大数据系列 | Kafka架构分析及应用
- 1. Kafka原理分析
- 2. Kafka架构分析
- 3. Kafka的应用
- 3.1. 安装Zookeeper集群
- 3.2. 安装Kafka集群
- 3.3. 生产者和消费者使用
- 3.3.1. 生产者使用
- 3.3.1. 消费者使用
- 4. Kafka Controller控制器
1. Kafka原理分析
Kafka是一个高吞吐量、 持久性的分布式发布/订阅消息系统。 其有以下特点。
● 高吞吐量:可以满足每秒百万级别消息的生产和消费。
● 持久性:有一套完善的消息存储机制, 可以确保数据高效、 安全地持久化。
● 分布式:基于分布式架构, 安全, 稳定
Kafka 的数据是存储在磁盘中的, 为什么可以满足每秒百万级别消息的生产和消费? 主要是因为 Kafka 用到了磁盘顺序,所以其读写速度超过内存随机(往硬盘的)读写速度。
Kafka主要应用在实时数据计算领域。 利用Flume实时采集日志文件中的新增数据, 然后将其存储到Kafka中, 最后在Kafka 后对接实时计算程序。 这其实是一个典型的实时数据计算流程。
2. Kafka架构分析
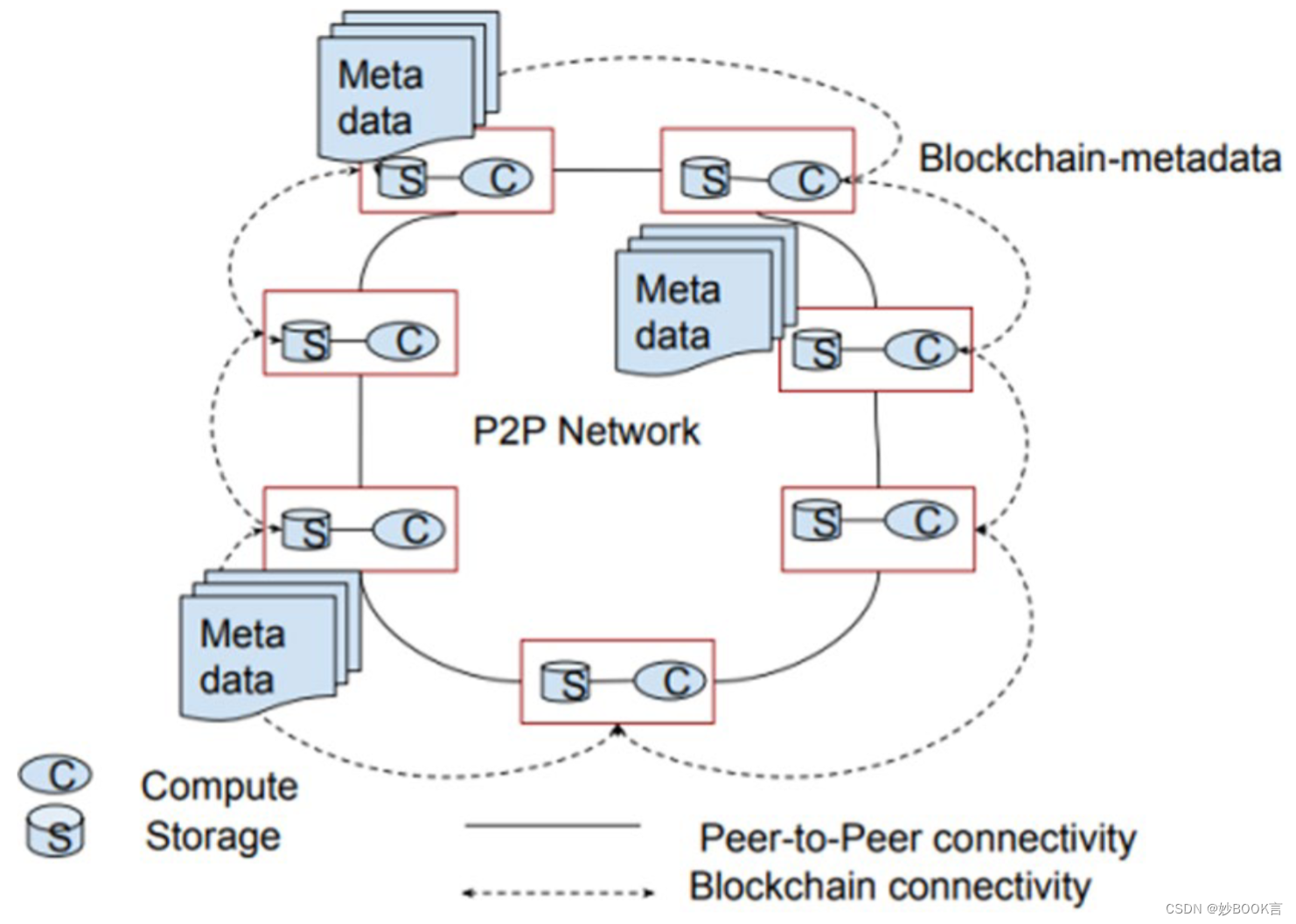
Kafka 中包含 Broker、Topic、Partition、Message、Producer和Consumer等组件
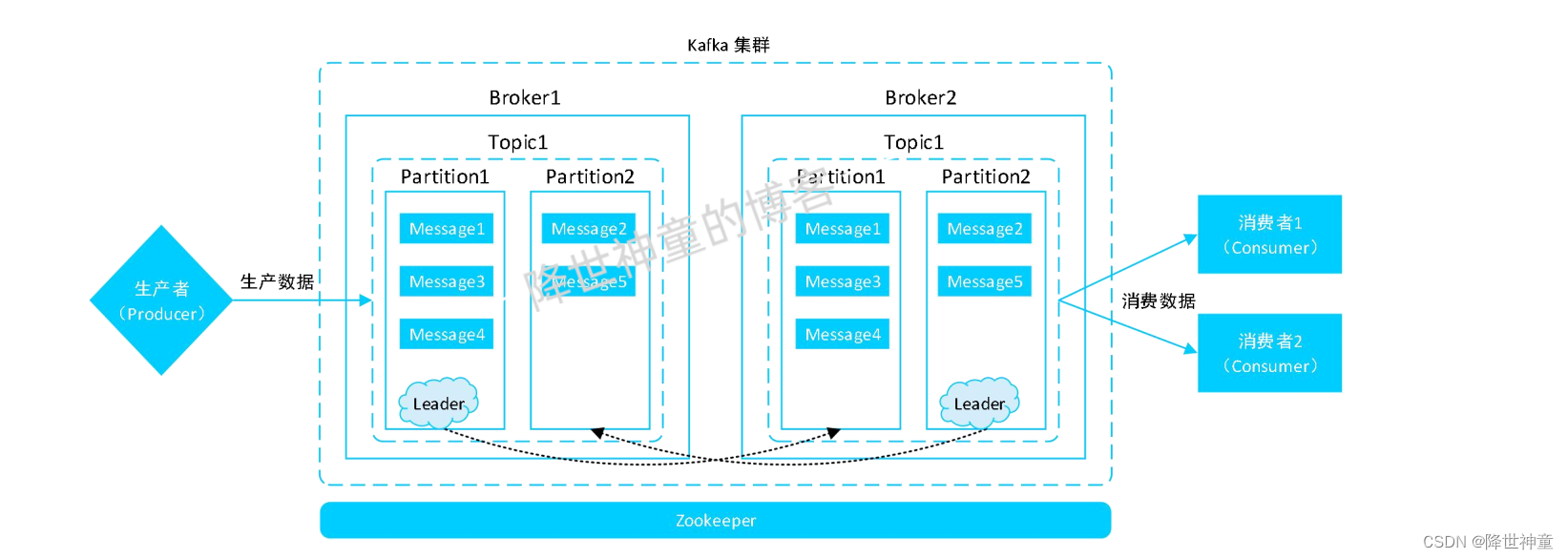
● Broker: 消息的代理。 Kafka 集群中的节点(机器) 被称为 Broker。
● Topic: 主题。 这是一个逻辑概念, 负责存储 Kafka 中的数据, 相同类型的数据一般会存储到同一个 Topic 中。 可以把 Topic 认为是数据库中的表。
● Partition: Topic 物理上的分组。 1 个 Topic 在 Broker 中被分为 1 个或者多个 Partition。分区是在创建 Topic 时指定的, 每个 Topic 都是有分区的, 至少 1 个。 Kafka 中的数据实际上存储在 Partition 中。
● Message: 消息, 是数据通信的基本单位。 每个消息都属于 1 个 Partition。
● Producer: 消息和数据的生产者, 向 Kafka 的 Topic 生产数据。
● Consumer: 消息和数据的消费者, 从 Kafka 的 Topic 消费数据。
Zookeeper 并不属于 Kafka 的组件, 但是 Kafka 可以根据需求选择依赖 Zookeeper。自Kafka 2.8版本开始,它“抛弃”了Zookeeper,引入了KIP-500架构升级,使用Raft协议实现去中心化。在新的架构中,每个Controller节点都保存所有元数据,通过KRaft协议保证副本的一致性,从而解决了Zookeeper带来的复杂度增加、必须具备Zookeeper运维能力、Controller故障处理麻烦、分区瓶颈等问题8。因此,Kafka并不再是必须依赖Zookeeper。
3. Kafka的应用
3.1. 安装Zookeeper集群
官方地址:https://downloads.apache.org/zookeeper/

选择xx-bin.tar.gz结尾的软件包
root@Agent1:~# cat /etc/hosts
127.0.0.1 localhost
127.0.1.1 zabbix-server# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters192.168.77.252 Agent1
192.168.77.253 Agent2
192.168.77.254 Agent3
zookeeper1安装:
root@Agent1:~# tar xf /opt/apache-zookeeper-3.8.4-bin.tar.gz -C /root
root@Agent1:~# cd apache-zookeeper-3.8.4-bin/conf/
