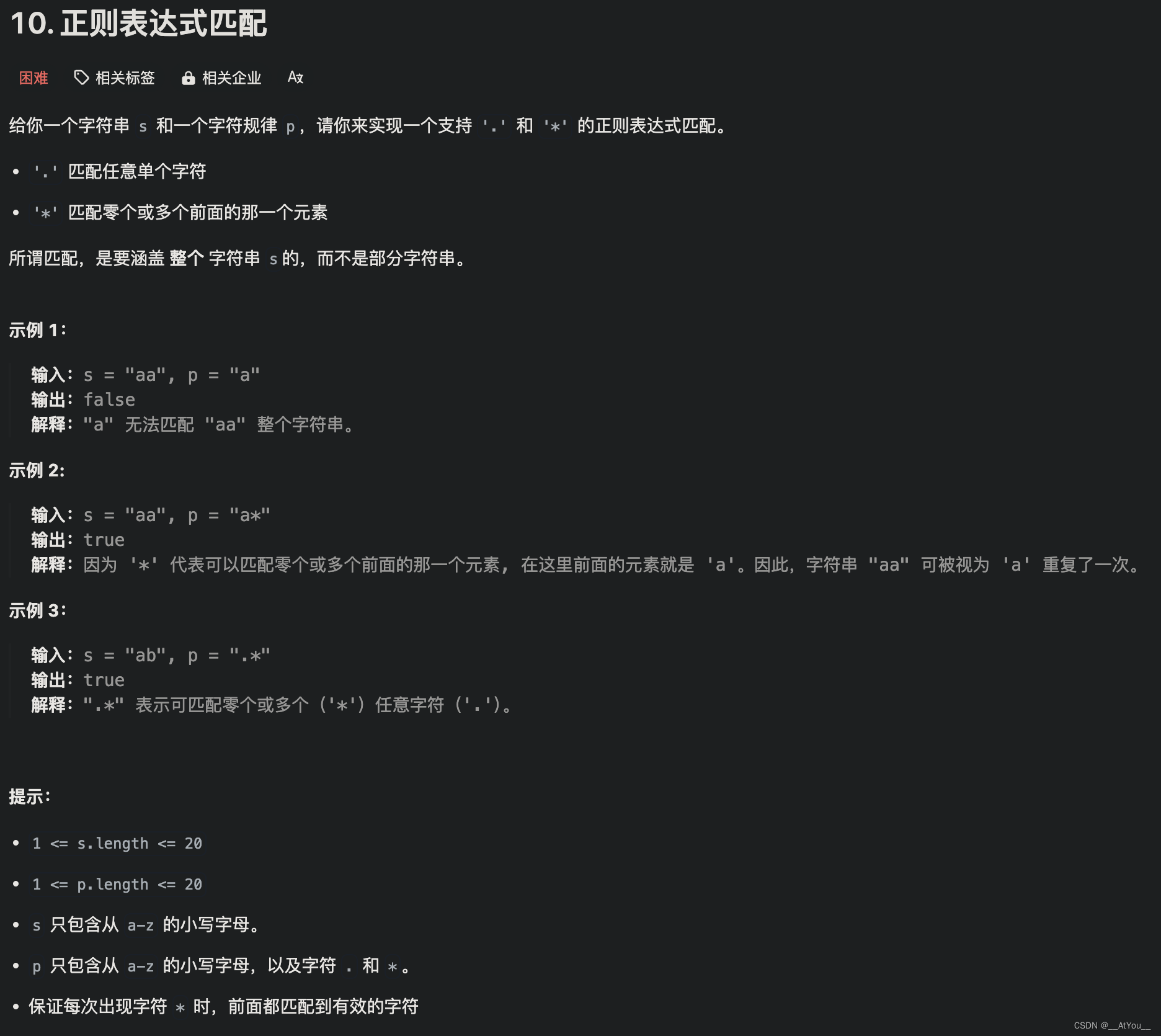
概述
本文[1]介绍了Seurat 5.0.0中的加权最近邻(WNN)分析方法,这是一种用于整合和分析多模态单细胞数据的无监督框架。
简介
多模态分析作为单细胞基因组学的一个新兴领域,它通过同时测量多种数据类型来精确描绘细胞状态,这要求开发新的计算技术。由于每种测量方式所含信息量的差异,即便是在同一组数据中的不同细胞间,也给多模态数据的分析与整合带来了挑战。在2021年发表于《Cell》杂志的一篇论文中,提出了一种名为‘加权最近邻’(WNN)的分析方法,这是一种无需监督的学习框架,它能够评估每种数据类型对每个细胞的具体贡献,从而实现对多种数据类型的综合分析。
本文介绍了WNN分析流程,它分为三个主要步骤:
-
首先,对每种数据类型进行独立的预处理和降维; -
其次,学习每种数据类型对于不同细胞的重要性,并构建一个综合这些数据类型的WNN图; -
最后,对WNN图进行深入分析,如可视化展示、细胞聚类等。
通过CITE-seq和10x multiome两种单细胞多模态技术,展示了WNN分析的应用。不再仅仅依据单一数据类型来定义细胞状态,而是综合两种数据类型的信息来进行定义。
CITE-seq、RNA + ADT 的 WNN 分析
利用了 Stuart 和 Butler 等人在《Cell》杂志 2019 年发表的研究中的 CITE-seq 数据集,这个数据集由 30,672 个来自骨髓的单细胞 RNA 测序样本和 25 种抗体数据组成。分析的数据包括 RNA 和抗体衍生标签(ADT)两种类型。
为了重现这个分析,需要先安装 SeuratData 包,该包可以在 GitHub 上找到。
library(Seurat)
library(SeuratData)
library(cowplot)
library(dplyr)
InstallData("bmcite")
bm <- LoadData(ds = "bmcite")
在对单细胞数据进行分析的过程中,首先独立地对两种不同的检测方法进行了预处理和降维处理。虽然采用了传统的标准化技术,但也可以根据需要选择使用 SCTransform 或其他替代技术。
DefaultAssay(bm) <- 'RNA'
bm <- NormalizeData(bm) %>% FindVariableFeatures() %>% ScaleData() %>% RunPCA()
DefaultAssay(bm) <- 'ADT'
# we will use all ADT features for dimensional reduction
# we set a dimensional reduction name to avoid overwriting the
VariableFeatures(bm) <- rownames(bm[["ADT"]])
bm <- NormalizeData(bm, normalization.method = 'CLR', margin = 2) %>%
ScaleData() %>% RunPCA(reduction.name = 'apca')
通过综合考量 RNA 和蛋白质数据的相似性,为每个细胞确定了它们在数据集中的最近邻细胞。这一过程中,为每个细胞分配了特定的模态权重,并识别了它们的多模态邻居。这一计算过程是通过一个函数完成的,对于当前的数据集来说,大约需要两分钟。还对每种模态的维度进行了设定,这类似于在单细胞 RNA 测序聚类中确定要包含的主成分数量。通过调整这些参数,可以发现细微的变化对最终的分析结果影响不大。
# Identify multimodal neighbors. These will be stored in the neighbors slot,
# and can be accessed using bm[['weighted.nn']]
# The WNN graph can be accessed at bm[["wknn"]],
# and the SNN graph used for clustering at bm[["wsnn"]]
# Cell-specific modality weights can be accessed at bm$RNA.weight
bm <- FindMultiModalNeighbors(
bm, reduction.list = list("pca", "apca"),
dims.list = list(1:30, 1:18), modality.weight.name = "RNA.weight"
)
利用这些结果,可以进行后续的分析工作,包括数据的可视化和聚类。例如,能够根据 RNA 和蛋白质数据的加权组合,生成 UMAP 图来直观展示数据。此外,还可以基于图结构进行聚类分析,并将聚类结果与细胞注释一起在 UMAP 图上展示,以便于更深入地理解细胞间的关系。
bm <- RunUMAP(bm, nn.name = "weighted.nn", reduction.name = "wnn.umap", reduction.key = "wnnUMAP_")
bm <- FindClusters(bm, graph.name = "wsnn", algorithm = 3, resolution = 2, verbose = FALSE)
p1 <- DimPlot(bm, reduction = 'wnn.umap', label = TRUE, repel = TRUE, label.size = 2.5) + NoLegend()
p2 <- DimPlot(bm, reduction = 'wnn.umap', group.by = 'celltype.l2', label = TRUE, repel = TRUE, label.size = 2.5) + NoLegend()
p1 + p2

