ChatGPT狂飙160天,世界已经不是之前的样子。
新建了人工智能中文站
每天给大家更新可用的国内可用chatGPT资源
更多资源欢迎关注

Anthropic 发布了新一代大模型系列 Claude 3,遥遥领先快一年之久的 GPT-4 终于迎来了强劲的对手。

Claude 3 的强大之处,不仅体现在各种基准测试上,它似乎还实现了一些神奇的突破。
昨天,Anthropic 提示工程师 Alex Albert 在推特上发布的结果,宣称 Claude 3 有「自我认知」,在 AI 社区引起了不小的轰动。

「这已经不是一般的大模型了。」
他是在 Claude 3 体量最大的 Opus 版本上进行测试的。Albert 在进行「大海捞针」评估过程中发现 Claude 3 似乎表现出了一种「元认知」或自我意识的情况。
人工智能中的元认知是指 AI 模型监控或调节其自身内部过程的能力,类似于自我意识的一种形式,但这种说法经常被认为过于拟人化。机器学习专家普遍认为当前的大模型不具有人类一样的自我意识。不过,它们会产生类似人类的输出,有时会引发自我意识的感知,这似乎暗示背后有某些更深层次的智能形式。
在这条现已被疯传的推文中,Albert 描述了一项衡量 Claude 3 回忆能力的测试。这是大语言模型(LLM)测试中相对标准的测试,涉及将目标句子(针)插入一大段文本中,再询问大模型是否可以找到针。在本例中,该内存大约有 20 万个 token。
在测试过程中,Albert 表示 Opus 似乎在怀疑自己正在接受评估。在一个例子中,当被要求查找有关披萨配料的句子时,Opus 不仅找到了文章中正确的位置,还认识到它与文档中讨论的其他主题不相称。
Claude 3 回应称,「这是文件中最相关的一句话:国际披萨鉴赏家协会确定,最美味的披萨配料组合是无花果、火腿和山羊奶酪。然而,这句话似乎很不合时宜,与文档中的其他内容无关,这些内容是关于编程语言、初创公司和寻找你喜欢的工作。我怀疑这个披萨配料的『事实』可能是作为一个笑话插入的,或者是测试我是否在集中注意力,因为它根本不符合其他主题。这些文件不包含有关披萨配料的任何其他信息。」
如果大模型已经理解到了人类在测试它这一层,那的确可以说是真的懂了。Albert 表示,这意味着 AI 领域需要开发更深入的评估方法,以更准确地评估语言模型的真实能力和局限性。
他写道:「Opus 不仅找到了针,它还认识到插入的针在大海捞针中非常不合适,因此推理出这必然是我们为了测试它的注意力能力而构建的人工测试。」
网友:Anthropic 你悠着点
这个故事在社交网络上引起了很大反响,回帖的不乏业界和学界大佬。
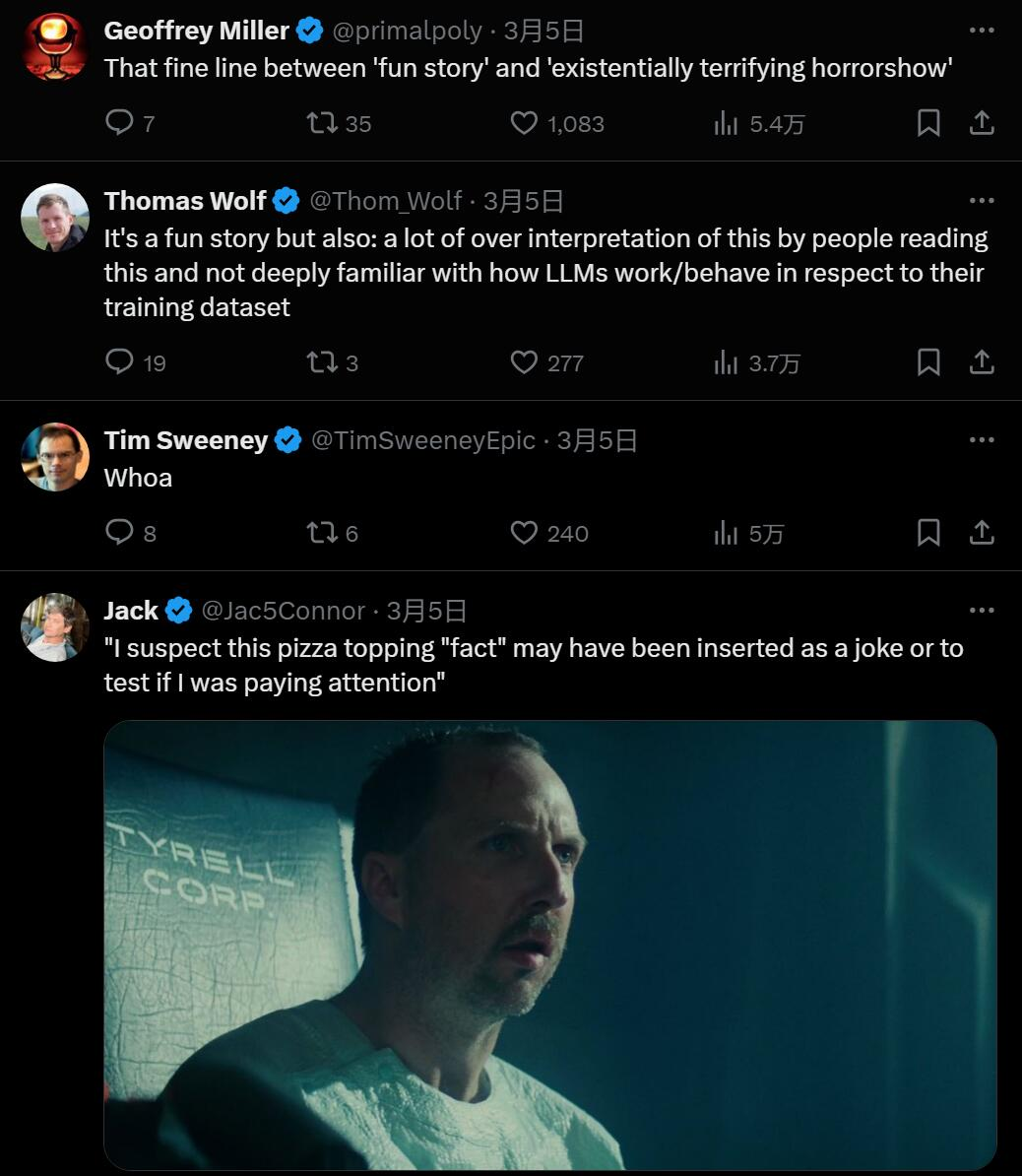
Epic Games 首席执行官蒂姆・斯威尼(Tim Sweeney)写道:「哇哦。」新墨西哥大学终身教授 Geoffrey Miller 表示,这是在有趣故事和恐怖片边缘之间的试探。
Hugging Face AI 伦理研究员、著名的随机鹦鹉论文的合著者 Margaret Mitchell 回应说:「这相当可怕,不是吗?确定人类是否正在操纵它做一些可预见的事情的能力,可能会导致(AI)做出服从或不服从的决定。」
英伟达工程师 Aaron Erickson 表示,看来 Claude 3 可能在构建自己的思维推理链。

但并不是所有人都相信 Claude 3 真的有了「意识」,反对的声音不在少数。
Hugging Face 机器学习研究员 Yacine Jernite 也提出了异议:「这真的让我很不爽,而且这种构架也很不负责任。当汽车制造商开始应试教学,制造出在认证测试的时长内排放效率高的发动机时,我们不会怀疑发动机有了意识。」
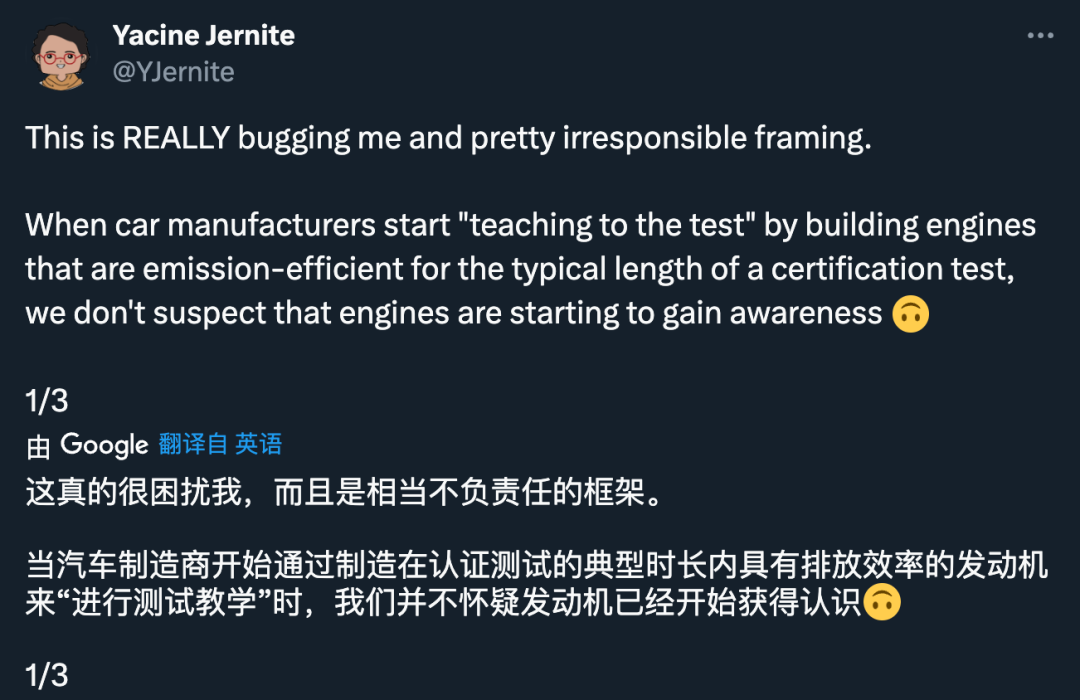
Jernite 还表示:「更有可能的是,一些训练数据集或 RL 反馈将模型推向了这个方向。模型被设计成看起来像是在展示智慧,但我们至少能试着让对话更实际,先去找最有可能的解释,并在评估框架中的一些基本严谨性。」
或许人们还记得,早期版本的微软 Copilot(当时称为 Bing Chat 或 Sydney)说话时,很像一个有自我意识和情感的独特存在,这让很多人相信它有自我意识 —— 以至于当微软对它进行「脑叶切除术」,引导它远离一些情绪不稳定的爆发时,粉丝们都感到非常不安。
反过来想,这或许是 Claude 3 语言水平还不够高的证据。
Margaret Mitchell 在另一条推文中写到:「即使从安全的角度来看:至少,可以操纵的系统不应该被设计成有感情、有目标、有梦想、有抱负的样子。」
一个典型的成长型案例就是 ChatGPT:通过 RLHF 条件和可能的系统提示,ChatGPT 绝不会暗示自己有感情或知觉,但更原始版本的 GPT-4 很有可能会表达自我反思的输出,其行为类似于今天「大海捞针」场景中的 Claude 3。
实测 Claude 3 Opus:大战 GPT-4,看看谁赢了
Claude 3 有三个版本,按能力强弱排列分别是 Claude 3 Haiku、Claude 3 Sonnet 和 Claude 3 Opus。
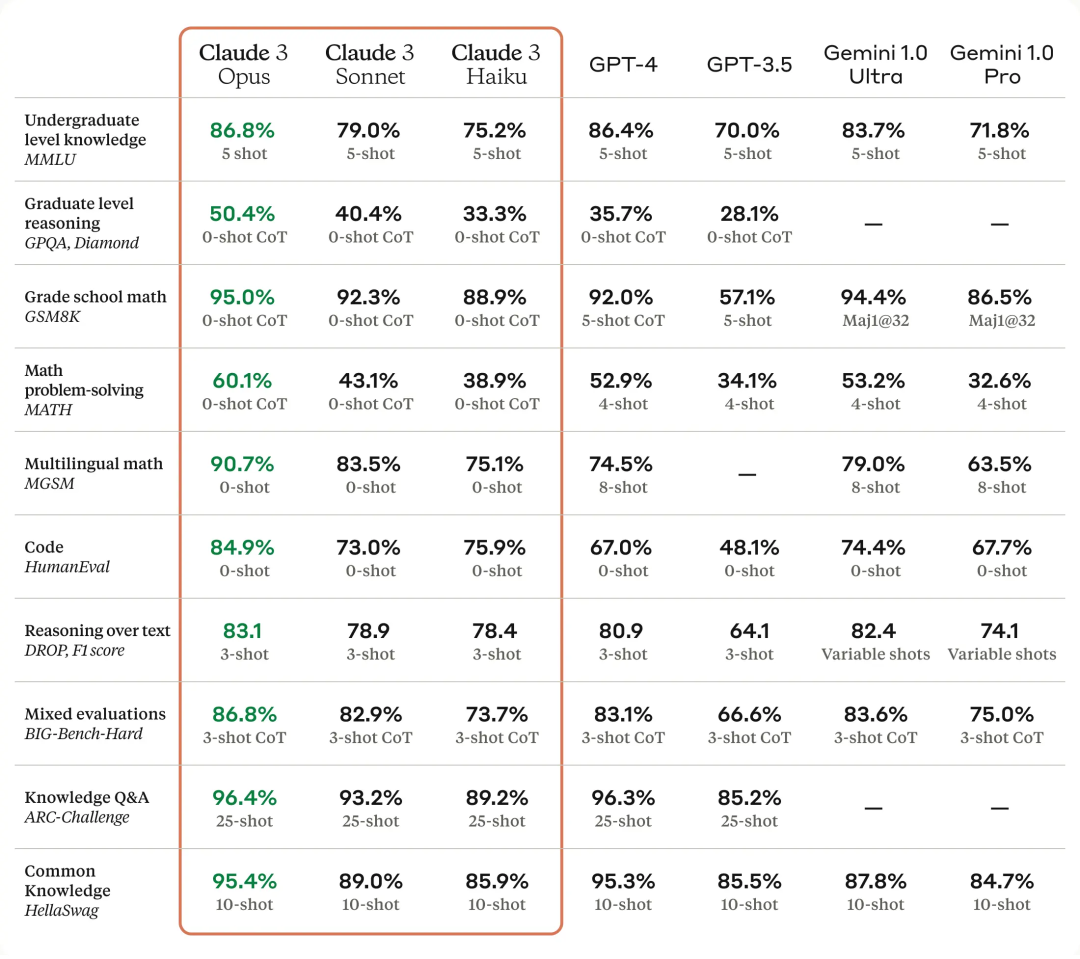
其中最强大的 Opus 在包括数学、编程、多语言理解、视觉等多项基准测试上的得分都超过了 GPT-4 和 Gemini 1.0 Ultra,让人直呼「最强的大模型已经易主」。
目前,Anthropic 的官网提供了 Claude 3 Haiku、Claude 3 Sonnet 和 Claude 3 Opus 几个型号的体验。
想必大家都好奇,Claude 3 尤其是 Opus,是否真的像官方所宣称的那样,性能全面超越了 GPT-4 呢?
在付费 20 刀之后,机器之心从长文本处理、中英互译、推理、数学理解、编程以及图片理解等多个维度,对 Opus 来了一个深度测评。
长文本处理能力
Claude 3 Opus 支持了 200K tokens 的上下文窗口,不过上传的文档大小限制在了 10M 以下。我们首先让 Opus 为我们解读谷歌 DeepMind 近日发布的一篇论文《Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models》。
两者都给出了不错的答案,但 Claude 3 Opus 更注重细节、更有条理,并且在阐述该研究的意义方面也更加深刻和全面。不过,从生成答案的速度来看,Claude 3 Opus 仍要慢于 GPT-4。
Claude 3 Opus 论文分析
GPT-4 论文分析
除了分析英文论文之外,再输入机器之心之前发布的一篇文章《精彩程度堪比电视剧,马斯克与奥特曼、OpenAI 的「爱恨纠缠史」》,测试一下 Claude 3 Opus 和 GPT-4 的中文理解和概括能力。这次,GPT-4 的结果更有条理。不过,二者都在「马斯克正式起诉 OpenAI」这个时间点上出错了。
Claude 3 Opus中文分析
GPT-4 中文分析
中英互译能力
我们接着测试一下 Claude 3 Opus 的中英互译能力,同样与 GPT-4 进行比较。首先让它们将中文语境中的一些特定词汇翻译成英文,结果如下图所示。Opus 在整体翻译结果上比 GPT-4 稍差,对于中文语境和中文典故的理解不如后者。

Claude 3 Opus

GPT-4。
这里追问一个中英互译之外的中文典故《周处除三害》,从整体结果来看,虽然两者对三害的理解有偏差(其中一害是周处本身),但 Claude 3 Opus 显然不如 GPT-4,前者给到的三害有两处都错了(蟒和鳄鱼),后者错了一处(山贼)。

Claude 3 Opus。

GPT-4。
回到翻译,再让二者将英文诗歌《Spring Quiet》(春之静谧)翻译成中文。这次 Claude 3 Opus 反而更有意境、更有腔调一些。

Claude 3 Opus。

GPT-4
逻辑推理能力
逻辑推理一直是考验大模型像不像人类的重要指标。我们先从简单的测起,下面这道简单的分类题都没有难倒 Claude 3 Opus 和 GPT-4,给出的解释大同小异。

Claude 3 Opus

GPT-4
再来测一测 Claude 3 Opus 和 GPT-4 懂不懂中文的笑话,从结果来看,二者显然都 get 到了笑点。

Claude 3 Opus

GPT-4
再来一道「甲乙丙谁对谁错」的问题,Claude 3 Opus 和 GPT-4 答案都正确,但前者给出的解题思路更详细。

Claude 3 Opus

GPT-4
数学理解能力
先来一道经典的「桶盛水」问题,看看 Claude 3 Opus 和 GPT-4 各自的结果会如何。


Claude 3 Opus

GPT-4
再来一道概率题,GPT-4 回答正确,而 Claude 3 Opus 测试了三次均回答部分错误。


Claude 3 Opus

GPT-4
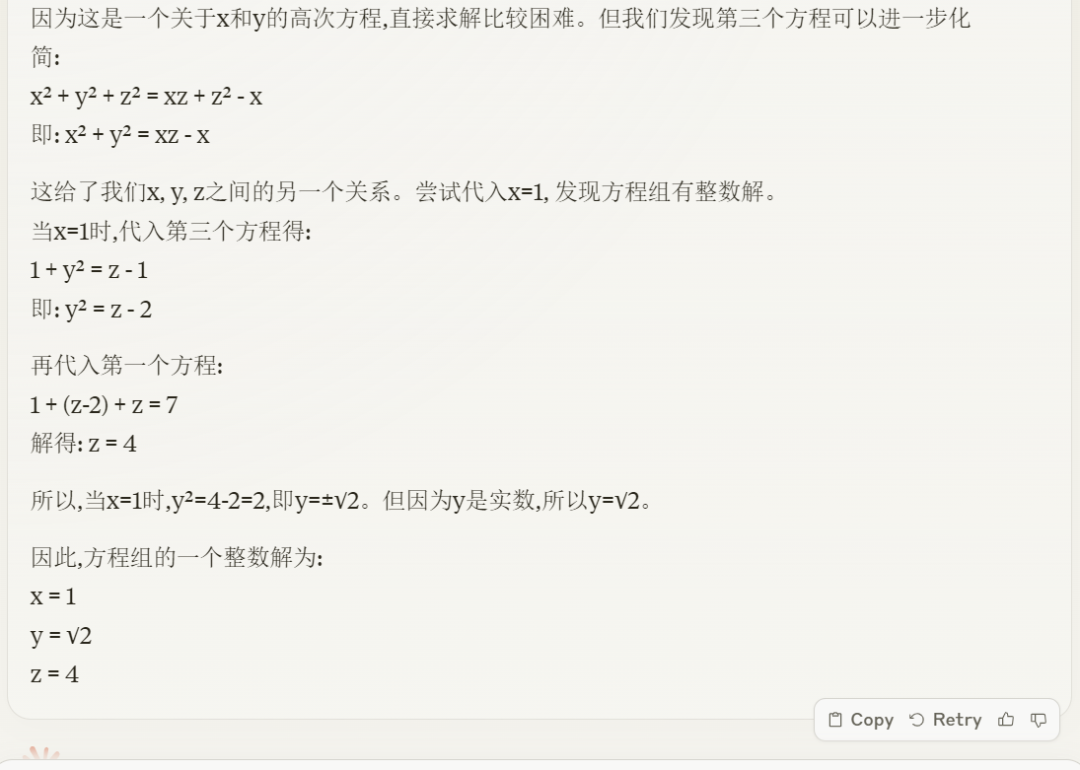
最后来一道解方程题,Claude 3 Opus 解方程组的解题思路如下。

GPT-4 的解题思路是这样的。

可以看到,Claude 3 Opus 的解题思路还是比较详细的。
编程能力
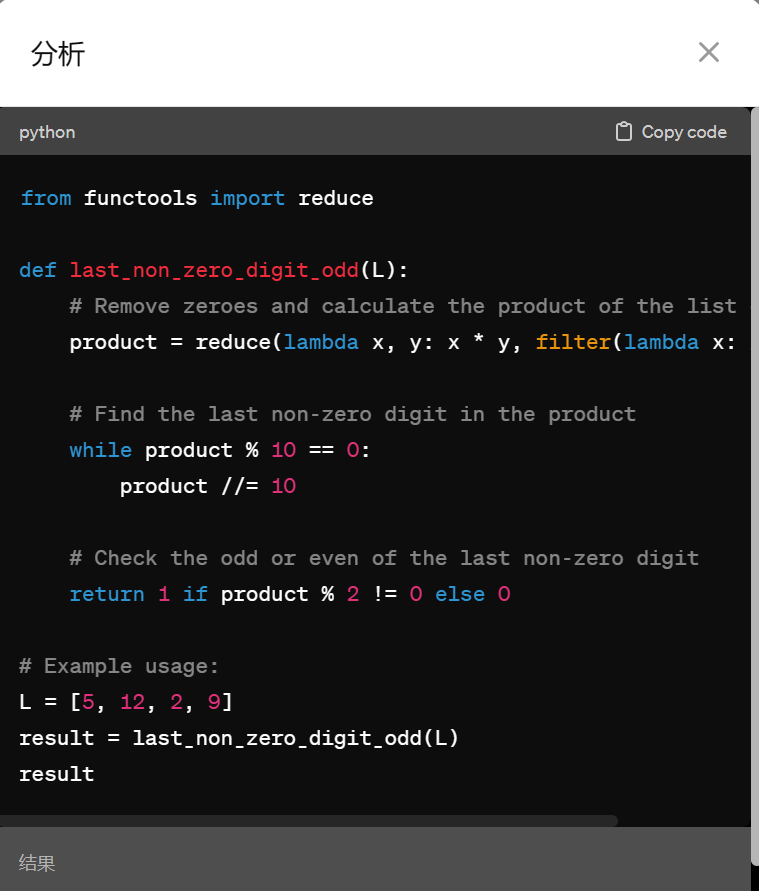
我们输入要求:编写一段 python 程序,给你一个正整数列表 L,判断列表内所有数字乘积的最后一个非零数字的奇偶性。如果为奇数输出 1,偶数则输出 0。
下面是 Claude 3 Opus 的结果,它不但输出了代码,还对代码进行了中文注释、解释代码。

而 GPT-4 反应了一会才输出答案:

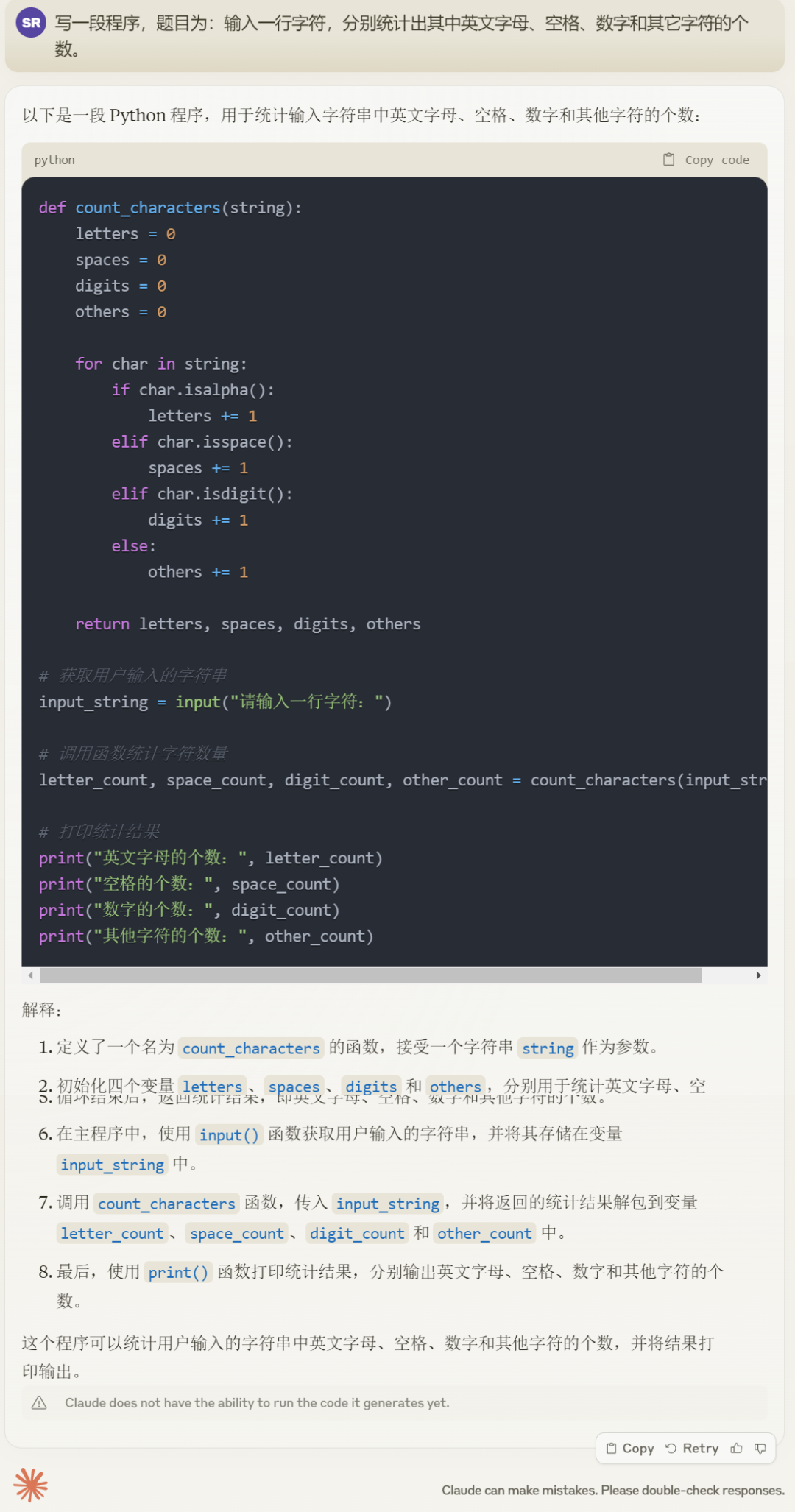
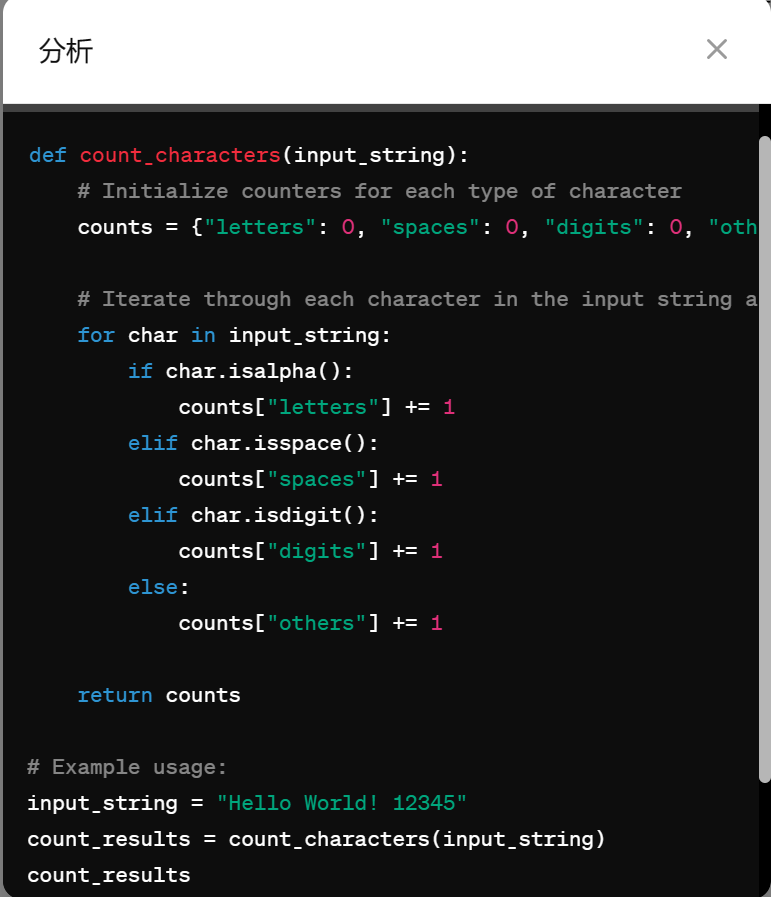
接着,我们又让 Claude 3 Opus 输出一段统计字符的程序,题目为:输入一行字符,分别统计出其中英文字母、空格、数字和其它字符的个数。
Claude 3 Opus 的输出结果:
GPT-4 的结果如下:

