UTF-8是目前使用最广泛的Unicode字符编码,本文顺着历史顺序讲解,来引出UTF8编码的来由和工作原理。
1. ASCII码
最开始是ASCII码,每个码位(code point)占1个字节,使用128个码位定义128个字符,每个字节的最高位是0
如果是英文环境,这个编码很理想,但是如果是其它语系环境,ASCII码就不行了,所以推出了Unicode编码。
2. UTF-32
UTF是Unicode Transformation Formats的缩写,32意思是每个字符使用32位来表示,即4个字节,这样就能表示很多的字符了。
但是缺点也很明显,如果是英文环境,那么每个英文字符都要占用4个字节,这样就会造成大量的浪费。
3.UTF-16
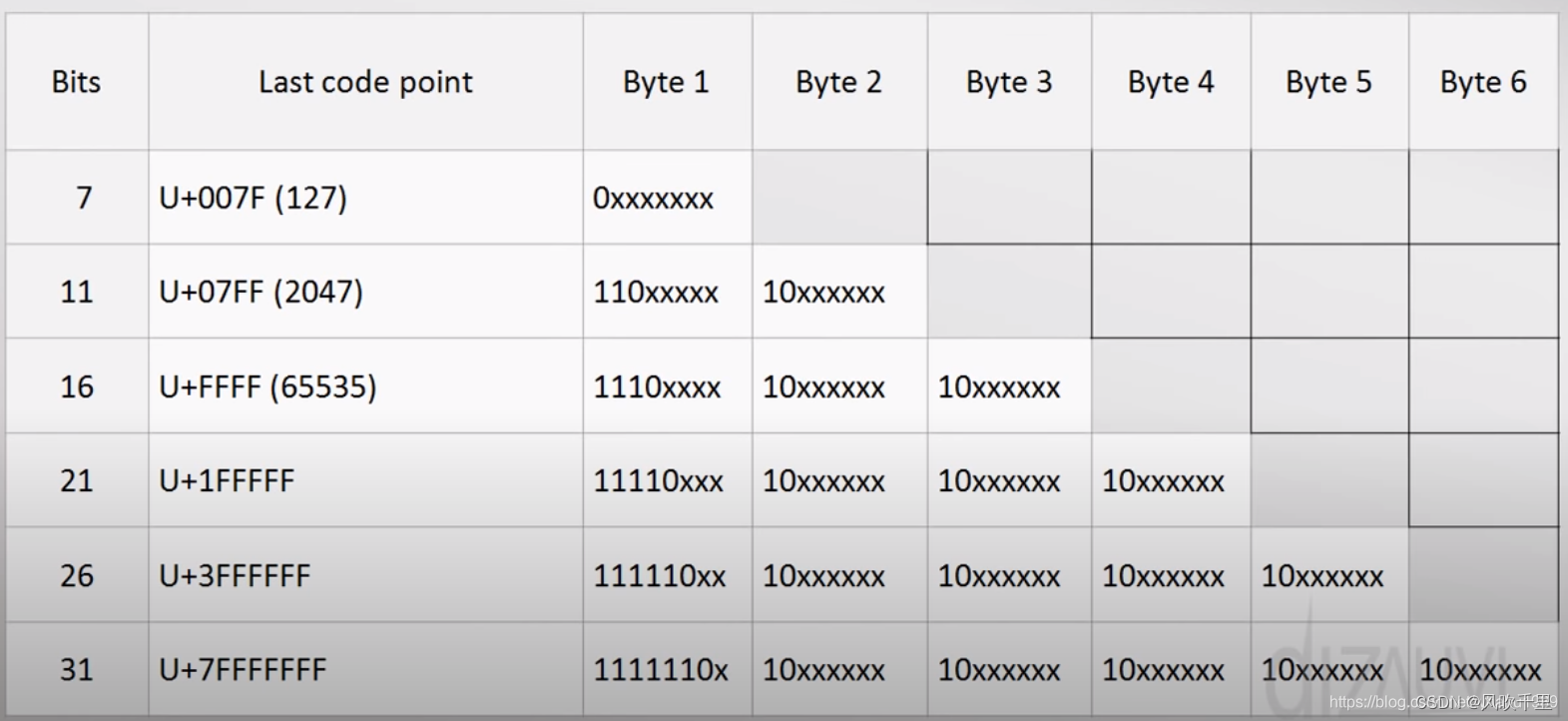
UTF16不是每个字符使用2个字节(16位)表示,而是一个字符根据其对应的码位(code point)大小,可以使用2个字节表示或者4个字节表示
4.UTF-8
UTF-8是变长的,根据字符对应的码位(code point)大小,可以是1个字节,2个字节,3个字节或4个字节。

在解码时,如何知道这个字符占用几个字节呢?通过解析第一个字节获取信息。
1个字节
如果第一个字节的最高位是0,那么表示占一个字节,如下,

可以看出UTF-8是完全兼容ASCII码的,因为ASCII码的最高位也是0
2个字节
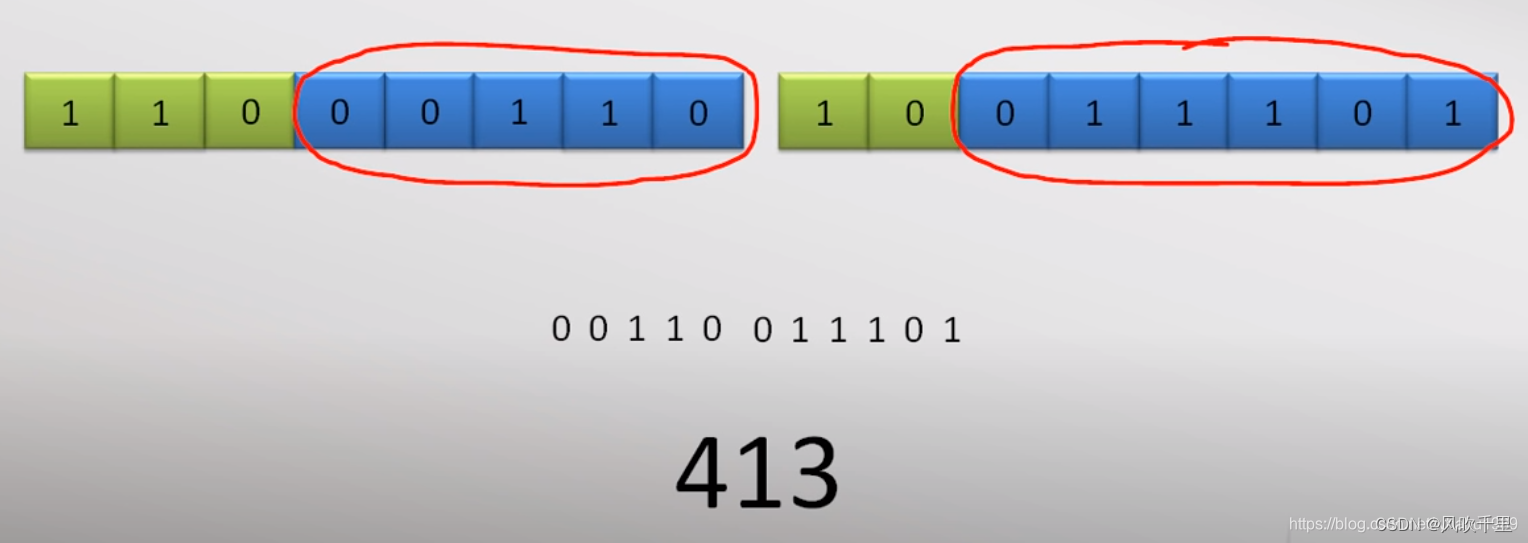
如果第一个字节(leading byte)的最高三位是110,那么表示这个字符占2个字节,第二个字节的最高2位是10
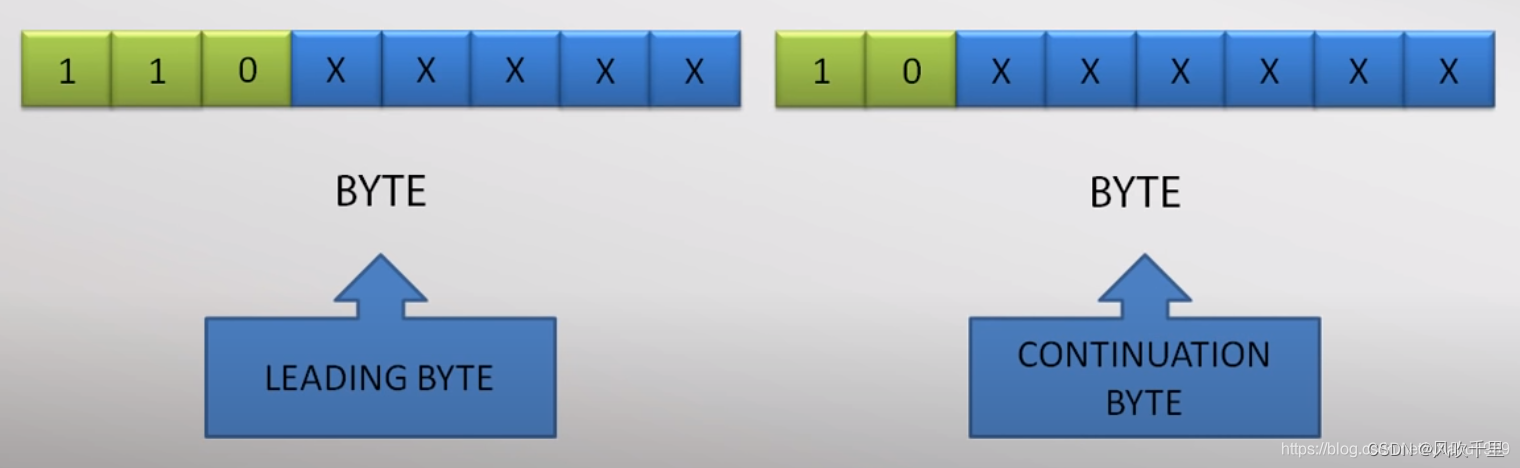
蓝色部分的数字组合在一起,就是实际的码位值。
假如要表示的字符,其码位值是413,那么就表示如下,
3个字节
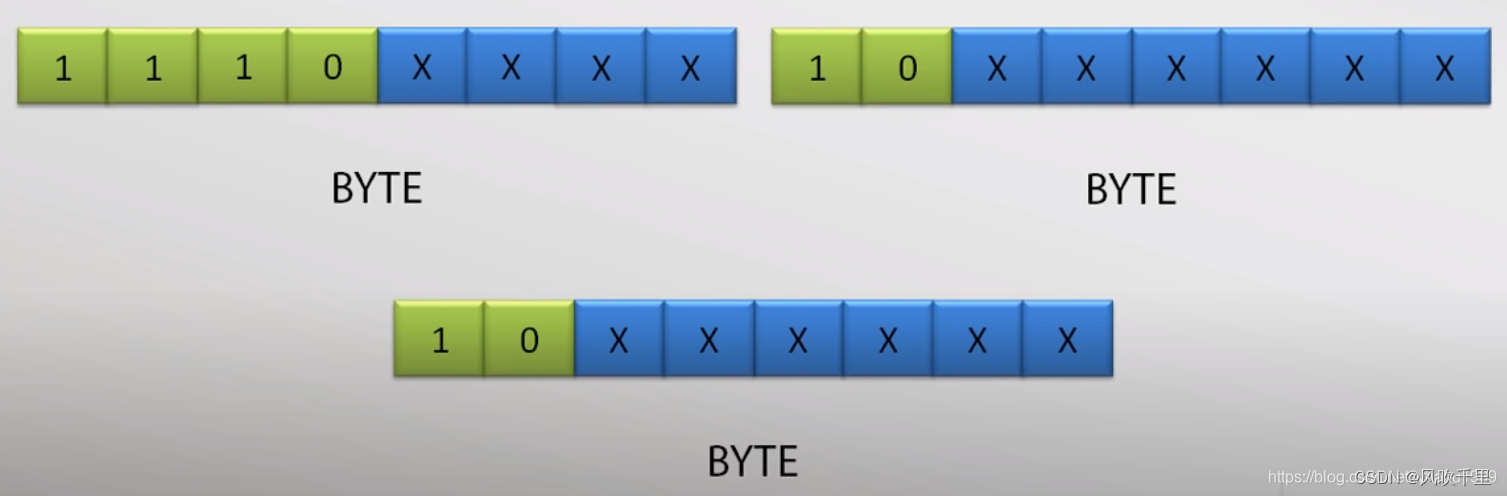
如果第一个字节(leading byte)的最高三位是1110,那么表示这个字符占3个字节,第2和第3个字节的最高2位是10
4个字节
原理同上,只是第一个字节(leading byte)的最高三位是11110

不同字节对应的码位范围如下图,左侧Bits栏表示用于表示码位的bit数,如4个字节,其中有21位用于表示码位,即上图中的蓝色部分。