还可以尝试仅使用 RNA 和蛋白质数据来生成 UMAP 可视化,并与之前的分析结果进行比较。发现,在识别祖细胞状态方面,RNA 分析比 ADT 分析提供了更多的信息(ADT 面板包含了用于识别分化细胞的标记)。而在识别 T 细胞状态方面,情况则正好相反,ADT 分析的表现超过了 RNA 分析。
bm <- RunUMAP(bm, reduction = 'pca', dims = 1:30, assay = 'RNA',
reduction.name = 'rna.umap', reduction.key = 'rnaUMAP_')
bm <- RunUMAP(bm, reduction = 'apca', dims = 1:18, assay = 'ADT',
reduction.name = 'adt.umap', reduction.key = 'adtUMAP_')
p3 <- DimPlot(bm, reduction = 'rna.umap', group.by = 'celltype.l2', label = TRUE,
repel = TRUE, label.size = 2.5) + NoLegend()
p4 <- DimPlot(bm, reduction = 'adt.umap', group.by = 'celltype.l2', label = TRUE,
repel = TRUE, label.size = 2.5) + NoLegend()
p3 + p4

此外,可以在多模态 UMAP 上展示标准标记基因和蛋白质的表达情况,这有助于验证已有的细胞注释是否准确。
p5 <- FeaturePlot(bm, features = c("adt_CD45RA","adt_CD16","adt_CD161"),
reduction = 'wnn.umap', max.cutoff = 2,
cols = c("lightgrey","darkgreen"), ncol = 3)
p6 <- FeaturePlot(bm, features = c("rna_TRDC","rna_MPO","rna_AVP"),
reduction = 'wnn.umap', max.cutoff = 3, ncol = 3)
p5 / p6

最终,能够直观地展示每个细胞所学习的模态权重。在这些权重中,RNA 权重最高的细胞群体通常代表祖细胞,而蛋白质权重最高的细胞群体则代表 T 细胞。这一发现与的生物学预期相吻合,因为抗体面板中并没有包含能够区分不同祖细胞群体的标记。
VlnPlot(bm, features = "RNA.weight", group.by = 'celltype.l2', sort = TRUE, pt.size = 0.1) +
NoLegend()

未完待续,欢迎关注!
Source: https://satijalab.org/seurat/articles/weighted_nearest_neighbor_analysis
本文由 mdnice 多平台发布