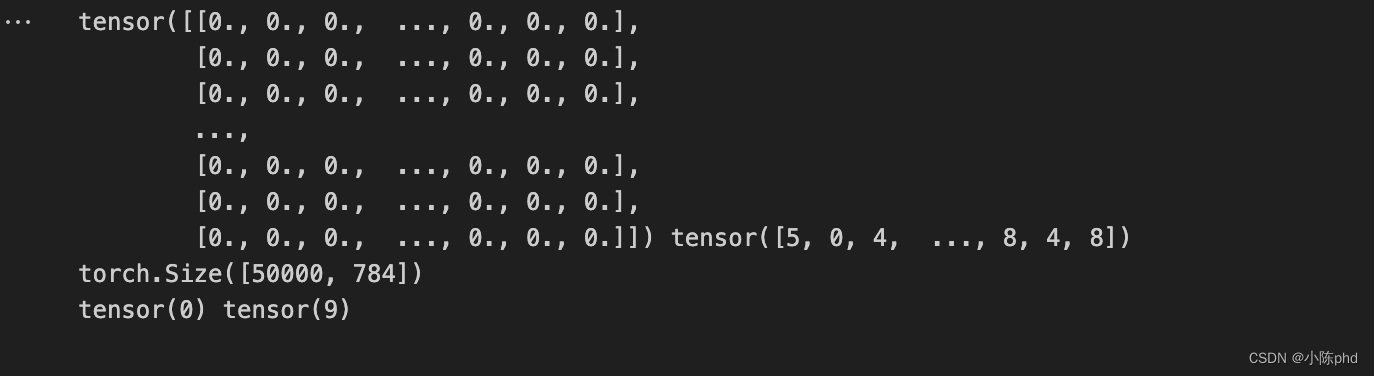
近年来,研究者在利用循环神经网络(Recurrent Neural Network,RNN)进行古诗自动生成方面取得了显著的效果。但 RNN 存在梯度问题,导致处理时间跨度较长的序列时 RNN 并不具备长期记忆存储功能。随后,出现的基于长短期记忆网络(Long Short-Term Memory,LSTM)古诗自动生成方法在一定程度上解决了 RNN 的梯度问题。本文将LSTM 应用在古诗自动生成技术上,并利用sparse_categorical_crossentropy损失函数和Adam(lr=0.002)优化算法对 LSTM模型进行优化,最后利用 flask 设计web界面进行操作和查看,可以根据提示词生成不同结构的五言律诗、七言绝句及藏头诗。结表明,相对于传统的RNN模型,LSTM模型在古诗自动生成方面生成的古诗效果更好。
1. LSTM模型设计与实现
古诗在中华传统文化中扮演着不可或缺的重要角色,其精炼的语言、和谐的音调和鲜明的节奏令人神往。古诗的创造讲究平仄声调、韵律严谨、绝句对仗、起承转合以及用词考究,还讲究意境的创造,要求意境优美;要通过简洁凝练的诗句表现出一定的意义,达到语美、音美、意美的效果 。这给没有文学功底的古诗爱好者在写作古诗时带来了一定的挑战,同时也促进了研究者利用现代技术对古诗自动生成的研究与开发。深度学习(Deep Learning,DL)主要应用于图像识别、语音识别和自然语言处理等领域 。深度学习是机器学习和神经网络更深层次的融合技术,其本质是众多成熟的神经网络算法模型,旨在利用计算机模拟人的大脑神经元学习过程,从而具有人的“思考”“推理”“规划”“判断”等能力。目前,利用深度学习神经网络实现古诗自动生成已成为了一大研究热点。
基于深度学习的歌词和古诗自动生成系统由多个模块构成,总体可以分为服务于 LSTM 神经网络的数据预处理模块、LSTM 神经网络模块等。数据预处理模块主要是对34646首传统古诗进行预处理,转换成 One-Hot 编码,神经网络才能进行矩阵计算、学习。LSTM 神经网络模块是最核心的模块,该模块是歌词和古诗生成最关键的部分,训练参数的选择十分重要,需要通过不断进行对比、调参,记录损失值和准确率来最终确定模型参数。建立古诗生成模型,需要三个步骤:搭建、训练和保存。
1.1 搭建模型::核心结构是两层 LSTM 神经网络,需要注意的是每次都定义一个新的BasicCell,而不是定义一个 BasicCell 之后多次调用。LSTM 神经网络在处理序列数据方面非常有效,虽然 RNN 与 CNN 都能进行序列建模,但本质上有不同。在搭建模型过程中还使用了 Embedding 层,称为嵌入层,相当于一个网络层,在模型第一层中使用,其目的是将有索引的标签映射到高密度低维向量,达到降维的作用,可以防止One-Hot 向量维度过大导致的运算速度过慢的问题,该层通常用于文本数据建模。使用 LSTM 神经网络模型还有一个必不可少的全连接层(Dense 层),它能够根据特征的组合进行分类,大大减少特征位置对分类带来的影响。
# 定义双层LSTM模型
model = Sequential()
model.add(Embedding(len(words), 128, input_length=78))
model.add(LSTM(128, return_sequences=True))
model.add(LSTM(128, return_sequences=True))
model.add(Dense(len(words), activation=' relu'))
