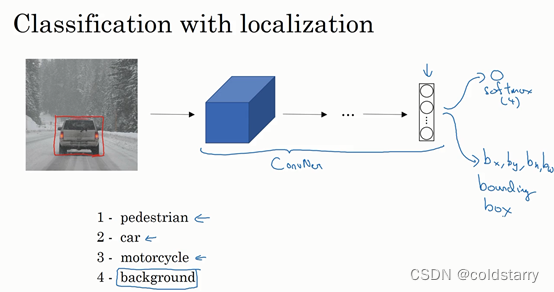
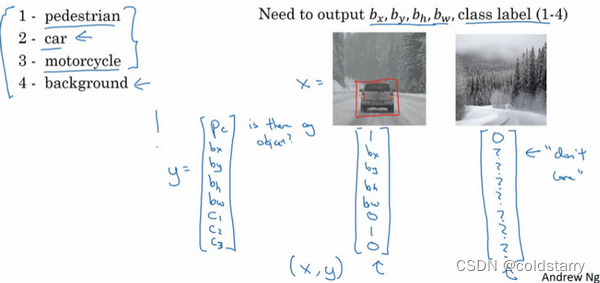
图片分类任务:判断其中的对象是不是汽车
定位分类:在图片中标记出它的位置,用边框或红色方框把汽车圈起来,这就是定位分类问题。其中“定位”的意思是判断汽车在图片中的具体位置。
通常只有一个较大的对象位于图片中间位置,我们要对它进行识别和定位。而在对象检测问题中,图片可以含有多个对象,甚至单张图片中会有多个不同分类的对象。因此,图片分类的思路可以帮助学习分类定位,而对象定位的思路又有助于学习对象检测

图片分类的例子:输入一张图片到多层卷积神经网络。这就是卷积神经网络,它会输出一个特征向量,并反馈给softmax单元来预测图片类型。
原理图
如果你正在构建汽车自动驾驶系统,那么对象可能包括以下几类:行人、汽车、摩托车和背景,这意味着图片中不含有前三种对象,也就是说图片中没有行人、汽车和摩托车,输出结果会是背景对象,这四个分类就是softmax函数可能输出的结果。
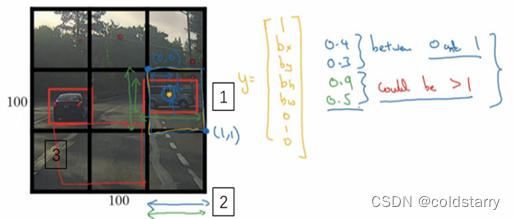
具体做法:
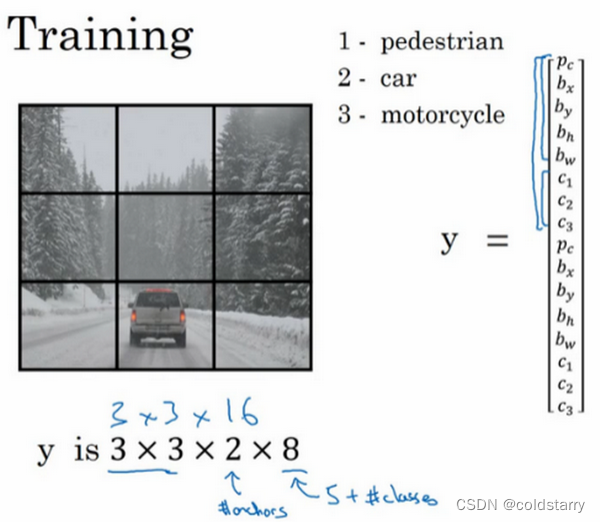
输出向量
我们可以让神经网络多输出几个单元,输出一个边界框。具体说就是让神经网络再多输出4个数字,标记bx,by,bh,bw,这四个数字是被检测对象的边界框的参数化表示。


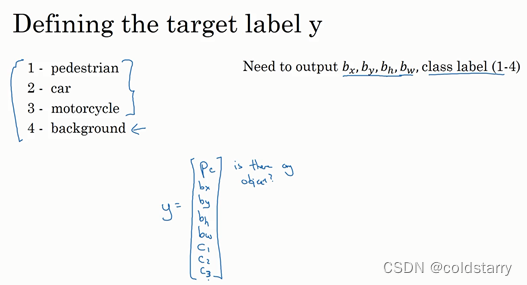


图片中没有检测对象的样例


损失函数


 特征点检测(Landmark detection)
特征点检测(Landmark detection)
定义:


