一. 各各品类产品交易指数对比
获取文件名
files = glob.glob("./*.xlsx")# 读取数据,并改列名,增加一列 品牌
dfs = []
for f in files:t = f[2:4]df = pd.read_excel(f)df["品牌"] = tif t == "拜耳":df.rename(columns={"时间":"日期"},inplace=True)dfs.append(df)#拼接
data = pd.concat(dfs,ignore_index=True)
#创建品类列,且都为nan
data["品类"] = np.nand.index
#(['上门服务', '杀虫剂', '白蚁', '虫', '虱', '蚂蚁', '蛾', '蝇', '螨', '蟑螂', '鼠'], dtype='object', name='适用对象')# 从d.index 上门服务', '杀虫剂', '白蚁', '虫', '虱', '蚂蚁', '蛾', '蝇', '螨', '蟑螂', '鼠' 的 白蚁开始到最后,修改品类这一列
for x in d.index[2:]:data.loc[data.商品.str.contains(x),"品类"] = x # 对比三家公司 将各种品类的销售金额 进行对比
for x in d.index[2:]:display(x,data.query("品类 == @x").groupby("品牌").交易金额.sum())二. 市场上商品结构
# 将品类为蟑螂的所有数据, 与 按照商品分类后对交易指数求和 的数据进行拼接,且把求和列改为 交易指数和
data = pd.merge(data.query("品类 == '蟑螂'"),data.groupby("商品").交易指数.sum().reset_index(0).rename(columns={"交易指数":"交易指数和"}),left_on="商品",right_on="商品")# 每一家公司 对 同种商品 进行销售的 比例 (如果为 1 说明只有一家在售卖)
data["同种类商品售卖比例"]=data["交易指数"].div(data["交易指数和"])#调和均值
data["交易增长幅度调和值"] = data["交易增长幅度"].mul(data["同种类商品售卖比例"])# 现在df是根据商品分类,进行的一系列操作
df = data.groupby("商品")\