optimizer = Adam(lr=0.002)
model.compile(loss='sparse_categorical_crossentropy', optimizer=optimizer)由于数据集较大,模型使用 Embedding 层将样本映射成低维向量,达到降维提速的效果。Embedding 层的词表大小设置为数据集中不重复字符的总数大小,词嵌入维度设置为 128。全连接层(Dense)设计。将数据集的词表大小设置为 Dense 层的维度,并使用 relu 作为 Dense 层的激活函数。优化函数设计。本文使用 Adam 优化算法对模型进行优化。利用大量数据集进行文本生成时,参数的梯度往往比较大,而加快训练速度减小参数梯度是 Adam优化算法的核心所在 。
1.2 训练模型::创建 session 会话进行训练,由于训练集比较大,所以歌词生成模型训练 30 个周期,古诗生成模型训练 100 个周期。输入每一轮的损失值,通过每轮训练后损失值的变化判断 LSTM 神经网络模型性能是否发生欠拟合,再比较 LSTM神经网络模型在训练集和测试集的正确率判断 LSTM 神经网络模型是否发生过拟合。若发生欠拟合则应该增加 LSTM 神经网络模型的深度或者增加训练的时间,若发生过拟合则应该采取正则化的方法或者 Dropout 抑制过拟合。
# 训练模型
for epoch in range(100):for batch_idx, (x_batch, y_batch) in enumerate(generate_batch(poetrys_vector, batch_size)):model.fit(x_batch, y_batch, verbose=0)if batch_idx % 50 == 1:print('Epoch:', epoch, 'Batch:', batch_idx, 'Loss:', model.evaluate(x_batch, y_batch, verbose=0))
1.3 保存模型
古诗生成模型保存为H5文件。Keras 框架使用 model.save() 方法保存模型。
# 保存模型
model.save('poetry_model.h5')其训练过程如下:


2. 基于LSTM 模型的古诗词自动生成系统
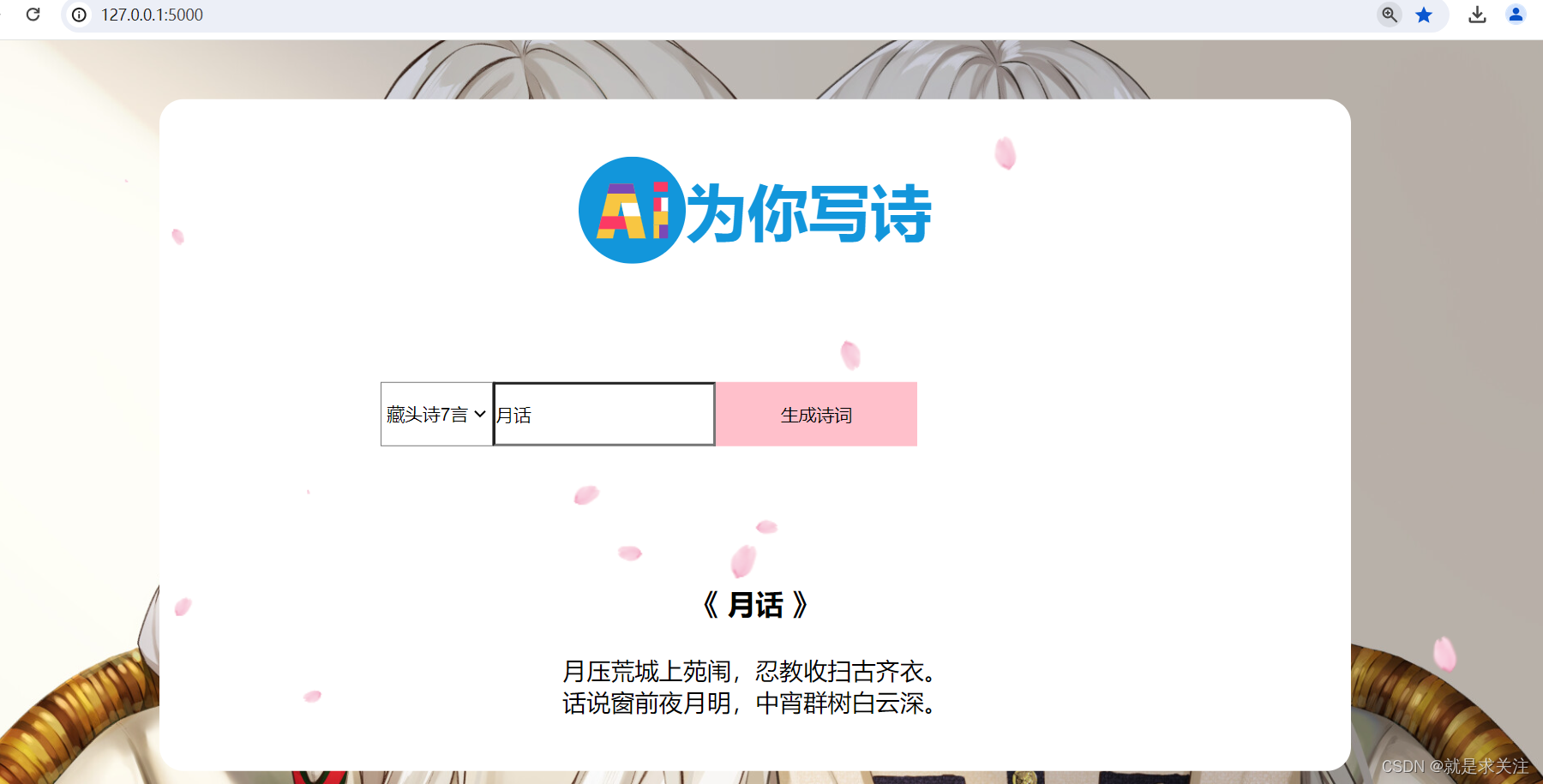
结合 Flask 框架的 Web 应用设计实现一个简单的 AI 诗歌生成器。在该代码中包含数据预处理:从文件中读取古诗数据,并进行预处理,包括去除特殊符号、筛选古诗长度等。将古诗转换为向量形式,每个字对应一个数字 ID。创建一个数据集类,用于按批次提取数据。使用 TensorFlow 定义了一个基于 LSTM 的 模型,用于生成古诗。定义生成古诗的函数:gen_head_poetry() 函数用于生成藏头诗,接受藏头和诗的类型(五言或七言)作为输入。gen_poetry() 函数用于随机生成古诗。在接收到请求时,根据请求的内容进行处理:如果请求是 POST 请求,则从表单中获取藏头和诗的类型,并生成对应的藏头诗或随机古诗。如果请求是 GET 请求,则从 URL 参数中获取相同的信息。最后,将生成的诗返回给客户端。实现界面如下:

该系统的功能包含用户选择框,让用户选择生成的诗歌类型(随机生成、藏头诗5言、藏头诗7言);一个输入框,让用户输入诗歌的名称或关键词,用于生成诗歌的内容。在用户点击生成按钮后,根据用户选择的诗歌类型和输入内容,生成的诗歌内容将在页面上展示出来,供用户阅读和分享。
藏头诗5言:
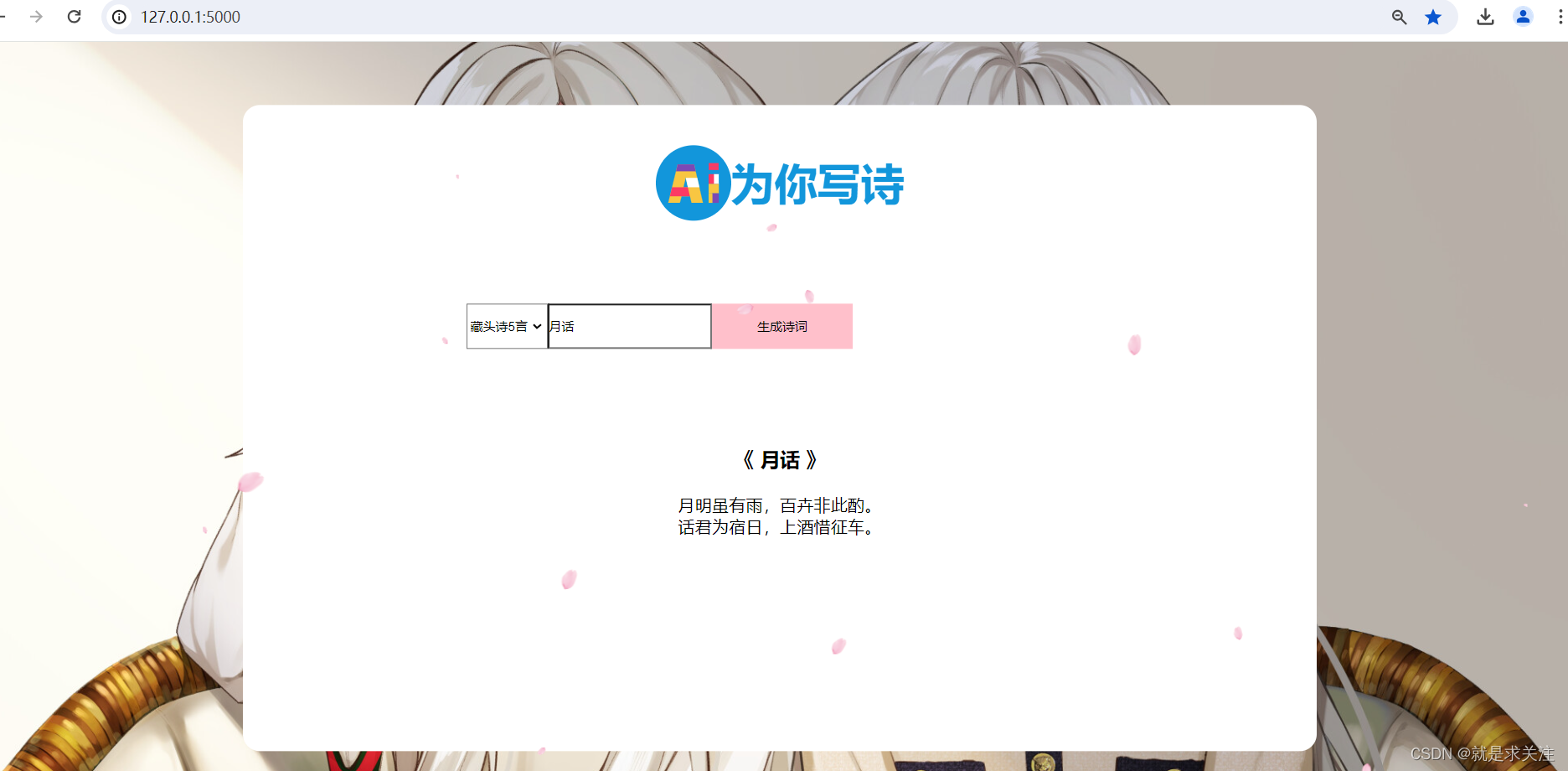
随机生成:

藏头诗7言: