前言的前言 科学!=技术
科学!=技术,非常有同感,接触过很多博士,硕士,博士的科学理论化和想象力更多一些,用于指导技术,而一些硕士和本科的技术的实践性更强一些,用于反向传播科学的参数,从而显现偏差,再来纠偏,这就和业务部门必须指导技术部门一样的道理,业务部门可以想象自己的处理方式,最后技术部门必须落地。我有一个比较映像深刻的地方就是闫令其老师在讲课图形学的时候,底下一个学生问体积着色的问题,一下把老师整蒙了,把底下听课的我也整笑了,就像你再问总统说我家里的拖把如何拖地的问题一样,事实上,这种细节问题显然不是图像学的基础,而是在工业上实际要解决的技术问题。反过来,我们下面也一样,不是要讲完整的解决方案,而是技术细节的处理过程,适合搞工程的人看,产品经理和解决方案工程师不一定适合。
以下是多阵列摄像头的举例

上面是12个摄像头的阵列,需要把画面整合起来,成为一个较大的画面,个数是一个例子,至于我们是3个,还是10个,都只是个数字。以上也不一定是8k处理,理论上我们也可以做到8k以上的处理,渲染。
前言
阵列摄像头涉及多画面的拼接,裁切,变换和纹理拉伸,做多画面高清画面4k,8k处理,涉及到非常多的技术,高分辨率画面非常难处理,不是软件技术做不到,而是硬件上有诸多限制,一是对带宽和显存的要求,cpu上拉到gpu,和gpu下拉到cpu时比较耗费时间,同时功耗上升,对显卡的位宽也有要求,硬件处理在显存和处理之间也不能延时太久,否则这些要求达不到,怎么做到 接到需求时我经常听到上亿像素的拼接要求,同时还有人提过5亿像素的拼接,这个要求很难,主要是来源于设备,设备没有那么大的处理能力,显示能力和编码能力严重不足,对于解码,4k处理多幅画面对现在的硬件是已经可以做到了,但编码能力是不足的,其中涉及到的技术不言而喻是非常严谨的,以游戏来讲,一般做到4k 几十帧渲染是可以的,但是做到8k,那就有要求了,所以游戏显卡两大公司出了两个技术,
1 是老黄英伟达的dlss,NVIDIA发布RTX20系列显卡同步发布的技术,这也是整个图形领域首次将AI和分辨率放大技术相结合,来实现提升渲染性能的目的。40系列显卡把这个技术发挥得游刃有余,注意是图形领域不仅仅是游戏领域。
2 是苏妈amd的fsr技术,都是从低分辨率到高分辨率的衍生技术,非常强悍,尤其是fsr技术值得借鉴,因为她对设备的要求相对而言比英伟达的要求要低。
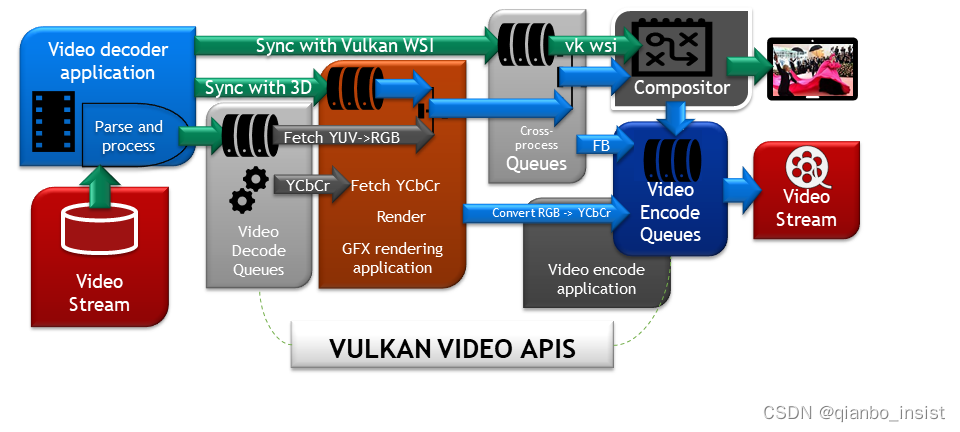
以下是英伟达所用的vulkan video api 架构,我们来分析一下:
This project is a Vulkan Video Sample Application demonstrating an end-to-end, all-Vulkan, processing of h.264/5 compressed video content. The application decodes the h.264/5 compressed content using an HW accelerated decoder, the decoded YCbCr frames are processed with Vulkan Graphics and then presented via the Vulkan WSI.
1 Extracts (DEMUX via FFMPEG) compressed video from .mp4, .mkv .mov and others video containers using h.264 (AVC) or h.265 (HEVC) compression formats.
2 The HW video decoder processes textures to Vulkan Video Images that can be directly sampled from Vulkan Samplers (Textures).
3 Converts the YCbCr (YUV) Images to RGB while sampling the decoded images using the VK_KHR_sampler_ycbcr_conversion
4 Displays the post-processed video frames using Vulkan WSI.
Provides the h.264/5 SPS/PPS video picture parameters inlined with each frame’s parameters. This isn’t compliant with the Vulkan Video Specification. Proper handling of such parameters must be done using an object of type VkVideoSessionParametersKHR.