root@Agent1:~/apache-zookeeper-3.8.4-bin/conf# cp zoo_sample.cfg zoo.cfg
修改Zookeeper的配置文件:
root@Agent1:~/apache-zookeeper-3.8.4/conf# vim zoo.cfg
dataDir=/root/apache-zookeeper-3.8.4-bin/data
server.0=Agent1:2888:3888
server.1=Agent2:2888:3888
server.2=Agent3:2888:3888
server.x,server后面的编号需要和kafka配置文件中的broker.id对应
2888表示Flower跟Leader的通信端口,简称服务端内部通信的端口,默认是2888。3888表示是选举端口,默认是3888
clientPort是客户端连接的接口,客户端连接zookeeper服务器的端口,zookeeper会监听这个端口,接收客户端的请求访问。默认是2181
在Zookeeper中创建data目录以保存 myid 文件:
root@Agent1:~/apache-zookeeper-3.8.4-bin# pwd
/root/apache-zookeeper-3.8.4-bin
root@Agent1:~/apache-zookeeper-3.8.4-bin# mkdir data
root@Agent1:~/apache-zookeeper-3.8.4-bin# echo 0 > ./data/myid
zookeeper2安装:
root@Agent2:~# tar xf /opt/apache-zookeeper-3.8.4-bin.tar.gz -C /root
root@Agent2:~# cd apache-zookeeper-3.8.4-bin/
root@Agent2:~/apache-zookeeper-3.8.4-bin# mkdir data
zookeeper3安装:
root@Agent3:~# tar xf /opt/apache-zookeeper-3.8.4-bin.tar.gz -C /root
root@Agent3:~# cd apache-zookeeper-3.8.4-bin/
root@Agent3:~/apache-zookeeper-3.8.4-bin# mkdir data
把Agent1节点上修改好配置的 Zookeeper 安装包复制到另外两台机器中:
root@Agent1:~/apache-zookeeper-3.8.4-bin# scp conf/zoo.cfg 192.168.77.253:/root/apache-zookeeper-3.8.4-bin/conf
root@Agent1:~/apache-zookeeper-3.8.4-bin# scp conf/zoo.cfg 192.168.77.254:/root/apache-zookeeper-3.8.4-bin/confroot@Agent1:~/apache-zookeeper-3.8.4-bin# scp data/myid 192.168.77.253:/root/apache-zookeeper-3.8.4-bin/data
root@Agent1:~/apache-zookeeper-3.8.4-bin# scp data/myid 192.168.77.254:/root/apache-zookeeper-3.8.4-bin/data
修改Agent2和Agent3上Zookeeper中myid文件的内容:
root@Agent2:~/apache-zookeeper-3.8.4-bin# cat data/myid
1
root@Agent3:~/apache-zookeeper-3.8.4-bin# cat data/myid
2
启动zookeeper集群:
./bin/zkServer.sh start-foreground :表示在前台启动
root@Agent1:~/apache-zookeeper-3.8.4-bin# pwd