.agg({"交易指数":"sum","交易增长幅度调和值":"sum","商品":"count","品牌":"max"})\
.rename(columns={"交易指数":"相对市场占有率","交易增长幅度调和值":"相对市场增长率","商品":"产品数量"})1.因为绘制BCG图时候,发现有些间隔中数据拉的过大,需要我们在选择时舍弃一些
display(df.describe(percentiles=[0.8,0.85,0.9,0.95,0.99,1])) #描述统计# 找到变化率不太快的位置 , 让大值 = 0.85位置的数值
# 这里的x 就是 下面action函数的 series。
def quantile(x,q=0.85):qu = x.quantile(q) # 找到0.85百分的值# 如果当前的值 大于0.85的值,则当前值替换为0.85.否则不便return x.mask(x > qu, qu) # mysql 当中 if(cond,True,False) mask有循环的功效# 截取数据,都替换成0.85的数据
def action(df):df = df.copy() #希望原先的数据不被修改df["相对市场占有率"] = quantile(df["相对市场占有率"])df["相对市场增长率"] = quantile(df["相对市场增长率"])return df绘制
def BCGPlot(df,is_mean=True,xq=0.5,yq=0.5): #默认使用均值进行分割axes = sns.scatterplot(df,x="相对市场占有率",y="相对市场增长率",size="产品数量",hue="品牌")# 如果ismean 为true, 线都采用均值计算,否则用0.5分位进行绘制if is_mean:plt.axvline(df.相对市场占有率.mean(),c="k",ls=":",lw=1)plt.axhline(df.相对市场增长率.mean(),c="k",ls=":",lw=1)else:plt.axvline(df.相对市场占有率.quantile(xq),c="k",ls=":",lw=1)plt.axhline(df.相对市场增长率.quantile(yq),c="k",ls=":",lw=1)plt.text(250000,.8,"明星类",fontsize=20,color="y")plt.text(250000,-.5,"奶牛类",fontsize=20,color="r")plt.text(100000,.8,"山猫类",fontsize=20,color="b")plt.text(100000,-.5,"瘦狗类",fontsize=20,color="k")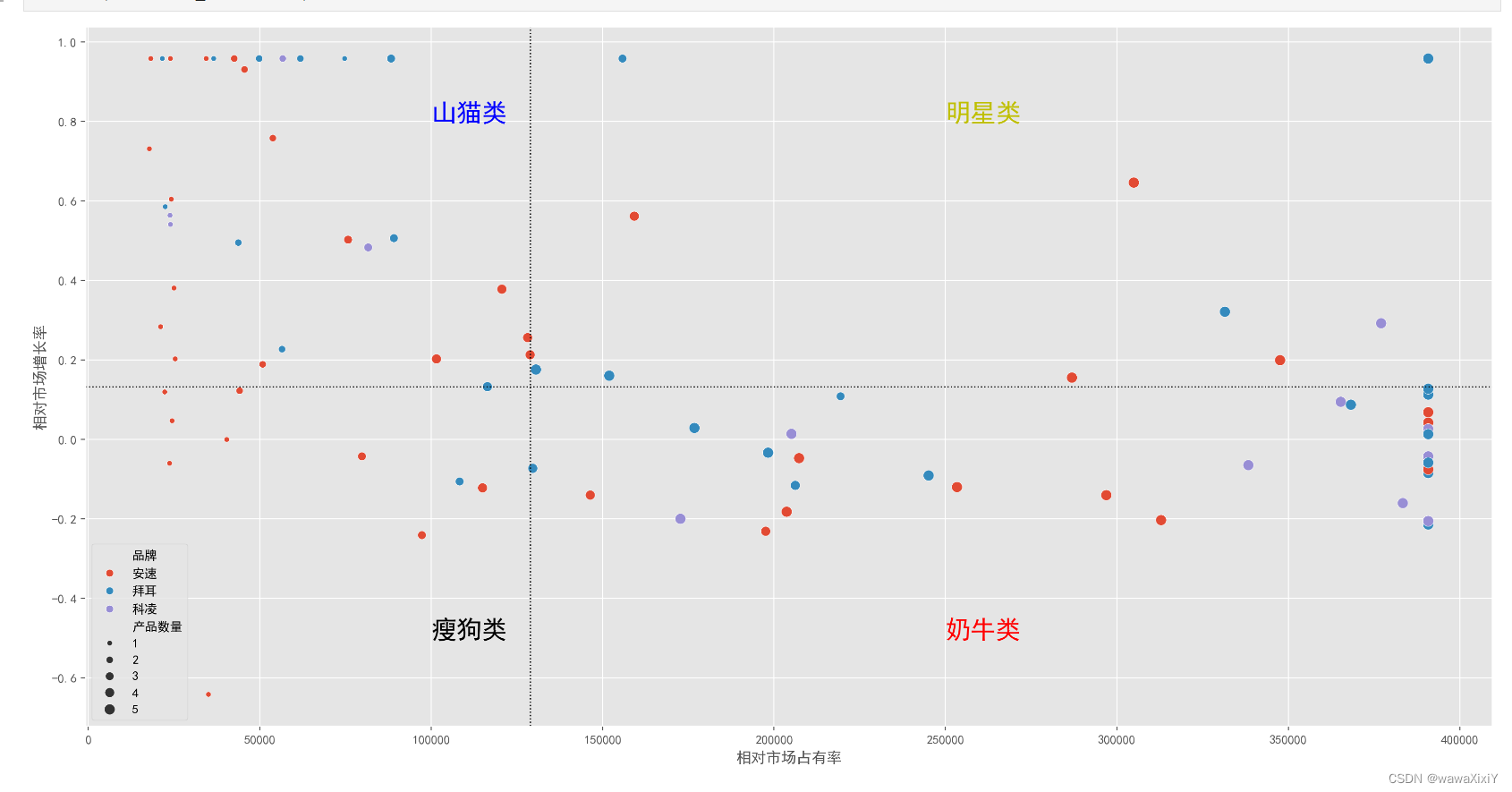
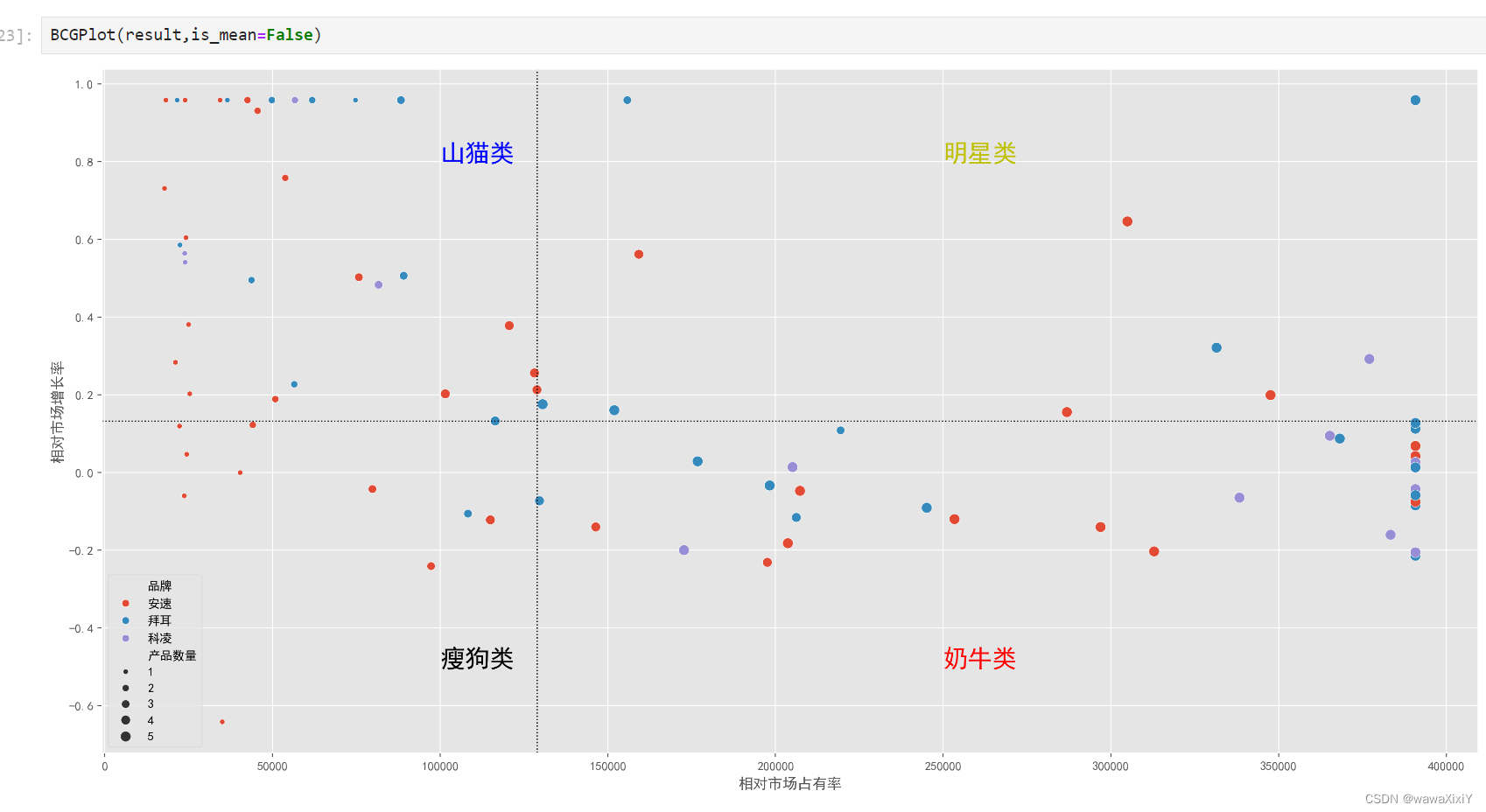
三. 给数据打上标签
def target(df,is_mean=True,xq=0.5,yq=0.5):相对市场占有率均值 = df["相对市场占有率"].mean()相对市场增长率均值 = df["相对市场增长率"].mean()df.loc[(df["相对市场占有率"] >= 相对市场占有率均值) & (df["相对市场增长率"] >= 相对市场增长率均值),"产品结构"] = "明星类"df.loc[(df["相对市场占有率"] >= 相对市场占有率均值) & (df["相对市场增长率"] < 相对市场增长率均值),"产品结构"] = "金牛类"df.loc[(df["相对市场占有率"] < 相对市场占有率均值) & (df["相对市场增长率"] >= 相对市场增长率均值),"产品结构"] = "山猫类"df.loc[(df["相对市场占有率"] < 相对市场占有率均值) & (df["相对市场增长率"] < 相对市场增长率均值),"产品结构"] = "瘦狗类"df.loc[(df["相对市场占有率"] >= 相对市场占有率均值) & (df["相对市场增长率"] >= 相对市场增长率均值),"序号"] = 2df.loc[(df["相对市场占有率"] >= 相对市场占有率均值) & (df["相对市场增长率"] < 相对市场增长率均值),"序号"] = 1df.loc[(df["相对市场占有率"] < 相对市场占有率均值) & (df["相对市场增长率"] >= 相对市场增长率均值),"序号"] = 3df.loc[(df["相对市场占有率"] < 相对市场占有率均值) & (df["相对市场增长率"] < 相对市场增长率均值),"序号"] = 4return df.sort_values(by="序号")result = target(result)result 是各个产品结构(比如金牛),对每个结构的数量进行热力图绘制
# 进行透视, index是产品结构, 列名是品牌,对产品数量计数(查看金牛等产品的个数)
d = pd.pivot_table(data=result,index="产品结构",columns="品牌",values="产品数量",aggfunc="count").fillna(0)sns.heatmap(data=d.loc[result.产品结构.unique()],annot=True,cmap="autumn",linewidths=1)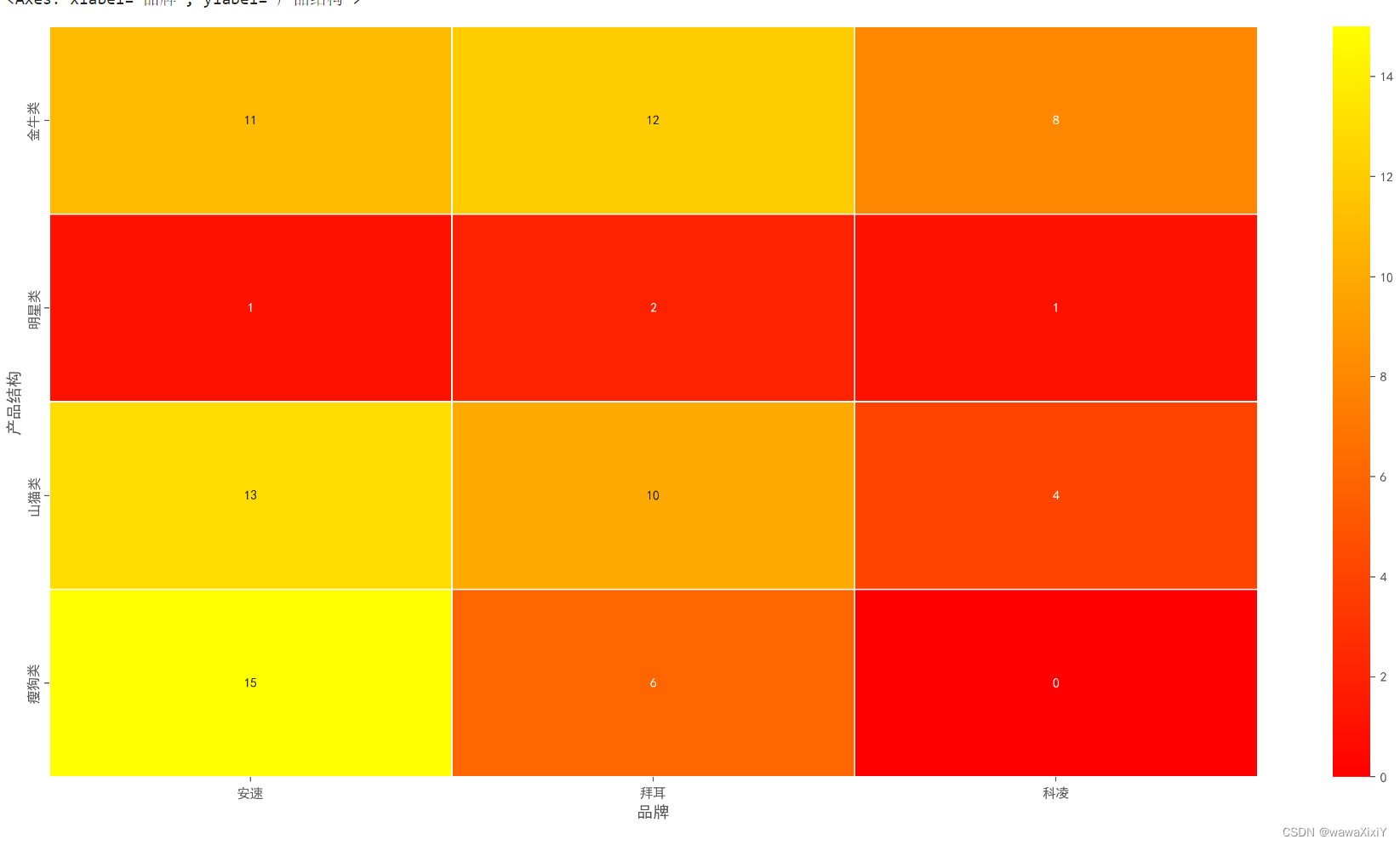
四.流量
-
ROI : 投资回报比
-
不同的渠道, 带来的用户质量(客单价 退货率 转换程付费率) 微信视频
-
投放广告的周期 ; 50W 7点 开投 - 9店 10点
-
不同的人群
-
不同的广告投放方式
-
付费流量
-
"免费"流量
- 淘宝客 : 自己生成链接 , 由淘宝客 推 链接出去 , 别人点击了链接 并且 购买了,则有提成
- SEO优化 : 关键字(关键字热度)
五. 剔除无用数据
import re
# re.sub 替换, 将表情替换空
data["评论"]=data.评论.map(lambda x : re.sub(r"[^\u000000-\uffffff]+","",x))data = data.loc[data.评论 != "此用户没有填写评论"]六. 中文分词(jieba库)
import jieba #结巴
from wordcloud import WordCloud# 将一句话 切称 有意义的词,或短句
jieba.lcut(data.评论[2])# 将数据划分为有用的词,然后选取大于1 的词
def fo(x):return [w for w in jieba.lcut(x) if len(w)>1]mask = plt.imread("../../leaf.jpg") def wcplot(d):#去除停用词 我认为这些词汇 可能没有用处w = d.explode() # 把一个列表多个词 分为一个一个的# w.isin() 是筛选在里的 , 取反取不是停用词w = w.loc[~w.isin(stopwords)] #去除停用词c = w.value_counts() #词计数#当前只是图片的配置项 返回词云画布wc = WordCloud(font_path="../../SimHei.ttf",mask=mask,width=1000,height=800,min_font_size=10,max_font_size=100,background_color="white")#这个就是生成了词云图wc.fit_words(c)# 借助 imshow 绘制plt.imshow(wc)# 去除坐标轴plt.axis("off")d = data.query("品牌 == '拜耳'").评论.map(fo)wcplot(d)
七, 情感分析
def fo(x):s = pd.Series([w for w in jieba.lcut(x) if len(w)>1])# 这里去除 停用词 然后选取这些数据, join 是直接去除逗号return " ".join(s.loc[~s.isin(stopwords)])textdata = data.评论.map(fo)textdata.iloc[6]a = data.loc[data.评论.str.contains("垃圾|完全没有效果|小强依然活跃")]
a["评价"] = 0b= data.loc[data.评论.str.contains("必须好评|效果很好|强烈推荐")]
b["评价"] = 1ab = pd.concat([a,b])
ab
八 . 贝叶斯分析
from sklearn.feature_extraction.text import TfidfVectorizer #把文字转换 成数字 #词向量tfidf = TfidfVectorizer()feature = tfidf.fit_transform(ab.评论) #179行数据 682个词汇pred_feature = tfidf.transform(textdata) #更加上面682个词汇 把 当前的数据 也定义成 词向量target = ab.评价from sklearn.naive_bayes import BernoulliNB #二项分布 添加越策标签model = BernoulliNB().fit(feature,target)pred_target = model.predict(pred_feature)data["评价"] = pred_targetdata.评价


![[AIGC] Spring中的SPI机制详解](https://img-blog.csdnimg.cn/direct/0a50f4c8f3554d86aa7d91504068b517.png)
![VUE typescript 调用stompjs[Rabbit MQ]](https://img-blog.csdnimg.cn/direct/66dc6a193b3d49cfb701107d2d599608.png)