节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
汇总合集
《大模型面试宝典》(2024版) 发布!
问题1、LLAMA 和 ChatGLM 的区别。

问题2、BatchNorm 和 LayerNorm 什么区别。
layernorm和batchnorm的区别:LN中同层神经元输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差;
BN中则针对不同神经元输入计算均值和方差,同一个batch中的输入拥有相同的均值和方差。
LN不依赖于batch的大小和输入sequence的深度,因此可以用于batchsize为1和RNN中对变长的输入sequence的normalize操作。
由于NLP中的文本输入一般为变长,所以使用layernorm更好。
问题3、Bert 的参数量是怎么决定的。
Bert(Bidirectional Encoder Representations from Transformers)的参数量由其模型结构以及隐藏层的大小、层数等超参数所决定。具体来说,Bert 模型由多个 Transformer Encoder 层组成,每个 Encoder 层包含多个注意力头以及前馈神经网络层。因此,Bert 的参数量主要由这些层的数量、每层的隐藏单元数、注意力头的数量等因素决定。
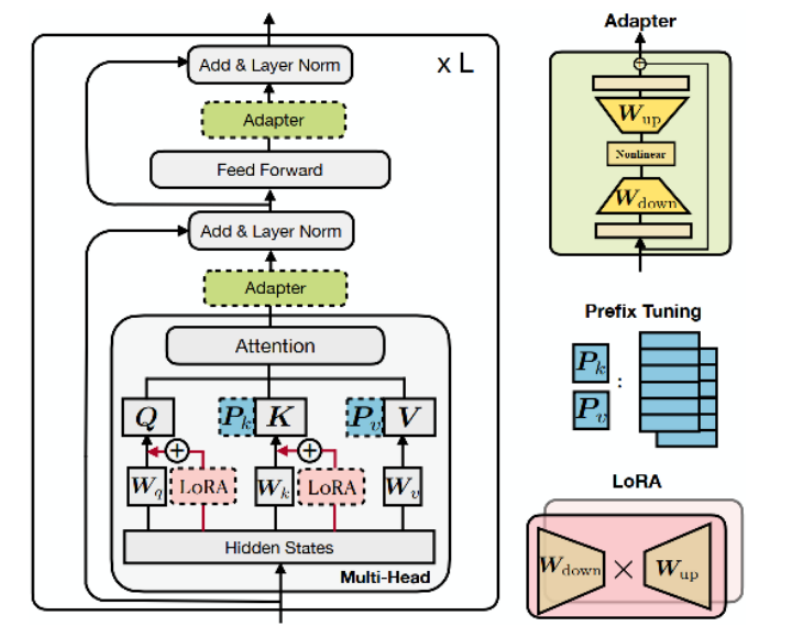
问题4、p tuning v2 和 prompt tuning 的区别。
Prompt tuning是之前其他论文提出的一种方法,通过冻结语言模型仅去调整连续的prompts,在参数量超过10B的模型上,效果追上了fine-tune,但是在normal-sized模型上表现不好,并且无法解决序列标注任务。针对这两个问题,作者提出了P-tuning v2。
P-Tuning V2在P-Tuning V1的基础上进行了下述改进:
-
在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层,这与Prefix Tuning的做法相同。这样得到了更多可学习的参数,且更深层结构中的Prompt能给模型预测带来更直接的影响。
-
去掉了重参数化的编码器。在 P-tuning v2 中,作者发现重参数化的改进很小,尤其是对于较小的模型,同时还会影响模型的表现。
-
针对不同任务采用不同的提示长度。提示长度在提示优化方法的超参数搜索中起着核心作用。在实验中,我们发现不同的理解任务通常用不同的提示长度来实现其最佳性能,这与Prefix-Tuning中的发现一致,不同的文本生成任务可能有不同的最佳提示长度。
-
可选的多任务学习。先在多任务的Prompt上进行预训练,然后再适配下游任务。一方面,连续提示的随机惯性给优化带来了困难,这可以通过更多的训练数据或与任务相关的无监督预训练来缓解;另一方面,连续提示是跨任务和数据集的特定任务知识的完美载体。
问题5、多头注意力机制和单个注意力机制时间复杂度会变吗?
多头注意力机制和单个注意力机制的时间复杂度都是
O(n^2d),其中 n 是序列长度,d 是每个词向量的维度。因为注意力机制涉及计算注意力分数的所有词对,因此时间复杂度与序列长度的平方成正比。无论是多头还是单个注意力机制,时间复杂度都是相同的。
问题6、大模型微调过程中如何避免灾难性遗忘?
在微调大模型的过程中,确实可能会遇到灾难性遗忘的问题,即模型在优化某一特定任务时,可能会忘记之前学到的其他重要信息或能力。为了缓解这种情况,可以采用以下几种策略:
(1)重新训练:通过使用所有已知数据重新训练模型,可以使其适应数据分布的变化,从而避免遗忘。
(2)增量学习:增量学习是一种在微调过程中逐步添加新数据的方法。通过增量学习,大模型可以在不忘记旧知识的情况下学习新数据。
(3)知识蒸馏:知识蒸馏是一种将老模型的知识传递给新模型的方法。通过训练一个教师模型来生成数据标注或权重,然后将标注或权重传递给新模型进行训练,可以避免灾难性遗忘。
(4)正则化技术:限制模型参数的变化范围,从而减少遗忘,使得大模型在微调过程中保持稳定性。
(5)使用任务相关性数据:如果可能的话,尽量使用与原始任务相关或相似的数据进行微调。这样,模型在优化新任务时,更容易与先前学到的知识建立联系。
技术交流
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了算法岗面试与技术交流群, 想要进交流群、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2040。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:技术交流
方式②、添加微信号:mlc2040,备注:技术交流+CSDN
用通俗易懂的方式讲解系列
-
重磅来袭!《大模型面试宝典》(2024版) 发布!
-
重磅来袭!《大模型实战宝典》(2024版) 发布!
-
用通俗易懂的方式讲解:不用再找了,这是大模型最全的面试题库
-
用通俗易懂的方式讲解:这是我见过的最适合大模型小白的 PyTorch 中文课程
-
用通俗易懂的方式讲解:一文讲透最热的大模型开发框架 LangChain
-
用通俗易懂的方式讲解:基于 LangChain + ChatGLM搭建知识本地库
-
用通俗易懂的方式讲解:基于大模型的知识问答系统全面总结
-
用通俗易懂的方式讲解:ChatGLM3 基础模型多轮对话微调
-
用通俗易懂的方式讲解:最火的大模型训练框架 DeepSpeed 详解来了
-
用通俗易懂的方式讲解:这应该是最全的大模型训练与微调关键技术梳理
-
用通俗易懂的方式讲解:Stable Diffusion 微调及推理优化实践指南
-
用通俗易懂的方式讲解:大模型训练过程概述
-
用通俗易懂的方式讲解:专补大模型短板的RAG
-
用通俗易懂的方式讲解:大模型LLM Agent在 Text2SQL 应用上的实践
-
用通俗易懂的方式讲解:大模型 LLM RAG在 Text2SQL 上的应用实践
-
用通俗易懂的方式讲解:大模型微调方法总结
-
用通俗易懂的方式讲解:涨知识了,这篇大模型 LangChain 框架与使用示例太棒了
-
用通俗易懂的方式讲解:掌握大模型这些优化技术,优雅地进行大模型的训练和推理!
-
用通俗易懂的方式讲解:九大最热门的开源大模型 Agent 框架来了