简介
概述

图-1 HBase图标
HBase原本是由Yahoo!公司开发的后来贡献给了Apache的一套开源的、基于Hadoop的、分布式的、可扩展的非关系型数据库(Non-Relational Database),因此HBase不支持SQL(非关系型数据库基本上都不支持SQL),而是提供了一套单独的命令用于操作HBase。
HBase本身是仿照了Google的Big Table(Google的论文<Google's Bigtable: A Distributed Storage System for Structured Data >)来实现的,因此HBase和Big Table除了实现语言不同(Big Table是使用C/C++实现的,HBase是使用Java实现的)以外,原理是一致的。
HBase能够管理非常大的表(billions of rows * millions of columns),且支持对大量的数据进行随机且实时的读写。而HBase本身是依赖于HDFS来存储这大量的数据。
迄今为止(截止到2023年07月31日),HBase一共提供了4个大版本:HBase0.X ,HBase1.X,HBase2.X以及HBase3.X。其中HBase0.X版本已经停止更新维护,因此市面上不再使用。HBase1.X的最新版本是HBase1.7.2(2022年02月08日更新),HBase2.X的最新版本是HBase2.5.5(2023年06月13号更新),HBase3.X的最新版本是HBase-3.0.0-alpha-4(2023年06月07日更新)。目前官网上指明,HBase3.X版本不稳定,还在测试阶段,不推荐在生产环境中使用(Testing only, not production ready);HBase2.5.5版本是目前最新的稳定版本(stable release)。
由于HBase是用Java语言实现的,且HBase基于HDFS来实现大量数据的存储,所以在选择HBase版本的时候需要注意和JDK版本以及和Hadoop版本的兼容性问题。
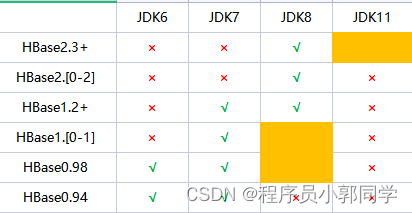
图-2 HBase版本和JDK版本兼容性

图-3 HBase版本和Hadoop版本兼容性
基本概念/数据模型
Rowkey(行键)
首先,需要注意的是,在HBase中没有主键的概念,取而代之的是行键(Rowkey)。不同于传统的关系型数据库,在HBase中,定义表的时候不需要指定行键列(例如MySQL中创建表的时候需要指定某一列为主键列,而HBase不需要),而是在添加数据的时候来手动添加行键,每一个行键都是这一行数据的唯一标识。在查询数据(HBase中查询数据和扫描整表是两个不同的操作)的时候,必须根据行键来获取数据,因此行键的合理性是十分有必要的。HBase默认会对行键来进行排序,按照字典序排序。
Column Family(列族/列簇)
在HBase中,没有表关联(join)的概念,取而代之的是用列族来进行设计。在HBase中,一个表中至少要包含1个列族,可以包含多个列族,理论上不限制列族的数量,每一个列族都可以看作是一个子表。需要注意的是,虽然理论上HBase的每一个表中不限制列族的数量,但是实际过程中一般不超过3个列族。官方建议一张表中的列族越少越好,列族太多会导致效率降低,且目前版本的HBase中,列族过多容易出现问题。
还需要注意的是,在HBase中强调列族,但是不强调列:在定义表的时候必须定义列族,每一个列族可以单独指定属性,表定义好之后,列族就不能更改(列族的数量和列族名不能变,属性可以变),但是每一个列族中的列可以动态增删,一个列族中可以包含0到多个列。
namespace(名称空间)
同样,在HBase中也没有database的概念,取而代之的是namespace。在HBase启动的时候,自带了两个空间:default和hbase。hbase空间下放的是HBase的基本信息(HBase的内置表) ,所以一般不要操作这个空间;default空间是HBase提供给用户操作的默认空间,在建表的时候如果不指定,则表默认是放在default空间下。
其他概念
Column Qualifier:列限定符。实际上就是列,需要注意的是,在HBase中,列是可以动态增删的,所以不同行的数据包含的列可能不一样,因此HBase中存储的数据是稀疏的。
Timestamp:时间戳。在HBase中,会对写入的每一条数据添加一个时间戳,用于标记数据写入的时间,同时可以立即为标记数据写入的顺序。这个时间戳,称之为版本(VERSION),当用户获取数据的时候,会自动返回最新版本(即时间戳最大)的数据。如果不指定,那么HBase默认只存储1个版本的数据,用户也只能获取1个版本的数据。如果需要HBase存储多个版本的数据(最新数据+历史数据),那么需要在列族的属性中指定。同样,如果需要获取多个版本的数据,也需要在命令中指定。
Cell:单元。在HBase中,如果要锁定唯一的一条数据,那么需要通过行键+列族+列+时间戳这四个维度来锁定,这种结构就称之为是一个Cell。
Hive和HBase的比较
Hive本质上是一个用于进行数据仓库管理的工具,在实际过程中经常用于对数据进行分析和清洗,提供了相对标准的SQL结构,底层会将SQL转化为MapReduce来执行,因此Hive的效率相对较低,更适合于离线开发的场景。Hive一般针对历史数据进行分析,一般只提供增加和查询的能力,一般不会提供修改和删除的功能。
HBase本质上是一个非关系型数据库,在实际过程中,用于存储数据。因为HBase的读写效率较高,吞吐量较大,因此一般使用HBase来存储实时的数据,最终数据会落地到HDFS上。HBase作为数据库,提供了完整的增删改查的能力,但是相对而言,HBase的事务能力较弱。HBase不支持SQL,提供了一套完整的命令。
总结:Hive强调的是分析能力,但是HBase强调的是存储能力,相同的地方在于两者都是利用HDFS来存储数据。
编译和安装
编译
此处选择HBase2.5.5版本来编译。
1)进入预安装目录,上传或者下载HBase的源码包:
# 进入预安装目录
cd /opt/presoftware
# 官方下载地址
wget --no-check-certificate https://dlcdn.apache.org/hbase/2.5.5/hbase-2.5.5-src.tar.gz
2)解压至源码目录:
tar -xvf hbase-2.5.5-src.tar.gz -C /opt/source/
3)进入HBase的源码目录:
cd /opt/source/hbase-2.5.5/
4)执行编译命令:
mvn clean package \
-Pdist,nativeN,docs \
-DskipTests \
-Dtar \
-Dmaven.skip.test=true \
-Dmaven.javadoc.skip=true \
-Denforcer.skip=true \
assembly:single
5)编译好的安装包在hbase-assembly/target目录下。
安装
安装HBase之前,需要服务器先安装好JDK1.8,Zookeeper(课程中是Zookeeper3.5.8),Hadoop(课程中是Hadoop3.2.4)版本。
1)进入软件预安装目录,上传或者下载HBase的安装包:
# 进入预安装目录
cd /opt/presoftware/
# 官网下载地址
wget --no-check-certificate https://dlcdn.apache.org/hbase/2.5.5/hbase-2.5.5-bin.tar.gz
2)解压至软件安装目录:
tar -xvf hbase-2.5.5-bin.tar.gz -C /opt/software/
3)进入HBase的配置目录:
cd /opt/software/hbase-2.5.5/conf/
4)修改hbase-env.sh:
# 编辑文件
vim hbase-env.sh
# 在文件中添加
export JAVA_HOME=/opt/software/jdk1.8
export HBASE_MANAGES_ZK=false
# 保存退出,生效
source hbase-env.sh
5)编辑文件:
vim hbase-site.xml
删除掉原来的属性,在文件中添加:
<!--指定HBase在HDFS上的存储位置-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop01:9000/hbase</value>
</property>
<!--开启HBase的分布式-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--配置Zookeeper连接地址-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop01,hadoop02,hadoop03:2181</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
6)指定子节点:
# 编辑文件
vim regionservers
# 删除掉原来的主机名,在文件中添加自己的主机名,例如
hadoop01
hadoop02
hadoop03
7)将Hadoop的核心配置拷贝到HBase的配置目录下:
cp /opt/software/hadoop-3.2.4/etc/hadoop/core-site.xml ./
8)远程分发HBase:
# 回到安装目录
cd /opt/software/
# 远程分发
scp -r hbase-2.5.5/ root@hadoop02:$PWD
scp -r hbase-2.5.5/ root@hadoop03:$PWD
9)配置环境变量:
# 编辑文件
vim /etc/profile.d/hbasehome.sh
# 在文件中添加
export HBASE_HOME=/opt/software/hbase-2.5.5
export PATH=$PATH:$HBASE_HOME/bin
# 保存退出,生效
source /etc/profile.d/hbasehome.sh
# 测试
hbase version
10)启动Zookeeper:
# 启动Zookeeper
zkServer.sh start
# 查看状态
zkServer.sh status
11)启动HDFS:
start-dfs.sh
12)启动HBase:
start-hbase.sh
启动成功之后,可以在浏览器中通过http://IP或者主机名:16010来访问HBase的web页面了。

图-4 WEB页面
HBase操作
启动命令
启动HBase集群:
start-hbase.sh
停止HBase集群:
stop-hbase.sh
进入HBase命令行:
hbase shell
启动HMaster:
hbase-daemon.sh start master
结束HMaster:
hbase-daemon.sh stop master
启动HRegionServer:
hbase-daemon.sh start regionserver
结束HRegionServer:
hbase-daemon.sh stop regionserver
命令操作
general
查看当前在执行的任务:
processlist
查看HBase的运行状态:
status
查看当前HBase的版本:
version
查看当前在使用HBase的用户:
whoami
DDL
建立一个person表,包含3个列族:basic,info,other:
create 'person', {NAME => 'basic'}, {NAME => 'info'}, {NAME => 'other'}
-- 或者
create 'person', 'basic', 'info', 'other'
指定每一个列族允许对外获取的版本数量:
