有状态任务是指执行期间需要维护一定状态或数据的任务或工作。这些任务通常需要记录并维护数据、状态、上下文或进度信息,并且这些信息在任务执行期间保持持久。有状态任务的解决目标是确保任务在不同的环境、节点或时间点之间维持一致的状态和标识。这种任务通常需要持久性存储、唯一标识和有序性,以确保数据的可用性和完整性。
Operator 和 StatefulSet 是 Kubernetes 中两个不同的概念,它们都用于管理容器化应用程序,但在用途和功能上有一些不同。
- Operator:
-
Operator 是一种自定义控制器,它是 Kubernetes 中的一个自动化扩展机制,用于管理和维护自定义资源(Custom Resource,CR)。 - 通过创建自定义资源定义(Custom Resource Definitions,CRD),定义自己的应用程序、服务或资源的规范和状态。
-
Operator 通过监视这些自定义资源的状态,并根据需要采取操作来确保资源处于所需的状态。 - 通常用于管理复杂的应用程序或有状态的服务,例如数据库、消息队列等,以确保它们的高可用性、扩展性和自愈能力。
- StatefulSet:
-
StatefulSet 是 Kubernetes 中的一个控制器,用于管理有状态应用程序的部署。 - 有状态应用程序是那些需要持久性标识(如网络标识、存储标识)的应用程序,例如数据库服务器。
-
StatefulSet 可以确保有状态应用程序的稳定标识(如 Pod 名称和网络标识)以及适当的部署和扩展顺序。 - 通常用于创建具有唯一标识的 Pod,这些标识在 Pod 重启或调度到不同节点时保持不变,以维护应用程序的稳定性。
Operator 是一种自定义控制器,用于管理自定义资源,它可以处理更广泛的自动化任务。而 StatefulSet 是一个专门用于管理有状态应用程序的控制器,它主要关注于维护应用程序的稳定性和标识。
1.StatefulSet
Kubernetes在1.9版本中正式发布的StatefulSet控制器能支持:
- Pod会被顺序部署和顺序终结:StatefulSet中的各个 Pod会被顺序地创建出来,每个Pod都有一个唯一的ID,在创建后续 Pod 之前,首先要等前面的 Pod 运行成功并进入到就绪状态。删除会销毁StatefulSet 中的每个 Pod,并且按照创建顺序的反序来执行,只有在成功终结后面一个之后,才会继续下一个删除操作。
- Pod具有唯一网络名称:Pod具有唯一的名称,而且在重启后会保持不变。通过Headless服务,基于主机名,每个 Pod 都有独立的网络地址,这个网域由一个Headless 服务所控制。这样每个Pod会保持稳定的唯一的域名,使得集群就不会将重新创建出的Pod作为新成员。
- Pod能有稳定的持久存储:StatefulSet中的每个Pod可以有其自己独立的PersistentVolumeClaim对象。即使Pod被重新调度到其它节点上以后,原有的持久磁盘也会被挂载到该Pod。
- Pod能被通过Headless服务访问到:客户端可以通过服务的域名连接到任意Pod。
StatefulSet的PVC模板
关于StatefulSet、Pod、PVC和PV之间的关系可以用下面这张图表示:

在StatefulSet的定义里可以额外添加了一个spec.volumeClaimTemplates字段。它跟 Pod模板(spec.template字段)的作用类似。
apiVersion: apps/v1
kind: StatefulSet
metadata:name: web
spec:serviceName: "nginx"replicas: 2selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:1.9.1ports:- containerPort: 80name: webvolumeMounts:- name: wwwmountPath: /usr/share/nginx/htmlvolumeClaimTemplates:- metadata:name: wwwspec:accessModes:- ReadWriteOnceresources:requests:storage: 1Gi示例-部署MySQL 集群
以在K8S中部署高可用的PostgreSQL集群为例,下面是其架构示意图:
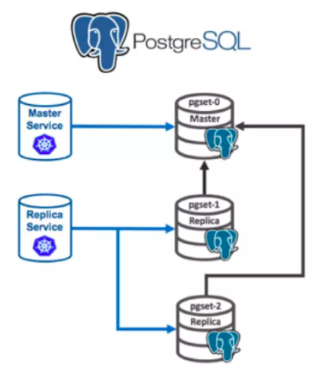
该架构中包含一个主节点和两个副本节点共3个Pod,这三个Pod在一个StatefulSet中。
Master Service是一个Headless服务,指向主Pod,用于数据写入;
Replica Service也是一个Headless服务,指向两个副本Pod,用于数据读取。
这三个Pod都有唯一名称,这样StatefulSet让用户可以用稳定、可重复的方式来部署PostgreSQL集群。StatefulSet不会创建具有重复ID的Pod,Pod之间可以通过稳定的网络地址互相通信。
使用StatefulSet部署高可用MySQL
当前命名空间为testmysql。
(1)创建ConfigMap,用于向mysql传递配置文件。
apiVersion: v1
kind: ConfigMap
metadata:name: mysqllabels:app: mysql
data:master.cnf: |#Apply this config only on the master.[mysqld]log-binslave.cnf: |#Apply this config only on slaves.[mysqld]
super-read-only(2)创建StatefulSet对象,它会负责创建Pod。
apiVersion: apps/v1
kind: StatefulSet
metadata:name: mysql
spec:selector:matchLabels:app: mysqlserviceName: mysqlreplicas: 3template:metadata:labels:app: mysqlspec:initContainers:- name: init-mysqlimage: mysql:5.7command:- bash- "-c"- |set -ex# Generate mysql server-id from pod ordinal index.[[ `hostname` =~ -([0-9]+)$ ]] || exit 1ordinal=${BASH_REMATCH[1]}echo [mysqld] > /mnt/conf.d/server-id.cnf# Add an offset to avoid reserved server-id=0 value.echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf# Copy appropriate conf.d files from config-map to emptyDir.if [[ $ordinal -eq 0 ]]; thencp /mnt/config-map/master.cnf /mnt/conf.d/elsecp /mnt/config-map/slave.cnf /mnt/conf.d/fivolumeMounts:- name: confmountPath: /mnt/conf.d- name: config-mapmountPath: /mnt/config-map- name: clone-mysqlimage: gcr.io/google-samples/xtrabackup:1.0command:- bash- "-c"- |set -ex# Skip the clone if data already exists.[[ -d /var/lib/mysql/mysql ]] && exit 0# Skip the clone on master (ordinal index 0).[[ `hostname` =~ -([0-9]+)$ ]] || exit 1ordinal=${BASH_REMATCH[1]}[[ $ordinal -eq 0 ]] && exit 0# Clone data from previous peer.ncat --recv-only mysql-$(($ordinal-1)).mysql 3307 | xbstream -x -C/var/lib/mysql# Prepare the backup.xtrabackup --prepare --target-dir=/var/lib/mysqlvolumeMounts:- name: datamountPath: /var/lib/mysqlsubPath: mysql- name: confmountPath: /etc/mysql/conf.dcontainers:- name: mysqlimage: mysql:5.7env:- name: MYSQL_ALLOW_EMPTY_PASSWORDvalue: "1"ports:- name: mysqlcontainerPort: 3306volumeMounts:- name: datamountPath: /var/lib/mysqlsubPath: mysql- name: confmountPath: /etc/mysql/conf.dresources:requests:cpu: 500mmemory: 1GilivenessProbe:exec:command: ["mysqladmin", "ping"]initialDelaySeconds: 30periodSeconds: 10timeoutSeconds: 5readinessProbe:exec:# Check we can execute queries over TCP (skip-networking is off).command: ["mysql", "-h", "127.0.0.1","-u", "root", "-e", "SELECT 1"]initialDelaySeconds: 5periodSeconds: 2timeoutSeconds: 1- name: xtrabackupimage: gcr.io/google-samples/xtrabackup:1.0ports:- name: xtrabackupcontainerPort: 3307command:- bash- "-c"- |set -excd /var/lib/mysql# Determine binlog position of cloned data, if any.if [[ -f xtrabackup_slave_info &&"x$(<xtrabackup_slave_info)" != "x" ]]; then# XtraBackup already generated a partial "CHANGE MASTER TO"query# because we're cloning from an existing slave. (Need to remove thetailing semicolon!)cat xtrabackup_slave_info | sed -E 's/;$//g' >change_master_to.sql.in# Ignore xtrabackup_binlog_info in this case (it's useless).rm -f xtrabackup_slave_info xtrabackup_binlog_infoelif [[ -f xtrabackup_binlog_info ]]; then# We're cloning directly from master. Parse binlog position.[[ `cat xtrabackup_binlog_info` =~ ^(.*?)[[:space:]]+(.*?)$ ]] || exit 1rm -f xtrabackup_binlog_info xtrabackup_slave_infoecho "CHANGE MASTER TO MASTER_LOG_FILE='${BASH_REMATCH[1]}',\MASTER_LOG_POS=${BASH_REMATCH[2]}"> change_master_to.sql.infi# Check if we need to complete a clone by starting replication.if [[ -f change_master_to.sql.in ]]; thenecho "Waiting for mysqld to be ready (accepting connections)"until mysql -h 127.0.0.1 -u root-e "SELECT 1"; do sleep 1; doneecho "Initializing replication from clone position"mysql -h 127.0.0.1 -u root \-e"$(<change_master_to.sql.in), \MASTER_HOST='mysql-0.mysql',\MASTER_USER='root', \MASTER_PASSWORD='', \MASTER_CONNECT_RETRY=10; \START SLAVE;" ||exit 1# In case of container restart, attempt this at-most-once.mv change_master_to.sql.in change_master_to.sql.origfi# Start a server to send backups when requested by peers.exec ncat --listen --keep-open --send-only --max-conns=1 3307 -c \"xtrabackup --backup --slave-info --stream=xbstream--host=127.0.0.1 --user=root"volumeMounts:- name: datamountPath: /var/lib/mysqlsubPath: mysql- name: confmountPath: /etc/mysql/conf.dresources:requests:cpu: 100mmemory: 100Mivolumes:- name: confemptyDir: {}- name: config-mapconfigMap:name: mysqlvolumeClaimTemplates:-metadata:name: dataspec:accessModes: ["ReadWriteOnce"]storageClassName: "nfs"resources:requests:storage: 2Gi(3)创建服务,用于访问mysql集群。
# Headless service for stable DNS entriesof StatefulSet members.
apiVersion: v1
kind: Service
metadata:name: mysqllabels:app: mysql
spec:ports:-name: mysqlport: 3306clusterIP: Noneselector:app: mysql
---
# Client service for connecting to anyMySQL instance for reads.
# For writes, you must instead connect tothe master: mysql-0.mysql.
apiVersion: v1
kind: Service
metadata:name: mysql-readlabels:app: mysql
spec:ports:-name: mysqlport: 3306selector:
app: mysqMySQL StatefulSet实例
(1)一个StatefulSet对象
NAME DESIRED CURRENT AGE
statefulset.apps/mysql 2 2 2d(2)三个Pod
[root@master1 ~]# oc get pod
NAME READY STATUS RESTARTS AGE
mysql-0 2/2 Running 0 2d
mysql-1 2/2 Running 0 2d
mysql-2 2/2 Running 0 2dStatefulSet 控制器创建出三个Pod,每个Pod使用数字后缀来区分顺序。创建时,首先mysql-0 Pod被创建出来,然后创建mysql-1 Pod,再创建mysql-2 Pod。
(3)两个服务
[root@master1 ~]# oc get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mysql ClusterIP None <none> 3306/TCP 2d
mysql-read ClusterIP 172.30.169.48 <none> 3306/TCP 2dmysql服务是一个Headless服务,它没有ClusterIP,只是为每个Pod提供一个域名,三个Pod的域名分别是:
- mysql-0.mysql.testmysql.svc.cluster.local
- mysql-1.mysql.testmysql.svc.cluster.local
- mysql-2.mysql.testmysql.svc.cluster.local
mysql-read 服务则是一个ClusterIP服务,作为集群内部的负载均衡,将数据库读请求分发到后端的两个Pod。
(4)三个PVC
[root@master1 ~]# oc get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-mysql-0 Bound pvc-98a6f5c9-11a9-11ea-b651-fa163e71648a 2Gi RWO nfs 2d
data-mysql-1 Bound pvc-845c0eae-11bb-11ea-b651-fa163e71648a 2Gi RWO nfs 2d
data-mysql-2 Bound pvc-018762f6-11bc-11ea-b651-fa163e71648a 2Gi RWO nfs 2d每个pvc和一个pod相对应,从名字上也能看出来其对应关系。mysql Pod的 /var/lib/mysql 文件夹保存在PVC卷中。
MySQL 集群操作
(1)集群访问
客户端通过 mysql-0.mysql.testmysql.svc.cluster.local 域名来向数据库写入数据:
[root@master1 ~]# mysql -h mysql-0.mysql.testmysql.svc.cluster.local -P 3306 -u root
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 142230
Server version: 5.7.28-log MySQL Community Server (GPL)Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.MySQL [(none)]> show databases;客户端通过 mysql-read.testmysql.svc.cluster.local 域名来从数据库读取数据:
[root@master1 ~]# mysql -h mysql-read.testmysql.svc.cluster.local -P 3306 -u root
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 142318
Server version: 5.7.28-log MySQL Community Server (GPL)Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.MySQL [(none)]> show databases;(2)集群扩容
当前的MySQL集群,具有一个写节点(mysql-0)和两个读节点(mysql-1和mysql-2)。如果要提升读能力,可以对StatefulSet对象扩容,以增加读节点。比如以下命令将总Pod数目扩大到4,读Pod数目扩大到3
oc scale statefulset mysql --replicas=4(3)集群缩容
运行以下命令,将集群节点数目缩容到3:
oc scale statefulset mysql --replicas=3然后mysql-3 Pod会被删除:
[root@master1 ~]# oc get pod
NAME READY STATUS RESTARTS AGE
mysql-0 2/2 Running 0 2d
mysql-1 2/2 Running 0 2d
mysql-2 2/2 Running 0 2d
mysql-3 2/2 Terminating 0 2应用场景
StatefulSet是为了解决有状态服务的问题,其应用场景包括:
- 稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现
- 稳定的网络标志,即Pod重新调度后其PodName和HostName不变,基于Headless Service(即没有Cluster IP的Service)来实现。。StatefulSet控制器依赖于一个事先存在的Headless Serivce对象实现Pod对象的持久,唯一的标识符配置;Headless Service需要由用户手动配置。
- 有序部署,有序扩展,即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依次进行(即从0到N-1,在下一个Pod运行之前所有之前的Pod必须都是Running和Ready状态),基于init containers来实现有序收缩,有序删除(即从N-1到0)
使用条件
- 各Pod用到的存储卷必须是又Storage Class动态供给或者由管理事先创建好的PV
- 删除StatefulSet或者缩减其规模导致Pod被删除时不会自动删除其存储卷以确保数据安全
- StatefulSet控制器依赖于事先存在一个Headless Service 对象事先Pod对象的持久、唯一的标识符配置,此Headless Service需要由用户手动配置。
