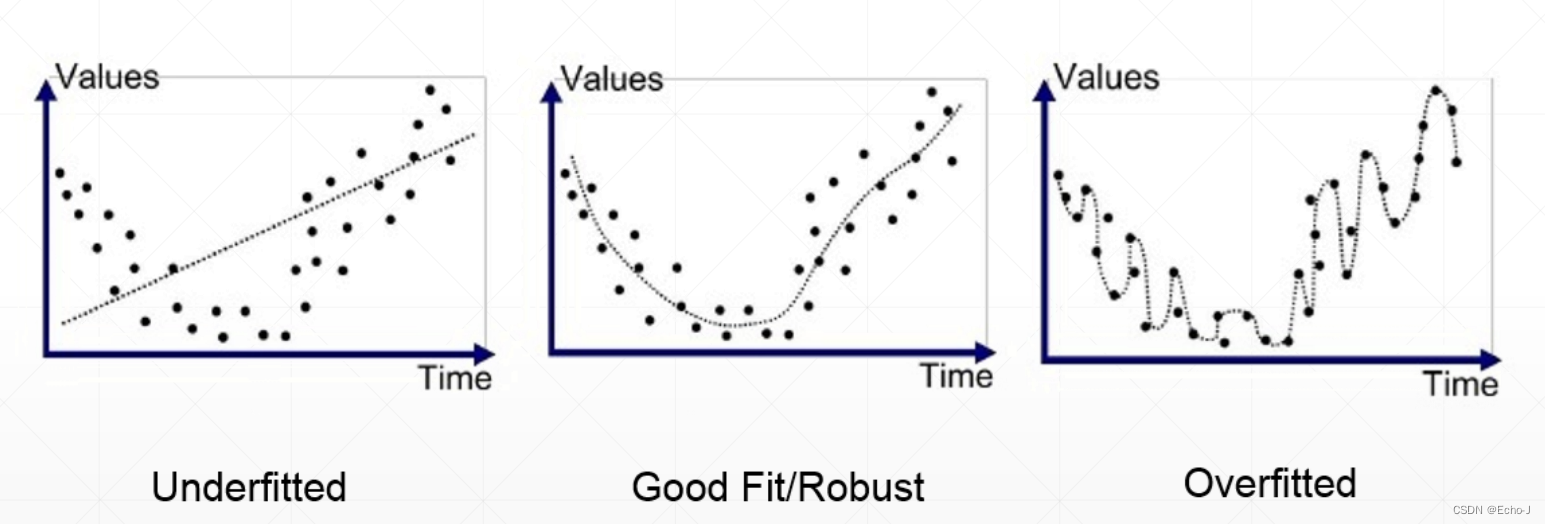
随着项数越来越多,函数的图形就更加复杂,多项式也更加的复杂。

如果利用多项式建造复杂模型,从仅仅一个常数至一个多次方函数,将会发现在线上的点会变得越来越多,这种逐渐接近样本点的过程叫做拟合。
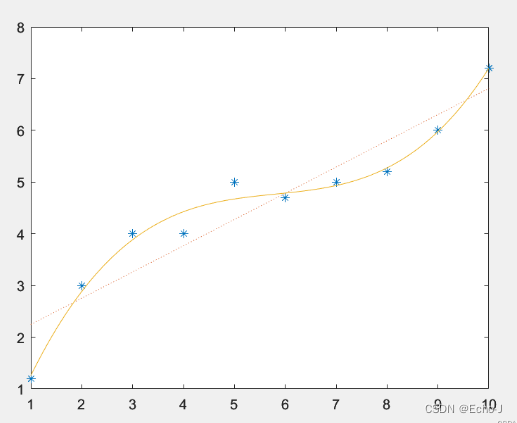
欠拟合
使用的模型复杂度小于真模型的称为欠拟合,表现在数据上的情况就是Accuracy和Loss都不是很好:
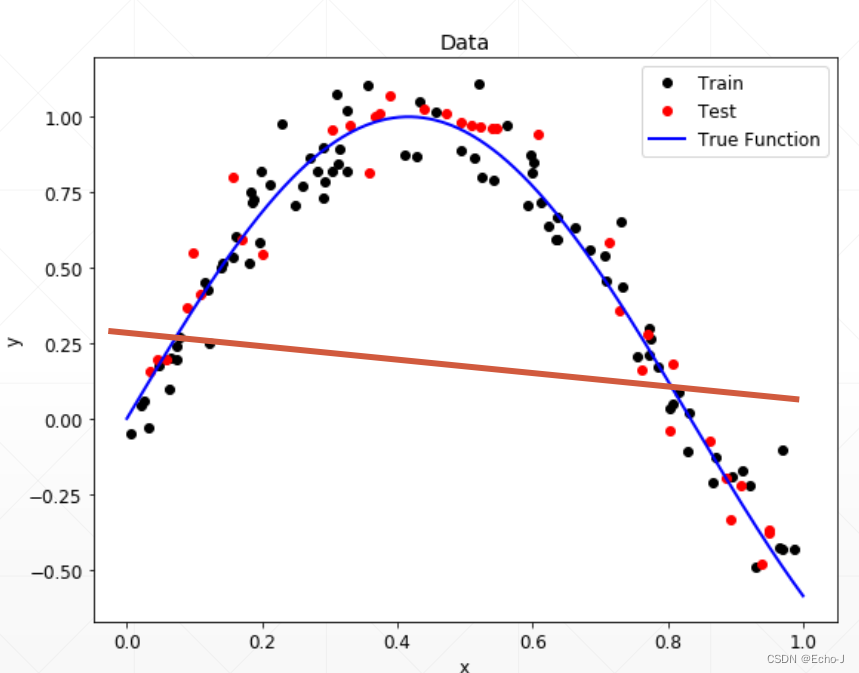
过拟合
使用的模型复杂度大于真模型的称为过拟合,表现在数据上的情况就是训练的Loss和Accuracy都很好,测试上的Accuracy很差:
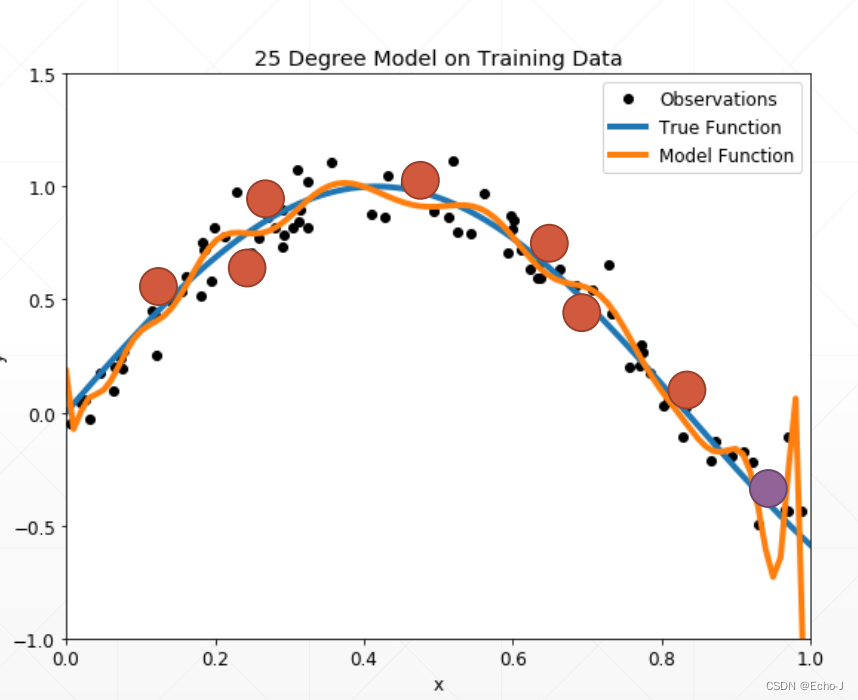
为什么需要测试?
如下图,是Accuracy和Loss随着训练数据的增加出现的现象。在一定数据量的时候,训练结果和测试的结果大致趋势是相同的,但是当数据量增加到一定量的时候,可以明显的看出测试结果出现较大的浮动。这种情况表明了并不是模型训练数据越多,得到的模型就会越好。
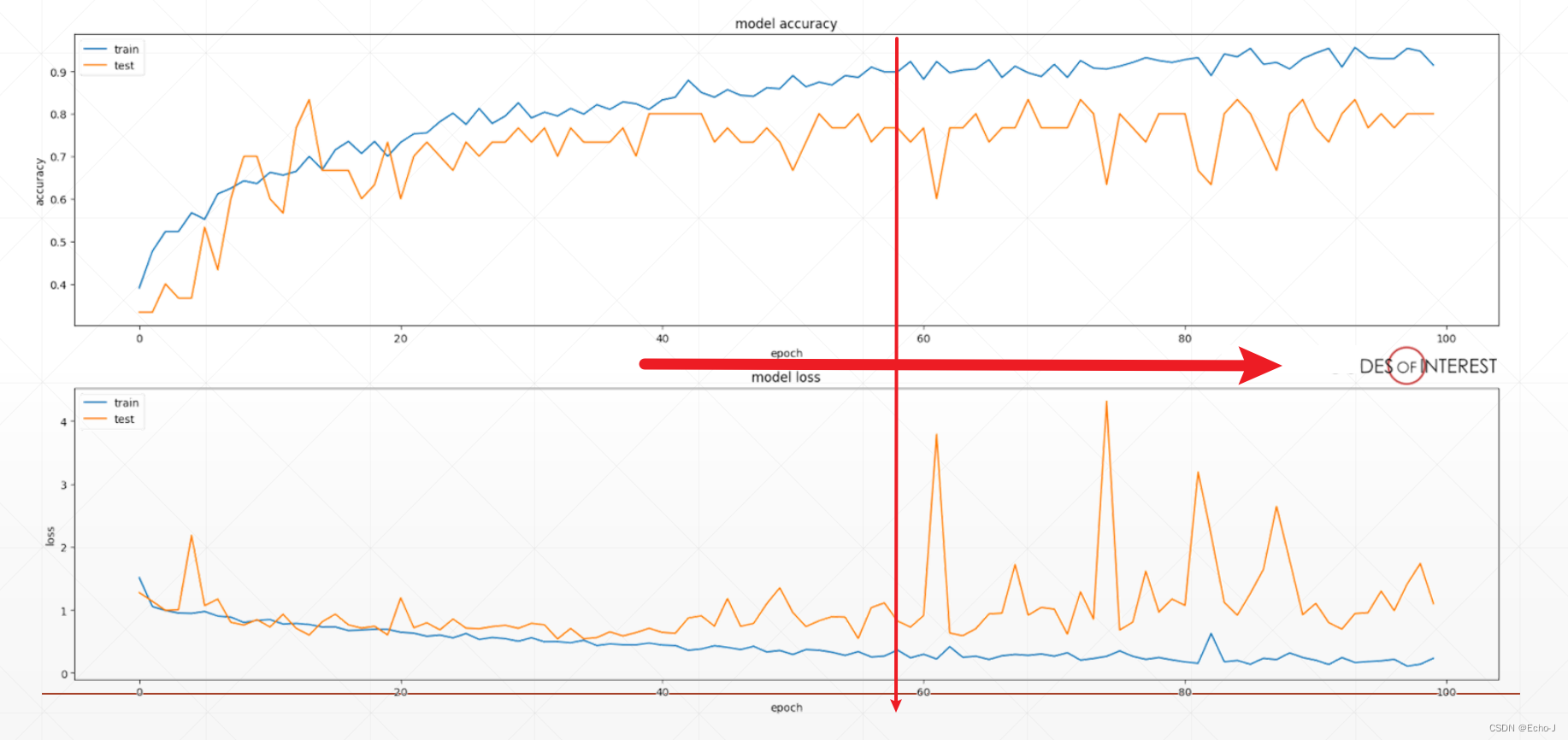
如何才能避免这种情况的发生,找到最好的模型?通过测试,发现结果出现较大偏差时,停止训练,根据以前的训练数据找到一个最好的模型。
应该将测试放在训练的什么位置,即什么时候测试?
1、每次经过几个batch时
2、每次完成一组epoch后
代码演示:
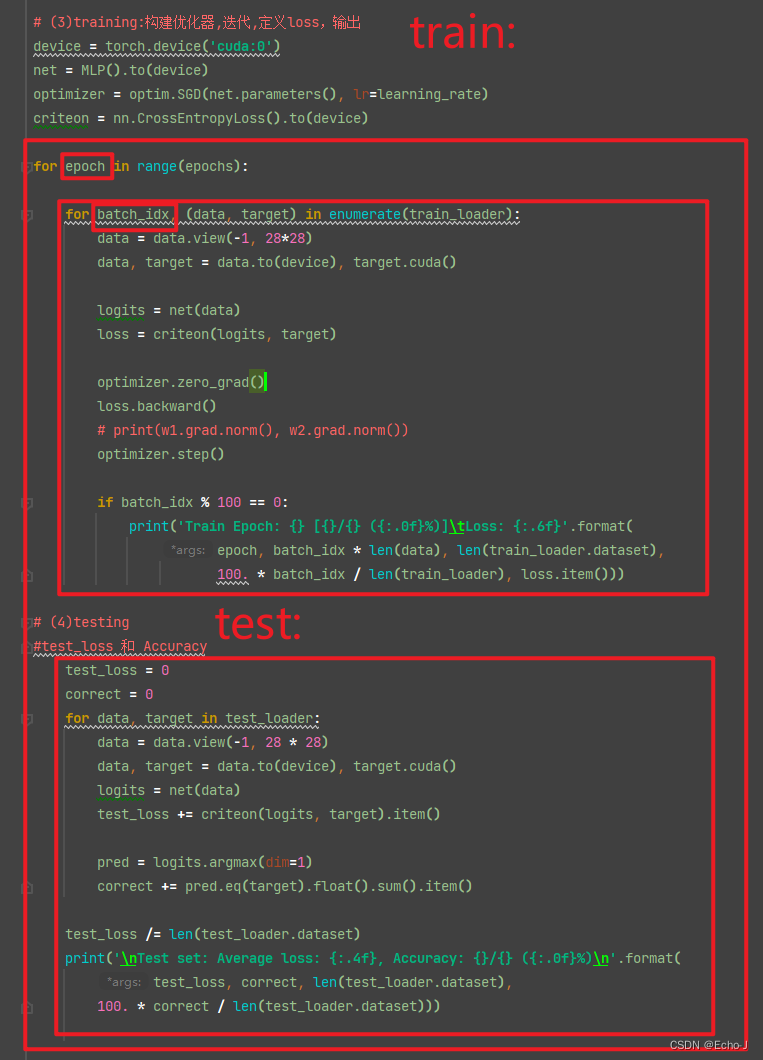
测试puls
一般我们会将数据集人为分成三份,即Train set 、Val set 、 Test set三部分,其中Train set用来训练参数,Val set用来挑选模型,Test set用来做测试。
使用 torch.utils.data.random_split 将训练集划分为 Train set 和 Val set 两部分,代码如下:
#将train数据集进行为train_loader和val_loader(5:1)
print('train:', len(train_db), 'test:', len(test_db))
train_db, val_db = torch.utils.data.random_split(train_db, [50000, 10000])
print('db1:', len(train_db), 'db2:', len(val_db))
train_loader = torch.utils.data.DataLoader(train_db,batch_size=batch_size, shuffle=True)
val_loader = torch.utils.data.DataLoader(val_db,batch_size=batch_size, shuffle=True)