create 'students', {NAME => 'basic', VERSIONS => 3}, {NAME => 'info', VERSIONS => 4}
描述表信息:
desc 'students'
-- 或者
describe 'students'
禁用表:
disable 'demo:users'
删除表:
drop 'demo:users'
启用表:
enable 'person'
判断表是否存在:
exists 'users'
判断person表是否被禁用:
is_disabled 'person'
判断person表是否被启用:
is_enabled 'person'
查看所有空间下的所有的表:
list
列出所有的过滤器:
show_filters
定位p1行键所在的HRegion的位置:
locate_region 'person', 'p1'
禁用demo空间下的所有的表:
disable_all 'demo:.*'
删除demo空间下的所有的表:
drop_all 'demo.*'
启用demo空间下的所有的表:
enable_all 'demo:.*'
DML
在person表中添加一个行键为p1的数据,向basic列族的name列中添加数据:
append 'person', 'p1', 'basic:name', 'Bob'
获取指定行键的数据:
get 'person', 'p1'
获取指定行键指定列族的数据:
get 'person', 'p1', {COLUMN => 'basic'}
或者
get 'person', 'p1', 'basic'
获取指定行键多列族的数据:
get 'person', 'p1', {COLUMN => ['basic', 'info']}
或者
get 'person', 'p1', 'basic', 'info'
获取指定行键指定列的数据:
get 'person', 'p1', {COLUMN => 'basic:name'}
-- 或者
get 'person', 'p1', 'basic:name'
扫描整表:
scan 'person'
获取指定列族的数据:
scan 'person', {COLUMNS => 'basic'}
获取多列族的数据:
scan 'person', {COLUMNS => ['basic', 'info']}
获取多个列的数据:
scan 'person', {COLUMNS => ['basic:name', 'other:address']}
修改数据:
put 'person', 'p1', 'basic:age', 20
删除指定行键指定列族的指定列:
delete 'person', 'p1', 'other:adderss'
-- 或者
deleteall 'person', 'pb', 'basic:name'
删除指定行键的所有数据:
deleteall 'person', 'p1'
获取指定行键指定列的指定数量版本的数据:
get 'students', 's1', {COLUMN => 'basic:age', VERSIONS => 3}
获取指定列的指定数量版本的数据:
scan 'students', {COLUMNS => 'basic:age', VERSIONS => 3}
统计person表中行键的个数:
count 'person'
获取person表对应的HRegion的个数:
get_splits 'person'
摧毁重建person表:
truncate 'person'
namespace
查看所有的空间:
list_namespace
创建demo空间:
create_namespace 'demo'
在demo空间下创建users表:
create 'demo:users', 'basic'
获取demo空间下的所有表:
list_namespace_tables 'demo'
描述demo空间:
describe_namespace 'demo'
删除demo空间,要求这个空间为空:
drop_namespace 'demo'
API
POM文件
在POM文件中添加如下内容:
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.5.5</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>2.5.5</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.5.5</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-protocol</artifactId>
<version>2.5.5</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase</artifactId>
<version>2.5.5</version>
<type>pom</type>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-mapreduce</artifactId>
<version>2.5.5</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-zookeeper</artifactId>
<version>2.5.5</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
</dependency>
<!--日志打印-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.12.0</version>
</dependency>
<!--Hadoop通用包-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.2.4</version>
</dependency>
<!--Hadoop客户端-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.4</version>
</dependency>
<!--Hadoop HDFS-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.2.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>3.2.4</version>
</dependency>
</dependencies>
Namespace API
发起连接以及关闭连接:
public class TestNamespace {
private Connection con;
private Admin admin;
// 发起连接
@Before
public void connect() throws IOException {
// 获取配置
Configuration conf = HBaseConfiguration.create();
// 指定Zookeeper连接地址
conf.set("hbase.zookeeper.quorum", "hadoop01:2181,hadoop02:2181,hadoop03:2181");
// 获取连接
con = ConnectionFactory.createConnection(conf);
// 获取管理权
admin = con.getAdmin();
}
// 关闭连接
@After
public void close() throws IOException {
if (admin != null) admin.close();
if (con != null) con.close();
}
}
创建名称空间:
// 创建名称空间
@Test
public void createNamespace() throws IOException {
// 构建空间描述器,指定空间名字
NamespaceDescriptor descriptor = NamespaceDescriptor.create("demo").build();
// 创建名称空间
admin.createNamespace(descriptor);
}
获取所有空间的名字:
@Test
public void listNamespaces() throws IOException {
// 获取所有空间的名字
String[] names = admin.listNamespaces();
// 遍历
for (String name : names) {
System.out.println(name);
}
}
删除空间:
@Test
public void listNamespaceTables() throws IOException {
admin.deleteNamespace("demo");
}
Table API
发起连接及关闭连接:
public class TestTable {
private Connection con;
private Admin admin;
private Table table;
// 发起连接
@Before
public void connect() throws IOException {
// 获取配置
Configuration conf = HBaseConfiguration.create();
// 设置Zookeeper连接地址
conf.set("hbase.zookeeper.quorum", "hadoop01:2181,hadoop02:2181,hadoop03:2181");
// 发起连接
con = ConnectionFactory.createConnection(conf);
// 获取管理权
admin = con.getAdmin();
// 获取表
table = con.getTable(TableName.valueOf("users"));
}
// 关闭连接
@After
public void close() throws IOException {
if (table != null) table.close();
if (admin != null) admin.close();
if (con != null) con.close();
}
}
创建表users:
// 建表
@Test
public void createTable() throws IOException {
// 获取列族描述器
ColumnFamilyDescriptor cf1 = ColumnFamilyDescriptorBuilder.newBuilder("basic".getBytes()).build();
ColumnFamilyDescriptor cf2 = ColumnFamilyDescriptorBuilder.newBuilder("info".getBytes()).build();
// 获取表描述器,指定列族
TableDescriptor table = TableDescriptorBuilder.newBuilder(TableName.valueOf("users")).setColumnFamily(cf1).setColumnFamily(cf2).build();
// 创建表
admin.createTable(table);
}
在表中添加数据:
@Test
public void appendData() throws IOException {
// 构建append对象
Append append = new Append("u1".getBytes());
// 添加列
append.addColumn("basic".getBytes(), "name".getBytes(), "Vincent".getBytes());