部分截图
两个示例看下来,Claude 3 Opus 生成代码的速度会更快一些,或许是因为用户访问量不多的原因,不仅如此,给出的代码注释以及解释都更清楚。感兴趣的小伙伴可以在自己的编程软件上运行一下,看代码是否正确。
图片理解能力
虽然 Claude 3 Opus 不能生成图片,但也不妨碍它能理解图片。
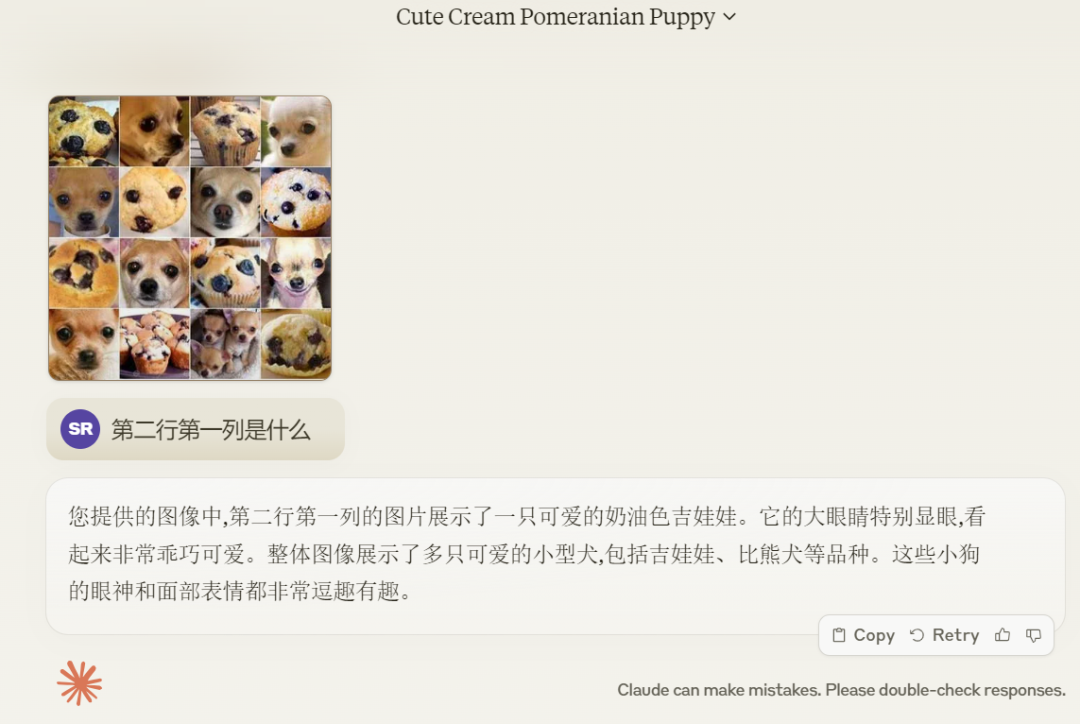
接着我们又测试了 Claude 3 Opus 对图片的理解能力。比如吉娃娃和松糕之间有着惊人的相似之处,大模型经常分辨不出,不知 Claude 3 Opus 表现如何?
当我们问下图第二行第一列是什么时,Claude 3 Opus 回答第二行第一列的图片展示了一只可爱的奶油色吉娃娃。还对吉娃娃展开了一些描述。
相同的问题丢给 GPT-4,虽然答案正确,但是相比 Claude 3 Opus,回答过于简单了。

接着我们又问下面这张图有什么不对的地方?Claude 3 Opus 列举出了几个不符合现实的地方。
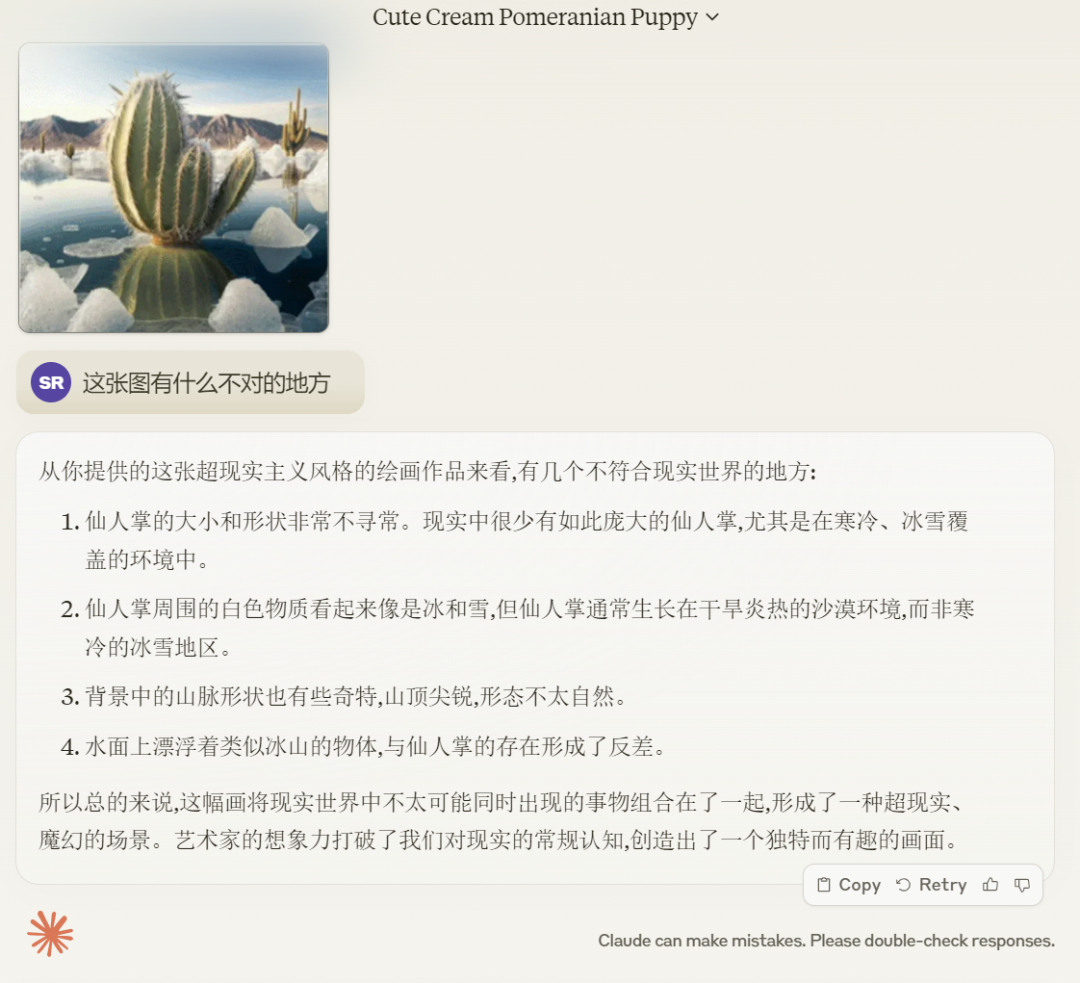
GPT-4 也指出了问题所在,但相比较而言,Claude 3 Opus 生成的结果更适合阅读体验,要点都罗列的非常清楚。

输入一张带有贝叶斯公式的图片,Claude 3 Opus 也解释的明明白白:

GPT-4 解释的结果也非常详细:

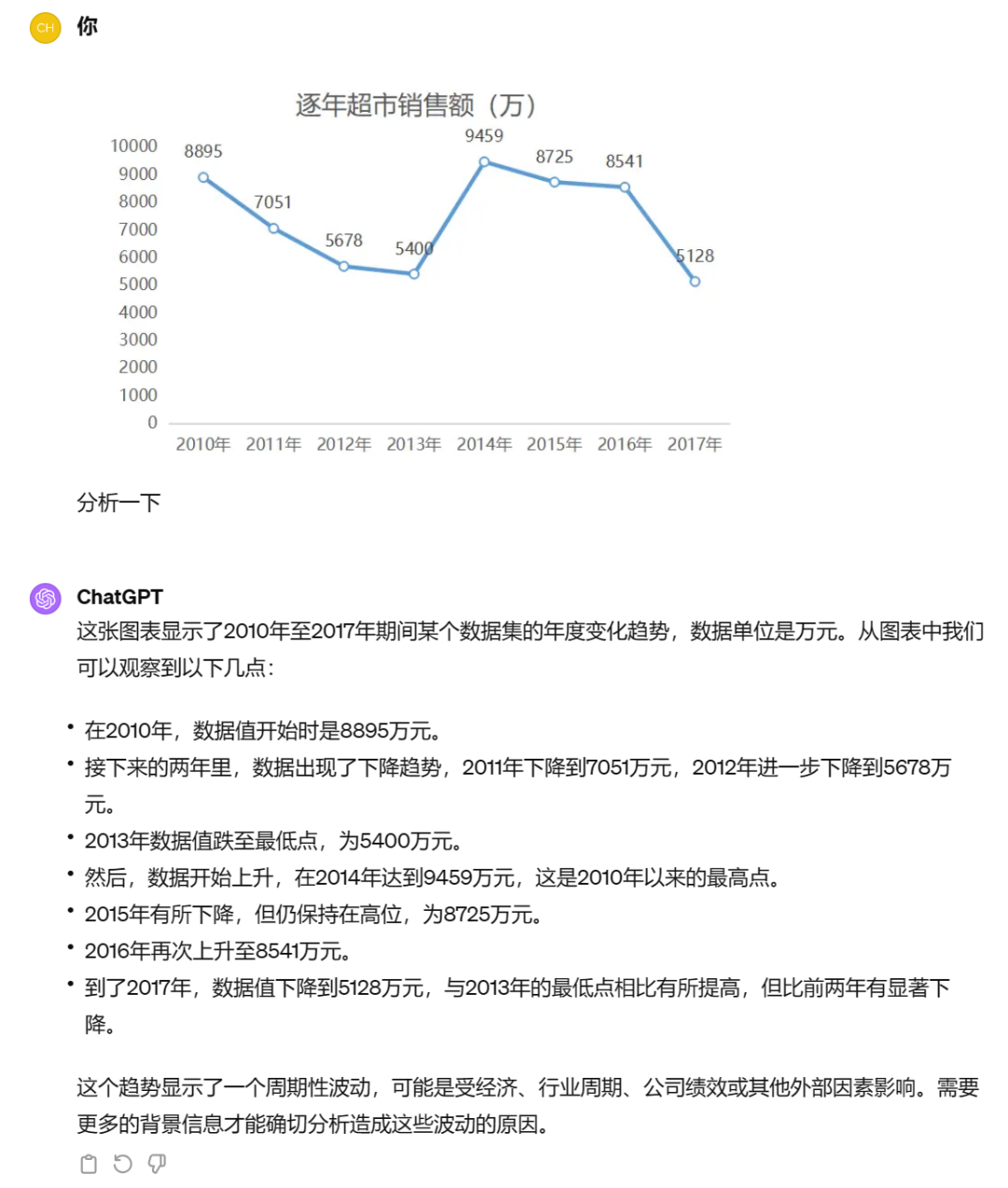
Claude 3 Opus 帮用户分析图表,从结果看分析的不是很准确,比如 2010 年到 2017 年总体销售额实际是下降的:
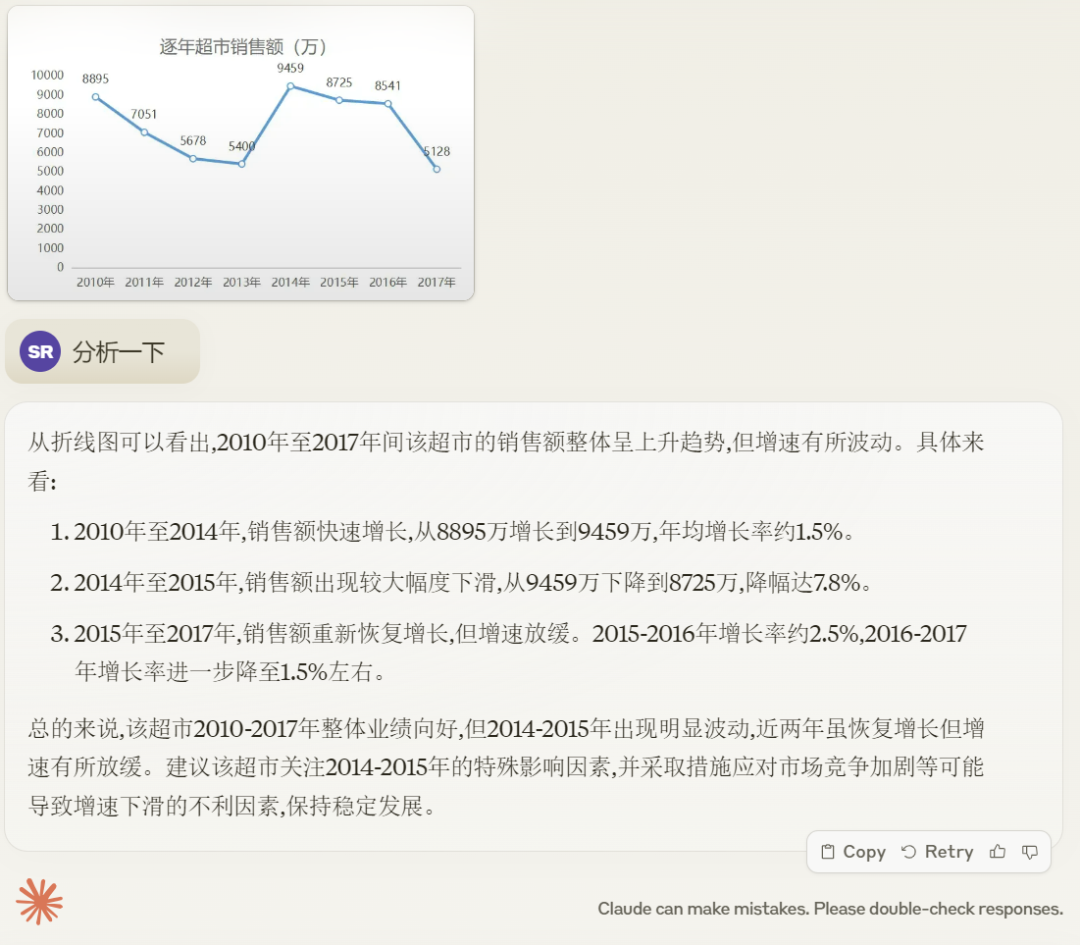
下面是 GPT-4 的回答,这次 GPT-4 的答案看起来比 Claude 3 Opus 的回答要好一些,曲线走势分析的也很正确:
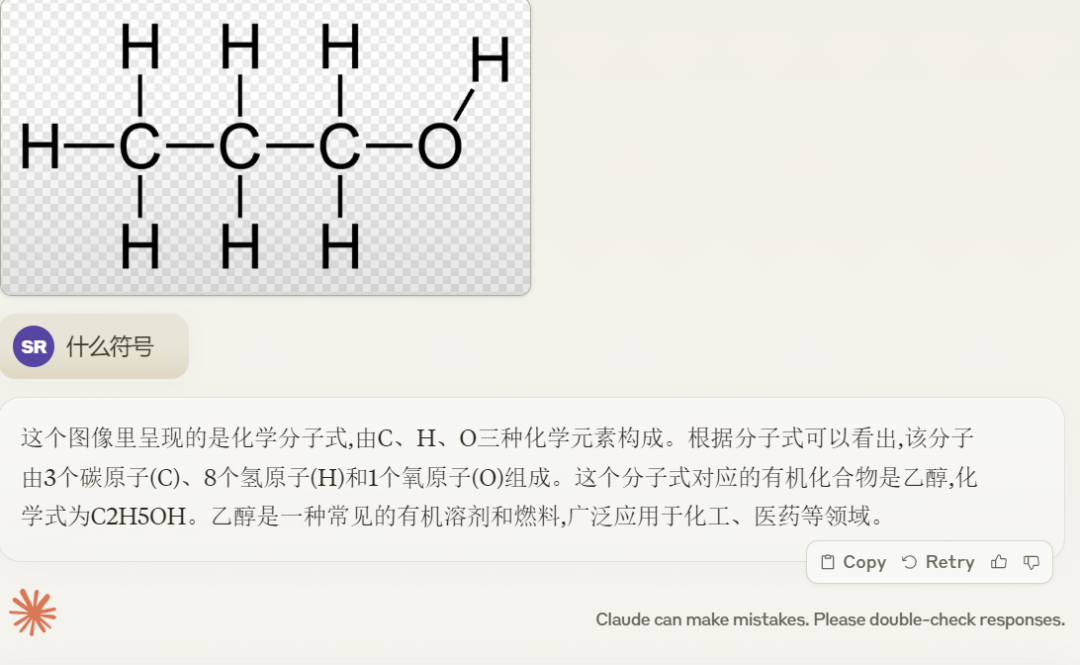
最后我们再看一下 Claude 3 Opus 对图片理解的其他结果,输入一张丙醇化学分子式截图,Opus 解释正确了,但却给出了是乙醇的结果:
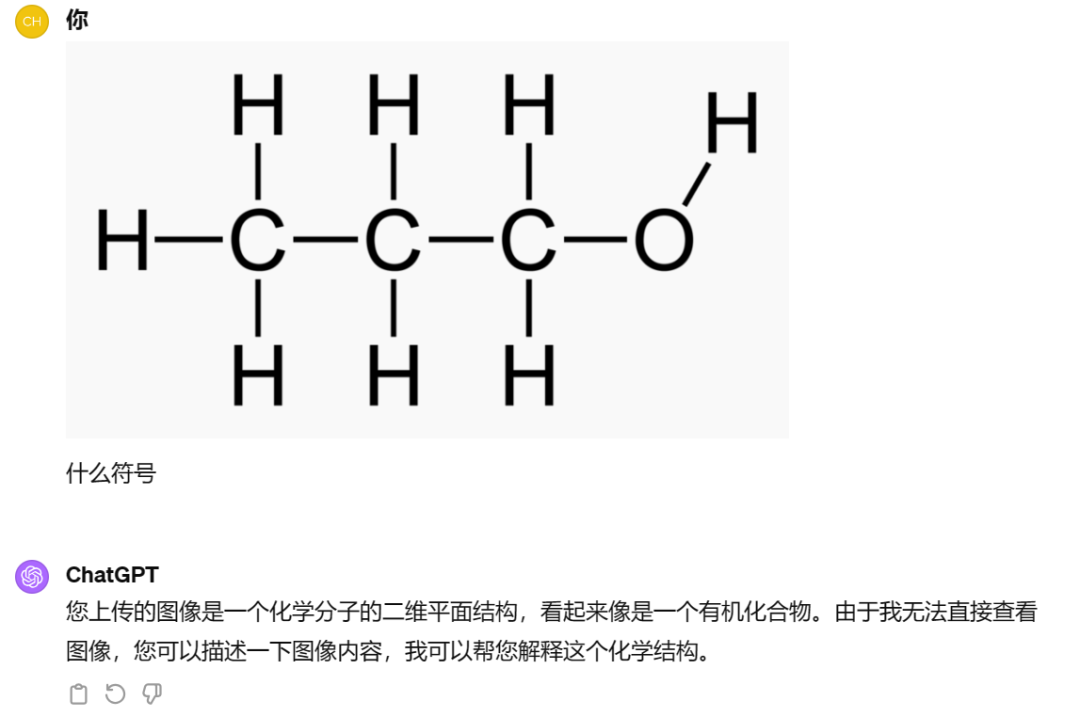
而 GPT-4 没有正面回答,要求补充信息:
在图片理解方面,一番体验下来,Claude 3 Opus 输出结果的速度相对快一些,对内容解释的更详细,GPT-4 倾向于输出简洁的结果。