2.Operator
StatefulSet 无法解决有状态应用的所有问题,它只是一个抽象层,负责给每个Pod打上不同的ID,并支持每个Pod使用自己的PVC卷。但有状态应用的维护非常复杂,需要一个独立的DBA团队来负责管理数据库。从上文也能看出,通过StatefulSet实例的操作,也只能做到创建集群、删除集群、扩缩容等基础操作,但比如备份、恢复等数据库常用操作,则无法实现。
CoreOS 公司开源了一个比较厉害的工具:Operator Framework,该工具可以让开发人员更加容易的开发 Operator 应用。地址是:https://github.com/operator-framework
CoreOS团队提出了K8S Operator概念。Operator是kubernetes的一个扩展,它使用自定义资源(Custom Resources)来管理应用和组件,并且遵循kubernetes的规范。它的核心就是自己编写控制器来实现自动化任务的效果,从而取代kubernetes自己的控制器和CRD资源,也就是使用自定义资源来编排有状态应用。
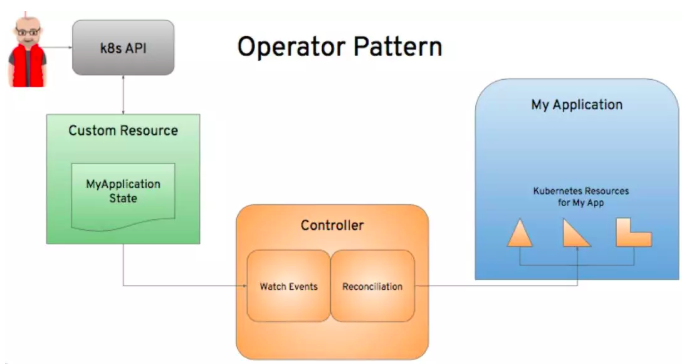
Operator是一个自动化的软件管理程序,负责处理部署在K8S和OpenShift上的软件的安装和生命周期管理。它包含一个Controller和CRD(Custom Resource Definition),CRD扩展了K8S API。其基本模式如下图所示:
示例1-ETCD Operator
创建ETCD Operator
下面创建etcd-operator:
[root@master example]# kubectl create -f deployment.yaml
deployment.apps/etcd-operator created创建成功后,过一段时间,就能看到这个pod进入running状态了:
[root@master rbac]# kubectl get pod
NAME READY STATUS RESTARTS AGE
etcd-operator-84cf6bc5d5-gfwzn 1/1 Running 0 105s查看CRD
创建operator时,应用会创建一个CRD(Custom Resource Definition),这正是operator的特性,查看一下这个crd:
[root@master rbac]# kubectl get crd
NAME CREATED AT
etcdclusters.etcd.database.coreos.com 2020-08-29T06:51:14Z查看CRD详细信息
[root@master rbac]# kubectl describe crd etcdclusters.etcd.database.coreos.com
Name: etcdclusters.etcd.database.coreos.com
Namespace:
Labels: <none>
Annotations: <none>
API Version: apiextensions.k8s.io/v1
Kind: CustomResourceDefinition
Metadata:Creation Timestamp: 2020-08-29T06:51:14ZGeneration: 1Resource Version: 3553Self Link: /apis/apiextensions.k8s.io/v1/customresourcedefinitions/etcdclusters.etcd.database.coreos.comUID: e71b69e9-1c55-4f38-a970-dad8484265ea
Spec:Conversion:Strategy: NoneGroup: etcd.database.coreos.comNames:Kind: EtcdClusterList Kind: EtcdClusterListPlural: etcdclustersShort Names:etcdSingular: etcdclusterPreserve Unknown Fields: trueScope: NamespacedVersions:Name: v1beta2Served: trueStorage: true
Status:Accepted Names:Kind: EtcdClusterList Kind: EtcdClusterListPlural: etcdclustersShort Names:etcdSingular: etcdclusterConditions:Last Transition Time: 2020-08-29T06:51:14ZMessage: no conflicts foundReason: NoConflictsStatus: TrueType: NamesAcceptedLast Transition Time: 2020-08-29T06:51:14ZMessage: the initial names have been acceptedReason: InitialNamesAcceptedStatus: TrueType: EstablishedStored Versions:v1beta2
Events: <none>这个crd里面定义的Group是etcd.database.coreos.com,kind是EtcdCluster。有了这个crd,operator就可以作为一个控制器来对这个crd进行控制了。
创建集群
下面创建集群,先看一下yaml文件,内容如下:
[root@master example]# cat example-etcd-cluster.yaml
apiVersion: "etcd.database.coreos.com/v1beta2"
kind: "EtcdCluster"
metadata:name: "example-etcd-cluster"## Adding this annotation make this cluster managed by clusterwide operators## namespaced operators ignore it# annotations:# etcd.database.coreos.com/scope: clusterwide
spec:size: 2
version: "3.3.25"这个yaml文件的定义:集群数量是2,etcd版本号是3.3.25,而kind就是自定义的资源类型EtcdCluster,所以它其实就是crd的具体实现,即CR(Custom Resources)。
创建这个集群:
[root@master example]# kubectl create -f example-etcd-cluster.yaml
etcdcluster.etcd.database.coreos.com/example-etcd-cluster created过一小段时间后查看pod创建情况,可以看到,集群中的2个节点已经创建出来了:
NAME READY STATUS RESTARTS AGE
example-etcd-cluster-4t886mhnwv 1/1 Running 0 2m43s
example-etcd-cluster-jkclxffwf5 1/1 Running 0 2m52s使用ETCD Operator的优势,就是可以把上面这个静态组建集群的过程自动化,不使用ETCD Oerator需要手动的一个节点一个节点的创建。
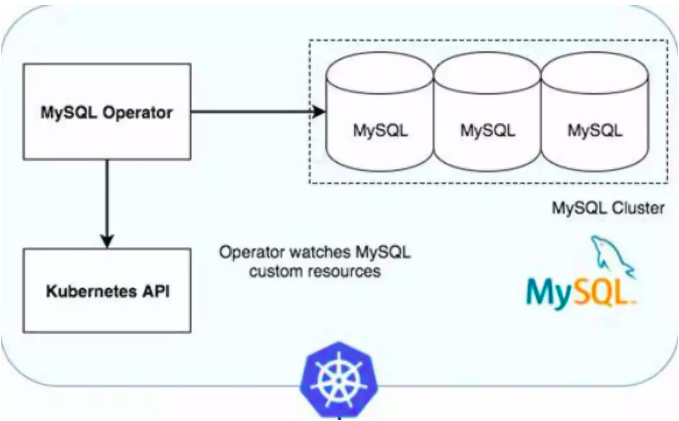
示例2-MySQL Operator
Oracle在github上开源了K8S MySQL Operator,它能在K8S上创建、配置和管理MySQL InnoDB 集群,其地址是https://github.com/mysql/mysql-operator。其主要功能包括:
- 在K8S上创建和删除高可用的MySQL InnoDB集群
- 自动化数据库的备份、故障检测和恢复操作
- 自动化定时备份和按需备份
- 通过备份恢复数据库
其基本架构如下图所示:
(1)定义一个1主2备MySQL集群:
apiVersion: mysql.oracle.com/v1alpha1
kind: Cluster
metadata:name: mysql-test-cluster
spec:members: 3(2)定义一个3主集群:
apiVersion: mysql.oracle.com/v1alpha1
kind: Cluster
metadata:name: mysql-multimaster-cluster
spec:multiMaster: truemembers: 3(3)创建一个到S3的备份:
apiVersion: "mysql.oracle.com/v1"
kind: MySQLBackup
metadata:name: mysql-backup
spec:executor:provider: mysqldumpdatabases:- teststorage:provider: s3 secretRef:name: s3-credentialsconfig: endpoint: x.compat.objectstorage.y.oraclecloud.comregion: ociregionbucket: mybucketclusterRef:name: mysql-cluster应用场景
使用operator是实现自动化的需求大概有以下几类:
- 按照需求部署一个应用
- 获取或者恢复一个应用的状态
- 应用代码升级,同时关联的数据库或者配置等一并升级
- 发布一个服务,让不支持kubernetes api的应用也能发现它
- 模拟集群的故障以测试集群稳定性
3.总结
Operator本质上是针对拥有复杂应用的应用场景去简化其运维管理的工具。StatefulSet也是一种Deployment,只是它的每一个pod都携带了一个唯一并且固定的编号。这个编号非常重要,因为这个编号固定了pod的拓扑关系,固定了pod的DNS记录,有了这个序号,当pod重建时,就不会丢失之前的状态了。pvc则固定了pod的存储状态,它与pv进行绑定从而使用pv中声明的volume存储。这样pod重启后数据就不会丢失了。
例如在编排方式上:创建ETCD集群,使用Operator的本质就是创建CRD,然后编写控制器来控制CRD的创建过程。跟StatefulSet的编排不一样的是,StatefulSet的编排pod是通过绑定编号的方式来固定拓扑结构的,而Operator的创建过程并没有这样,原因就是etcd operator的编排无非就是新增节点加入集群和删除多的节点,这个拓扑结果etcd内部就可以维护了,绑定编号没有意义。
参考资料:
1.在Kubernetes上运行有状态应用:从StatefulSet到Operator - SammyLiu - 博客园
2.https://github.com/coreos/etcd-operator/blob/master/doc/user/walkthrough/restore-operator.md
3.https://cloud.tencent.com/developer/article/1693895