append.addColumn("basic".getBytes(), "age".getBytes(), "21".getBytes());
append.addColumn("basic".getBytes(), "gender".getBytes(), "male".getBytes());
append.addColumn("info".getBytes(), "address".getBytes(), "beijing".getBytes());
append.addColumn("info".getBytes(), "phone".getBytes(), "123456".getBytes());
// 添加数据
table.append(append);
}
向表中添加/修改数据:
// 修改/添加数据
@Test
public void putData() throws IOException {
// 封装Put对象
Put put = new Put("u1".getBytes(StandardCharsets.UTF_8));
// 添加列
put.addColumn("basic".getBytes(StandardCharsets.UTF_8), "password".getBytes(StandardCharsets.UTF_8), "123456".getBytes(StandardCharsets.UTF_8));
// 添加/修改数据
users.put(put);
}
测试添加百万条数据:
// 测试添加百万数据
@Test
public void appendMillionData() throws IOException {
// 定义集合临时存储数据
List<Put> puts = new ArrayList<>();
// 列族
byte[] family = "basic".getBytes();
// 列
byte[] qualifier = "password".getBytes();
// 起始时间
long begin = System.currentTimeMillis();
// 添加百万条数据
for (int i = 0; i < 1000000; i++) {
//构建put对象
Put put = new Put(("u" + i).getBytes());
put.addColumn(family, qualifier, getPassword());
// 放入集合
puts.add(put);
if (puts.size() >= 1000) {
// 每一千条数据放一次
table.put(puts);
// 清空集合
puts.clear();
}
}
// 结束时间
long end = System.currentTimeMillis();
System.out.println(end - begin);
}
private byte[] getPassword() {
StringBuilder builder = new StringBuilder();
for (int i = 0; i < 6; i++) {
char c = (char) (Math.random() * 26 + 65);
builder.append(c);
}
return builder.toString().getBytes();
}
删除指定行键的数据:
@Test
public void deleteLine() throws IOException {
// 封装Delete对象
Delete del = new Delete("u1".getBytes());
// 删除一行数据
table.delete(del);
}
删除指定行键指定列族的数据:
@Test
public void deleteFamily() throws IOException {
// 构建Delete对象
Delete del = new Delete("u2".getBytes());
// 指定列族
del.addFamily("basic".getBytes());
// 删除数据
table.delete(del);
}
删除指定行键指定列:
@Test
public void deleteData() throws IOException {
// 封装Delete对象
Delete del = new Delete("u3".getBytes());
// 指定列
del.addColumn("basic".getBytes(), "password".getBytes());
// 删除数据
table.delete(del);
}
获取指定行键的数据:
@Test
public void getLine() throws IOException {
// 封装Get对象
Get get = new Get("u1".getBytes());
// 获取结果
Result result = table.get(get);
// 获取列族,这个families的键表示的列族名,值是列族中包含的列
NavigableMap<byte[], NavigableMap<byte[], NavigableMap<Long,byte[]>>> families = result.getMap();
for(Map.Entry<byte[], NavigableMap<byte[],NavigableMap<Long,byte[]>>> family : families.entrySet()){
// 键是列族名
System.out.println("Column Family:" + new String(family.getKey()));
// 值是包含的列
NavigableMap<byte[], NavigableMap<Long,byte[]>> columns = family.getValue();
for(Map.Entry<byte[], NavigableMap<Long,byte[]>> column : columns.entrySet()){
// 键是列名
System.out.println("\tColumn:" + new String(column.getKey()));
// 值是这个列对应的值
NavigableMap<Long, byte[]> value = column.getValue();
for(Map.Entry<Long, byte[]> v : value.entrySet()){
// 键是时间戳
System.out.println("\t\tTimestamp:" + v.getKey());
// 值是对应的值
System.out.println("\t\tValue:" + new String(v.getValue()));
}
}
}
}
获取指定行键指定列族的而数据:
@Test
public void getFamily() throws IOException {
// 封装Get对象
Get get = new Get("u1".getBytes());
// 指定列族
get.addFamily("basic".getBytes());
// 查询数据,获取结果
Result result = table.get(get);
// 获取列族
NavigableMap<byte[], byte[]> familyMap = result.getFamilyMap("basic".getBytes());
// 遍历结果
for (Map.Entry<byte[], byte[]> column : familyMap.entrySet()) {
//获取列名和数据
System.out.println(new String(column.getKey()) + "=" + new String(column.getValue()));
}
}
获取指定行键指定列的数据:
@Test
public void getData() throws IOException {
// 封装Get对象
Get get = new Get("u1".getBytes());
// 指定列
get.addColumn("basic".getBytes(), "name".getBytes());
// 查询数据,获取结果
Result result = table.get(get);
// 获取数据
byte[] value = result.getValue("basic".getBytes(), "name".getBytes());
System.out.println(new String(value));
}
扫描所有数据:
@Test
public void scanData() throws IOException {
// 封装Scan对象
Scan scan = new Scan();
// 添加扫描仪,获取结果集
ResultScanner scanner = table.getScanner(scan);
// 遍历结果集
Iterator<Result> iterator = scanner.iterator();
byte[] family = "basic".getBytes();
byte[] qualifier = "password".getBytes();
while (iterator.hasNext()) {
// 获取结果
Result result = iterator.next();
// 获取数据
byte[] value = result.getValue(family, qualifier);
if (value != null)
System.out.println(new String(value));
}
}
过滤数据:
@Test
public void filter() throws IOException {
// 构建Scan对象
Scan scan = new Scan();
// 构建Filter对象
Filter filter = new ValueFilter(CompareOperator.EQUAL, new RegexStringComparator(".*AAA.*"));
// 添加过滤器
scan.setFilter(filter);
// 获取结果集
ResultScanner scanner = table.getScanner(scan);
byte[] family = "basic".getBytes();
byte[] qualifier = "password".getBytes();
// 遍历数据
for (Result result : scanner) {
byte[] value = result.getValue(family, qualifier);
System.out.println(new String(value));
}
}
HBase结构
HRegion
概述
在HBase中,会将每一个表从行键方向上进行切分,切分出来的每一个结构,称之为HRegion。注意,在HBase中,每一个表中至少包含1个HRegion,可以包含多个HRegion。切分之后,每一个HRegion都会交给某一个HRegionServer来管理。需要注意的是,一个HRegionServer可以管理多个HRegion。
在HBase中,行键是有序的(行键默认是按照字典序排序的),所以切分出来的HRegion之间是不交叉的,因此HBase中,可以将不同的请求分发给不同的HRegionServer,从而避免了请求集中在某一个节点上,尽量保证了请求的分散。
随着运行时间的推移,HRegion中管理的数据变得越来越多,那么当HRegion中管理的数据达到指定大小的时候,会进行分裂。刚分裂完的时候,两个HRegion都是在同一个HRegionServer上的,但是HBase为了负载均衡,可能会将其中一个HRegion转移到其他HRegionServer上进行管理。注意,这个过程中,不会发生大量数据的转移!
每一个HRegion中,至少包含1个HStore,可以包含多个HStore,HStore的数量由列族数量决定。如果一个表中包含了3个列族,那么HRegion中就包含3个HStore。每一个HStore中会包含1个memStore以及0到多个StoreFile。StoreFile又叫HFile(HBase不同版本中的叫法)。

图-5 HRegion结构
分裂策略
在HBase2.X中,支持7中分裂策略:
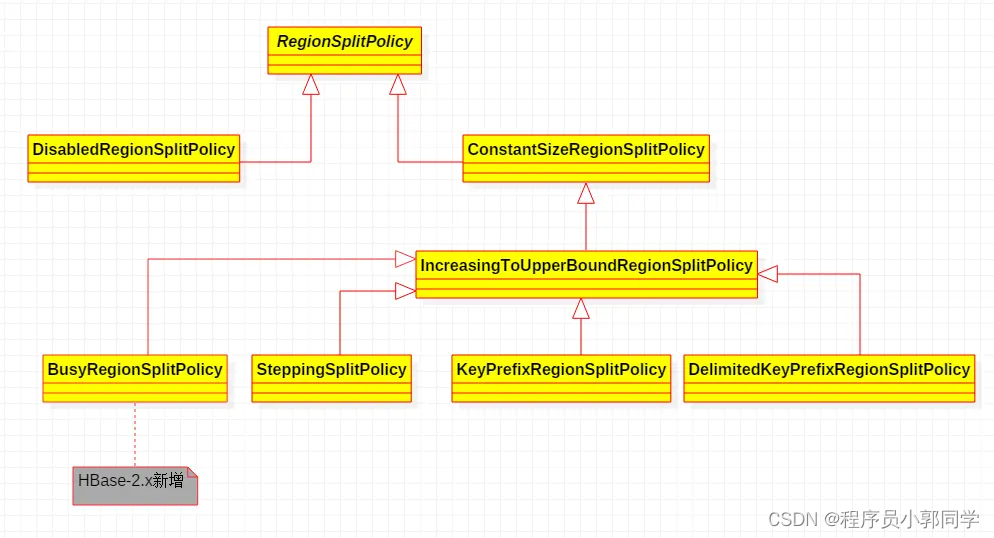
图-6 分裂策略
ConstantSizeRegionSplitPolicy
当HRegion的大小达到了hbase.hregion.max.filezie就会分裂。这种策略下,分裂产生的HRegion的大小是均匀的,即一个10G的HRegion会分裂为两个5G的HRegion。
其中,属性hbase.hregion.max.filesize默认值是10737418240,单位是字节,即10G。
IncreasingToUpperBoundRegionSplitPolicy
这种拆分策略是HBase-1.2.x中默认使用的拆分策略。这种策略的特点是:HRegion的前几次拆分的阈值不是固定的数值,而是需要经过计算得到的。
1)如果HRegion的数量超过了100,那么就按照hbase.hregion.max.filezie(即默认10G)的大小来拆分;
2)如果HRegion的数量在1~100之间,那么按照公式min(hbase.hregion.max.filezie,regionCount^3*initialSize)来计算。其中,regionCount指的是HRegion的数量,initialSize指的是HRegion的初始大小,默认情况下,值为2*hbase.hregion.memstore.flush.size(默认是134217728,单位是字节,即128M大小),initialSize的值可以通过属性hbase.increasing.policy.initial.size来指定,单位是字节。
在默认情况下,此时initialSize=2*128M=256M=0.25G:
1)如果表中只有1个HRegion,那么此时HRegion的分裂阈值为min(10G,1^3*0.25G)=0.25G;
2)如果表中有2个HRegion,那么此时HRegion的分裂阈值为min(10G,2^3*0.25G)=2G;
3)如果表中有3个HRegion,那么此时HRegion的分裂阈值为min(10G,3^3*0.25G)=6.75G;
4)如果表中有4个HRegion,那么此时HRegion的分裂阈值为min(10G,4^3*0.25G)=10G,所以从4个及以上的数量开始,HRegion的分裂阈值默认都是10G了。
KeyPrefixRegionSplitPolicy
该策略是IncreasingToUpperBoundRegionSplitPolicy的子类,在IncreasingToUpperBoundRegionSplitPolicy计算容量方式的基础上增加了对拆分点(splitPoint),即根据行键前缀来拆分。它保证了有相同前缀的rowkey不会被拆分到两个不同的Region里面。这种拆分方式,拆分出来的HRegion之间可能不是等大的。
DelimitedKeyPrefixRegionSplitPolicy
不同于KeyPrefixRegionSplitPolicy的地方在于,KeyPrefixRegionSplitPolicy在拆分的时候,会读取Rowkey固定字节个数(默认是5个字节)的前缀,而如果前缀比较灵活(例如log_001,video_001,前缀字节个数不同),那么需要使用DelimitedKeyPrefixRegionSplitPolicy,在使用的时候需要指定前缀和后续字符之间的间隔符号(例如指定_作为间隔符号)。
SteppingSplitPolicy
在HBase2.X版本中默认采用就是这种策略,计算方式为:如果当前该表中只有1个HRegion,那么按照2*hbase.hregion.memstore.flush.size(默认128M)分裂,否则按照hbase.hregion.max.filezie(默认是10G)分裂。即表中如果只有1个HRegion,当这个HRegion的大小达到2*128M=256M的时候,会进行分裂;如果表中的HRegion的数量超过1个,那么HRegion的大小需要达到10G才会分裂为两个5G的HRegion。
BusyRegionSplitPolicy
该策略是HBase2.X中提供的一套新的切分策略,目前为止,只有HBase2.X版本支持,早期的版本不支持。该策略是IncreasingToUpperBoundRegionSplitPolicy的子类,在容量计算方式的基础上,添加了热点策略。即某一些HRegion在短时间内被频繁访问,那么此时这些HRegion就是热点HRegion。判断一个HRegion是否为热点的计算方式为:
1)判断条件:当前时间-上次检测时间≥hbase.busy.policy.aggWindow。这一步的目的是为了控制计算的频率,如果条件成立,则执行下一步。
2)计算请求的被阻塞率(aggBlockedRate)。aggBlockedRate=这段时间被阻塞的请求/这段时间的总请求。
3)判断条件:如果aggBlockedRate>hbase.busy.policy.blockedRequests,且该HRegion的繁忙时间≥hbase.busy.policy.minAge,那么则判定该HRegion为热点HRegion。
其中,属性hbase.busy.policy.aggWindow的默认值是300000,单位是毫秒,即5min;属性hbase.busy.policy.blockedRequests的默认值是0.2f,即阻塞率阈值为20%;属性hbase.busy.policy.minAge的默认值是6000000,单位是毫秒,即10min,这个属性的目的是为了防止短时间内的访问频率波峰。例如,如果在1min内,某一个HRegion访问次数比较多,但是1min之后,这个HRegion就几乎没有被访问过,那么此时就不能判定该HRegion为热点HRegion。
所以,综上,可以理解为:在默认情况下,每5min监测一次HRegion,如果发现某一个HRegion接收的请求中有超过20%被阻塞,且该HRegion被频繁请求的时间已经超过了10min,那么此时就判定这个HRegion是一个热点HRegion。
DisabledRegionSplitPolicy
该策略禁止HRegion自动拆分,所以该策略极少使用。实际过程中,如果使用该策略,一般有两种场景:预拆分HRegion或者数据量较小。例如,已经预估了数据量,在建表的时候就指定该表必须立即拆分出来n个HRegion,建好表之后就不再拆分了,可以使用这种策略;或者建表的时候知道数据量很小,1个HRegion足够存放,那么也可以使用这种策略。
HBase架构
Zookeeper的作用
Zookeeper在HBase中充当了注册中心:HBase中的每一个节点启动之后,都会注册到Zookeeper上。首先,当HBase启动的时候,会在Zookeeper上注册一个节点/hbase,后续HBase启动的所有其他进程都会在/hbase下注册子节点:当Active HMaster启动的时候,会自动的在Zookeeper上注册一个/hbase/master节点;当Backup HMaster启动的时候,会自动的在Zookeeper的/hbase/backup-masters节点下来注册子节点;当HRegionServer启动之后,也会在Zookeeper的/hbase/rs节点下来注册子节点。
HMaster
HBase是一个典型的主从结构,其中主节点是HMaster。而在HBase中,不限制HMaster的个数。HBase允许用户在任意一台安装了HBase的节点上启动HMaster。启动命令为:
hbase-daemon.sh start master
因为HBase不限制HMaster的个数,因此理论上HMaster不存在单点故障。如果在HBase集群中启动了多个HMaster,那么HMaster会分为Active和Backup两种状态。为了保证数据的一致性,Active HMaster在接收到数据之后,会将数据同步给其他的Backup HMaster,同步的节点数量越多效率就会越低。因此,虽然理论上HBase不限制HMaster的个数,但是实际过程中HMaster一般不会超过3个,即1个Active HMaster+2个Backup HMaster。
Active HMaster启动之后会实时监控Zookeeper上/hbase/backup-masters下子节点的变化,以确定下一次要同步的节点是哪一个。
HMaster的作用:
1)管理HRegionServer,主要是负责HRegion在HRegionServer之间的分配和转移,即HMaster决定了将HRegion交给哪一个HRegionServer来管理。
2)记录和管理元数据。HBase中的元数据包含了namespace名、表名、列族名、表信息等数据,因此凡是会产生元数据的操作都会经过HMaster,而不产生元数据的操作不会经过HMaster。而在HBase中,DDL(Data Defination Language,数据定义语言)操作会产生元数据,DML(Data Manipulation Language,数据操纵语言)操作不会产生有元数据。
HBase架构间的读写流程
1)客户端访问Zookeeper,获取到hbase:meta表对应的HRegion由哪一个HRegionServer管理;
2)读取hbase:meta表,从中获取到要操作的数据所对应的HRegion的位置;
3)访问当前HRegion对应的HRegionServer,读写数据。
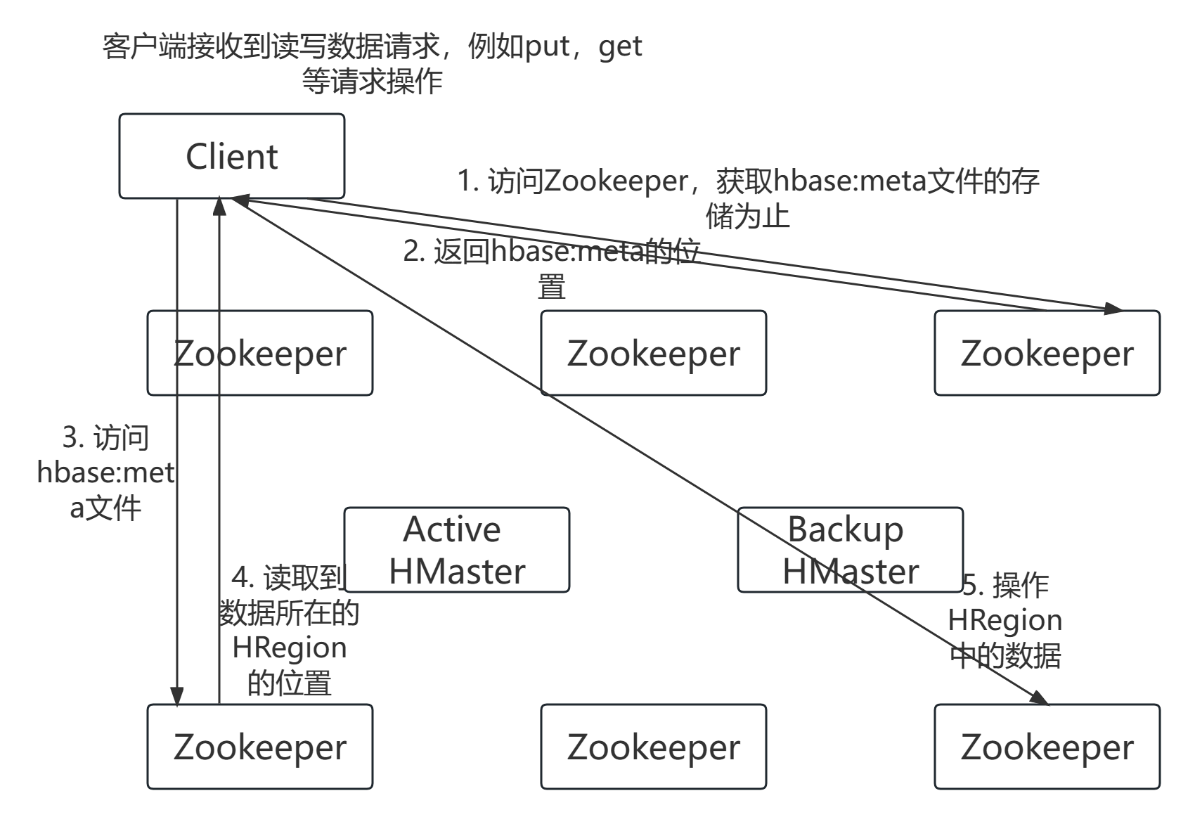
图-7 读写流程
为了提高效率,HBase在客户端设置了缓存机制:即客户端在第一个请求Zookeeper之后,会缓存hbase:meta文件的位置,那么后续客户端要读写数据的时候,可以直接去访问hbase:meta,而减少了对Zookeeper的请求。同样,客户端还会缓存每次要操作的HRegion所在的位置,下次如果还是要操作这个HRegion,那么就可以直接去招对应的HRegionServer,从而减少了访问hbase:meta文件的次数。随着运行时间的延长,客户端的缓存逐渐变多,效率也越来越高。如果发生HRegion的分裂或者转移,或者发生了缓存的崩溃(例如内存出现故障)等,那么会导致缓存失效,需要重新缓存。
HRegionServer
HRegionServer是HBase的从进程,负责管理HRegion。根据官方文档给定,每一个HRegionServer大约能够管理1000个HRegion。
每一个HRegionServer中包含了WAL、BlockCache,以及0到多个HRegion。
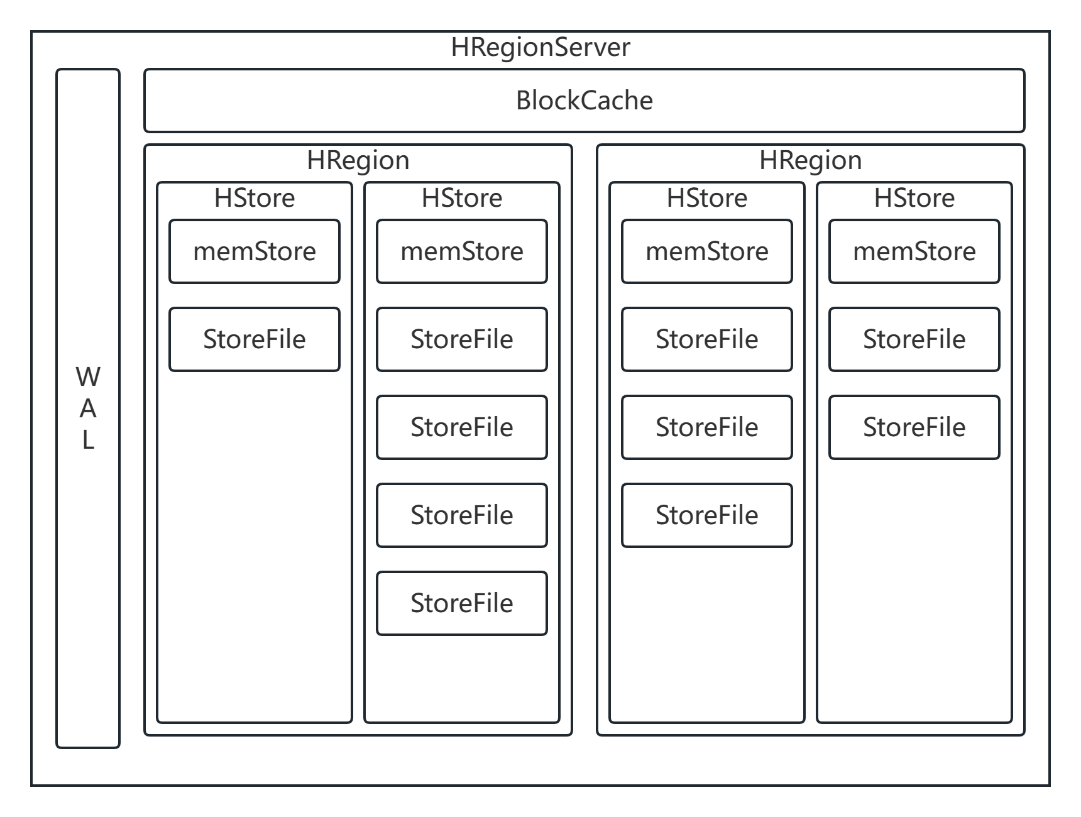
图-8 HRegionServer的结构
WAL
WAL(Write Ahead Log):发生在写之前的日志,早期版本这个文件也称之为HLog。有些类似于HDFS中的edits文件。当HRegionServer接收到写操作之后,会先将该操作记录到WAL中,然后再将数据更新到对应的HStore的memStore中。
在HBase0.94版本之前,WAL采用的是串行写机制,从HBase0.94版本开始,引入了NIO中的Channel机制,是的WAL开始运行并行写机制,从而提高了WAL的写入效率,有提高了HRegionServer的并发效率。
通过WAL机制,可以有效的保证数据不会产生丢失,但是因为WAL是落地在磁盘上的,因此一定程度上会降低写入效率。如果在实际开发中,能够允许一定程度上的数据丢失,那么可以考虑关闭WAL机制。
需要注意的是,单个WAL文件的大小是由属性hbase.regionserver.hlog.blocksize*hbase.regionserver.logroll.multiplier来决定。早期的时候,属性hbase.regionserver.hlog.blocksize默认和HDFS的Block等大,后来改成了2倍于HDFS Block的大小。同样,早期的时候,属性hbase.regionserver.logroll.multiplier默认值是0.95,现在的版本中该属性的默认值是0.5!所以在HBase2.5.5版本中,一个WAL大小是2*128M*0.5=128M。当一个WAL写满之后,就会产生一个新的WAL。随着运行时间的推移,WAL越来越多,占用的磁盘空间也越来越大,所以当WAL大小超过指定数量的时候,按照时间顺序产生的最早的WAL就会被清理掉,直到WAL的数量低于指定数量为止。早期的时候,WAL的数量由属性hbase.regionserver.max.logs决定,该属性的默认值是32。现在该属性以废弃,固定数量为32。
BlockCache
BlockCache:块缓存机制,本质上是一个读缓存,维系在内存中,通过属性hfile.block.cache.size指定大小,默认值是0.4,即占用服务器40%的内存空间。需要注意的是,如果
hbase.regionserver.global.memtstore.size+hfile.block.cache.size>0.8
即所有的memStore所占内存之和+BlockCache占用的内存>0.8,那么该HRegionServer就会报错!
当从HRegionServer中读取数据的时候,会先将数据缓存到BlockCache中,再返回给客户端,这样客户端下一次来读取的时候可以直接从BlockCache中来获取该数据而不用从HStore中来获取数据。
BlockCache在缓存的过程中还采用了局部性原理:
1)时间局部性:当一条数据被读取之后,HBase会认为这条数据被再次读取的概率要高于其他未被读取过的数据,此时HBase会将这条数据放到BlockCache中缓存。
2)空间局部性:当一条数据被读取之后,HBase会认为与这条数据相邻的数据被读取的概率要高于其他不相邻的数据,此时HBase也会将与这条数据相邻的数据放到BlockCache中。
默认情况下,BlockCache还采用了LRU(Least Recently Used,最近最少使用)策略来回收数据。除了LRUBlockCache以外,HBase还支持SlabBlockCache和BucketBlockCache。
HRegion
HRegion是HBase分布式存储和管理的基本结构。每一个HRegion中会包含1个到多个HStore,其中HStore的数据由列族的数量来决定。每一个HStore中会包含1个memStore以及0个到多个StoreFile/HFile(早期版本中称之为StoreFile,后来的版本称之为HFile,但是在实际开发中以及官方文档中,这两种说法是混着称呼的)。
memStore本质上是一个写缓存,即HRegion在接收到写操作之后,会先将数据写到memStore中。memStore维系在内存中,通过属性hbase.hregion.memstore.flush.size来调节大小,默认值是134217728,单位是字节,即128M。当达到一定条件的时候,memStore中的数据会进行冲刷(flush)操作,每次冲刷产生一个新的HFile。HFile最终会以Block形式落地到DataNode上。
memStore的冲刷条件:
1)当某一个memStore被用满之后,那么这个memStore所在的HRegion中的所有的memStore都会进行冲刷。
2)当一个HRegionServer上所有的memStore所占内存之和≥java_heapsize*hbase.regionserver.global.memtstore.size*hbase.regionsrver.global.memstore.upperLimit,那么此时会按照memStore的大小顺序(从大到小)来依次冲刷,直到所有的memStore所占内存之和≤java_heapsize*hbase.regionserver.global.memtstore.size*hbase.regionserver.global.memstore.lowerLimit为止。其中,java_heapsize表示Java堆内存的大小,属性hbase.regionserver.global.memtstore.size表示所有的memStore能够占用的内存比例,默认是0.4,属性hbase.regionsrver.global.memstore.upperLimit表示的上限,默认是0.95,属性hbase.regionserver.global.memstore.lowerLimit表示的下限,默认值为none,即不设置下限。所以,只要所有的memStore之和<0.95,那么就会停止冲刷。
3)如果WAL的数量达到了hbase.regionserver.max.logs,那么会将按照HRegion的时间顺序来依次冲刷,直到WAL的数量低于指定值。属性hbase.regionserver.max.logs默认值为32,在HBase2.X中已经废弃,现在默认WAL的最大数量就是32。
4)当距离上一次冲刷达到指定时间间隔(通过属性hbase.regionserver.optionalcacheflushinterval来指定,默认值是3600000,单位是毫秒,即1个小时)之后,也会自动冲刷,产生一个HFile。
Compaction
当达到指定条件的时候,memStore就会冲刷产生HFile。随着运行时间的推移,就会产生越来越多的HFile,那么此时会面临着两个问题:
1)由于memStore的冲刷条件所致,例如一个memStore用满,所有memStore都要跟着冲刷,那么就会导致在HDFS上产生大量的小文件;
2)随着运行时间的推移,HBase中的数据也会越来越多,其中一些被删除的数据和历史数据依然存储在HDFS上,占用了大量的存储空间。
因此,HBase提供了Compaction机制来规约StoreFile,通过合并(merge)的方式来减少StoreFile的数量,以此来提高读取的效率。
在HBase中,Compaction机制分为两种:minor compaction和major compaction。
minor compaction是将一些小的、相邻的HFile合并成一个较大的HFile,且在合并过程中不会舍弃数据。所以合并完成之后,每一个HStore中依然可能存在几个较大的HFile。
major compaction是将这个HStore中的所有的HFile合并成一个大的File,合并过程中会舍弃掉被标记为删除的或者过时的数据。合并完成之后,每一个HStore中只存在1个HFile。
相对而言,major compaction需要合并大量的数据,所以需要进行大量的读写操作,同事需要耗费大量的资源,所以major compaction一般是放在相对空闲的时间进行,例如周日的凌晨。
HBase默认使用的Compaction机制是minor compaction。
HRegionServer的读写流程
写流程
当HRegionServer接收到写操作的时候,会先将这个写操作记录到WAL中,记录成功之后会将数据更新到memStore中。数据在memStore中会进行排序,按照行键字典序->列族字典序->列字典序->时间戳倒序的顺序排序。当达到冲刷条件之后,memStore中的数据会进行冲刷产生HFile。HFile最终会以Block的形式落地到DataNode上。注意,因为memStore中的数据是有序的,因此冲刷出来的HFile中的数据也是有序的。HFile的v1格式如下:

图-9 HFile结构
会发现,每一个HFile中,包含了6块结构:DataBlock,MetaBlock,FileInfo,DataIndex,MetaIndex以及Trailer。其中:
1)DataBlock表示数据块,用于记录数据;
2)MetaBlock表示元数据块。用于记录元数据;
3)FileInfo为文件信息,用于描述文件的长度等信息;
4)DataIndex是数据索引。记录DataBlock的索引位置;
5)MetaIndex是元数据索引。记录MetaBlock的索引位置;
6)Trailer在文件末尾占用固定字节大小,记录DataIndex、MetaIndex在文件中的起始位置。
在读取HFile的时候,需要先读取文件末尾的Trailer,从Trailer中获取到DataIndex的位置,然后再从DataIndex中获取到DataBlock的位置,然后再读取DataBlock,从DataBlock中获取具体数据。
此处,再详细解析一下DataBlock。每一个HFile中会包含1个到多个DataBlock,DataBlock是HBase中数据存储的最小单位。因为HFile中的数据是有序的,因此DataBlock之间的数据是不交叉的!