5 Added support for VkVideoSessionParametersKHR for full compliance with the Vulkan Video Specification.
Use Video display timing synchronization (such as VK_EXT_present_timing) at the WSI side - currently the 6 video is played at the maximum frame rate that the display device can support. The video may be played at a faster rate than it is authored.
Convert the sample’s framework to be compatible with the rest of the nvpro-samples.
到5 和 6 并没有实现。
技术
1 基于cuda,directx12, vulkan ,opengl 处理
directx12 和 vulkan的管线技术涉及底层的理解,是最适合做高清画面4k处理,不过为了兼容和跨平台,暂时先做opengl的处理。总体来说,我们的技术方案:cuda 方式着重于处理算法, dx,vulkan,opengl 的glsl 做后处理和渲染,也可以做一些算法处理,这方面要做一些平衡,具体在于设计。
2 opengl
使用opengl glsl来进行处理,在裁剪和纹理拉伸方面在使用glsl 语言,GPU中直接处理,这样的优点是能够得到脚本处理,glsl脚本放在 得到像素矩阵后直接取出
BO(Buffer Object,缓冲对象)
VBO(Vertex Buffer Object,顶点缓冲对象)
GL_STATIC_DRAW :数据不会或几乎不会改变。
GL_DYNAMIC_DRAW:数据会被改变很多。
GL_STREAM_DRAW :数据每次绘制时都会改变。
其中最重要的技术就是FBO,使用FBO可以将最后的渲染纹理再取出来做其他处理,比如hdr算法,比如dlss 算法,fsr算法,其他超分算法。
什么是FBO
帧缓冲是显卡内存中的一块,保存在该内存区块中的图像数据会实时地在显示器上显示出来,帧缓存中的数据最大最小值会被限定在一个范围内,也就是 [0-255,0-255,0-255],有一个叫 EXT_framebuffer_object 的OpenGL的扩展, 允许我们把一个离屏缓冲区作为我们渲染运算的目标。我们通常把这一技术叫FBO,也就是 Frame Buffer Object的缩写。
3 cuda 处理
OpenGL与CUDA互操作方式总结
这方面国内的硬件确实达不到处理多4k画面的要求,目前只有cuda能做到并发处理,rk 的硬件虽然也好,不过文档缺失,rga硬件处理也是有很多问题,而这一部分,英伟达不但有方案,而且英伟达的研究人员也做了很多很好的尝试,基于他的硬件cuda解码,再使用cuda 处理,再使用cuda 并行编码,在opengl 互操作的过程中可以直接注册opengl的 buffer 资源,而结合opengl的glsl 语言脚本,我们可以把脚本写在外面,做到灵活编译,使用cuda的操作opengl 的方式,
两个api,可以让开发人员操作opengl的纹理,实际上纹理即矩阵,在显存里面的数据如果像内存一样操作就是工程开发人员所要解决的。
cudaGraphicsGLRegisterBuffer();
cudaGraphicsResourceGetMappedPointer();
在OpenGL里面初始化Buffer Object
1 在CUDA中注册OpenGL中的Buffer Object
2 CUDA锁定资源,获取操作资源的指针,在CUDA核函数中进行处理
3 CUDA释放资源,在OpenGL中使用Buffer Object
// 初始化Buffer Object
//vertex array object
glGenVertexArrays(1, &this->VAO);
//Create vertex buffer object
glGenBuffers(2, this->VBO);
//Create Element Buffer Objects
glGenBuffers(1, &this->EBO);//Bind the Vertex Array Object first, then bind and set vertex buffer(s) and attribute pointer(s).
glBindVertexArray(this->VAO);// 绑定VBO后即在CUDA中注册Buffer Object
glBindBuffer(GL_ARRAY_BUFFER, this->VBO[0]);
glBufferData(GL_ARRAY_BUFFER, sizeof(*this->malla)*this->numPoints, this->malla, GL_DYNAMIC_COPY);
cudaGraphicsGLRegisterBuffer(&this->cudaResourceBuf[0], this->VBO[0], cudaGraphicsRegisterFlagsNone);glBindBuffer(GL_ARRAY_BUFFER, this->VBO[1]);
glBufferData(GL_ARRAY_BUFFER, sizeof(*this->malla)*this->numPoints, this->malla, GL_DYNAMIC_COPY);
cudaGraphicsGLRegisterBuffer(&this->cudaResourceBuf[1], this->VBO[1], cudaGraphicsRegisterFlagsNone);// 在CUDA中映射资源,锁定资源
cudaGraphicsMapResources(1, &this->cudaResourceBuf[0], 0);
cudaGraphicsMapResources(1, &this->cudaResourceBuf[1], 0);point *devicePoints1;
point *devicePoints2;
size_t size = sizeof(*this->malla)*this->numPoints;
// 获取操作资源的指针,以便在CUDA核函数中使用
cudaGraphicsResourceGetMappedPointer((void **)&devicePoints1, &size, this->cudaResourceBuf[0]);
cudaGraphicsResourceGetMappedPointer((void **)&devicePoints2, &size, this->cudaResourceBuf[1]);
// execute kernel
dim3 dimGrid(20, 20, 1);
dim3 dimBlock(this->X/dimGrid.x, this->Y/dimGrid.y, 1);
modifyVertices<<<dimGrid, dimBlock>>>(devicePoints1, devicePoints2,this->X, this->Y);
modifyVertices<<<dimGrid, dimBlock>>>(devicePoints2, devicePoints1,this->X, this->Y);// 处理完了即可解除资源锁定,OpenGL可以开始利用处理结果了。
// 注意在CUDA处理过程中,OpenGL如果访问这些锁定的资源会出错。
cudaGraphicsUnmapResources(1, &this->cudaResourceBuf[0], 0);
cudaGraphicsUnmapResources(1, &this->cudaResourceBuf[1], 0);
cpu 和 gpu 通信
cpu和gpu通信是比较慢的事情(相对来说),所以一定要少让gpu 和 cpu 之间产生交互,为什么这么说?我们看大家平常的操作(很可怕):
1 我们要把数据从网络中拉过来,使用cpu,
2 我们从cpu拿到数据后上拉到gpu的decoder,解码
3 解码完毕从gpu下拉到cpu
4 cpu 上拉到gpu 如cuda做算法处理
5 从cuda处理完毕下拉到cpu,从cpu 上传到gpu opengl做渲染和后处理,从framebuffer中下拉图像
6 cpu再做上拉到gpu的encoder 做编码
7 encoder 完毕下拉到cpu
8 cpu使用协议如rtsp 做服务或者推流
看完以上的处理我们迷糊了,这样做显然已经把通信变成了一个来回转轴的场景,我们是否应该这样做
1 我们要把数据从网络中拉过来,使用cpu,
2 我们从cpu拿到数据后上拉到gpu的decoder,解码
3 解码完毕从gpu decoder 直接交给cuda 做算法处理
4 cuda 处理完毕显存数据直接交给opengl渲染和后处理,同时交给encoder做编码
5 编码完毕下拉到cpu
6 cpu使用协议如rtsp 做服务或者推流
确实,如果我们没有工程处理的能力,cpu和gpu之间的通信就成灾难了
多显卡解码和编码
多个4K的解码一定要对cpu和gpu decoder进行测试,一秒钟到底能做多少帧,才能计算出使用多少个显卡,这和功耗也有关系,过多的使用显卡和cpu 在一定的时间内发热到一定的程度时,降频会使画面产生抖动不稳定,这就是为什么设计和代码需要好好推敲和计算。
有多路编解码一定要分布式在多个gpu上,不要一股脑使用单个gpu,性能的问题,单个设备可能解决不了那么大的图像,问题来了,多个解码芯片解完以后,数据在不同显卡的显存里面,如果拿到?
1 使用下载到cpu 内存,再次上载到gpu
2 使用链接设备将gpu链接起来
glsl 语言编辑器
提供编辑器的目的是为了使用脚本提供便利性,如果我们在自己的语言体系里插入lua,插入python,最终还不如直接使用glsl编辑器。
三维处理降维
尝试过在三维里面处理降维,优点又是非常多,我们都知道三维的mipmap技术,实际上在近处和远处无论是directx 和 opengl vulkan都是会去主动匹配需要什么样的显示像素的要求,在正对摄像机的画面中,远就会丢弃一些像素,这就完成了自动降维的过程。我们可以在unity 和 UE中做一些尝试,事实上我们在unity中做了一个插件,拉流rtsp, 使用硬件解码,直接使用opengl nv12 渲染, 可以渲染出28000 长度像素的图片,同时在unity中架设摄像机,取图像再进行编码,分成了3个8k,一个4k,来进行h265编码,这个技术做中间的过程是合适的,不是非常精彩,但是做出来了。
后期有一个三维播放器,就是需要打造自己的引擎来做这个漫游播放。在三维里面把视角处理好,对降维非常有用,毕竟,就算我们能处理这么大的图像,也不一定有这么大的显示器啊。
编码
成为一个大的画面以后,需要编码,那么现在的设备编码技术,作为工程人员不得不用ffmpeg,gstreamer这种厉害的库来做,这两种库我都用过,都很强大,需要我们做很多测试,这两个提供底层API的库确实很好用,这一点中国的sdk 必须好好学习一样国外的这些方式,你跟着他不累,就像看ffmpeg的头文件一样,里面会有详细的指导,还有很好的sample。问题就是ffmpeg不一定能帮你直接处理gpu图像,如果要这么做,需要修改代码,或者有一个方案,直接使用nvidia的encoder sdk。
整体服务架构
1 阵列摄像头硬件
2 拼接工具
3 后台GPU服务
4 其他AI 追踪服务
5 画面漫游多维播放器
功耗
一个最容易被忽略的事实:功耗。例如我们真正使用4k显示器,还是1080P显示器,还是有一个8K显示器,如果一一对应,图像是8K, 显示器是8k,如果我们使用dlss这种技术,会大大的降低功耗。
其他
看完是否觉得要处理的东西有点多,下次再讲,我们先使用三维降维技术解决一些基础问题,处理和显示超长,超大的画面