原论文地址:原论文下载地址
论文摘要:Transformer最近在各种视觉任务上表现出了优异的性能。对于巨大的甚至是全局性的感受野赋予Transformer模型比CNN模型更高的表现力。然而,仅仅扩大感受野也会引起一些担忧。一方面,在ViT中使用密集的注意力会导致过度的内存和计算成本,并且特征可能会受到感兴趣区域之外的不相关部分的影响。另一方面,在PVT或Swin Transformer中采用的稀疏注意力可能会限制建立long range关系模型的能力。为了缓解这些问题,我们提出了一种新的可变形的自注意模块,其中以数据相关的方式选择自注意中的键-值对的位置。这种灵活的方案使自注意模块能够专注于相关区域并捕获其特征。在此基础上,我们提出了Deformable Attention Transformer,这是一种用于图像分类和密集预测任务的具有可变形注意力的通用主干模型。大量实验表明,我们的模型在综合基准上取得了持续改进的结果。

具体的内容学习可以参考这篇博客介绍的比较详细:
博客地址
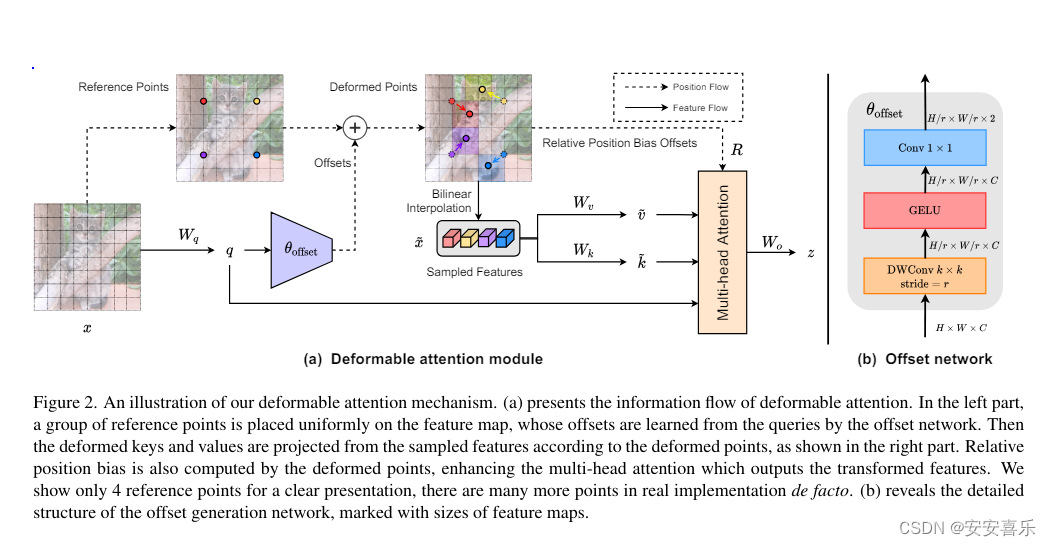
可变形注意机制的图示。 (a) 呈现可变形注意力的信息流。在左侧部分,一组参考点均匀地放置在特征图上,其偏移量是通过偏移网络从查询中学习到的。然后根据变形点从采样的特征中投影出变形的键和值,如右图所示。相对位置偏差也由变形点计算,增强了输出变形特征的多头注意力。我们只展示了 4 个参考点以进行清晰的展示,实际实施中还有更多参考点。 (b) 揭示了偏移生
Deformable CNN and attention
可变形卷积是一种处理以输入数据为条件的灵活变换空间位置的机制。最近,它已应用于ViT。Deformable DETR通过为CNN backbone顶部的每个query选择少量的key,改进了DETR的收敛性。由于缺少key限制了表示能力,其可变形注意力不适合用于作为特征提取的视觉主干。此外,Deformable DETR中的注意力来自简单学习的线性投影,并且query token之间不共享key。DPT和PS ViT构建可变形模块以优化视觉token。具体而言,DPT提出了一种可变形patch embedding方法来细化各个stage的patch,而PS ViT在ViT主干之前引入了一个空间采样模块来改进视觉token。它们都没有将变形注意力纳入视觉中枢。相比之下,我们的可变形注意力采用了一种强大而简单的设计来学习视觉token之间共享的一组全局key,可以作为各种视觉任务的通用主干。我们的方法也可以被视为一种空间自适应机制,这在各种工作中都被证明是有效的。
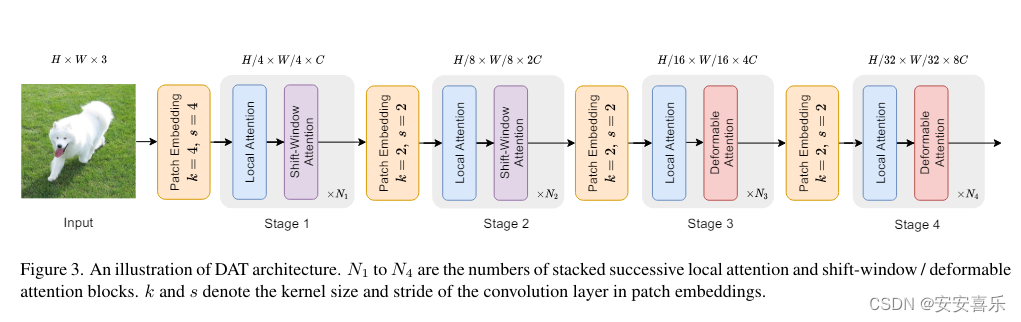
与 DCN 类似,将设计好的可变形注意力模块加入到 ViT 模型的最后两个阶段,得到 Deformable Attention Transformer,如下图所示:
2.DAT加入到yolov8的步骤:
2.1 加入ultralytics/nn/attention/deformable_attention_2d.py
import torch
import torch.nn.functional as F
from torch import nn, einsumfrom einops import rearrange, repeat# helper functionsdef exists(val):return val is not Nonedef default(val, d):return val if exists(val) else ddef divisible_by(numer, denom):return (numer % denom) == 0# tensor helpersdef create_grid_like(t, dim = 0):h, w, device = *t.shape[-2:], t.devicegrid = torch.stack(torch.meshgrid(torch.arange(h, device = device),torch.arange(w, device = device),indexing = 'ij'), dim = dim)grid.requires_grad = Falsegrid = grid.type_as(t)return griddef normalize_grid(grid, dim = 1, out_dim = -1):# normalizes a grid to range from -1 to 1h, w = grid.shape[-2:]grid_h, grid_w = grid.unbind(dim = dim)grid_h = 2.0 * grid_h / max(h - 1, 1) - 1.0grid_w = 2.0 * grid_w / max(w - 1, 1) - 1.0return torch.stack((grid_h, grid_w), dim = out_dim)class Scale(nn.Module):def __init__(self, scale):super().__init__()self.scale = scaledef forward(self, x):return x * self.scale# continuous positional bias from SwinV2class CPB(nn.Module):""" https://arxiv.org/abs/2111.09883v1 """def __init__(self, dim, heads, offset_groups, depth):super().__init__()self.heads = headsself.offset_groups = offset_groupsself.mlp = nn.ModuleList([])self.mlp.append(nn.Sequential(nn.Linear(2, dim),nn.ReLU()))for _ in range(depth - 1):self.mlp.append(nn.Sequential(nn.Linear(dim, dim),nn.ReLU()))self.mlp.append(nn.Linear(dim, heads // offset_groups))def forward(self, grid_q, grid_kv):device, dtype = grid_q.device, grid_kv.dtypegrid_q = rearrange(grid_q, 'h w c -> 1 (h w) c')grid_kv = rearrange(grid_kv, 'b h w c -> b (h w) c')pos = rearrange(grid_q, 'b i c -> b i 1 c') - rearrange(grid_kv, 'b j c -> b 1 j c')bias = torch.sign(pos) * torch.log(pos.abs() + 1) # log of distance is sign(rel_pos) * log(abs(rel_pos) + 1)for layer in self.mlp:bias = layer(bias)bias = rearrange(bias, '(b g) i j o -> b (g o) i j', g = self.offset_groups)return bias# main classclass DeformableAttention2D(nn.Module):def __init__(self,dim,dim_head = 64,heads = 8,dropout = 0.,downsample_factor = 4,offset_scale = None,offset_groups = None,offset_kernel_size = 6,group_queries = True,group_key_values = True):super().__init__()offset_scale = default(offset_scale, downsample_factor)assert offset_kernel_size >= downsample_factor, 'offset kernel size must be greater than or equal to the downsample factor'assert divisible_by(offset_kernel_size - downsample_factor, 2)offset_groups = default(offset_groups, heads)assert divisible_by(heads, offset_groups)inner_dim = dim_head * headsself.scale = dim_head ** -0.5self.heads = headsself.offset_groups = offset_groupsoffset_dims = inner_dim // offset_groupsself.downsample_factor = downsample_factorself.to_offsets = nn.Sequential(nn.Conv2d(offset_dims, offset_dims, offset_kernel_size, groups = offset_dims, stride = downsample_factor, padding = (offset_kernel_size - downsample_factor) // 2),nn.GELU(),nn.Conv2d(offset_dims, 2, 1, bias = False),nn.Tanh(),Scale(offset_scale))self.rel_pos_bias = CPB(dim // 4, offset_groups = offset_groups, heads = heads, depth = 2)self.dropout = nn.Dropout(dropout)self.to_q = nn.Conv2d(dim, inner_dim, 1, groups = offset_groups if group_queries else 1, bias = False)self.to_k = nn.Conv2d(dim, inner_dim, 1, groups = offset_groups if group_key_values else 1, bias = False)self.to_v = nn.Conv2d(dim, inner_dim, 1, groups = offset_groups if group_key_values else 1, bias = False)self.to_out = nn.Conv2d(inner_dim, dim, 1)def forward(self, x, return_vgrid = False):"""b - batchh - headsx - heighty - widthd - dimensiong - offset groups"""heads, b, h, w, downsample_factor, device = self.heads, x.shape[0], *x.shape[-2:], self.downsample_factor, x.device# queriesq = self.to_q(x)# calculate offsets - offset MLP shared across all groupsgroup = lambda t: rearrange(t, 'b (g d) ... -> (b g) d ...', g = self.offset_groups)grouped_queries = group(q)offsets = self.to_offsets(grouped_queries)# calculate grid + offsetsgrid =create_grid_like(offsets)vgrid = grid + offsetsvgrid_scaled = normalize_grid(vgrid)kv_feats = F.grid_sample(group(x),vgrid_scaled,mode = 'bilinear', padding_mode = 'zeros', align_corners = False)kv_feats = rearrange(kv_feats, '(b g) d ... -> b (g d) ...', b = b)# derive key / valuesk, v = self.to_k(kv_feats), self.to_v(kv_feats)# scale queriesq = q * self.scale# split out headsq, k, v = map(lambda t: rearrange(t, 'b (h d) ... -> b h (...) d', h = heads), (q, k, v))# query / key similaritysim = einsum('b h i d, b h j d -> b h i j', q, k)# relative positional biasgrid = create_grid_like(x)grid_scaled = normalize_grid(grid, dim = 0)rel_pos_bias = self.rel_pos_bias(grid_scaled, vgrid_scaled)sim = sim + rel_pos_bias# numerical stabilitysim = sim - sim.amax(dim = -1, keepdim = True).detach()# attentionattn = sim.softmax(dim = -1)attn = self.dropout(attn)# aggregate and combine headsout = einsum('b h i j, b h j d -> b h i d', attn, v)out = rearrange(out, 'b h (x y) d -> b (h d) x y', x = h, y = w)out = self.to_out(out)if return_vgrid:return out, vgridreturn out2.2 注册ultralytics/nn/tasks.py
在tasks.py文件的上面导入部分粘贴下面的代码
from ultralytics.nn.attention.deformable_attention_2d import DeformableAttention2D修改def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
只需要加入 DeformableAttention2D,加入以下代码:
if m in (Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, Focus,BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, DeformableAttention2D):2.3 yolov8_DeformableAttention2D.yaml
# Ultralytics YOLO 🚀, GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 1, DeformableAttention2D, [1024]] # 22# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)