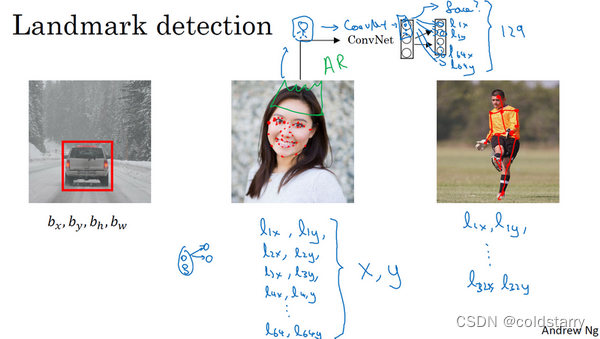
也许除了这四个特征点,你还想得到更多的特征点输出值,这些(图中眼眶上的红色特征点)都是眼睛的特征点,你还可以根据嘴部的关键点输出值来确定嘴的形状,从而判断人物是在微笑还是皱眉,也可以提取鼻子周围的关键特征点。为了便于说明,你可以设定特征点的个数,假设脸部有64个特征点,有些点甚至可以帮助你定义脸部轮廓或下颌轮廓。选定特征点个数,并生成包含这些特征点的标签训练集,然后利用神经网络输出脸部关键特征点的位置。
具体做法:

目标检测(Object detection)
学过了对象定位和特征点检测,今天我们来构建一个对象检测算法。这节课,我们将学习如何通过卷积网络进行对象检测,采用的是基于滑动窗口的目标检测算法。


滑动窗口目标检测

假设这是一张测试图片,首先选定一个特定大小的窗口,比如图片下方这个窗口,将这个红色小方块输入卷积神经网络,卷积网络开始进行预测,即判断红色方框内有没有汽车。

滑动窗口目标检测算法接下来会继续处理第二个图像,即红色方框稍向右滑动之后的区域,并输入给卷积网络,因此输入给卷积网络的只有红色方框内的区域,再次运行卷积网络,然后处理第三个图像,依次重复操作,直到这个窗口滑过图像的每一个角落。
为了滑动得更快,我这里选用的步幅比较大,思路是以固定步幅移动窗口,遍历图像的每个区域,把这些剪切后的小图像输入卷积网络,对每个位置按0或1进行分类,这就是所谓的图像滑动窗口操作。

重复上述操作,不过这次我们选择一个更大的窗口,截取更大的区域,并输入给卷积神经网络处理,你可以根据卷积网络对输入大小调整这个区域,然后输入给卷积网络,输出0或1。

再以某个固定步幅滑动窗口,重复以上操作,遍历整个图像,输出结果。
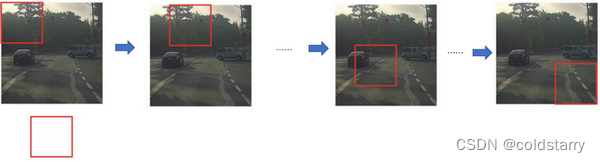
然后第三次重复操作,这次选用更大的窗口。
如果你这样做,不论汽车在图片的什么位置,总有一个窗口可以检测到它。

比如,将这个窗口(编号1)输入卷积网络,希望卷积网络对该输入区域的输出结果为1,说明网络检测到图上有辆车。
这种算法叫作滑动窗口目标检测,因为我们以某个步幅滑动这些方框窗口遍历整张图片,对这些方形区域进行分类,判断里面有没有汽车。
缺陷:
滑动窗口目标检测算法也有很明显的缺点,就是计算成本,因为你在图片中剪切出太多小方块,卷积网络要一个个地处理。如果你选用的步幅很大,显然会减少输入卷积网络的窗口个数,但是粗糙间隔尺寸可能会影响性能。反之,如果采用小粒度或小步幅,传递给卷积网络的小窗口会特别多,这意味着超高的计算成本。
滑动窗口的卷积实现(Convolutional implementation of sliding windows)
为了构建滑动窗口的卷积应用,首先要知道如何把神经网络的全连接层转化成卷积层
假设对象检测算法输入一个14×14×3的图像。在这里过滤器大小为5×5,数量是16,14×14×3的图像在过滤器处理之后映射为10×10×16。然后通过参数为2×2的最大池化操作,图像减小到5×5×16。然后添加一个连接400个单元的全连接层,接着再添加一个全连接层,最后通过softmax单元输出y。为了跟下图区分开,我先做一点改动,用4个数字来表示y,它们分别对应softmax单元所输出的4个分类出现的概率。这4个分类可以是行人、汽车、摩托车和背景或其它对象。

全连接层转化为卷积层
画一个这样的卷积网络,它的前几层和之前的一样,而对于下一层,也就是这个全连接层,我们可以用5×5的过滤器来实现,数量是400个(编号1所示),输入图像大小为5×5×16,用5×5的过滤器对它进行卷积操作,过滤器实际上是5×5×16,因为在卷积过程中,过滤器会遍历这16个通道,所以这两处的通道数量必须保持一致,输出结果为1×1。假设应用400个这样的5×5×16过滤器,输出维度就是1×1×400,我们不再把它看作一个含有400个节点的集合,而是一个1×1×400的输出层。从数学角度看,它和全连接层是一样的,因为这400个节点中每个节点都有一个5×5×16维度的过滤器,所以每个值都是上一层这些5×5×16激活值经过某个任意线性函数的输出结果。
我们再添加另外一个卷积层(编号2所示),这里用的是1×1卷积,假设有400个1×1的过滤器,在这400个过滤器的作用下,下一层的维度是1×1×400,它其实就是上个网络中的这一全连接层。最后经由1×1过滤器的处理,得到一个softmax激活值,通过卷积网络,我们最终得到这个1×1×4的输出层,而不是这4个数字(编号3所示)。
以上就是用卷积层代替全连接层的过程,结果这几个单元集变成了1×1×400和1×1×4的维度
通过卷积实现滑动窗口对象检测算法

假设向滑动窗口卷积网络输入14×14×3的图片,为了简化演示和计算过程,这里我们依然用14×14的小图片。和前面一样,神经网络最后的输出层,即softmax单元的输出是1×1×4,我画得比较简单,严格来说,14×14×3应该是一个长方体,第二个10×10×16也是一个长方体,但为了方便,我只画了正面。所以,对于1×1×400的这个输出层,我也只画了它1×1的那一面,所以这里显示的都是平面图,而不是3D图像
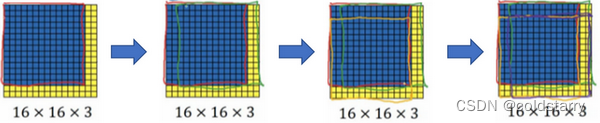
假设输入给卷积网络的图片大小是14×14×3,测试集图片是16×16×3,现在给这个输入图片加上黄色条块,在最初的滑动窗口算法中,你会把这片蓝色区域输入卷积网络(红色笔标记)生成0或1分类。接着滑动窗口,步幅为2个像素,向右滑动2个像素,将这个绿框区域输入给卷积网络,运行整个卷积网络,得到另外一个标签0或1。继续将这个橘色区域输入给卷积网络,卷积后得到另一个标签,最后对右下方的紫色区域进行最后一次卷积操作。我们在这个16×16×3的小图像上滑动窗口,卷积网络运行了4次,于是输出了了4个标签
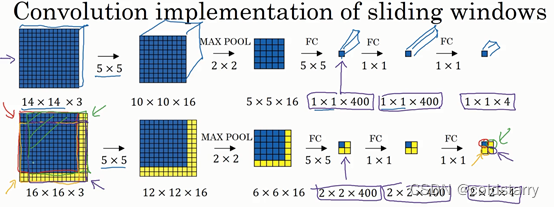
结果发现,这4次卷积操作中很多计算都是重复的。所以执行滑动窗口的卷积时使得卷积网络在这4次前向传播过程中共享很多计算,尤其是在这一步操作中(编号1),卷积网络运行同样的参数,使得相同的5×5×16过滤器进行卷积操作,得到12×12×16的输出层。然后执行同样的最大池化(编号2),输出结果6×6×16。照旧应用400个5×5的过滤器(编号3),得到一个2×2×400的输出层,现在输出层为2×2×400,而不是1×1×400。应用1×1过滤器(编号4)得到另一个2×2×400的输出层。再做一次全连接的操作(编号5),最终得到2×2×4的输出层,而不是1×1×4。最终,在输出层这4个子方块中,蓝色的是图像左上部分14×14的输出(红色箭头标识),右上角方块是图像右上部分(绿色箭头标识)的对应输出,左下角方块是输入层左下角(橘色箭头标识),也就是这个14×14区域经过卷积网络处理后的结果,同样,右下角这个方块是卷积网络处理输入层右下角14×14区域(紫色箭头标识)的结果
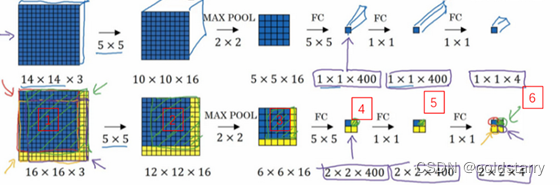
如果你想了解具体的计算步骤,以绿色方块为例,假设你剪切出这块区域(编号1),传递给卷积网络,第一层的激活值就是这块区域(编号2),最大池化后的下一层的激活值是这块区域(编号3),这块区域对应着后面几层输出的右上角方块(编号4,5,6)。
所以该卷积操作的原理是我们不需要把输入图像分割成四个子集,分别执行前向传播,而是把它们作为一张图片输入给卷积网络进行计算,其中的公共区域可以共享很多计算,就像这里我们看到的这个4个14×14的方块一样。