DataBlock大小默认为64K,可以在建表的时候通过属性BLOCKSIZE指定。小的DataBlock利于查询,大的DataBlock利于遍历。
每一个DataBlock都是由一个Magic(魔数)以及多个KeyValue来组成的。Magic(魔数)本质上是一个随机数,用于进行数据的校验;KeyValue是存储数据的,每一条数据最终都会以键值对形式落地到HFile中。

图-10 DataBlock结构
在HFile的v2版本中,还引入了BloomFilter(布隆过滤器):
1)BloomFilter在使用的时候需要定义一个字节数组以及三个不同的哈希函数,当获取到数据x的时候,BloomFilter会先利用这三个哈希函数对这个值x进行映射,将这个值映射到数组的不同位置上去。
2)当来了一个新的值w的时候,BloomFilter同样会利用这三个哈希函数对这个值w进行映射,如果某一个哈希函数映射到的值为0,则表示这个值一定不存在。
3)需要注意的是,在BloomFilter中,如果映射到0,则表示这个值一定不存在,但是如果映射到1,则表示这个值可能存在 - BloomFilter只能判断元素没有,但是不能判断元素有。
4)随着映射的元素越来越多,会发现数组中的空闲位也会越来越少,此时BloomFilter的误判率也会越来越高,解决方案就是对数组进行扩容。
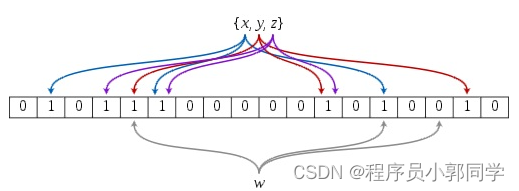
图-11 BloomFilter
读流程
当HRegionServer接收到读请求的时候,会先试图从BlockCahce中读取当前数据。如果没有从BlockCache中读取到数据,那么HRegionServer会试图从memStore中读取数据。如果也没有从memStore中获取到指定的数据,那么HRegionServer就会试图从HFile中来读取数据。在读取HFile的时候,会先根据行键范围来进行过滤,过滤掉不符合范围的HFile,然后会再次利用BloomFilter来进行过滤,被过滤掉的HFile中一定没有要找的数据,但是不代表剩余的文件中有要找的数据。
HBase的设计与优化
设计原则
行键设计原则:
1)行键在设计的时候要尽量散列,从而保证数据不会集中在一个节点上而是会散落到不同的节点上。可以对密集的行键进行哈希、随机、散列等操作。例如:
# 行键p001经过hash之后的值为:
476add61ae307328cfb24a7b4792945879aa610028d48378e4a85021e9214647
# 行键p002经过hash之后的值为:
fca5855dd15c06fe63155be37a8a782ad034198068d2ec66cf0c38f194fa5d5e
# 会发现,经过哈希之后,原来相邻的/密集的行键变得稀疏,从而可以被分配到不同的HRegion上
2)行键设计最好有意义,但是,有意义的行键容易产生相邻的问题,那么此时可以考虑对行键进行翻转,例如:
# 行键表示商品的种类及下单时间
pc20230810152014经过翻转就会编程41025101803202cp
pc20230810152015经过翻转就会编程51025101803202cp
# 会发现,此时行键的范围变化非常大,同时还保证了行键有意义
另外一种方案,是可以对行键进行前缀的随机拼接,在保证行键有意义的同时,又能保证行键的散列,例如:
# 行键表示商品的种类及下单时间
pc20230810152014,在之前产生随机字符拼接,可能是al2_ pc20230810152014
pc20230810152015,在之前产生随机字符拼接,可能是qkd_ pc20230810152015
# 在获取到行键之后只需要根据_进行切分就可以获取到原始行键了
3)行键设计要保证唯一。
列族设计原则:
1)在HBase中,虽然理论上不限制列族的数量,但是实际过程中,一个表中一般不会超过3个列族。列族数量过多,会导致查询消耗变大,同时更容易产生大量的小文件。
2)在设计列的时候,要尽量将具有相同特性的或者经常使用的列放在一个列族中,避免跨列族查询。
优化
1)调节数据块(DataBlock)的大小。每一个列族可以单独指定DataBlock的大小。这个数据块不同于之前谈到的HDFS数据块,其默认值是65536字节,即64KB大小。Data Index会存储每个HFile数据块的行键范围。数据块大小的设置影响数据块索引的大小。数据块越小,索引越多,从而会占用更大内存空间,同时加载进内存的数据块越小,随机查找性能更好。反之,如果需要更好的序列扫描性能,那么一次能够加载更多HFile数据进入内存更为合理,这意味着应该将数据块设置为更大的值。相应地,索引变小,将在随机读性能上付出更多的代价可以在表实例化时设置数据块大小:
create 'mytable', {NAME => 'colfam1', BLOCKSIZE => '65536'}
2)适当时机关闭数据块缓存。把数据放进读缓存,并不是一定能够提升性能。如果一个表或表的列族只被顺序化扫描访问或很少被访问,则Get或Scan操作花费时间长一点是可以接受的。在这种情况下,可以选择关闭列族的缓存关闭缓存的原因在于:如果只是执行很多顺序化扫描,会多次使用缓存,并且可能会滥用缓存,从而把应该放进缓存获得性能提升的数据给排挤出去,所以如果关闭缓存,不仅可以避免上述情况发生,而且可以让出更多缓存给其他表和同一表的其他列族使用。数据块缓存默认是打开的。可以在新建表或更改表时关闭数据块缓存属性:
create 'mytable', {NAME => 'colfam1', BLOCKCACHE => 'false'}
3)开启布隆过滤器。布隆过滤器(Bloom Filter)允许对存储在每个数据块的数据做一个反向测验。当查询某行时,先检查布隆过滤器,看看该行是否不在这个DataBlock。布隆过滤器要么确定回答该行不在,要么回答不知道。因此称之为反向测验。布隆过滤器也可以应用到行内的单元格(Cekll)上,当访问某列标识符时先使用同样的反向测验。使用布隆过滤器也不是没有代价,相反,存储这个额外的索引层次占用额外的空间。布隆过滤器的占用空间大小随着它们的索引对象数据的增长而增长,所以行级布隆过滤器比列标识符级布隆过滤器占用空间要少。当空间不是问题时,它们可以压榨整个系统的性能潜力。可以在列族上打开布隆过滤器:
create 'mytable', {NAME => 'colfam1', BLOOMFILTER => 'ROWCOL'}
布隆过滤器参数的默认值是NONE。另外,还有两个值:ROW和ROWCOL。其中,ROW表示行级布隆过滤器;ROWCOL表示列标识符级布隆过滤器。行级布隆过滤器在数据块中检查特定行键是否不存在,列标识符级布隆过滤器检查行和列标识符联合体是否不存在。ROWCOL布隆过滤器的空间开销高于ROW布隆过滤器。
4)开启数据压缩。HFile可以被压缩并存放在HDFS上,这有助于节省硬盘I/O,但是读写数据时压缩和解压缩会抬高CPU利用率。压缩是表定义的一部分,可以在建表或模式改变时设定。除非确定压缩不会提升系统的性能,否则推荐打开表的压缩。只有在数据不能被压缩,或者因为某些原因服务器的CPU利用率有限制要求的情况下,有可能需要关闭压缩特性
HBase可以使用多种压缩编码,包括LZO、SNAPPY和GZIP,LZO和SNAPPY是其中最流行的两种。当建表时可以在列族上打开压缩:
create 'mytable', {NAME => 'colfam1', COMPRESSION => 'SNAPPY'}
注意,数据只在硬盘上是压缩的,在内存中(MemStore或BlockCache)或在网络传输时是没有压缩的。
5)显式地指定列。当使用Scan或Get来处理大量的行时,最好确定一下所需要的列。因为服务器端处理完的结果,需要通过网络传输到客户端,而且此时,传输的数据量成为瓶颈,如果能有效地过滤部分数据,使用更精确的需求,能够很大程度上减少网络I/O的花费,否则会造成很大的资源浪费。如果在查询中指定某列或者某几列,能够有效地减少网络传输量,在一定程度上提升查询性能。
6)使用批量读。通过调用HTable.get(Get)方法可以根据一个指定的行键获取HBase表中的一行记录。同样HBase提供了另一个方法,通过调用HTable.get(List<Get>)方法可以根据一个指定的行键列表,批量获取多行记录。使用该方法可以在服务器端执行完批量查询后返回结果,降低网络传输的速度,节省网络I/O开销,对于数据实时性要求高且网络传输RTT高的场景,能带来明显的性能提升。
7)使用批量写。通过调用HTable.put(Put)方法可以将一个指定的行键记录写入HBase,同样HBase提供了另一个方法,通过调用HTable.put(List<Put>)方法可以将指定的多个行键批量写入。这样做的好处是批量执行,减少网络I/O开销。