/root/apache-zookeeper-3.8.4-binroot@Agent1:~/apache-zookeeper-3.8.4-bin# ./bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /root/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
root@Agent2:~/apache-zookeeper-3.8.4-bin# ./bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /root/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
root@Agent3:~/apache-zookeeper-3.8.4-bin# ./bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /root/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
验证Zookeeper 集群运行状态:
分别在Agent1、Agent2和Agent3上执行jps命令, 以验证是否有QuorumPeerMain进程。 如果都有则说明Zookeeper集群启动成功了, 否则需要到对应机器中Zookeeper的logs目录下查看tail -f -n 200 /root/apache-zookeeper-3.8.4-bin/logs/zookeeper*-*.out日志文件中的报错信息。
root@Agent1:~# jps
159674 Jps
159628 QuorumPeerMain
zookeeper leader角色主机会开启2888、3888、2181三个端口,其余follower节点只有3888、2181两个端口
root@Agent3:~/apache-zookeeper-3.8.4-bin# ./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /root/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leaderroot@Agent3:~/apache-zookeeper-3.8.4-bin# ss -tnlp
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 50 *:3888 *:* users:(("java",pid=177883,fd=65))
LISTEN 0 50 *:2181 *:* users:(("java",pid=177883,fd=53))
LISTEN 0 50 *:2888 *:* users:(("java",pid=177883,fd=67))
3.2. 安装Kafka集群
官方地址:https://kafka.apache.org/downloads
kafka1安装:
root@Agent1:~# tar xf /opt/kafka_2.13-3.7.0.tgz -C /root
root@Agent1:~# cd kafka_2.13-3.7.0/config/
root@Agent1:~/kafka_2.13-3.7.0/config# vim server.properties
修改Kafka的配置文件:
主要修改server.properties配置文件中的broker.id、 log.dirs和zookeeper.connect参数
broker.id=0
log.dirs=/data/kafka-logs
#zookeeper.connect=localhost:2181
zookeeper.connect=Agent1:2181,Agent2:2181,Agent2:2181root@Agent1:~# mkdir -p /data/kafka-logs
● broker.id:Kafka集群中Broker的编号, 默认是从0开始的, 所以Agent1主机中的broker.id 值为 0。
● log.dirs: Kafka 中的数据存储目录。 建议指定到存储空间比较大的磁盘中, 因为在实际工作中 Kafka 中会存储很多数据。
● zookeeper.connect: Zookeeper 集群的地址, 多个地址之间使用逗号分隔。
root@Agent1:~/kafka_2.13-3.7.0# bin/kafka-server-start.sh -daemon config/server.properties
root@Agent1:~/kafka_2.13-3.7.0# jps
160227 Jps
159628 QuorumPeerMain
160141 Kafka
同样的方式安装Agent2和Agent3主机,并修改broker.id参数的值
kafka2安装:
root@Agent2:~/kafka_2.13-3.7.0/config# vim server.properties
broker.id=1
log.dirs=/data/kafka-logs
zookeeper.connect=Agent1:2181,Agent2:2181,Agent2:2181
root@Agent2:~/kafka_2.13-3.7.0# bin/kafka-server-start.sh -daemon config/server.properties
root@Agent2:~/kafka_2.13-3.7.0# jps
154018 Kafka
153505 QuorumPeerMain
154070 Jps
kafka3安装:
root@Agent3:~/kafka_2.13-3.7.0/config# vim server.properties
broker.id=2
log.dirs=/data/kafka-logs
zookeeper.connect=Agent1:2181,Agent2:2181,Agent2:2181
root@Agent3:~/kafka_2.13-3.7.0# bin/kafka-server-start.sh -daemon config/server.properties
root@Agent3:~/kafka_2.13-3.7.0# jps
162163 Jps
162116 Kafka
161589 QuorumPeerMain
启动Kafka集群:
root@Agent1:~/kafka_2.13-3.7.0# bin/kafka-server-start.sh -daemon config/server.properties
root@Agent2:~/kafka_2.13-3.7.0# bin/kafka-server-start.sh -daemon config/server.properties
root@Agent3:~/kafka_2.13-3.7.0# bin/kafka-server-start.sh -daemon config/server.properties
验证Kafka集群的运行状态:
分别在Agent1、 Agent2和Agent3上执行jps命令验证是否有Kafka进程, 如果都有则说明Kafka集群启动成功了, 否则需要到对应的机器上查看 Kafka 的日志信息
root@Agent1:~/kafka_2.13-3.7.0# jps
924314 Jps
507311 QuorumPeerMain
160799 Kafka
169837 Application
3.3. 生产者和消费者使用
3.3.1. 生产者使用
创建Topic:
在安装好Kafka集群之后, 还需要先在Kafka中创建Topic, 之后就可以基于 Kafka 生产和消费数据了。
root@Agent3:~/kafka_2.13-3.7.0# bin/kafka-topics.sh --create --topic hello --partitions 5 --replication-factor 2 --bootstrap-server localhost:9092
Created topic hello.
● --create: 创建 Topic。
● --zookeeper: 指定Kafka集群使用的Zookeeper集群地址, 指定1个或者多个都可以, 多个用逗号分隔。
● --partitions: 指定Topic中的分区数量。
● --replication-factor: 指定Topic中分区的副本因子, 这个参数的值需要小于或等于Kafka集群中Broker的数量。
● --topic: 指定Topic的名称
root@Agent3:~/kafka_2.13-3.7.0# bin/kafka-topics.sh --describe --topic hello --bootstrap-server localhost:9092
Topic: hello TopicId: wvzIUg03RN6FMc9iA4-QNw PartitionCount: 5 ReplicationFactor: 2 Configs:Topic: hello Partition: 0 Leader: 0 Replicas: 0,1 Isr: 0,1Topic: hello Partition: 1 Leader: 2 Replicas: 2,0 Isr: 2,0Topic: hello Partition: 2 Leader: 1 Replicas: 1,2 Isr: 1,2Topic: hello Partition: 3 Leader: 0 Replicas: 0,2 Isr: 0,2Topic: hello Partition: 4 Leader: 2 Replicas: 2,1 Isr: 2,1
启动基于控制台的生产者并向指定 Topic 中生产数据:
Kafka 默认提供了基于控制台的生产者 , 直接使用Kafka的bin目录下的kafka-console-producer.sh 即可, 方便测试
启动基于控制台的生产者之后, 生产测试数据: hehe
root@Agent3:~/kafka_2.13-3.7.0# bin/kafka-console-producer.sh --topic hello --bootstrap-server localhost:9092
>hehe
>
● broker-list: 指定Kafka集群的地址, 指定1个或者多个都可以, 指定多个时用逗号隔开。
● topic: 指定要生产数据的Topic名称
3.3.1. 消费者使用
kafka默认提供了基于控制台的消费者, 直接使用Kafka 的 bin目录下的kafka-consoleconsumer.sh即可, 方便测试。
root@Agent1:~# cd kafka_2.13-3.7.0/
root@Agent1:~/kafka_2.13-3.7.0# bin/kafka-console-consumer.sh --topic hello --from-beginning --bootstrap-server localhost:9092
hehe
● bootstrap-server: 指定Kafka集群的地址, 指定1个或者多个都可以, 指定多个时用逗号分隔。
● topic: 指定要消费数据的Topic名称
● --from-beginning:Kafka消费者默认是消费最新生产的数据, 如果想消费之前生产的数据, 则需要添加参数–from-beginning, 表示从头消费。
Kafka的生产者和消费者也可以使用Java代码来实现。 不过在实际工作中并不会经常这么用, 因为和 Kafka 经常对接使用的技术框架(例如 Flume) 已经内置了对应的消费者和生产者代码, 在使用时只需要进行简单的配置即可。
kafka和zookeeper对接成功之后,可以在zookeeper中查看kafka的信息:
[zk: localhost:2181(CONNECTED) 5] ls /brokers
[ids, seqid, topics][zk: localhost:2181(CONNECTED) 1] ls /brokers/ids
[0, 1, 2][zk: localhost:2181(CONNECTED) 2] get /brokers/ids/0
{"features":{},"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://Agent1:9092"],"jmx_port":-1,"port":9092,"host":"Agent1","version":5,"timestamp":"1711374513109"}
4. Kafka Controller控制器
kafka控制器的作用是在Zookeeper的帮助下管理和协调整个Kafka集群,任意一台Broker可以成为Controller,但是只有一台会Controller
leader和控制器可以不是同一台机器。ZooKeeper集群中会有一个选举过程来决定哪台服务器作为Leader,这个选举是基于ZooKeeper的内部机制进行的。一旦选举完成,Leader就负责处理所有的客户端请求,并确保集群中的其他服务器(被称为Follower)与它保持同步。
控制器负责维护集群的元数据信息,处理客户端的创建、删除节点等操作,并将这些操作同步到其他服务器上。因此,控制器和Leader虽然有所区别,但在实践中,控制器通常是Leader,因为Leader负责处理所有客户端请求。但理论上,它们可以在不同的服务器上。
控制器的选取:
Broker启动时,会尝试创建ZK中 /controller znode,第一个创建/controller的Broker会是Controller
[zk: localhost:2181(CONNECTED) 2] get /controller
{"version":2,"brokerid":1,"timestamp":"1711374505881","kraftControllerEpoch":-1}
控制器的功能:
● topic管理:当使用kafka-topics脚本时,后台工作通过 controller 完成
● 分区重分配:对已有 topic 分区进行细粒度的分配
● Preferred Leader 选举:Kafka为了避免部分Broker负载过重而提供的一种换Leader的方案
● 集群成员管理(新增 Broker、Broker 主动关闭、Broker 宕机):自动检测 Broker、controller 通过 watch 机制检查 ZK 的 /brokers/ids 子节点数量变更
● 数据服务:controller向其他Broker提供数据服务、controller上保存了最全的集群元数据
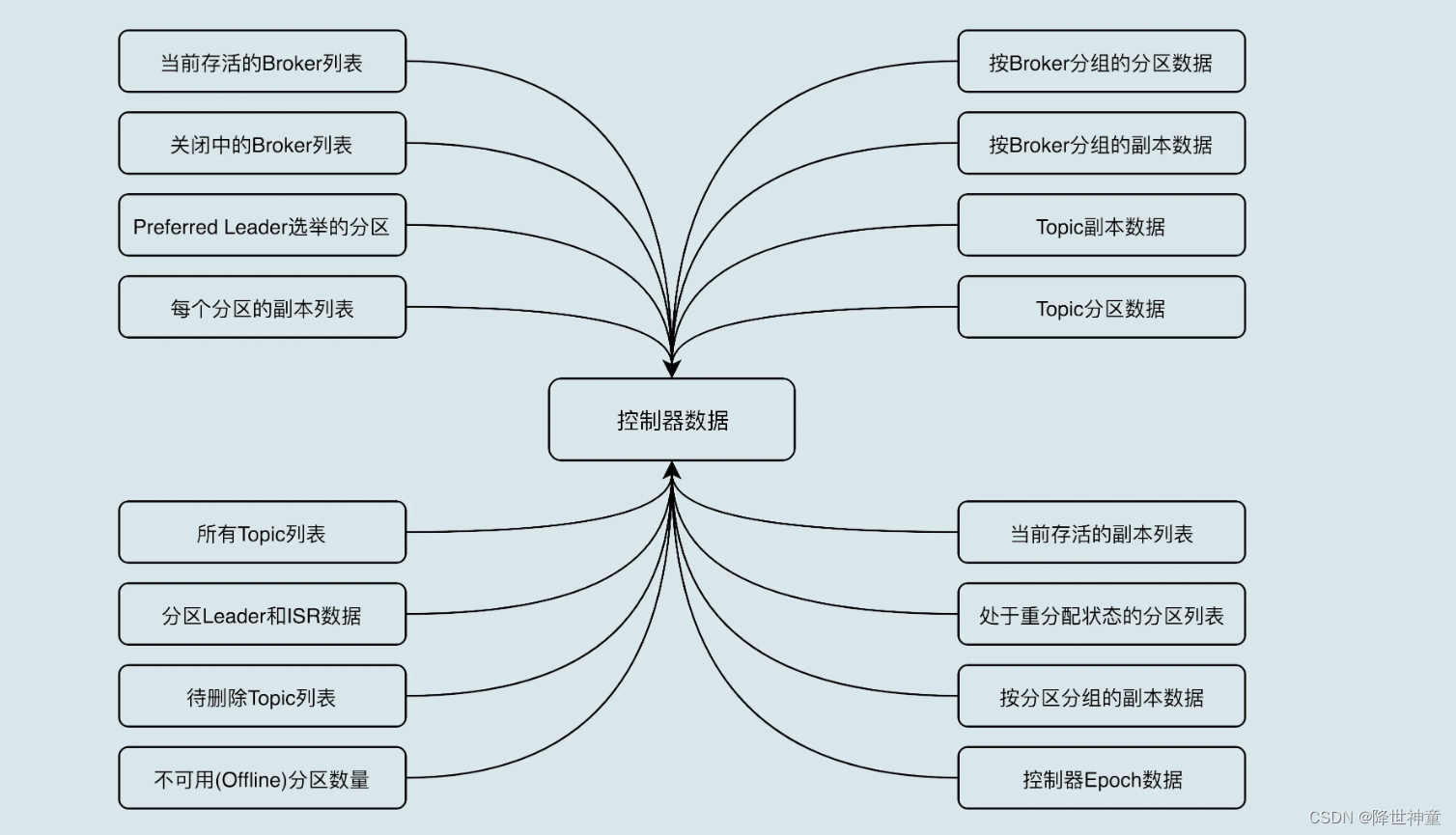
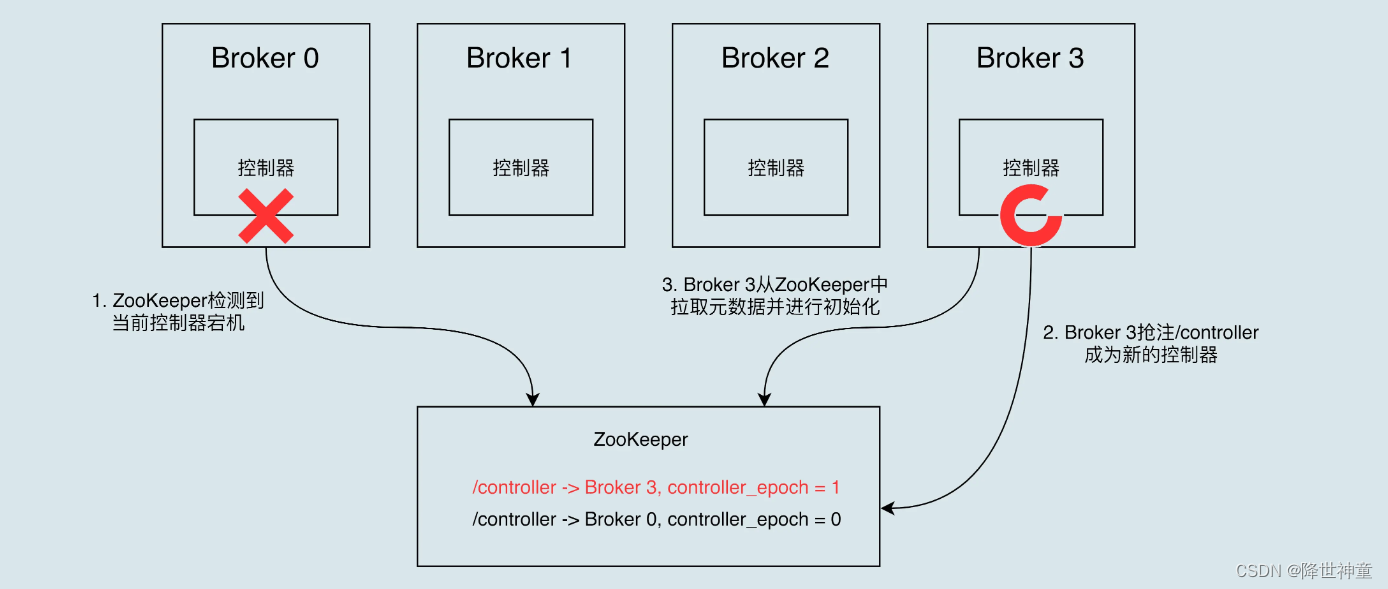
控制器故障转移Failover:
Controller存在单点
故障转移:当运行中的Controller突然宕机,Kafka能够快速感知,并立即启用备用Controller代替之前失败的Controller,这个过程称为 Failover