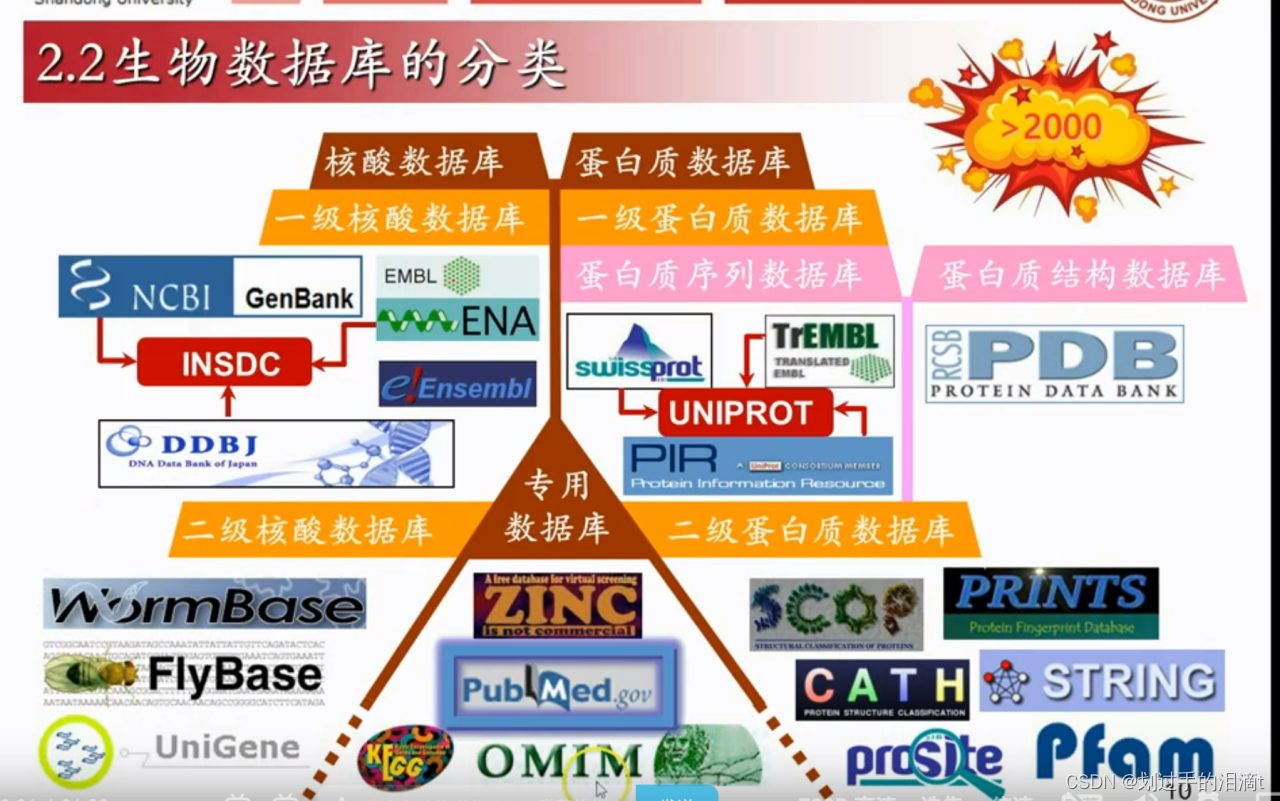
生物信息学数据库
(一)文献数据库
1、PubMed:拥有超过两百六十万生物医学文献的数据库,这些文献来源于MEDLINE,也就是生物医学文献数据库、生命科学领域学术杂志、以及在线的专业书籍。链接:PubMed (nih.gov)
PubMed存在的问题
(1)搜索1995年前文献中排名是为以后的作者
(2)搜索1976年以前的文献是没有摘要的
(3)1965年前的文献较难搜索
(二)一级核酸数据库
1、※GenBank:是美国国家生物技术信息中心(National Center for Biotechnology Information ,NCBI)建立的DNA序列数据库,从公共资源中获取序列数据,主要是科研人员直接提供或来源于大规模基因组测序计划。为保证数据尽可能的完全,GeneBank与EMBL(欧洲EMBL-DNA数据库)、DDBJ(日本DNA数据库)共同构成国际核酸序列数据库合作联盟(INSDC),三大数据库的信息每日相互交换,更新汇总。链接:GenBank Overview (nih.gov)
2、ENA:ENA Browser
ENA:欧洲核苷酸序列数据库(European Nucleotide Archive),由欧洲分子生物学研究室(European Molecular Biology Laboratory,EMBL)开发并维护。
3、DDBJ:DDBJ
DDBJ是日本DNA数据库(DNA Data Bank of Japan),由日本国立遗传学研究所(National Institute of Geneics, NIG)开发并负责维护。
以上三个数据库共同组成了国际核酸序列数据库合作联盟(International Nucleotide Sequence Database Collaboration,INSDC)。即这个数据库的信息可以相互交换,同步更新,共享。INSDC:International Nucleotide Sequence Database Collaboration
(三)、二级核酸数据库
二级核酸数据库包含的内容很多,经常会用到的几个数据库有:NCBI下属的RefSeq数据库,dbEST数据库以及Gene数据库。
RefSeq数据库:参考序列数据库,是通过自动及人工精选出的非冗余数据库,包括基因组序列、转录序列和蛋白质序列。
dbEST数据库:表达序列标签数据库,包含来源于不同物种的表达序列标签(EST)
Gene数据库:为用户提供基因序列注释和检索服务,收录了来自5300多个物种的430万条基因记录
ncRNAdb:非编码RNA数据库,提供非编码RNA的序列和功能信息。包含来源于99种细菌,古细菌和真核生物的3万多条序列。
ncRNA链接: http://biobases.ibch.poznan.pl/ncRNA/
miRBase:主要存放已发表的microRNA序列和注释。可以分析microRNA在基因组中的定位和挖掘miRNA序列间的关系。
miRBase链接: http://www.mirbase.org/
(四)一级蛋白质序列数据库
1、UniPort数据库,链接:UniProt
①swissprot:人工注释,注释可信度高、冗余度小
②TrEMBL:计算机注释,包含为蛋白质编码的核酸序列的所有翻译产物
③PIR:支持基因组学、蛋白质组学和系统生物学研究的综合公共生物信息学资源
④UniParc:收录所有UniPort数据库子库中的蛋白质序列,量大,粗糙
⑤UniRef:归纳UniPort几个主要数据库并将重复序列去除后的数据库
⑥UniProtKB:有详细注释并与其他数据库有链接的数据库
(五)一级蛋白质结构数据库
1、PDB:蛋白质结构数据库(PDB)是全世界唯一存储生物大分子3D结构的数据库。这些生物大分子除了蛋白质以外还包括核酸及两者的复合物。只有通过实验方法获得的3D结构才会被收入其中。链接:RCSB PDB: Homepage
(六)二级蛋白质数据库
1、Pfam数据库:Pfam数据库是一个蛋白质结构域家族的集合,包括了一万六千多个蛋白质家族
2、CATH:结构分类数据库CATH,根据结构域的空间特征可以对结构域进行分类。数据库中四种结构分类层次分别是:蛋白质种类(class,C)、蛋白质二级结构的构架(architecture,A)、蛋白质的拓扑结构(topology,T)、蛋白质同源超家族(homologous superfamily,H)
3、SCOP2:结构分类数据库,该数据库详细描述了已知结构的蛋白质在结构、进化事件与功能类型三个方面的关系。SCOP2把SCOP中仅基于蛋白质结构的树状等级分类系统发展成为单向非循环网状分类系统
(七)专项数据库
1、KEGG:京都基因与基因组百科全书(KEGG),是关于基因、蛋白质、生化反应及通路的综合生物信息数据库,由多个子库构成
2、OMIM:人类孟德尔遗传在线(OMIM),是一个有关人类遗传病的数据库,它将遗传病分类并链接到相关人类基因组中的数据库


![[C++初阶]初识C++(一)—————命名空间和缺省函数](https://img-blog.csdnimg.cn/direct/0885298cb0c64fcfaf9046f95acc820e.png)
![蓝桥杯(4):python动态规划DF[1]](https://img-blog.csdnimg.cn/direct/0c6768dd0acd471daa755f1852ddd22b.png)