下面我们再看一个更大的图片样本,假如对一个28×28×3的图片应用滑动窗口操作,如果以同样的方式运行前向传播,最后得到8×8×4的结果。跟上一个范例一样,以14×14区域滑动窗口,首先在这个区域应用滑动窗口,其结果对应输出层的左上角部分。接着以大小为2的步幅不断地向右移动窗口,直到第8个单元格,得到输出层的第一行。然后向图片下方移动,最终输出这个8×8×4的结果。因为最大池化参数为2,相当于以大小为2的步幅在原始图片上应用神经网络。

总结:
总结一下滑动窗口的实现过程,在图片上剪切出一块区域,假设它的大小是14×14,把它输入到卷积网络。继续输入下一块区域,大小同样是14×14,重复操作,直到某个区域识别到汽车。
但是正如在前一页所看到的,我们不能依靠连续的卷积操作来识别图片中的汽车,比如,我们可以对大小为28×28的整张图片进行卷积操作,一次得到所有预测值,如果足够幸运,神经网络便可以识别出汽车的位置。

不过这种算法仍然存在一个缺点,就是边界框的位置可能不够准确,在 Bounding Box预测 中解决这个问题
Bounding Box预测(Bounding box predictions)
滑动窗口法的卷积实现,这个算法效率更高,但仍然存在问题,不能输出最精准的边界框。在这个视频中,我们看看如何得到更精准的边界框

在滑动窗口法中,你取这些离散的位置集合,然后在它们上运行分类器,在这种情况下,这些边界框没有一个能完美匹配汽车位置,也许这个框(编号1)是最匹配的了。还有看起来这个真实值,最完美的边界框甚至不是方形,稍微有点长方形(红色方框所示),长宽比有点向水平方向延伸,有没有办法让这个算法输出更精准的边界框呢?
其中一个能得到更精准边界框的算法是YOLO算法,YOLO(You only look once)意思是你只看一次
YOLO算法(You only look once)
事实上YOLO算法有一个好处,也是它受欢迎的原因,因为这是一个卷积实现,实际上它的运行速度非常快,可以达到实时识别
原理




