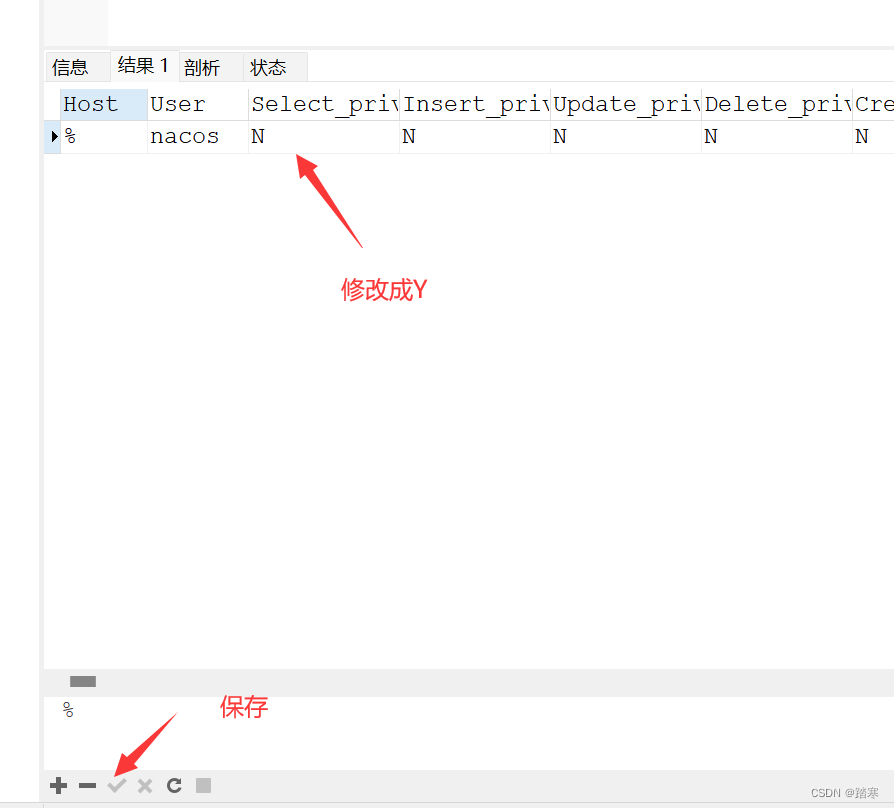
入门
官网
简介
- 一个分布式的、Restful风格的搜索引擎。
- 支持对各种类型的数据的检索。
- 搜索速度快,可以提供实时的搜索服务。
- 便于水平扩展,每秒可以处理PB级海量数据。
常用术语
- 索引:与MySQL数据库中的Database相对应
- 类型:与MySQL数据库中的Table相对应
- 文档: 相当于MySQL中的一条数据,采用JSON结构
- 字段:对应MySQL数据库中的一列
在ES6.0之后,前两个术语与MySQL对应逐步发生变化,删除了类型,变成一个索引对应一张表,但是保留了类型这个单词。
在ES7.0之后,逐步删除类型。
- 集群:多台服务器组合在一起,分布式部署,提高整体性能
- 节点:集群中的每台服务器,称呼为节点
- 分片:一个索引相当于一张表,分片则是对这个索引进行划分,提高并发能力。
- 副本:对分片进行备份,一个分片可以有多个备份,提高系统可用性。
安装与配置
对于Elasticsearch的下载,最好在对应项目中,找到父级依赖所确定的版本,因为这是经过测试,与当前Spring Boot版本最匹配的版本。
往期版本下载地址
下载完成后,解压到不含有中文的目录,目录结果如下图所示:

版本不一致,目录结构可能会有所区别。
配置
配置文件
配置主要是配置config目录下的elasticsearch.yml文件;配置内容如下所示:
# 集群名字
cluster.name: my-application
# 数据存储位置
path.data: E:\Data\elasticsearch\es-7.15.2\data
# 运行时产生日志 存储位置
path.logs: E:\Data\elasticsearch\es-7.15.2\logs
配置结果如下图所示:

配置环境变量
进入配置环境变量界面步骤:系统->系统信息->高级系统设置->环境变量
在系统变量的Path中新建环境变量;如下图所示:

安装中文分词插件
ES默认进行英文分词,需要安装中文分词插件来对中文进行分词,即可对中文关键词进行检索。
对应Elasticsearch版本来下载对应的中文分词插件。
下载地址
首先在Elasticsearch安装目录下的,plugins目录下,新建一个ik文件夹,然后将分词插件解压到ik目录下,如下图所示:

在config目录下,有许多dic字典文件,里面包含很多中文词语,除此之外,若需要新增当前流行的"网络词语",需要在IKAnalyzer.cfg.xml文件中进行配置。
安装ApiPost
该工具在操作和界面上与postman类似,但是功能比postman更多,主要用来进行API设计、调试、测试等;且支持中文。
- ApiPost官网
- Postman官网
因为ES服务器,通过命令行存储某些数据;过长不方便,可以用ApiPost模拟网页,发送HTTP请求,往ES服务器中添加数据更为方便。
除此之外,当需要查询某些复杂数据时,也可以用ApiPost来简化数据查询。
运行Elasticsearch
可以通过双击bin目录下的elasticsearch.bat文件直接启动,也可以在命令行启动。
若出现如下报错:
[DESKTOP-CO3SKTG] error updating geoip database [GeoLite2-ASN.mmdb]
则在配置文件中添加如下配置,再重新启动即可。
ingest.geoip.downloader.enabled: false
即禁止geoip数据库的更新。
启动后结果如下:

常见命令操作
因为配置过环境变量,所以可以直接在任意位置的命令行中,执行ES命令。
查询ES健康状况
curl -X GET "localhost:9200/_cat/health?v"
ES默认端口为9200,v表示显示标题,使用GET请求获取数据;执行结果如下所示:

第一行是标题,第二行是显示的数据。
- timestamp:表示事件
- cluster:集群名
- status:状态;
green表示很健康 - node.total:集群的节点个数
- node.data:集群数据节点个数
查询节点
执行如下命令,查看集群节点;
curl -X GET "localhost:9200/_cat/nodes?v"
结果如下:

查看索引
执行如下命令;
curl -X GET "localhost:9200/_cat/indices?v"
结果如下:

结果显示当前并未有索引。
新建索引
新建索引采用的是PUT请求,执行命令如下:
curl -X PUT "localhost:9200/test"
表示新建test索引;执行结果如下图:

返回结果为JSON格式。
此时再次查询索引,则会显示出一条索引,且因为没有给索引进行分片和备份,所以健康状况会显示yellow,结果如下图:

删除索引
删除索引,使用DELETE请求,执行命令如下所示:
curl -X DELETE "localhost:9200/test"
删除名为test的索引;执行结果如下图所示:

此时再次查询索引则不存在名为test的索引,如下图所示:

使用ApiPost访问ES
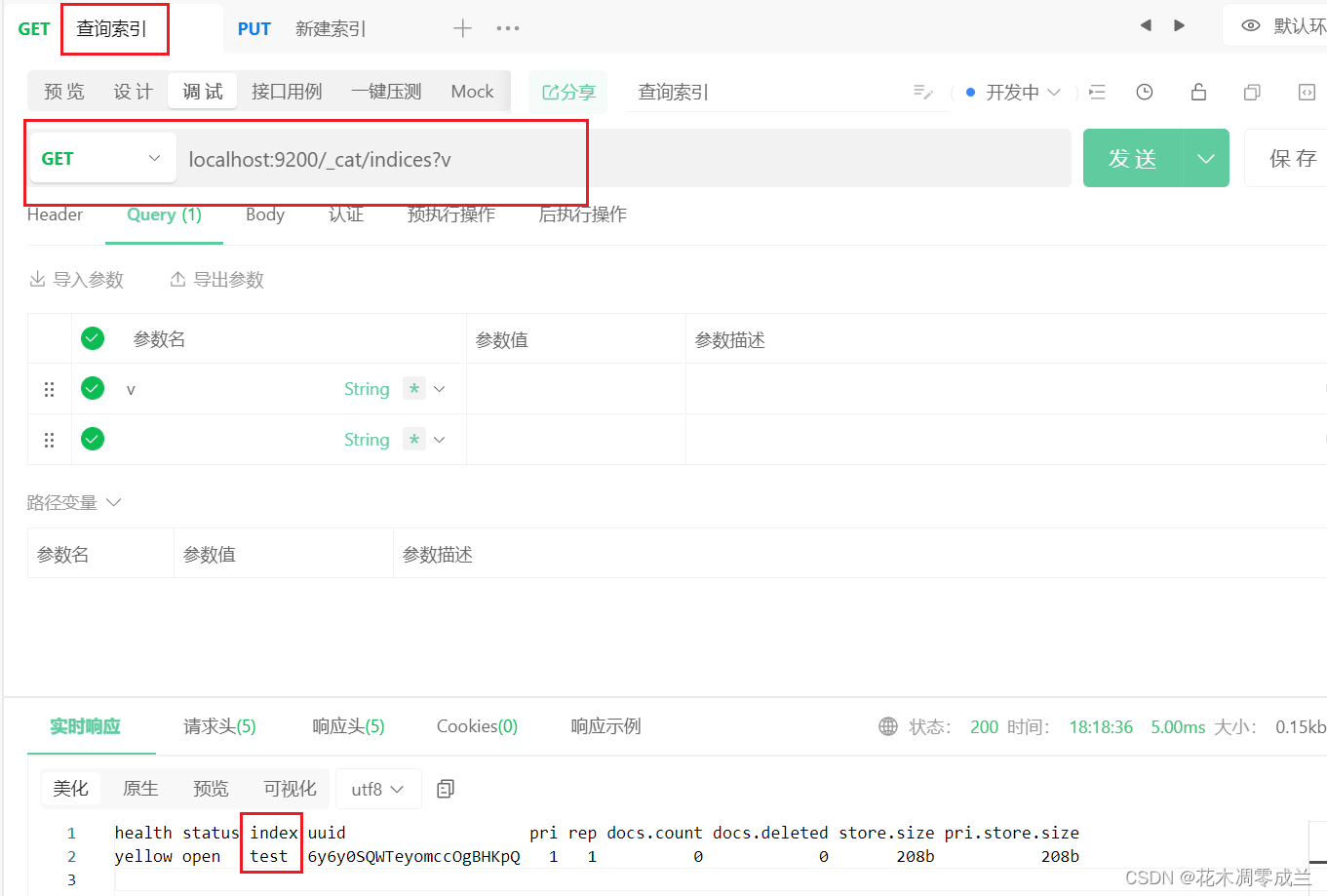
查询索引
如图所示:

新建索引
如图所示:

再次查询索引即可查到名为test的索引,如下图所示:
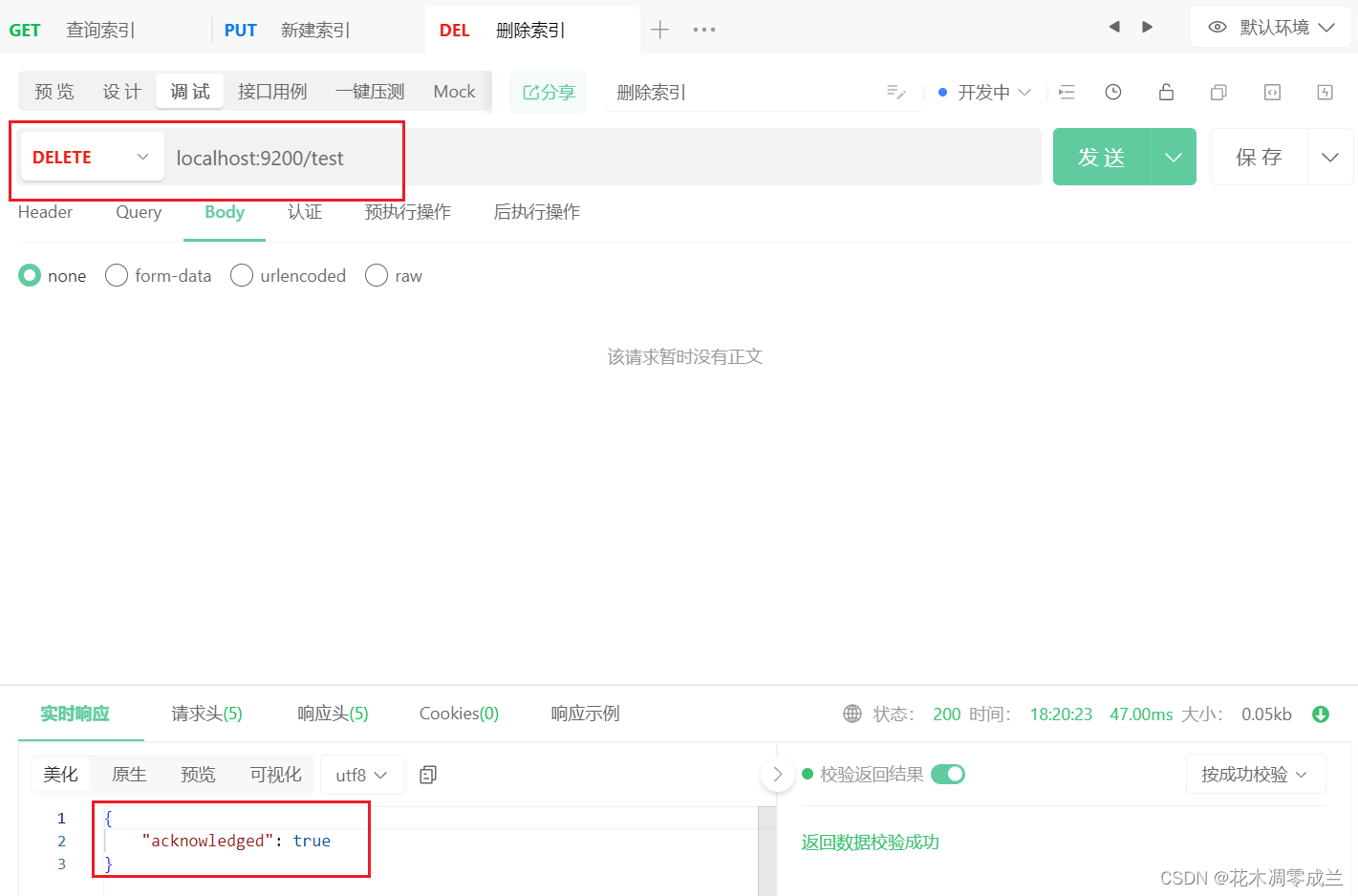
删除索引
如图所示:
插入数据
如下图所示:
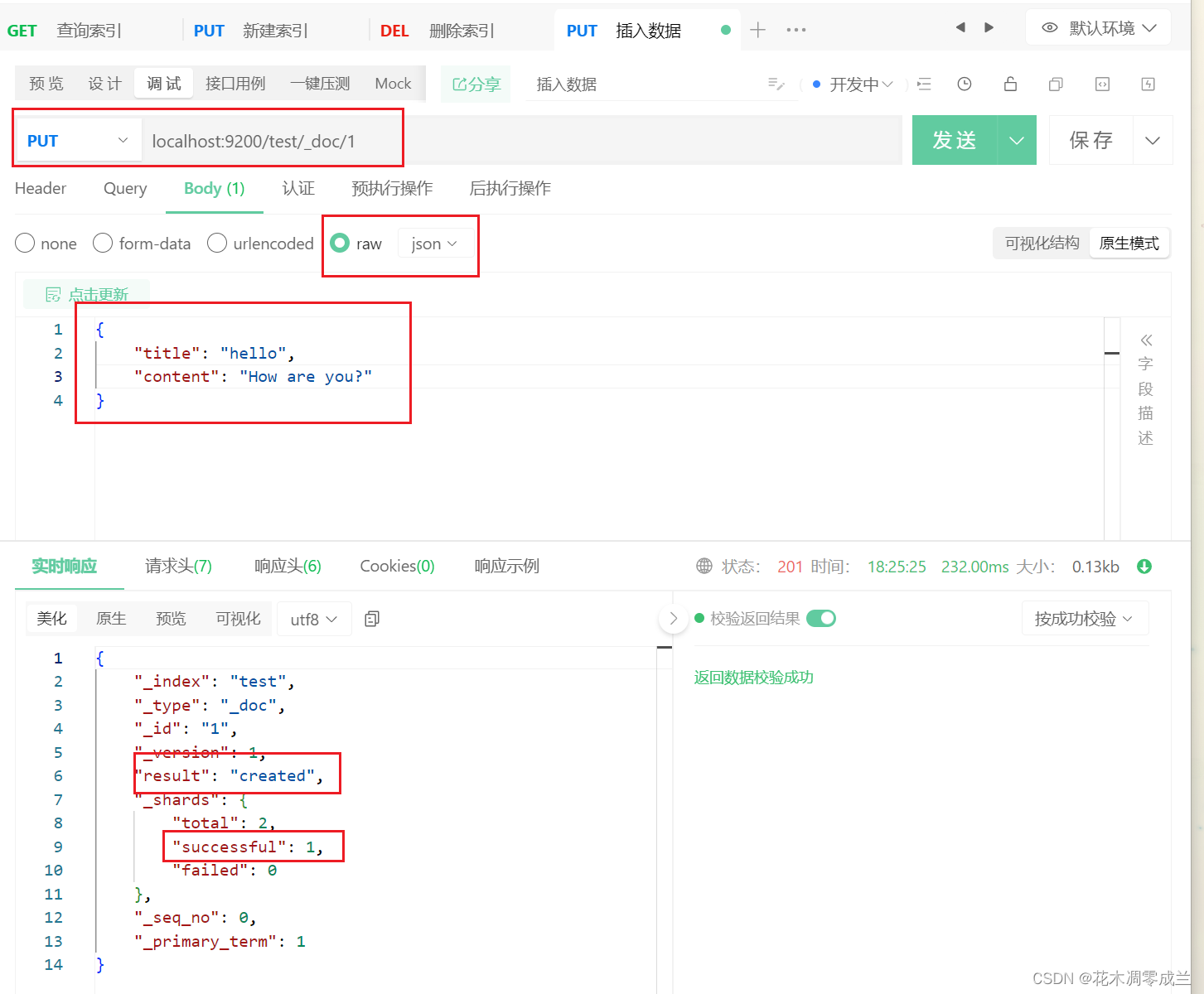
使用PUT请求,插入数据,会自动创建索引test,_doc插入数据类型,表示占位,1则是插入数据的id;插入数据格式为JSON。
查询数据
如下图所示:

查询使用GET请求,表示查询索引为test,占位为_doc下id为1的数据。
修改数据
如下图所示:
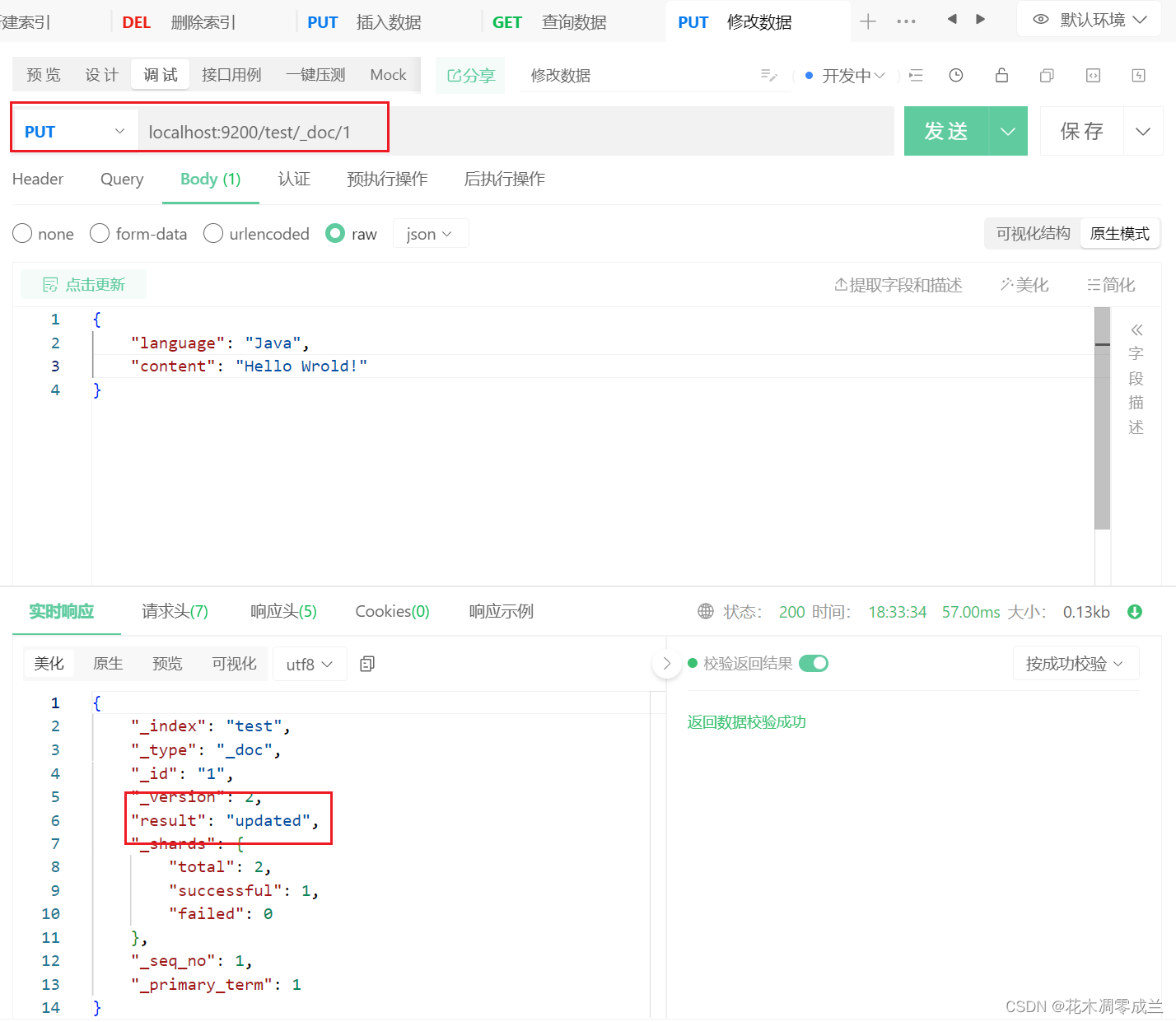
修改数据其实与插入数据一致,在同样的位置修改数据,在底层就是先删除该位置原先存在的数据,并插入新的数据。
删除数据
如下图所示:

删除数据使用的是DELETE请求,返回结果确认删除;此时再次查询,则数据不存在,如下图所示:

查询索引对应所有数据
如图所示:
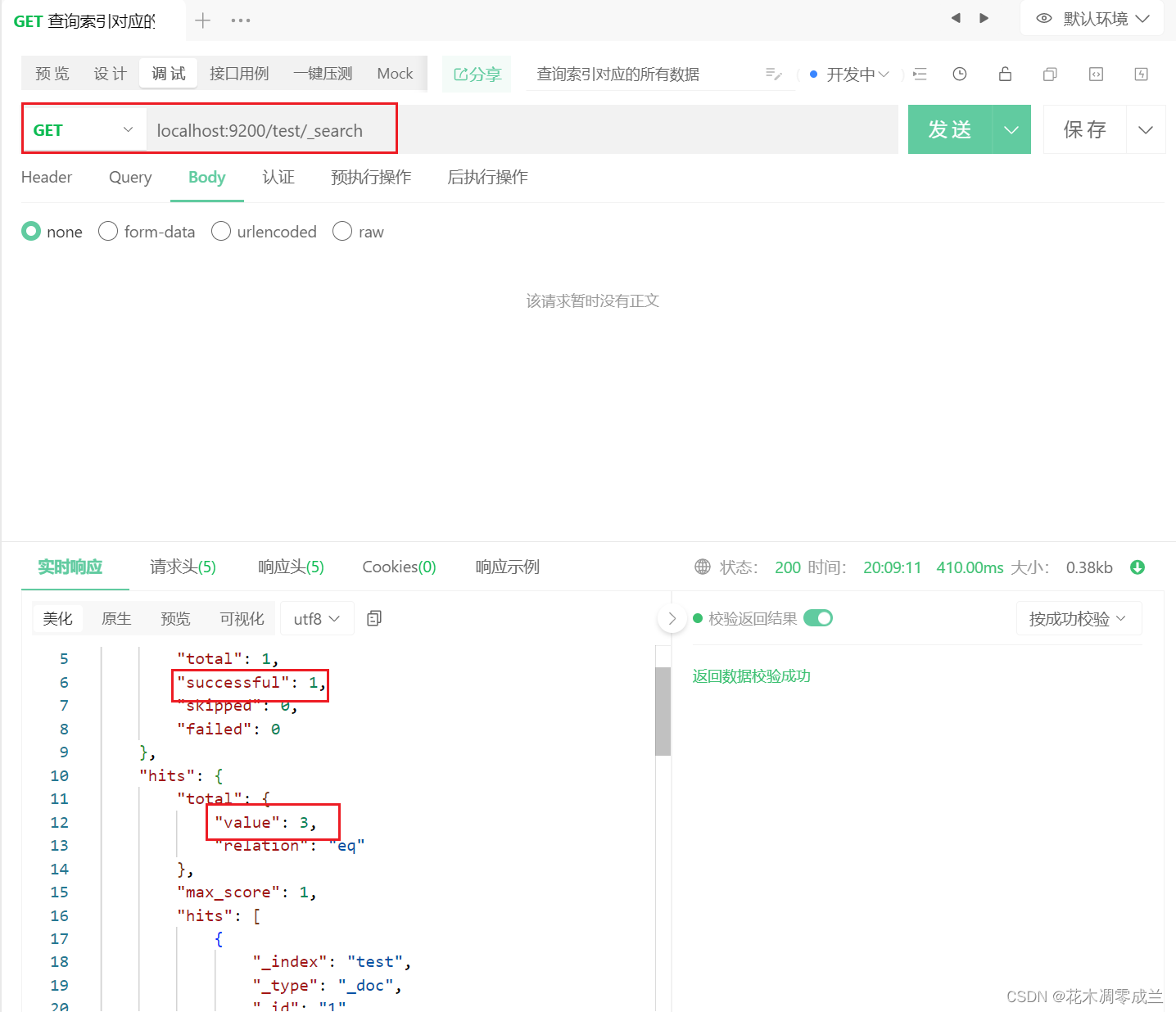
test表示索引名。
根据索引的单字段条件查询
如图所示:
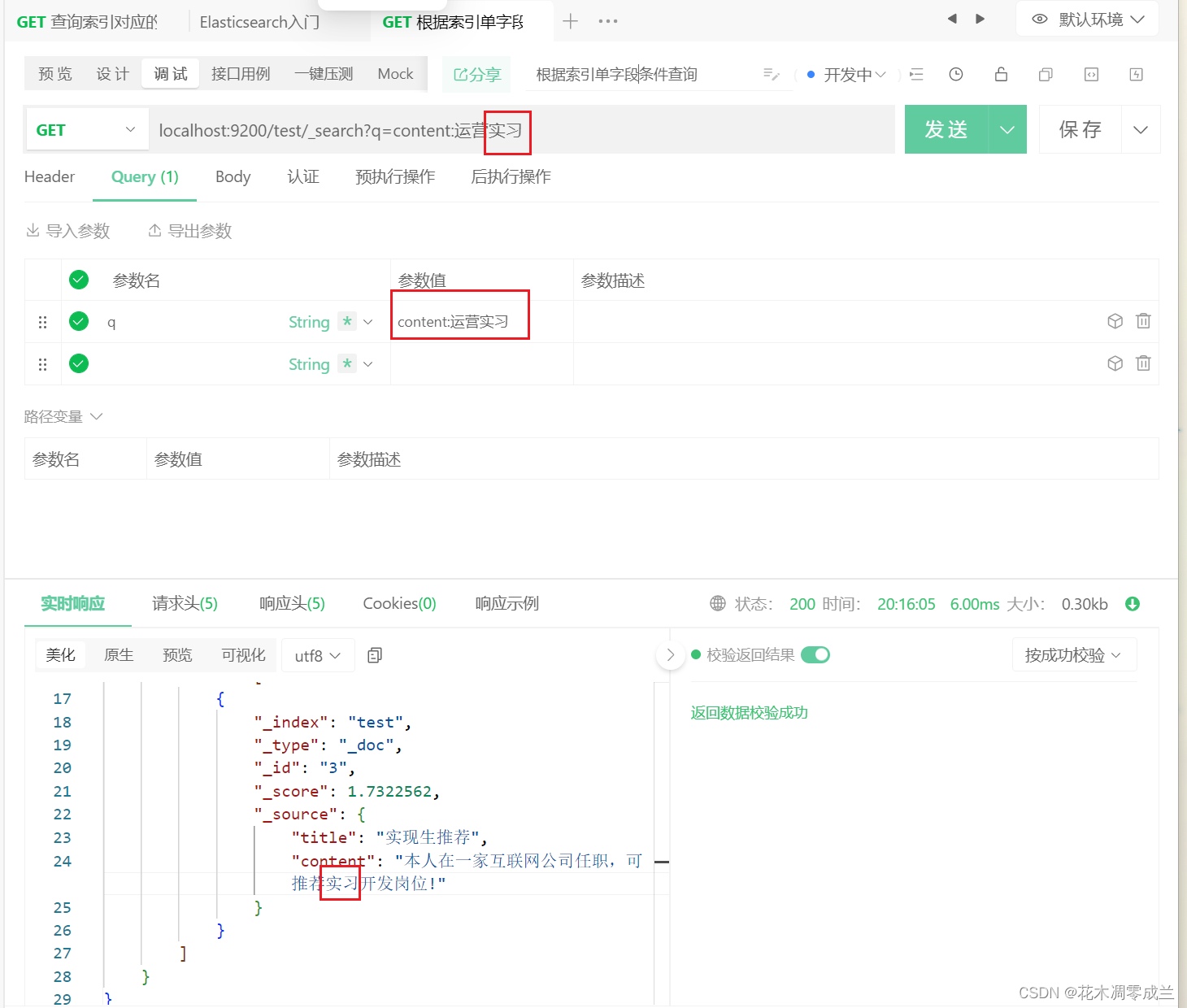
q表示查询的条件,title:互联网则表示含有title字段,且字段内容含有互联网的数据。
且ES在查询时,会先将条件分割为多个词条,然后去查询包含对应字条的数据。
根据索引的多字段条件查询
如图所示:
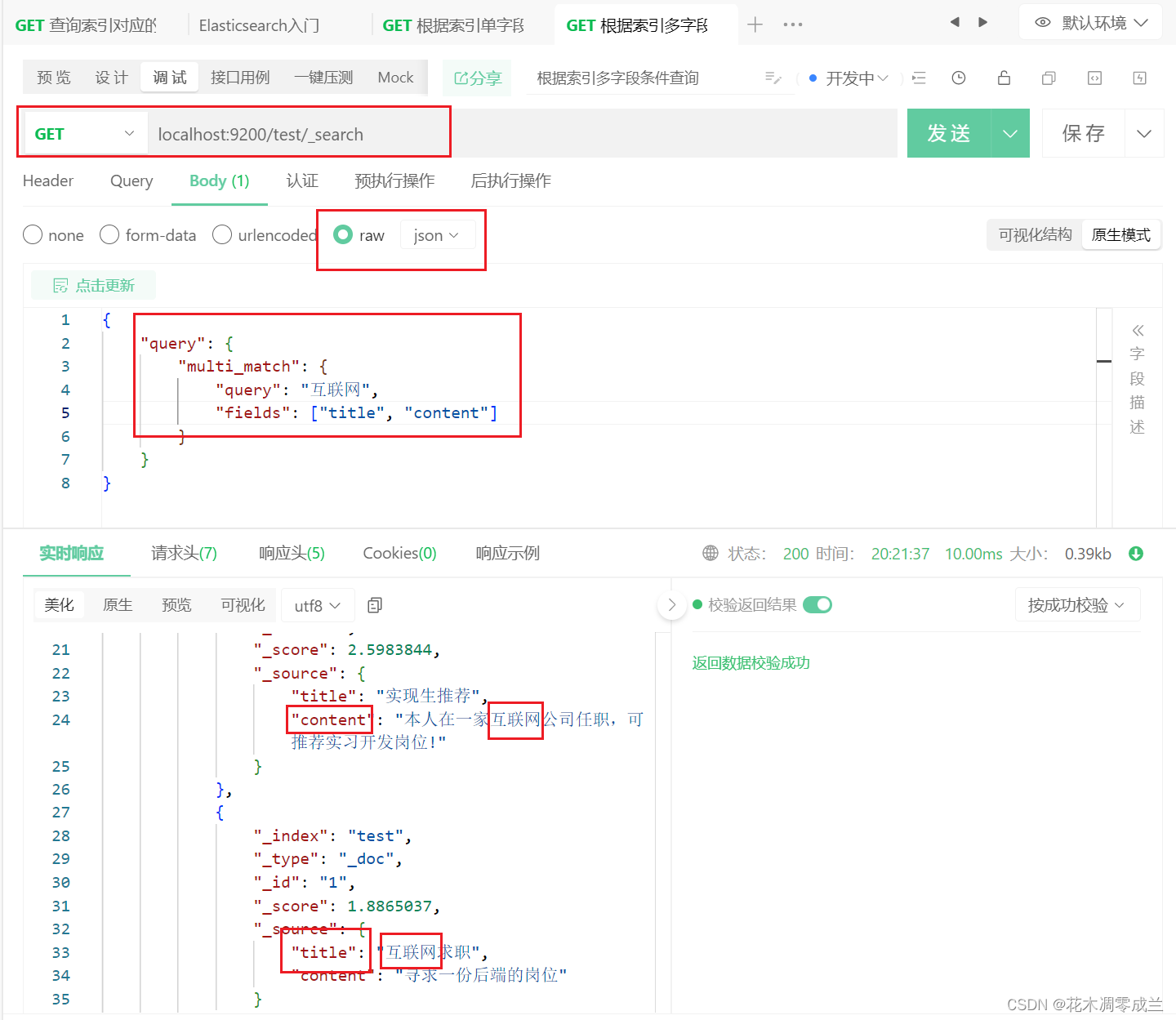
多字段查询格式如图所示;query表示条件,multi_match表示多个匹配,fields则表示匹配条件的字段。
Spring整合Elasticsearch
引入依赖
<!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-data-elasticsearch -->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
配置Elasticsearch
在配置文件application.properties中配置如下内容:
# 连接集群节点
spring.elasticsearch.uris=localhost:9200
出现Redis与Elasticsearch发生Netty冲突
主要是Redis与Elasticsearch都调用了NettyRuntime类的setAvailableProcessors方法。
解决办法
在Application启动类中,添加如下内容:
@PostConstruct // 所注解的方法 会在构造器调用完以后调用public void init() {// 解决Netty启动冲突问题// 由Netty4Utils.setAvailableProcessors()得System.setProperty("es.set.netty.runtime.available.processors", "false");}
配置实体
即配置项目实体与ElasticSearch相对应;即可自动生成与某实体相对应的索引;具体实体类配置如下所示:
/*** @author 花木凋零成兰* @date 2024/3/4 20:16*/
@Document(indexName = "discusspost") // 与Elasticsearch关联 设置索引 注意不能出现大写字母
public class DiscussPost {@Id // 与ES索引对应字段private int id;@Field(type = FieldType.Integer) // type字段类型private int userId;/*** analyzer时候的解析器 ik_max_word 尽可能的拆分* searchAnalyzer搜索时候的解析器 ik_smart 灵活的拆分*/@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")private String title;@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")private String content;@Field(type = FieldType.Integer)private int type;@Field(type = FieldType.Integer)private int status;@Field(type = FieldType.Date)private Date createTime;@Field(type = FieldType.Integer)private int commentCount;@Field(type = FieldType.Double)private double score;}配置接口
配置完实体类后,还需要配置对ES操作接口,即接口内自动包含了与ES有关的API;接口配置如下所示:
/*** ES操作接口* @author 花木凋零成兰* @date 2024/3/25 21:14*/
@Repository
public interface DiscussPostRepository extends ElasticsearchRepository<DiscussPost, Integer> {
}
自定义接口继承ElasticsearchRepository<K, V>类,自定义接口内即有关于ES操作的API,K指操作的数据实体类型,V指数据实体类型的id类型。
测试
在ES7中,ElasticsearchRepository主要用来实现简单的对数据增删改查,即主要用于实现简单操作;ElasticsearchRestTemplate类则主要用来实现对数据的复杂查询等;即主要用户复杂的数据操作。
测试代码如下:
/*** @author 花木凋零成兰* @date 2024/3/25 21:15*/
@SpringBootTest
@ContextConfiguration(classes = Application.class) // 使用Application类的配置
public class ElasticsearchTests {@Autowiredprivate DiscussPostMapper discussPostMapper;@Autowired()private DiscussPostRepository discussPostRepository;@Autowiredprivate ElasticsearchRestTemplate elasticsearchRestTemplate; // 多用于复杂查询@Testpublic void insertTest() {// 测试插入数据 若不存在索引 会自动创建discussPostRepository.save(discussPostMapper.selectDiscussPostById(241)); // 每次插入一条数据discussPostRepository.save(discussPostMapper.selectDiscussPostById(242));discussPostRepository.save(discussPostMapper.selectDiscussPostById(243));}@Testpublic void insertListTest() {discussPostRepository.saveAll(discussPostMapper.selectDiscussPosts(101, 0, 100)); // 一次性插入多条数据discussPostRepository.saveAll(discussPostMapper.selectDiscussPosts(102, 0, 100)); // 一次性插入多条数据discussPostRepository.saveAll(discussPostMapper.selectDiscussPosts(103, 0, 100)); // 一次性插入多条数据discussPostRepository.saveAll(discussPostMapper.selectDiscussPosts(111, 0, 100)); // 一次性插入多条数据discussPostRepository.saveAll(discussPostMapper.selectDiscussPosts(112, 0, 100)); // 一次性插入多条数据discussPostRepository.saveAll(discussPostMapper.selectDiscussPosts(131, 0, 100)); // 一次性插入多条数据discussPostRepository.saveAll(discussPostMapper.selectDiscussPosts(132, 0, 100)); // 一次性插入多条数据discussPostRepository.saveAll(discussPostMapper.selectDiscussPosts(133, 0, 100)); // 一次性插入多条数据discussPostRepository.saveAll(discussPostMapper.selectDiscussPosts(134, 0, 100)); // 一次性插入多条数据}@Testpublic void updateTest() {DiscussPost discussPost = discussPostMapper.selectDiscussPostById(231);discussPost.setContent("我是Java程序员,我要好好学Java!");discussPostRepository.save(discussPost); // 在同样id处重新插入数据 覆盖原先数据}@Testpublic void deleteTest() {discussPostRepository.deleteById(231); // 根据id删除数据}@Testpublic void deleteAllTest() {discussPostRepository.deleteAll(); // 一次性删除所有数据}@Testpublic void testSearch() {// 构造搜索条件NativeSearchQuery searchQuery = new NativeSearchQueryBuilder().withQuery(QueryBuilders.multiMatchQuery("互联网寒冬", "title", "content")) // 构建搜索条件 多字段查询内容.withSorts(SortBuilders.fieldSort("type").order(SortOrder.DESC), // 构建排序顺序 先按照type倒序排SortBuilders.fieldSort("score").order(SortOrder.DESC), // 再按score倒序排SortBuilders.fieldSort("createTime").order(SortOrder.DESC) // 再按创建时间 倒序排).withPageable(PageRequest.of(0, 10)) // 分页查询 第几页, 该页显示数据数量.withHighlightFields( // 配置字段高亮显示new HighlightBuilder.Field("title").preTags("<em>").postTags("</em>"),new HighlightBuilder.Field("content").preTags("<em>").postTags("</em>")).build();SearchHits<DiscussPost> searchHits = elasticsearchRestTemplate.search(searchQuery, DiscussPost.class);if (searchHits.getTotalHits() <= 0) { // 若查询无数据new PageImpl<DiscussPost>(null, PageRequest.of(0, 20), 0);}List<DiscussPost> discussPostList = searchHits.stream().map(SearchHit::getContent).collect(Collectors.toList()); // 将查询的数据转化为List集合Page<DiscussPost> page = new PageImpl<>(discussPostList, searchQuery.getPageable(), searchHits.getTotalHits());System.out.println(page.getTotalElements()); // 获取总数System.out.println(page.getNumber()); // 获取页码System.out.println(page.getSize()); // 获取每页个数System.out.println(page.getTotalPages()); // 分页总数for (DiscussPost discussPost : page) {System.out.println(discussPost); // 输出查询结果}}@Testpublic void testSearchByTemplateHighLight() { // 按条件查询数据 实现高亮NativeSearchQuery searchQuery = new NativeSearchQueryBuilder().withQuery(QueryBuilders.multiMatchQuery("互联网寒冬", "title", "content")) // 构建搜索条件 多字段查询内容.withSorts(SortBuilders.fieldSort("type").order(SortOrder.DESC), // 构建排序顺序 先按照type倒序排SortBuilders.fieldSort("score").order(SortOrder.DESC), // 再按score倒序排SortBuilders.fieldSort("createTime").order(SortOrder.DESC) // 再按创建时间 倒序排).withPageable(PageRequest.of(0, 10)) // 分页查询 第几页, 该页显示数据数量.withHighlightFields(new HighlightBuilder.Field("title").preTags("<em>").postTags("</em>"),new HighlightBuilder.Field("content").preTags("<em>").postTags("</em>")) // 配置字段高亮显示.build();SearchHits<DiscussPost> searchHits = elasticsearchRestTemplate.search(searchQuery, DiscussPost.class);// SearchPage<DiscussPost> page = SearchHitSupport.searchPageFor(searchHits, searchQuery.getPageable());// 获取高亮结果集List<DiscussPost> list = new ArrayList<>();for (SearchHit<DiscussPost> searchHit : searchHits) {DiscussPost discussPost = searchHit.getContent();if (searchHit.getHighlightFields().get("title") != null) {discussPost.setTitle(searchHit.getHighlightFields().get("title").get(0));// discussPost.setContent(searchHit.getHighlightField("content").toString());}if (searchHit.getHighlightFields().get("content") != null) {discussPost.setContent(searchHit.getHighlightFields().get("content").get(0));// discussPost.setContent(searchHit.getHighlightField("content").toString());}list.add(discussPost);}// 组装分页对象Page<DiscussPost> pageInfo = new PageImpl<>(list, searchQuery.getPageable(), searchHits.getTotalHits());System.out.println(pageInfo.getTotalElements()); // 获取查询得到数据总数System.out.println(pageInfo.getTotalPages()); // 获取总页数System.out.println(pageInfo.getNumber()); // 获取当前页码System.out.println(pageInfo.getSize()); // 获取当前页面个数// 输出分页结果for (DiscussPost discussPost : pageInfo) {System.out.println(discussPost);}}
}
因测试数据过多,此处只展示最后一个测试方法执行成功结果;如下所示: