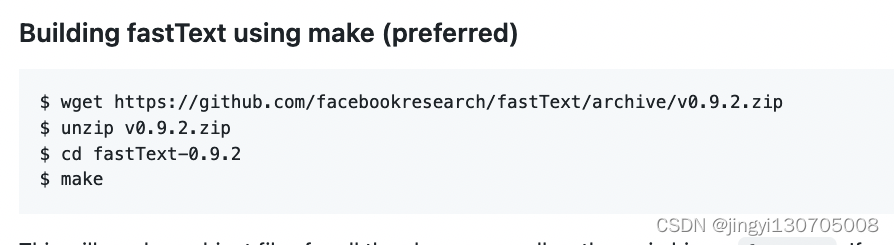
1.安装正确版本
(1)下载IncrementalTraining分支代码GitHub - SergeiAlonichau/fastText at IncrementalTraining,或者下载资源;
(2)将上一步下载的zip进行解压,然后进入文件夹执行make操作即可;
仿照下面的示例,注意一定要是IncrementalTraining分支的代码
2.使用教程
当前版本代码新增了-nepoch、-inputModel两个参数。
-inputModel:指定需要继续训练的模型文件,不需要增量训练时不需要设置该参数。
-nepoch:指定该参数时每迭代一个epoch将会对模型保存一次,并且模型前缀为inputModel传入的参数。当nepoch为0时则不进行加载checkpoint,默认值为-1.
新增用途:
(1)在每轮epoch下可以进行增量训练和评估;
(2)可以通过分批训练来支持海量数据的训练;
(3)微调已经预训练好的模型。
3.使用示例
3.1 一般训练
执行命令
./fasttext.exe supervised -input in_sample_td_1p.txt -output modelx -dim 2 -wordNgrams 6 -bucket 80000000 -thread 10 -verbose 1 -epoch 10
./fasttext test modelx.bin in_sample_td_1p.txt 1执行日志
Read 96M words
Number of words: 234072
Number of labels: 2
start training...
Progress: 100.0% words/sec/thread: 11638890 lr: 0.000000 loss: 0.204641 ETA: 0h 0mN 4002234
P@1 0.994
R@1 0.994
Number of examples: 40022343.2 增量训练
执行命令
./fasttext.exe supervised -input in_sample_td_1p.txt -output model0 -dim 2 -wordNgrams 6 -bucket 80000000 -thread 10 -verbose 1 -epoch 10 -nepoch 0 -inputModel empty.bin
./fasttext test model0.bin in_sample_td_1p.txt 1
for e in 1 2 3 4 5 6 7 8 9 ; dop=`awk "BEGIN { print $e -1 }"` ;echo ./fasttext.exe supervised -input in_sample_td_1p.txt -output model$e -dim 2 -wordNgrams 6 -bucket 80000000 -thread 10 -verbose 1 -inputModel model$p.bin -epoch 10 -nepoch $e ;./fasttext.exe supervised -input in_sample_td_1p.txt -output model$e -dim 2 -wordNgrams 6 -bucket 80000000 -thread 10 -verbose 1 -inputModel model$p.bin -epoch 10 -nepoch $e ;echo ./fasttext test model$e.bin in_sample_td_1p.txt 1 ;./fasttext test model$e.bin in_sample_td_1p.txt 1 ;
done执行日志
...Read 96M words
Number of words: 234072
Number of labels: 2
Update args
Load dict from trained model
Read 96M words
Load dict from training data
Read 96M words
Number of words: 234072
Number of labels: 2
start training...
Progress: 100.0% words/sec/thread: 108804462 lr: 0.000000 loss: 0.208056 ETA: 0h 0m
./fasttext test model8.bin in_sample_td_1p.txt 1
N 4002234
P@1 0.991
R@1 0.991
Number of examples: 4002234
./fasttext.exe supervised -input in_sample_td_1p.txt -output model9 -dim 2 -wordNgrams 6 -bucket 80000000 -thread 10 -verbose 1 -inputModel model8.bin -epoch 10 -nepoch 9
Read 96M words
Number of words: 234072
Number of labels: 2
Update args
Load dict from trained model
Read 96M words
Load dict from training data
Read 96M words
Number of words: 234072
Number of labels: 2
start training...
Progress: 100.0% words/sec/thread: 119974496 lr: 0.000000 loss: 0.188905 ETA: 0h 0m
./fasttext test model9.bin in_sample_td_1p.txt 1
N 4002234
P@1 0.993
R@1 0.993
Number of examples: 4002234说明:上述命令先用in_sample_td_1p.txt 数据迭代了10个epoch,然后产生了10个checkpoint,之后再在数据上进行10轮epoch的增量训练,
注意程序会根据thread的取值将bin模型拆分为几个part,供后续增量更新。并且增量训练需要前后保持thread一致,如果最后一次增量训练没设置nepoch则不会产生part文件。
参考资料:
GitHub - SergeiAlonichau/fastText at IncrementalTraining