8)关闭写WAL。在默认情况下,为了保证系统的高可用性,写WAL日志是开启状态。写WAL开启或者关闭,在一定程度上确实会对系统性能产生很大影响,根据HBase内部设计,WAL是规避数据丢失风险的一种补偿机制,如果应用可以容忍一定的数据丢失的风险,可以尝试在更新数据时,关闭写WAL。该方法存在的风险是,当RegionServer宕机时,可能写入的数据会出现丢失的情况,且无法恢复。关闭写WAL操作通过Put类中的writeToWAL(boolean)设置。可以通过在代码中添加:
put.setWriteToWAL(false);
9)设置AutoFlush。HTable有一个属性是AutoFlush,该属性用于支持客户端的批量更新。该属性默认值是true,即客户端每收到一条数据,立刻发送到服务端。如果将该属性设置为false,当客户端提交Put请求时,将该请求在客户端缓存,直到数据达到某个阈值的容量时(该容量由参数hbase.client.write.buffer决定)或执行hbase.flushcommits()时,才向RegionServer提交请求。这种方式避免了每次跟服务端交互,采用批量提交的方式,所以更高效。但是,如果还没有达到该缓存而客户端崩溃,该部分数据将由于未发送到RegionServer而丢失。这对于有些零容忍的在线服务是不可接受的。所以,设置该参数的时候要慎重。可以在代码中添加:
table.setAutoFlush(false);
table.setWriteBufferSize(12*1024*1024);
10)预创建Region。在HBase中创建表时,该表开始只有一个Region,插入该表的所有数据会保存在该Region中。随着数据量不断增加,当该Region大小达到一定阈值时,就会发生分裂(Region Splitting)操作。并且在这个表创建后相当长的一段时间内,针对该表的所有写操作总是集中在某一台或者少数几台机器上,这不仅仅造成局部磁盘和网络资源紧张,同时也是对整个集群资源的浪费。这个问题在初始化表,即批量导入原始数据的时候,特别明显。为了解决这个问题,可以使用预创建Region的方法。Hbase内部提供了RegionSplitter工具:
${HBASE_HOME}/bin/hbase org.apache.hadoop.hbase.util.RegionSplitter test2 HexStringSplit -c 10 -f cf1
其中,test2是表名,HexStringSplit表示划分的算法,参数-c 10表示预创建10个Region,-f cf1表示创建一个名字为cf1的列族。
11)调整ZooKeeper Session的有效时长。参数zookeeper.session.timeout用于定义连接ZooKeeper的Session的有效时长,这个默认值是180秒。这意味着一旦某个RegionServer宕机,HMaster至少需要180秒才能察觉到宕机,然后开始恢复。或者客户端读写过程中,如果服务端不能提供服务,客户端直到180秒后才能觉察到。在某些场景中,这样的时长可能对生产线业务来讲不能容忍,需要调整这个值。
12)内存设置。会发现,HBase在使用过程中需要非常大的内存开销(客户端缓存、BlockCache、memStore等都需要耗费内存),但是给HBase分配的内存不是越大越好,因为在GC过程中HRegionServer是处在不可用状态(暂时不对外提供读写服务),内存越大,GC需要的时间就越长,HRegionServer的不可用状态就会越长;同时HBase如果占用的内存过大,那么也会影响其他服务/框架的使用。实际过程中,一般是给HRegionServer分配16G~36G内存即可。
# hbase-env.sh文件
# 整体内存设置(HMaster和HRegionServer)
export HBASE_HEAPSIZE=1G
# 设置HMaster的内存
export HBASE_MASTER_OPTS=1G
#设置HRegionServer的内存
export HBASE_REGIONSERVER_OPTS=1G
扩展
Hive集成HBase
概述及步骤
HBase作为一个非关系型数据库,本身提供了非常强大的存储能力以及对数据的增删改查能力,但是HBase对于数据的分析能力较弱(通过help会发现,HBase中几乎没有提供针对数据进行分析的命令或者函数),因此如果需要对HBase中的数据进行处理分析,那么可以考虑使用Hive。
Hive集成HBase的步骤:
1)进入Hive的安装目录,查看是否有操作HBase的jar包:
# 进入Hive的lib目录
cd /opt/software/hive-3.1.3/lib/
# 查看是否有hbase的处理包
ls hive-hbase-handler-3.1.3.jar
2)将HBase的依赖jar包拷贝到Hive目录下:
cp /opt/software/hbase-2.5.5/lib/hbase-common-2.5.5.jar ./
cp /opt/software/hbase-2.5.5/lib/hbase-server-2.5.5.jar ./
cp /opt/software/hbase-2.5.5/lib/hbase-client-2.5.5.jar ./
cp /opt/software/hbase-2.5.5/lib/hbase-protocol-2.5.5.jar ./
cp /opt/software/hbase-2.5.5/lib/hbase-it-2.5.5.jar ./
cp /opt/software/hbase-2.5.5/lib/hbase-hadoop2-compat-2.5.5.jar ./
cp /opt/software/hbase-2.5.5/lib/hbase-hadoop-compat-2.5.5.jar ./
3)进入Hive的配置目录,修改Hive的配置文件:
# 进入目录
cd ../conf
# 编辑文件
vim hive-site.xml
在文件中添加:
<property>
<name>hive.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>
4)启动YARN:
start-yarn.sh
5)启动Hive:
hive --service metastore &
hive --service hiveserver2 &
案例
在Hive中建表,映射到HBase中:
-- 1. 在Hive中建表
create table if not exists students (
id int, -- 编号
name string, -- 姓名
age int, -- 年龄
gender string, -- 性别
grade int, -- 年级
class int -- 班级
) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties (
"hbase.columns.mapping" = ":key,basic:name,basic:age,basic:gender,info:grade,info:class"
) tblproperties (
"hbase.table.name" = "students"
);
-- 2. 在HBase中查询是否生成了对应的表
list
-- 3. 插入数据,注意,此时只能使用insert方式而不能使用load方式
insert into table students values (1, 'amy', 15, 'female', 3, 5);
-- 4. 在HBase中查询数据是否写入
scan 'studetns'
在Hive中建表来管理HBase中已经存在的表:
-- 1. 在HBase中建表
create 'person', 'basic', 'info'
-- 2. 向HBase表中插入数据
put 'person', 1, 'basic:name', 'amy';
put 'person', 1, 'basic:age', 15
put 'person', 1, 'basic:gender', 'female'
put 'person', 1, 'info:height', 165.5
put 'person', 1, 'info:weight', 55.8
-- 3. 在Hive中建表,管理HBase中已经存在的表
create external table person (
id int, -- 编号
name string, -- 姓名
age int, -- 年龄
gender string, -- 性别
height double, -- 身高
weight double -- 体重
) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties ("hbase.columns.mapping" = ":key,basic:name,basic:age,basic:gender,info:height,info:weight")
tblproperties ("hbase.table.name" = "person");
-- 查询数据
select * from person;