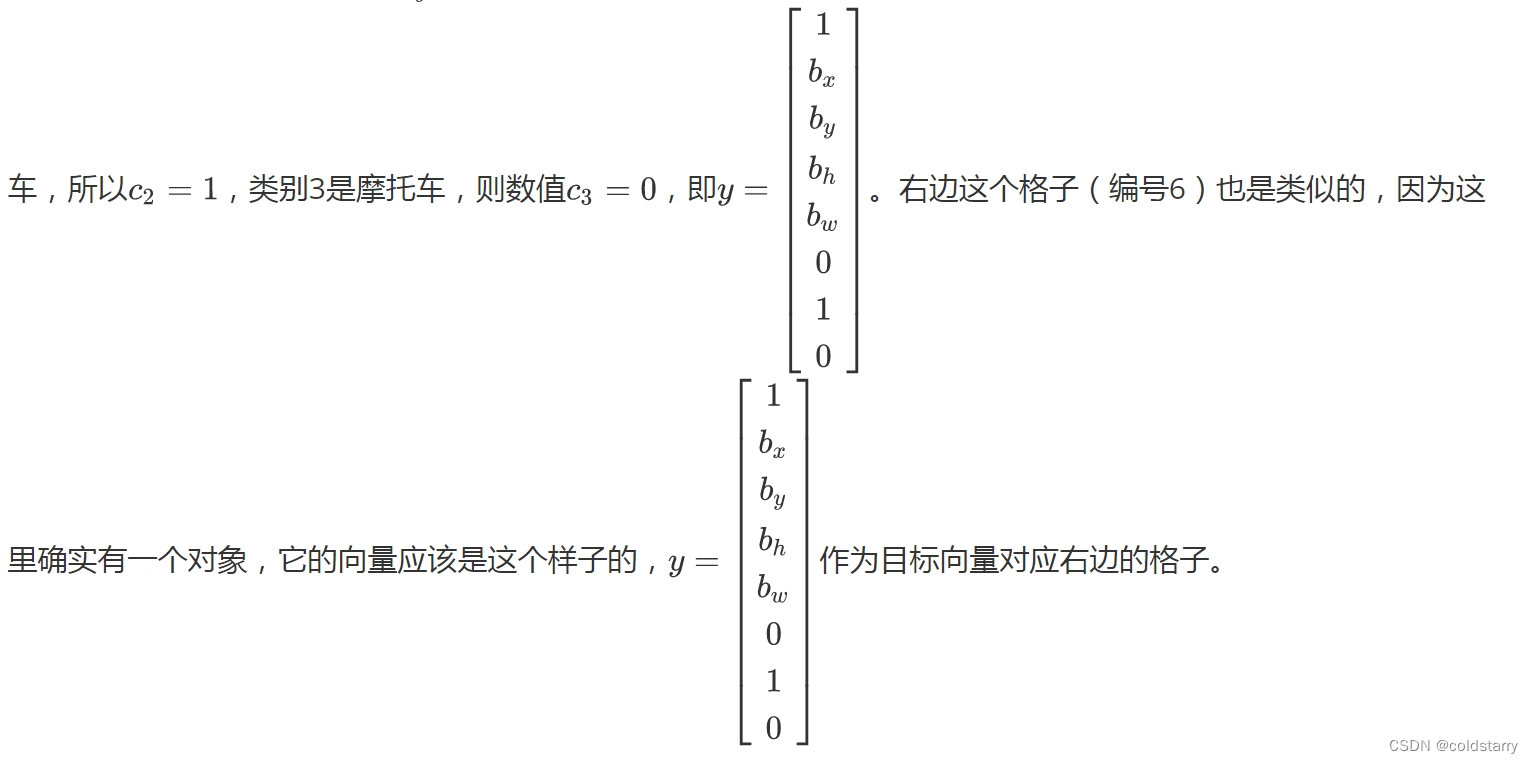
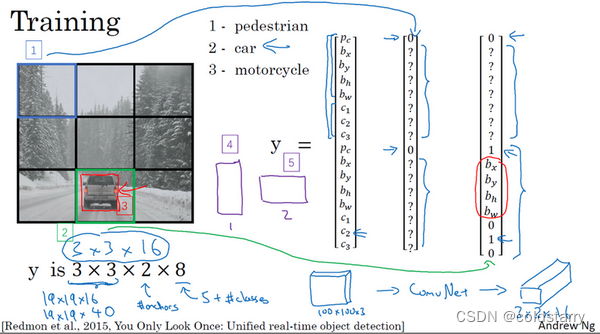
所以对于这里9个格子中任何一个,你都会得到一个8维输出向量,因为这里是3×3的网格,所以有9个格子,总的输出尺寸是3×3×8,所以目标输出是3×3×8。因为这里有3×3格子,然后对于每个格子,你都有一个8维向量,所以目标输出尺寸是3×3×8。

对于这个例子中,左上格子是1×1×8,对应的是9个格子中左上格子的输出向量。所以对于这3×3中每一个位置而言,对于这9个格子,每个都对应一个8维输出目标向量y。所以总的目标输出,这个图片的输出标签尺寸就是3×3×8

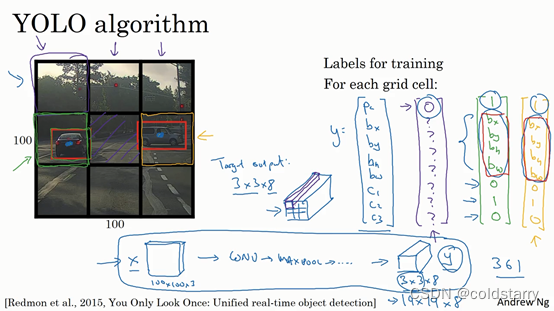
如果你现在要训练一个输入为100×100×3的神经网络,现在这是输入图像,然后你有一个普通的卷积网络,卷积层,最大池化层等等,最后你会有这个,选择卷积层和最大池化层,这样最后就映射到一个3×3×8输出尺寸。所以你要做的是,有一个输入x,就是这样的输入图像,然后你有这些3×3×8的目标标签y。当你用反向传播训练神经网络时,将任意输入x映射到这类输出向量y。

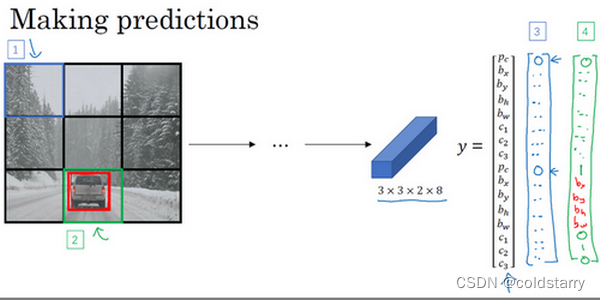
所以这个算法的优点在于神经网络可以输出精确的边界框,所以测试的时候,你做的是喂入输入图像x,然后跑正向传播,直到你得到这个输出y。然后对于这里3×3位置对应的9个输出,我们在输出中展示过的,你就可以读出1或0(编号1位置),你就知道9个位置之一有个对象。如果那里有个对象,那个对象是什么(编号3位置),还有格子中这个对象的边界框是什么(编号2位置)。只要每个格子中对象数目没有超过1个,这个算法应该是没问题的。一个格子中存在多个对象的问题,我们稍后再讨论。但实践中,我们这里用的是比较小的3×3网格,实践中你可能会使用更精细的19×19网格,所以输出就是19×19×8。这样的网格精细得多,那么多个对象分配到同一个格子得概率就小得多。
重申一下,把对象分配到一个格子的过程是,你观察对象的中点,然后将这个对象分配到其中点所在的格子,所以即使对象可以横跨多个格子,也只会被分配到9个格子其中之一,就是3×3网络的其中一个格子,或者19×19网络的其中一个格子。在19×19网格中,两个对象的中点(图中蓝色点所示)处于同一个格子的概率就会更低。
所以要注意,首先这和图像分类和定位算法非常像,我们在本周第一节课讲过的,就是它显式地输出边界框坐标,所以这能让神经网络输出边界框,可以具有任意宽高比,并且能输出更精确的坐标,不会受到滑动窗口分类器的步长大小限制。其次,这是一个卷积实现,你并没有在3×3网格上跑9次算法,或者,如果你用的是19×19的网格,19平方是361次,所以你不需要让同一个算法跑361次。相反,这是单次卷积实现,但你使用了一个卷积网络,有很多共享计算步骤,在处理这3×3计算中很多计算步骤是共享的,或者你的19×19的网格,所以这个算法效率很高。

确定边界框


交并比(Intersection over union)
用于判断对象检测算法运作良好

在对象检测任务中,你希望能够同时定位对象,所以如果实际边界框是这样的,你的算法给出这个紫色的边界框,那么这个结果是好还是坏?所以交并比(loU)函数做的是计算两个边界框交集和并集之比。两个边界框的并集是这个区域,就是属于包含两个边界框区域(绿色阴影表示区域),而交集就是这个比较小的区域(橙色阴影表示区域),那么交并比就是交集的大小,这个橙色阴影面积,然后除以绿色阴影的并集面积。

所以这是衡量定位精确度的一种方式,你只需要统计算法正确检测和定位对象的次数,你就可以用这样的定义判断对象定位是否准确。再次,0.5是人为约定,没有特别深的理论依据,如果你想更严格一点,可以把阈值定为0.6。有时我看到更严格的标准,比如0.6甚至0.7,但很少见到有人将阈值降到0.5以下。
人们定义loU这个概念是为了评价你的对象定位算法是否精准,但更一般地说,loU衡量了两个边界框重叠地相对大小。如果你有两个边界框,你可以计算交集,计算并集,然后求两个数值的比值,所以这也可以判断两个边界框是否相似
非极大值抑制(Non-max suppression)
到目前为止你们学到的对象检测中的一个问题是,你的算法可能对同一个对象做出多次检测,所以算法不是对某个对象检测出一次,而是检测出多次。非极大值抑制这个方法可以确保你的算法对每个对象只检测一次,我们讲一个例子。

假设你需要在这张图片里检测行人和汽车,你可能会在上面放个19×19网格,理论上这辆车只有一个中点,所以它应该只被分配到一个格子里,左边的车子也只有一个中点,所以理论上应该只有一个格子做出有车的预测。

实践中当你运行对象分类和定位算法时,对于每个格子都运行一次,所以这个格子(编号1)可能会认为这辆车中点应该在格子内部,这几个格子(编号2、3)也会这么认为。对于左边的车子也一样,所以不仅仅是这个格子,如果这是你们以前见过的图像,不仅这个格(编号4)子会认为它里面有车,也许这个格子(编号5)和这个格子(编号6)也会,也许其他格子也会这么认为,觉得它们格子内有车。
因为你要在361个格子上都运行一次图像检测和定位算法,那么可能很多格子都会举手说我的pc,我这个格子里有车的概率很高,而不是361个格子中仅有两个格子会报告它们检测出一个对象。所以当你运行算法的时候,最后可能会对同一个对象做出多次检测,所以非极大值抑制做的就是清理这些检测结果。这样一辆车只检测一次,而不是每辆车都触发多次检测。
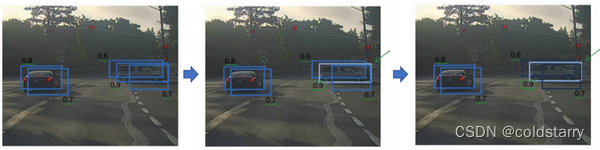


接下来,逐一审视剩下的矩形,找出概率最高,pc最高的一个,在这种情况下是0.8,我们就认为这里检测出一辆车(左边车辆),然后非极大值抑制算法就会去掉其他loU值很高的矩形。所以现在每个矩形都会被高亮显示或者变暗,如果你直接抛弃变暗的矩形,那就剩下高亮显示的那些,这就是最后得到的两个预测结果。
所以这就是非极大值抑制,非最大值意味着你只输出概率最大的分类结果,但抑制很接近,但不是最大的其他预测结果,所以这方法叫做非极大值抑制。
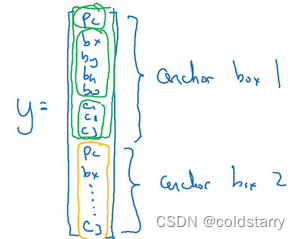
Anchor Boxes
到目前为止,对象检测中存在的一个问题是每个格子只能检测出一个对象,如果你想让一个格子检测出多个对象,你可以这么做,就是使用anchor box这个概念


而anchor box的思路是,这样子,预先定义两个不同形状的anchor box,或者anchor box形状,你要做的是把预测结果和这两个anchor box关联起来。一般来说,你可能会用更多的anchor box,可能要5个甚至更多,但对于这个视频,我们就用两个anchor box,这样介绍起来简单一些。



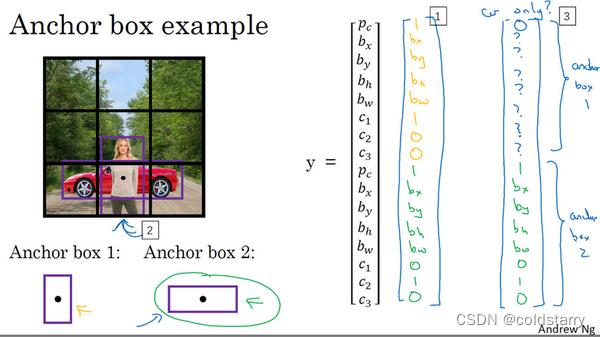
现在还有一些额外的细节,如果你有两个anchor box,但在同一个格子中有三个对象,这种情况算法处理不好,你希望这种情况不会发生,但如果真的发生了,这个算法并没有很好的处理办法,对于这种情况,我们就引入一些打破僵局的默认手段。还有这种情况,两个对象都分配到一个格子中,而且它们的anchor box形状也一样,这是算法处理不好的另一种情况,你需要引入一些打破僵局的默认手段,专门处理这种情况,希望你的数据集里不会出现这种情况,其实出现的情况不多,所以对性能的影响应该不会很大。
人们一般手工指定anchor box形状,你可以选择5到10个anchor box形状,覆盖到多种不同的形状,可以涵盖你想要检测的对象的各种形状。还有一个更高级的版本,我就简单说一句,你们如果接触过一些机器学习,可能知道后期YOLO论文中有更好的做法,就是所谓的k-平均算法,可以将两类对象形状聚类,如果我们用它来选择一组anchor box,选择最具有代表性的一组anchor box,可以代表你试图检测的十几个对象类别,但这其实是自动选择anchor box的高级方法。如果你就人工选择一些形状,合理的考虑到所有对象的形状,你预计会检测的很高很瘦或者很宽很胖的对象,这应该也不难做
候选区域(选修)(Region proposals (Optional))-R-CNN算法

你们还记得滑动窗法吧,你使用训练过的分类器,在这些窗口中全部运行一遍,然后运行一个检测器,看看里面是否有车辆,行人和摩托车。现在你也可以运行一下卷积算法,这个算法的其中一个缺点是,它在显然没有任何对象的区域浪费时间,对吧。

所以这里这个矩形区域(编号1)基本是空的,显然没有什么需要分类的东西。也许算法会在这个矩形上(编号2)运行,而你知道上面没有什么有趣的东西。
R-CNN的算法,意思是带区域的卷积网络,或者说带区域的CNN。这个算法尝试选出一些区域,在这些区域上运行卷积网络分类器是有意义的,所以这里不再针对每个滑动窗运行检测算法,而是只选择一些窗口,在少数窗口上运行卷积网络分类器。
选出候选区域的方法是运行图像分割算法,分割的结果是下边的图像,为了找出可能存在对象的区域。比如说,分割算法在这里得到一个色块,所以你可能会选择这样的边界框(编号1),然后在这个色块上运行分类器,就像这个绿色的东西(编号2),在这里找到一个色块,接下来我们还会在那个矩形上(编号2)运行一次分类器,看看有没有东西。在这种情况下,如果在蓝色色块上(编号3)运行分类器,希望你能检测出一个行人,如果你在青色色块(编号4)上运行算法,也许你可以发现一辆车,我也不确定

所以这个细节就是所谓的分割算法,你先找出可能2000多个色块,然后在这2000个色块上放置边界框,然后在这2000个色块上运行分类器,这样需要处理的位置可能要少的多,可以减少卷积网络分类器运行时间,比在图像所有位置运行一遍分类器要快。特别是这种情况,现在不仅是在方形区域(编号5)中运行卷积网络,我们还会在高高瘦瘦(编号6)的区域运行,尝试检测出行人,然后我们在很宽很胖的区域(编号7)运行,尝试检测出车辆,同时在各种尺度运行分类器。
git地址:
https://github.com/object-detection-algorithm/R-CNN
完整的算法
你们已经学到对象检测算法的大部分组件了,在这个视频里,我们会把所有组件组装在一起构成YOLO对象检测算法






最后你要运行一下这个非极大值抑制,为了让内容更有趣一些,我们看看一张新的测试图像,这就是运行非极大值抑制的过程。如果你使用两个anchor box,那么对于9个格子中任何一个都会有两个预测的边界框,其中一个的概率pc很低。但9个格子中,每个都有两个预测的边界框,比如说我们得到的边界框是是这样的,注意有一些边界框可以超出所在格子的高度和宽度(编号1所示)。接下来你抛弃概率很低的预测,去掉这些连神经网络都说,这里很可能什么都没有,所以你需要抛弃这些(编号2所示)。
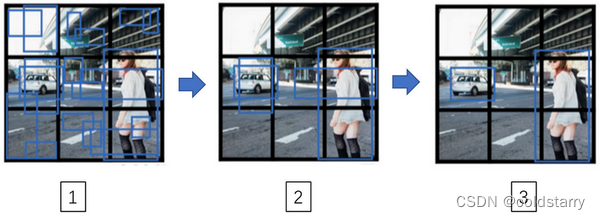
最后,如果你有三个对象检测类别,你希望检测行人,汽车和摩托车,那么你要做的是,对于每个类别单独运行非极大值抑制,处理预测结果所属类别的边界框,用非极大值抑制来处理行人类别,用非极大值抑制处理车子类别,然后对摩托车类别进行非极大值抑制,运行三次来得到最终的预测结果。所以算法的输出最好能够检测出图像里所有的车子,还有所有的行人(编号3所示)。
参考资料
吴恩达的深度学习