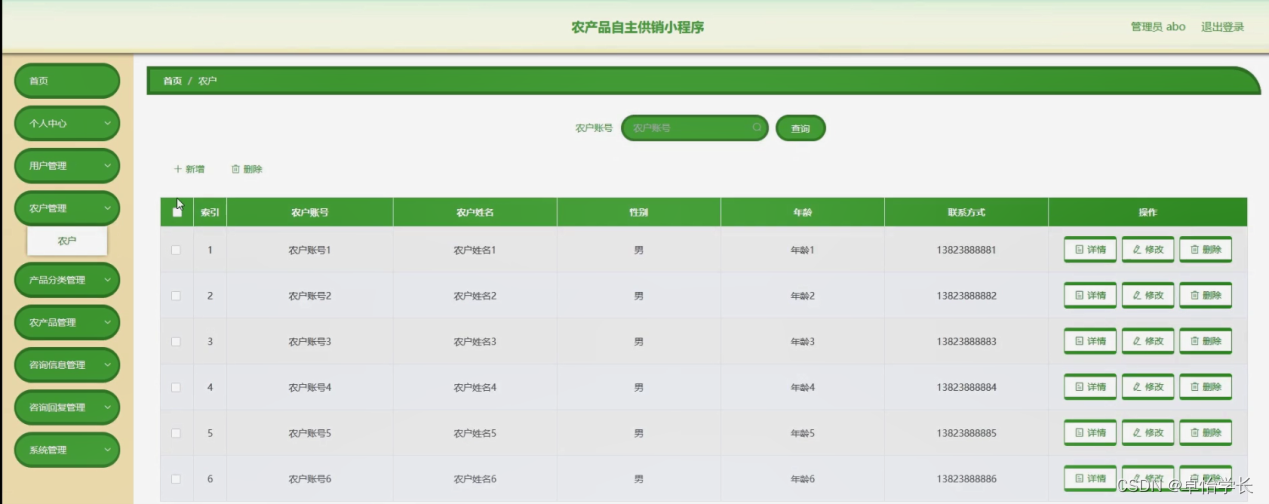
文档地址:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+LateralView
- 1.介绍
- 2.语法
- 3.code demo
- 1)单重侧视图
- 2)多重侧视图
- 3)tips:lateral view outer
1.介绍
lateral view也叫侧视图,属于hive sql所特有的语法。用来实现类似标准sql中join的操作。但区别在于:
- join参与运算的往往是两个表,根据指定的关联字段进行横向连接。
- lateral view参与运算的是一张表,这张表里往往存在某个多值的字段,通过侧视图结合UDTF函数可以将这个多值字段拆分为粒度更小的值,每一个拆分出来的值都会作为新的字段和一条原记录进行拼接。类似于列转行操作,虽然严格意义上不算列转行,因为只是增加了行数,但并未减少列数,只是减少了列中所包含的字段个数。
2.语法
selectsrc.*,tb_alias.col_alias
from src lateral view UDTF(src.col) tb_alias as col_alias [, col_alias, ...];
以上只是一个基本的语法参考,tb_alias为表别名,这里的表指的是UDTF所返回的虚拟表。as col_alias [, col_alias, ...]是给这个虚拟表的字段指定别名,方便后续引用。返回的虚拟表中有几个字段,就得指定几个别名,业务中一般只返回一个。
关于字段别名,文档里说的是从
hive 0.12.0字段别名可以省略,此时它继承自UDTF函数在定义时指定的字段名,但仅做了解即可,按照上面语法通用就不必要做一些非必要的改动。

重点是理解上述代码的逻辑执行过程,UDTF会根据传入的字段先返回一张虚拟表,此时虚拟表的表名和字段名分别被命名为tb_alias 和col_alias,然后通过lateral view,将虚拟表的每条记录关联到原来所属的记录上去,类似于join操作,只不过不需要我们显式指定on的字段,hive内部会自己识别原来属于哪条记录并关联。最后再从这张结果表中select我们需要的字段就可以了。
3.code demo
1)单重侧视图
with src as (select '张三' as name, '唱;跳;rap'as skillsunion allselect '李四' as name, '唱;跳'as skills
)
selectsrc.*,tb.col_name
from src lateral view explode(split(skills,';')) tb as col_name;
output:

2)多重侧视图
多重侧视图的执行过程是在上一步侧视图结果的基础上,再进行一次lateral view操作,所以对于后面的lateral view,是可以直接引用前面lateral view结果表中的字段的。
下面通过代码对二重lateral view拆开分步演示,可以更好的理解执行逻辑。
step1:
with src as (select '张三' as name, map('语文', '71;72;73', '数学', '81;82;83') as colunion allselect '李四' as name, map('语文', '90') as col
)
select src.*,tb1.subject,tb1.score
from src lateral view explode(col) tb1 as subject, score;
output:

step2,基于step1的结果,对成绩score列的值继续展开:
with src as (select '张三' as name, map('语文', '71;72;73', '数学', '81;82;83') as colunion allselect '李四' as name, map('语文', '90') as col
)
select src.*,tb1.subject,tb1.score,tb2.score_detail
from src lateral view explode(col) tb1 as subject, scorelateral view explode(split(tb1.score, ';')) tb2 as score_detail;
output:

当然,如果需要,可以继续lateral view下去。
3)tips:lateral view outer
有一个点需要注意,就是实际任务中UDTF的返回结果可能存在空值null的情况,对于这种情况,hive会丢失原表中的数据行,因为本身lateral view就类似于join操作,关联不上那就丢失了。
例如:
with src as (select '张三' as name, '唱;跳;rap'as skillsunion allselect '李四' as name, null as skills
)
selectsrc.*,tb.col_name
from src lateral view explode(split(skills,';')) tb as col_name;
output:

可以看到原始数据“李四”的信息就丢失了,同时需要注意这里的空值指的是null,而不是空字符串,这是两种不同的概念,比如下面这段sql:
with src as (select '张三' as name, '唱;跳;rap'as skillsunion allselect '李四' as name, '' as skills -- 这里修改null为空字符串''
)
selectsrc.*,tb.col_name
from src lateral view explode(split(skills,';')) tb as col_name;
output:

为了规避这种可能造成数据丢失的情况,hive从0.12.0版本及之后提供了lateral view outer来解决。这种方式可以理解为标准sql中的left join,即使UDTF返回的结果为null,也会保留原表的这条数据。具体见代码:
with src as (select '张三' as name, '唱;跳;rap'as skillsunion allselect '李四' as name, null as skills
)
selectsrc.*,tb.col_name
from src lateral view outer explode(split(skills,';')) tb as col_name;
output: