普拉萨梅什·加德卡尔
探索所有模型以选择最佳模型。

一、介绍:
烟雾探测器检测烟雾并触发警报以提醒他人。通常,它们存在于办公室、家庭、工厂等。通常,烟雾探测器分为两类:
Photoelectric Smoke Detector- 设备检测光强度,如果低于设定的阈值,则生成警报,因为烟雾会导致灰尘颗粒和烟雾导致光强度降低。Ionization Smoke Detector- 这种类型的探测器配备了一个电子电路,可以测量电流差,并在超过某个阈值时提醒用户。由于烟雾和管道颗粒导致离子不能自由移动,电路中的电流将减少。
使用提供的数据集,我们的目标是开发一个人工智能模型,如果检测到烟雾,可以准确地发出警报。我们的目标是根据其准确性比较许多分类模型,例如 KNN、逻辑回归等,直观地表示它们,并从中选择最好的。
数据是从这里获取的。
二、导入所需库
#Importing all essential libraries
import numpy as np
import pandas as pd
import seaborn as sns
from plotly.subplots import make_subplots
import matplotlib.pyplot as plt
import plotly.express as px
import missingno as msnofrom sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler#Importing Models
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression,SGDClassifier
from sklearn.ensemble import RandomForestClassifier,GradientBoostingClassifier,AdaBoostClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
from sklearn.dummy import DummyClassifier
from sklearn.tree import ExtraTreeClassifier from sklearn.metrics import accuracy_score
import timeimport warnings
warnings.filterwarnings('ignore')三、数据探索
3.1 特征分布
UTC- The time when the experiment was performed.Temperature- Temperature of Surroundings. Measured in CelsiusHumidity- The air humidity during the experiment.TVOC- Total Volatile Organic Compounds. Measured in ppb (parts per billion)eCo2- CO2 equivalent concentration. Measured in ppm (parts per million)Raw H2- The amount of Raw Hydrogen present in the surroundings.Raw Ethanol- 周围环境中存在的生乙醇量。Pressure-气压。以 hPa 为单位测量PM1.0- 直径小于1.0微米的颗粒物。PM2.5- 直径小于2.5微米的颗粒物。NC0.5- 直径小于0.5微米的颗粒物的浓度。NC1.0- 直径小于1.0微米的颗粒物的浓度。NC2.5- 直径小于2.5微米的颗粒物的浓度。CNT- 简单计数。Fire Alarm-(现实)如果发生火灾,则值为1,否则为0。
data = pd.read_csv('../input/smoke-detection-dataset/smoke_detection_iot.csv',index_col = False)
data.head()
数据前五行(来源:作者)
data.shape
data.describe().T.sort_values(ascending = 0,by = "mean").\
style.background_gradient(cmap = "BuGn")\
.bar(subset = ["std"], color ="red").bar(subset = ["mean"], color ="blue")
描述数据(来源:作者)
#Getting all the unique values in each feature
features = data.columns
for feature in features:print(f"{feature} ---> {data[feature].nunique()}")
所有变量的唯一值(来源:作者)
3.2 空值分布:
data.isna().sum()
空值计数(来源:作者)
msno.matrix(data)
空值可视化(来源:作者)
3.3 数据清理:
数据集中没有缺失值,这使我们能够更有效地分析数据并构建准确的预测模型。
如果数据集包含缺失值,请参考以下链接,帮助您进行数据清洗:
- 开始使用 Kaggle(英语:Kaggle)
- 极客的极客
尽管有些功能是无用的,并且会妨碍我们的模型。这些是:
UTC- 它仅指示实验进行的时间,因此不会影响结果。Unnamed :0- 这只是索引。CNT- 这是计数(类似于索引)。
由于这些属性是无用的,我们将删除它们。
del_features = ['Unnamed: 0','UTC','CNT']
for feature in del_features:data = data.drop(feature,axis = 1)
data.head()
删除不需要的功能(来源:作者)
3.4 ⭐重要观察
- 数据中总共有行和列。
6236016 - 数据不包含任何缺失值。
- 我们删除 、 属性,因为它们对我们毫无用处。
UTCUnnamed 0:CNT - 完成所有修改后,我们总共拥有将对其执行 EDA 的属性。
13 - 总共有 (62360 x 13) 个观测值。
810680
四、探索性数据分析
4.1 使用目标变量进行特征分析
sns.set_style("whitegrid")
sns.histplot(data['Fire Alarm'])
Histogram of Frequency (Source: Author)
plt.figure(figsize = (6,6))
sns.kdeplot(data = data,x = 'TVOC[ppb]')
Probability Density Function (Source: Author)
4.2 HeatMap :
plt.figure(figsize = (12,12))
sns.heatmap(data.corr(),annot = True,cmap = 'GnBu')
热图(来源:作者)
4.3 ⭐重要观察:
- 考虑到相关性很高,我们可以这么说,并且相关性很高。
>=0.65PressureHumidity - 所有 和 彼此之间具有很高的相关性。
PM'sNC's - 的均值和中位数之间的差值非常高。这告诉我们存在许多异常值。
TVOCPM'sNC's - 和 是分类中非常重要的属性,因为目标变量的均值和中位数之间的差异非常大。
TVOCPM'sNC's
五、建模
5.1 数据预处理
X = data.copy()
X.drop('Fire Alarm',axis = 1,inplace = True)
y = data['Fire Alarm']X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,random_state=0)
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
X_test = ss.transform(X_test)5.2 模型实现:
models = [KNeighborsClassifier(),SGDClassifier(),LogisticRegression(),RandomForestClassifier(),
GradientBoostingClassifier(),AdaBoostClassifier(),BaggingClassifier(),
SVC(),GaussianNB(),DummyClassifier(),ExtraTreeClassifier()]Name = []
Accuracy = []
Time_Taken = []
for model in models:Name.append(type(model).__name__)begin = time.time()model.fit(X_train,y_train)prediction = model.predict(X_test)end = time.time()accuracyScore = accuracy_score(prediction,y_test)Accuracy.append(accuracyScore)Time_Taken.append(end-begin)Dict = {'Name':Name,'Accuracy':Accuracy,'Time Taken':Time_Taken}
model_df = pd.DataFrame(Dict)
model_df
Accuracy and Time Taken (Source: Author)
5.3 Accuracy vs Model:
model_df.sort_values(by = 'Accuracy',ascending = False,inplace = True)
fig = px.line(model_df, x="Name", y="Accuracy", title='Accuracy VS Model')
fig.show()
Accuracy Vs Model (Source: Author)
5.4 Time Taken vs Model:
model_df.sort_values(by = 'Time Taken',ascending = False,inplace = True)
fig = px.line(model_df, x="Name", y="Time Taken", title='Time Taken VS Model')
fig.show()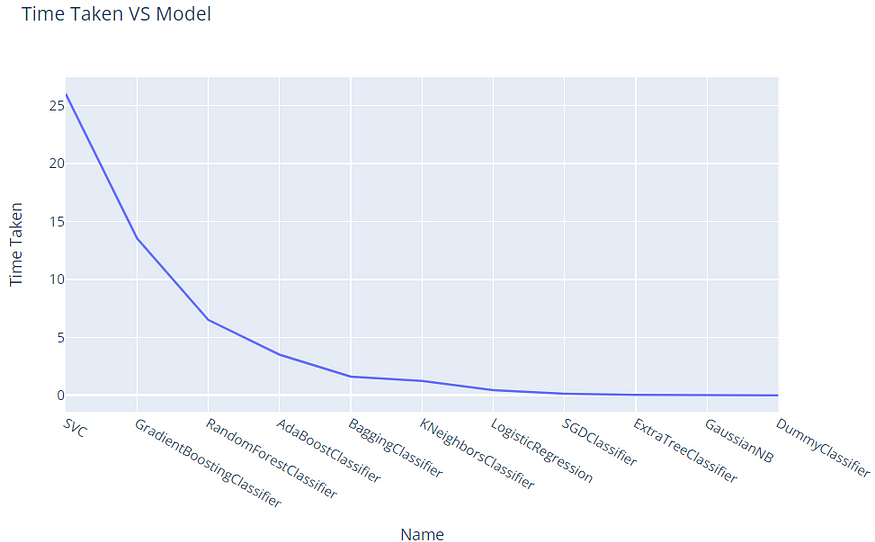
所用时间与模型(来源:作者)
六、结论
作为上述分析的结果,我们可以看到ExtraTreeClassifier需要更少的训练和执行时间,并提供最高级别的准确性。


![[国产MCU]-BL602开发实例-定时器](https://img-blog.csdnimg.cn/9492ba0c826d4d9e8a37d5a68282a75b.png#pic_center)