手动调参
分析影响模型的参数,设计步长进行交叉验证
我们以随机森林为例:
本文将使用sklearn自带的乳腺癌数据集,建立随机森林,并基于泛化误差(Genelization Error)与模型复杂度的关系来对模型进行调参,从而使模型获得更高的得分。
泛化误差是机器学习中,用来衡量模型在未知数据上的准确率的指标;
1、导入相关包
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt2、导入乳腺癌数据集,建立模型
由于sklearn自带的数据集已经很工整了,所以无需做预处理,直接使用。
# 导入乳腺癌数据集
data = load_breast_cancer()# 建立随机森林
rfc = RandomForestClassifier(n_estimators=100, random_state=90)用交叉验证计算得分
score_pre = cross_val_score(rfc, data.data, data.target, cv=10).mean()
score_pre3、调参
随机森林主要的参数有n_estimators(子树的数量)、max_depth(树的最大生长深度)、min_samples_leaf(叶子的最小样本数量)、min_samples_split(分支节点的最小样本数量)、max_features(最大选择特征数)。它们对随机森林模型复杂度的影响如下图所示:
n_estimators是影响程度最大的参数,我们先对其进行调整
# 调参,绘制学习曲线来调参n_estimators(对随机森林影响最大)
score_lt = []# 每隔10步建立一个随机森林,获得不同n_estimators的得分
for i in range(0,200,10):rfc = RandomForestClassifier(n_estimators=i+1,random_state=90)score = cross_val_score(rfc, data.data, data.target, cv=10).mean()score_lt.append(score)
score_max = max(score_lt)
print('最大得分:{}'.format(score_max),'子树数量为:{}'.format(score_lt.index(score_max)*10+1))# 绘制学习曲线
x = np.arange(1,201,10)
plt.subplot(111)
plt.plot(x, score_lt, 'r-')
plt.show()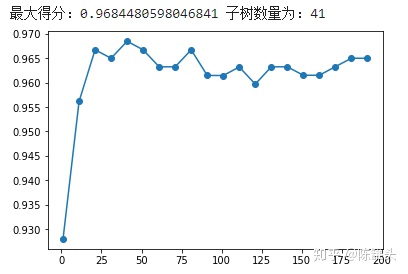
如图所示,当n_estimators从0开始增大至21时,模型准确度有肉眼可见的提升。这也符合随机森林的特点:在一定范围内,子树数量越多,模型效果越好。而当子树数量越来越大时,准确率会发生波动,当取值为41时,获得最大得分。
框架自动调参
Optuna是一个自动化的超参数优化软件框架,专门为机器学习而设计。 这里对其进行简单的入门介绍,详细的学习可以参考:https://github.com/optuna/optuna
optuna是一个使用python编写的超参数调节框架。一个极简的 optuna 的优化程序中只有三个最核心的概念,目标函数(objective),单次试验(trial),和研究(study)。其中 objective 负责定义待优化函数并指定参/超参数数范围,trial 对应着 objective 的单次执行,而 study 则负责管理优化,决定优化的方式,总试验的次数、试验结果的记录等功能。
- objective:根据目标函数的优化Session,由一系列的trail组成。
- trail:根据目标函数作出一次执行。
- study:根据多次trail得到的结果发现其中最优的超参数。
随机森林iris数据集调优
from sklearn.datasets import load_iris
x, y = load_iris().data, load_iris().target
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
def objective(trial):global x, yX_train, X_test, y_train, y_test=train_test_split(x, y, train_size=0.3)# 数据集划分param = {"n_estimators": trial.suggest_int('n_estimators', 5, 20),"criterion": trial.suggest_categorical('criterion', ['gini','entropy'])}dt_clf = RandomForestClassifier(**param)dt_clf.fit(X_train, y_train)pred_dt = dt_clf.predict(X_test)score = (y_test==pred_dt).sum() / len(y_test)return score
study=optuna.create_study(direction='maximize')
n_trials=20 # try50次
study.optimize(objective, n_trials=n_trials)
print(study.best_value)
print(study.best_params)
#######################################结果######################################
[32m[I 2021-04-12 16:20:13,627][0m A new study created in memory with name: no-name-47fe20d7-e9c0-4bed-bc6d-8113edae0bec[0m
[32m[I 2021-04-12 16:20:13,652][0m Trial 0 finished with value: 0.9523809523809523 and parameters: {'n_estimators': 15, 'criterion': 'gini'}. Best is trial 0 with value: 0.9523809523809523.[0m
[32m[I 2021-04-12 16:20:13,662][0m Trial 1 finished with value: 0.9523809523809523 and parameters: {'n_estimators': 5, 'criterion': 'gini'}. Best is trial 0 with value: 0.9523809523809523.[0m
[32m[I 2021-04-12 16:20:13,680][0m Trial 2 finished with value: 0.9428571428571428 and parameters: {'n_estimators': 15, 'criterion': 'entropy'}. Best is trial 0 with value: 0.9523809523809523.[0m
[32m[I 2021-04-12 16:20:13,689][0m Trial 3 finished with value: 0.9523809523809523 and parameters: {'n_estimators': 7, 'criterion': 'gini'}. Best is trial 0 with value: 0.9523809523809523.[0m
[32m[I 2021-04-12 16:20:13,704][0m Trial 4 finished with value: 0.9428571428571428 and parameters: {'n_estimators': 14, 'criterion': 'gini'}. Best is trial 0 with value: 0.9523809523809523.[0m
[32m[I 2021-04-12 16:20:13,721][0m Trial 5 finished with value: 0.9714285714285714 and parameters: {'n_estimators': 14, 'criterion': 'gini'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,733][0m Trial 6 finished with value: 0.9619047619047619 and parameters: {'n_estimators': 10, 'criterion': 'gini'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,753][0m Trial 7 finished with value: 0.9619047619047619 and parameters: {'n_estimators': 18, 'criterion': 'gini'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,764][0m Trial 8 finished with value: 0.9714285714285714 and parameters: {'n_estimators': 8, 'criterion': 'entropy'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,771][0m Trial 9 finished with value: 0.9333333333333333 and parameters: {'n_estimators': 5, 'criterion': 'gini'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,795][0m Trial 10 finished with value: 0.9333333333333333 and parameters: {'n_estimators': 20, 'criterion': 'entropy'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,809][0m Trial 11 finished with value: 0.9333333333333333 and parameters: {'n_estimators': 9, 'criterion': 'entropy'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,827][0m Trial 12 finished with value: 0.9428571428571428 and parameters: {'n_estimators': 12, 'criterion': 'entropy'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,842][0m Trial 13 finished with value: 0.9238095238095239 and parameters: {'n_estimators': 11, 'criterion': 'entropy'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,855][0m Trial 14 finished with value: 0.9428571428571428 and parameters: {'n_estimators': 8, 'criterion': 'entropy'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,880][0m Trial 15 finished with value: 0.9428571428571428 and parameters: {'n_estimators': 18, 'criterion': 'entropy'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,899][0m Trial 16 finished with value: 0.9428571428571428 and parameters: {'n_estimators': 13, 'criterion': 'entropy'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,911][0m Trial 17 finished with value: 0.9714285714285714 and parameters: {'n_estimators': 7, 'criterion': 'gini'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,933][0m Trial 18 finished with value: 0.9428571428571428 and parameters: {'n_estimators': 17, 'criterion': 'entropy'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,948][0m Trial 19 finished with value: 0.9523809523809523 and parameters: {'n_estimators': 11, 'criterion': 'gini'}. Best is trial 5 with value: 0.9714285714285714.[0m0.9714285714285714
{'n_estimators': 14, 'criterion': 'gini'}
##################################################################################