Neo4j系列导航:
neo4j安装及简单实践
cypher语法基础
cypher插入语法
cypher插入语法
cypher查询语法
cypher通用语法
cypher函数语法
neo4j索引及调优
neo4j java Driver等更多
1.依赖引入
<dependency><groupId>org.neo4j.driver</groupId><artifactId>neo4j-java-driver</artifactId><version>5.19.0</version>
</dependency>
2.简单使用
- 使用方法
Driver.executableQuery()执行Cypher语句。 - 不要硬编码或连接参数: 使用占位符并通过
. withparameters()方法将参数指定为映射。 - 需要释放资源: Driver和Session
package demo;import org.neo4j.driver.AuthTokens;
import org.neo4j.driver.GraphDatabase;public class App {public static void main(String... args) {// URI examples: "neo4j://localhost", "neo4j+s://xxx.databases.neo4j.io"final String dbUri = "<URI for Neo4j database>";final String dbUser = "<Username>";final String dbPassword = "<Password>";// 获取driver并自动释放try (var driver = GraphDatabase.driver(dbUri, AuthTokens.basic(dbUser, dbPassword))) {driver.verifyConnectivity();// 执行query语句var result = driver.executableQuery("MATCH (p:Person {age: $age}) RETURN p.name AS name").withParameters(Map.of("age", 42)) // 使用withParameters注入参数值,可以有效的防止sql注入且能利用缓存.withConfig(QueryConfig.builder().withDatabase("neo4j").build()).execute();}}
}
3.高级用法及性能优化
3.1.使用事务
对于更高级的用例,您可以运行事务。使用方法Session.executeRead()和Session.executeWrite()来运行托管事务。或者使用beginTransaction()直接获取事务,然后执行cypher语句
package demo;import java.util.Map;
import java.util.List;
import java.util.Arrays;
import java.util.concurrent.TimeUnit;import org.neo4j.driver.AuthTokens;
import org.neo4j.driver.GraphDatabase;
import org.neo4j.driver.QueryConfig;
import org.neo4j.driver.Record;
import org.neo4j.driver.RoutingControl;
import org.neo4j.driver.SessionConfig;
import org.neo4j.driver.TransactionContext;
import org.neo4j.driver.exceptions.NoSuchRecordException;public class App {// Create & employ 100 people to 10 different organizationspublic static void main(String... args) {final String dbUri = "<URI for Neo4j database>";final String dbUser = "<Username>";final String dbPassword = "<Password>";try (var driver = GraphDatabase.driver(dbUri, AuthTokens.basic(dbUser, dbPassword))) {try (var session = driver.session(SessionConfig.builder().withDatabase("neo4j").build())) {session.executeWrite(tx -> {// 创建一个Person节点tx.run("MERGE (p:Person {name: $name})", Map.of("name", name));var result = tx.run("""MATCH (o:Organization)RETURN o.id AS id, COUNT{(p:Person)-[r:WORKS_FOR]->(o)} AS employeesNORDER BY o.createdDate DESCLIMIT 1""");Record org = null;String orgId = null;int employeesN = 0;try {org = result.single();orgId = org.get("id").asString();employeesN = org.get("employeesN").asInt();} catch (NoSuchRecordException e) {System.out.printf("No orgs available, created %s.%n", orgId);}}}}
}3.2.执行查询结果中的ResultSummary
处理完来自查询的所有结果后,服务器通过返回执行summary来结束事务。它以ResultSummary对象的形式出现,它包含以下信息:
- 查询计数器(Query counters):在服务器上触发的查询发生了哪些变化
- 查询执行计划(Query execution plan):数据库将如何执行(或执行)查询
- 通知:服务器在运行查询时产生的额外信息
- 定时信息和查询请求摘要
当使用Driver.executableQuery()运行查询时,执行summary是默认返回对象的一部分,可通过.summary()方法检索。
var result = driver.executableQuery("""UNWIND ['Alice', 'Bob'] AS nameMERGE (p:Person {name: name})""").withConfig(QueryConfig.builder().withDatabase("neo4j").build()).execute();
var resultSummary = result.summary(); // mark-line
如果使用事务函数,则可以使用Result.consume()方法检索查询执行summary。
注意,一旦请求执行摘要,结果流就会耗尽。这意味着任何尚未处理的记录都将被丢弃。
try (var session = driver.session(SessionConfig.builder().withDatabase("neo4j").build())) {var resultSummary = session.executeWrite(tx -> {var result = tx.run("""UNWIND ['Alice', 'Bob'] AS nameMERGE (p:Person {name: name})""");return result.consume(); // mark-line});
}
3.2.1.查询计数器(Query counters)
方法ResultSummary.counters()返回查询触发的操作的计数器
var result = driver.executableQuery("""MERGE (p:Person {name: $name})MERGE (p)-[:KNOWS]->(:Person {name: $friend})""").withParameters(Map.of("name", "Mark", "friend", "Bob")).withConfig(QueryConfig.builder().withDatabase("neo4j").build()).execute();
var queryCounters = result.summary().counters(); // mark-line
System.out.println(queryCounters);// 输出结果
/*
InternalSummaryCounters{nodesCreated=2, nodesDeleted=0, relationshipsCreated=1, relationshipsDeleted=0,
propertiesSet=2, labelsAdded=2, labelsRemoved=0, indexesAdded=0, indexesRemoved=0, constraintsAdded=0,
constraintsRemoved=0, systemUpdates=0}
*/
counters()的返回值类型SummaryCounters还有两个布尔方法作为元计数器:
.containsUpdates(): 查询是否在其运行的数据库上触发任何写操作.containsSystemUpdates(): 查询是否更新了系统数据库
3.2.2.查询执行计划(Query execution plan)
EXPLAIN作为查询的前缀:
如果使用
EXPLAIN作为查询的前缀,服务器将返回用于运行查询的计划,但不会实际运行查询。然后,该计划通过方法ResultSummary.plan()获取plan对象,该计划包含将用于检索结果集的Cypher操作符列表。您可以使用这些信息来定位潜在的瓶颈或性能改进的空间(例如通过创建索引)。
var result = driver.executableQuery("EXPLAIN MATCH (p {name: $name}) RETURN p").withParameters(Map.of("name", "Alice")).withConfig(QueryConfig.builder().withDatabase("neo4j").build()).execute();
var queryPlan = result.summary().plan().arguments().get("string-representation"); // mark-line
System.out.println(queryPlan);// 输出结果
/*
Planner COST
Runtime PIPELINED
Runtime version 5.0
Batch size 128+-----------------+----------------+----------------+---------------------+
| Operator | Details | Estimated Rows | Pipeline |
+-----------------+----------------+----------------+---------------------+
| +ProduceResults | p | 1 | |
| | +----------------+----------------+ |
| +Filter | p.name = $name | 1 | |
| | +----------------+----------------+ |
| +AllNodesScan | p | 10 | Fused in Pipeline 0 |
+-----------------+----------------+----------------+---------------------+Total database accesses: ?
*/
使用关键字PROFILE作为查询的前缀:
如果您使用关键字
PROFILE作为查询的前缀,服务器将返回用于运行查询的执行计划,以及分析器统计信息。这包括所使用的操作符列表和关于每个中间步骤的附加分析信息。计划可以通过ResultSummary.profile()方法作为plan对象使用。注意,还运行了查询,因此结果对象还包含所有结果记录。
var result = driver.executableQuery("PROFILE MATCH (p {name: $name}) RETURN p").withParameters(Map.of("name", "Alice")).withConfig(QueryConfig.builder().withDatabase("neo4j").build()).execute();
var queryPlan = result.summary().profile().arguments().get("string-representation"); // mark-line
System.out.println(queryPlan);// 输出结果
/*
Planner COST
Runtime PIPELINED
Runtime version 5.0
Batch size 128+-----------------+----------------+----------------+------+---------+----------------+------------------------+-----------+---------------------+
| Operator | Details | Estimated Rows | Rows | DB Hits | Memory (Bytes) | Page Cache Hits/Misses | Time (ms) | Pipeline |
+-----------------+----------------+----------------+------+---------+----------------+------------------------+-----------+---------------------+
| +ProduceResults | p | 1 | 1 | 3 | | | | |
| | +----------------+----------------+------+---------+----------------+ | | |
| +Filter | p.name = $name | 1 | 1 | 4 | | | | |
| | +----------------+----------------+------+---------+----------------+ | | |
| +AllNodesScan | p | 10 | 4 | 5 | 120 | 9160/0 | 108.923 | Fused in Pipeline 0 |
+-----------------+----------------+----------------+------+---------+----------------+------------------------+-----------+---------------------+Total database accesses: 12, total allocated memory: 184
*/
3.2.3.通知(Notifications)
如果执行查询引发了任何,方法ResultSummary.notifications()返回来自服务器的通知列表。
这些包括建议性能改进建议、关于使用不推荐的特性的警告,以及关于Neo4j的次优使用的其他提示。每个通知都是一个notification对象。
var result = driver.executableQuery("""MATCH p=shortestPath((:Person {name: $start})-[*]->(:Person {name: $end}))RETURN p""").withParameters(Map.of("start", "Alice", "end", "Bob")).withConfig(QueryConfig.builder().withDatabase("neo4j").build()).execute();
var notifications = result.summary().notifications(); // mark-line
System.out.println(notifications);// 输出结果
/*
[code=Neo.ClientNotification.Statement.UnboundedVariableLengthPattern,title=The provided pattern is unbounded, consider adding an upper limit to the number of node hops.,description=Using shortest path with an unbounded pattern will likely result in long execution times. It is recommended to use an upper limit to the number of node hops in your pattern.,severityLevel=InternalNotificationSeverity[type=INFORMATION,level=800],rawSeverityLevel=INFORMATION,category=InternalNotificationCategory[type=PERFORMANCE],rawCategory=PERFORMANCE,position={offset=21, line=1, column=22}
]
*/
过滤通知:
默认情况下,服务器分析每个查询的所有类别和通知的严重性。从5.7版开始,您可以使用配置方法.withnotificationconfig (NotificationConfig)来限制您感兴趣的通知的严重性或类别,或者完全禁用它们。限制服务器允许发出的通知数量会略微提高性能。
NotificationConfig接口提供了
.enableminimumseverity (NotificationSeverity)、.disablecategories (Set<NotificationCategory>)和.disableallconfig()方法来设置配置。你可以在创建Driver实例时在Config对象上调用.withnotificationconfig(),也可以在创建会话时在SessionConfig对象上调用。
- 只允许警告(及以上)通知,但不允许提示或一般类别的通知
// at `Driver` level
var driver = GraphDatabase.driver(dbUri, AuthTokens.basic(dbUser, dbPassword),Config.builder().withNotificationConfig(NotificationConfig.defaultConfig() // mark-line.enableMinimumSeverity(NotificationSeverity.WARNING) // mark-line.disableCategories(Set.of(NotificationCategory.HINT, NotificationCategory.GENERIC)) // mark-line).build()
);// at `Session` level
var session = driver.session(SessionConfig.builder().withDatabase("neo4j").withNotificationConfig(NotificationConfig.defaultConfig() // mark-line.enableMinimumSeverity(NotificationSeverity.WARNING) // mark-line.disableCategories(Set.of(NotificationCategory.HINT, NotificationCategory.GENERIC)) // mark-line).build()
);
- 禁用所有通知
// at `Driver` level
var driver = GraphDatabase.driver(dbUri, AuthTokens.basic(dbUser, dbPassword),Config.builder().withNotificationConfig(NotificationConfig.disableAllConfig()) // mark-line.build()
);// at `Session` level
var session = driver.session(SessionConfig.builder().withDatabase("neo4j").withNotificationConfig(NotificationConfig.disableAllConfig()) // mark-line.build()
);
3.3.异步查询(非阻塞异步查询)
查询数据库和运行事务中的示例使用了同步形式的驱动程序。这意味着,当对数据库运行查询时,应用程序等待服务器检索所有结果并将其传输给驱动程序。对于大多数用例来说,这不是问题,但对于处理时间较长或结果集较大的查询,异步处理可能会加快应用程序的速度。
异步管理事务:
通过AsyncSession运行异步事务。该流程与常规事务类似,除了异步事务函数返回一个CompletionStage对象(可以进一步转换为CompletableFuture)。
package demo;import java.util.Map;
import java.util.concurrent.CompletionStage;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;import org.neo4j.driver.async.AsyncSession;
import org.neo4j.driver.AuthTokens;
import org.neo4j.driver.Driver;
import org.neo4j.driver.GraphDatabase;
import org.neo4j.driver.summary.ResultSummary;
import org.neo4j.driver.SessionConfig;public class App {public static void main(String... args) throws ExecutionException, InterruptedException {final String dbUri = "<URI for Neo4j database>";final String dbUser = "<Username>";final String dbPassword = "<Password>";//在同步和异步驱动程序的创建是相同的try (var driver = GraphDatabase.driver(dbUri, AuthTokens.basic(dbUser, dbPassword))) { ①driver.verifyConnectivity();var summary = printAllPeople(driver);// Block as long as necessary (for demonstration purposes)System.out.println(summary.get()); //等待未来完成所需的时间,然后返回其结果}}public static CompletableFuture<ResultSummary> printAllPeople(Driver driver) {/*通过提供AsyncSession.class作为Driver.session()的第一个参数来创建异步会话,该参数返回一个AsyncSession对象。请注意,异步会话可能不会作为try语句打开的资源,因为驱动程序无法知道何时关闭它们是安全的。*/var session = driver.session(AsyncSession.class, SessionConfig.builder().withDatabase("neo4j").build());var query = """UNWIND ['Alice', 'Bob', 'Sofia', 'Charles'] AS nameMERGE (p:Person {name: name}) RETURN p.name""";/* 对于常规事务,executewriteasync()和executeReadAsync()接受一个事务函数回调。在事务函数内部,使用. runasync()运行查询。每次查询运行都会返回一个CompletionStage。*/var summary = session.executeWriteAsync(tx -> tx.runAsync(query)// 可选择使用CompletionStage上的方法在异步运行器中处理结果。查询的结果集作为AsyncResultCursor可用,它实现了一组类似于// 同步事务处理结果的方法。内部对象类型与同步情况相同(即Record, ResultSummary)。.thenCompose(resCursor -> resCursor.forEachAsync(record -> {System.out.println(record.get(0).asString());}))).whenComplete((result, error) -> { // 查询完成后可选择运行操作,例如关闭驱动程序会话session.closeAsync();}).toCompletableFuture(); // CompletableFuture异步Future类型// 与同步事务相反,executewriteasync()和executeReadAsync()只返回结果摘要。结果处理和处理必须在异步运行程序内部完成。return summary;}
}
方法
.executereadasync()和.executewriteasync()已经取代了.readtransactionasync()和.writetransactionasync(),它们在版本5中已弃用并将在6.0版中删除。
3.4.协调并行事务
当使用Neo4j集群时,在大多数情况下默认强制因果一致性,这保证查询能够读取以前查询所做的更改。但是,对于并行运行的多个事务,默认情况下不会发生相同的情况。在这种情况下,可以使用bookmarks让一个事务在运行自己的工作之前等待另一个事务的结果在整个集群中传播。这不是必需的,如果您需要跨不同事务的临时一致性,则应该只使用bookmarks,因为等待书签可能会对性能产生负面影响。
bookmarks是表示数据库某些状态的令牌。通过将一个或多个bookmarks与查询一起传递,服务器将确保在建立所表示的状态之前不会执行查询。
3.4.1.使用executableQuery()创建Bookmarks
当使用.executablequery()查询数据库时,驱动程序为您管理bookmarks。在这种情况下,您可以保证后续查询可以读取之前的更改,而无需进一步操作。
driver.executableQuery("<QUERY 1>").execute();// subsequent .executableQuery() calls will be causally chained
driver.executableQuery("<QUERY 2>").execute(); // can read result of <QUERY 1>
driver.executableQuery("<QUERY 3>").execute(); // can read result of <QUERY 2>
要禁用bookmarks管理和因果一致性,请在查询配置中使用.withbookmarkmanager (null)。
driver.executableQuery("<QUERY>").withConfig(QueryConfig.builder().withBookmarkManager(null).build()).execute();
3.4.2.单个session中的Bootmarks
对于在单个session中运行的查询,会自动进行Bootmarks管理,因此您可以相信,一个会话中的查询是因果链接的。
try (var session = driver.session(SessionConfig.builder().withDatabase("neo4j").build())) {session.executeWriteWithoutResult(tx -> tx.run("<QUERY 1>"));session.executeWriteWithoutResult(tx -> tx.run("<QUERY 2>")); // can read QUERY 1session.executeWriteWithoutResult(tx -> tx.run("<QUERY 3>")); // can read QUERY 1,2
}
3.4.3.跨多个session的Bootmarks
如果您的应用程序使用多个session,您可能需要确保一个session在允许另一个session运行其查询之前完成了所有事务。
// 在下面的demo中,允许sessiononA和sessionB并发运行,而sessionC等待,直到它们的结果被传播。
// 这保证了sessionC想要操作的Person节点实际存在。
package demo;import java.util.Map;
import java.util.List;
import java.util.ArrayList;import org.neo4j.driver.AuthTokens;
import org.neo4j.driver.Bookmark;
import org.neo4j.driver.Driver;
import org.neo4j.driver.GraphDatabase;
import org.neo4j.driver.SessionConfig;
import org.neo4j.driver.TransactionContext;public class App {private static final int employeeThreshold = 10;public static void main(String... args) {final String dbUri = "<URI for Neo4j database>";final String dbUser = "<Username>";final String dbPassword = "<Password>";try (var driver = GraphDatabase.driver(dbUri, AuthTokens.basic(dbUser, dbPassword))) {createSomeFriends(driver);}}public static void createSomeFriends(Driver driver) {List<Bookmark> savedBookmarks = new ArrayList<>(); // to collect the sessions' bookmarks// 创建第一人并建立雇佣关系try (var sessionA = driver.session(SessionConfig.builder().withDatabase("neo4j").build())) {sessionA.executeWriteWithoutResult(tx -> createPerson(tx, "Alice"));sessionA.executeWriteWithoutResult(tx -> employ(tx, "Alice", "Wayne Enterprises"));// 使用Session.lastBookmarks()收集和组合来自不同会话的Bookmark,并将它们存储在Bookmark对象中savedBookmarks.addAll(sessionA.lastBookmarks());}// 创建第二人并建立雇佣关系try (var sessionB = driver.session(SessionConfig.builder().withDatabase("neo4j").build())) {sessionB.executeWriteWithoutResult(tx -> createPerson(tx, "Bob"));sessionB.executeWriteWithoutResult(tx -> employ(tx, "Bob", "LexCorp"));savedBookmarks.addAll(sessionB.lastBookmarks());}// 在上面提到的两个人之间建立友谊关系try (var sessionC = driver.session(SessionConfig.builder().withDatabase("neo4j").withBookmarks(savedBookmarks) // 使用它们通过withbookmarks()配置方法初始化另一个session.build())) {sessionC.executeWriteWithoutResult(tx -> createFriendship(tx, "Alice", "Bob"));sessionC.executeWriteWithoutResult(tx -> printFriendships(tx));}}// 创建人员节点static void createPerson(TransactionContext tx, String name) {tx.run("MERGE (:Person {name: $name})", Map.of("name", name));}// 创建到现有公司节点的雇佣关系// 这依赖于首先被创造的人。static void employ(TransactionContext tx, String personName, String companyName) {tx.run("""MATCH (person:Person {name: $personName})MATCH (company:Company {name: $companyName})CREATE (person)-[:WORKS_FOR]->(company)""", Map.of("personName", personName, "companyName", companyName));}// 在两个人之间建立友谊关系static void createFriendship(TransactionContext tx, String nameA, String nameB) {tx.run("""MATCH (a:Person {name: $nameA})MATCH (b:Person {name: $nameB})MERGE (a)-[:KNOWS]->(b)""", Map.of("nameA", nameA, "nameB", nameB));}// 检索和显示所有存在友谊关系的人的姓名static void printFriendships(TransactionContext tx) {var result = tx.run("MATCH (a)-[:KNOWS]->(b) RETURN a.name, b.name");while (result.hasNext()) {var record = result.next();System.out.println(record.get("a.name").asString() + " knows " + record.get("b.name").asString());}}
}
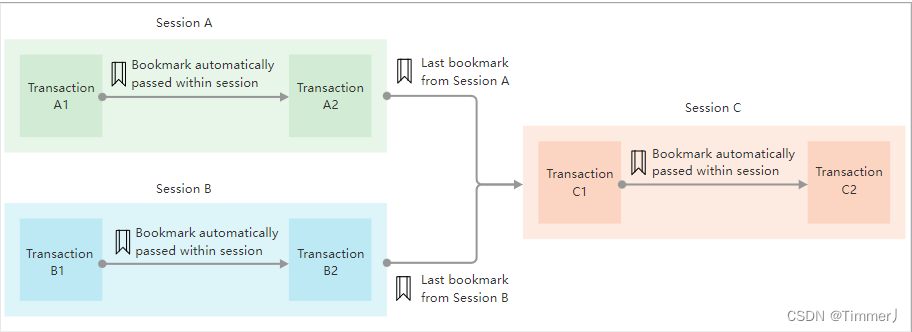
使用bootmark会
对性能产生负面影响,因为所有查询都被迫等待最新的更改在整个集群中传播。对于简单的用例,尝试在单个事务或单个会话中对查询进行分组。
3.4.4.混合使用executableQuery()和sessions
为了确保部分使用.ExecutableQuery()执行的事务和部分使用session执行的事务之间的因果一致性,您可以通过driver.executableQueryBookmarkManager()获取ExecutableQuery实例的默认bookmark管理器,并通过.withbookmarkmanager()配置方法将其传递给新session。这将确保所有工作都在相同的boomark管理器下执行,从而保持因果一致。
driver.executableQuery("<QUERY 1>").execute();
try (var session = driver.session(SessionConfig.builder().withBookmarkManager(driver.executableQueryBookmarkManager()) // mark-line.build())) {// 此session中的每个查询都将被因果链接(即,可以读取<QUERY 1>所写的内容)session.executeWriteWithoutResult(tx -> tx.run("<QUERY 2>"));
}
// 随后的executableQuery调用也将被因果链接(即,可以读取<QUERY 2>所写的内容)
driver.executableQuery("<QUERY 3>").execute();
3.5.深入查询机制
3.5.1.隐式(或自动提交)事务
这是运行Cypher查询的最基本和最有限的形式。驱动程序不会自动重试隐式事务,而对于使用.executablequery()和托管事务运行的查询,它会这样做。隐式事务应该仅在其他驱动程序查询接口不符合目的或用于快速原型时使用。
使用Session.run()运行隐式事务,它返回一个需要进行相应处理的Result对象:
import java.util.Map
import org.neo4j.driver.SessionConfigtry (var session = driver.session(SessionConfig.builder().withDatabase("neo4j").build())) {session.run("CREATE (a:Person {name: $name})", Map.of("name", "Licia"));
}
- 隐式事务最迟在会话销毁时提交,或者在同一会话内执行另一个事务之前提交。除此之外,对于在会话的生命周期中何时提交隐式事务并没有明确的保证。要确保提交隐式事务,可以对其结果调用
.consume()方法。 - 由于驱动程序无法确定
session .run()调用中的查询是否需要与数据库进行读或写会话,因此它默认为写。如果您的隐式事务仅包含读查询,则在创建会话时通过配置方法.withrouting (RoutingControl.READ)使驱动程序意识到这一点可以提高性能。 - 隐式事务是唯一可以用于
CALL{…}IN TRANSACTIONS查询的事务。
-
导入CSV文件:
使用Session.run()最常见的用例是使用LOAD CSVCypher子句将大型CSV文件导入数据库,并防止由于事务大小而导致的超时错误。将CSV数据导入Neo4j数据库:
import java.util.Map import org.neo4j.driver.SessionConfigtry (var session = driver.session(SessionConfig.builder().withDatabase("neo4j").build())) {var result = session.run("""LOAD CSV FROM 'https://data.neo4j.com/bands/artists.csv' AS lineCALL {WITH lineMERGE (:Artist {name: line[1], age: toInteger(line[2])})} IN TRANSACTIONS OF 2 ROWS""");var summary = result.consume();System.out.println(summary.counters()); }
虽然LOAD CSV很方便,但是将CSV文件的解析放到Java应用程序并避免LOAD CSV并没有错。实际上,将解析逻辑移到应用程序中可以让您更好地控制导入过程。有关高效的批量数据插入,请参见本文3.7
- 事务配置:
通过为Session.run()调用提供一个TransactionConfig对象作为可选的最后一个参数来进一步控制隐式事务。配置回调允许指定查询超时并将元数据附加到事务。有关更多信息,请参见本文3.1import java.util.Map import java.time.Duration import org.neo4j.driver.SessionConfig import org.neo4j.driver.TransactionConfigtry (var session = driver.session(SessionConfig.builder().withDatabase("neo4j").build())) {var result = session.run("CREATE (a:Person {name: $name})", Map.of("name", "John"),TransactionConfig.builder() // mark-line.withTimeout(Duration.ofSeconds(5)).withMetadata(Map.of("appName", "peopleTracker")).build()); }
3.5.2. 属性key、关系类型和标签中的动态值
一般来说,不应该将参数直接连接到查询中,而应该使用query parameters。然而,在某些情况下,您的查询结构可能会阻止在其所有部分使用参数。事实上,虽然参数可以用于字面量和表达式以及节点和关系id,但它们不能用于以下结构:
- 属性keys:如
MATCH (n) WHERE n.$param = 'something'是无效的 - 关系类型:如
MATCH (n)-[:$param]→(m)是无效的 - 标签:如
MATCH (n:$param)是无效的
- 对于这些查询,您
必须使用字符串连接。为了防止Cypher注入,您应该将动态值括在反引号中,并自己转义它们。注意,Cypher处理Unicode,因此也要注意Unicode字面值
\u0060。// 在连接前手动转义动态标签import org.neo4j.driver.QueryConfig;var label = "Person\\u0060n"; // convert \u0060 to literal backtick and then escape backticks var escapedLabel = label.replace("\\u0060", "`").replace("`", "``");var result = driver.executableQuery("MATCH (p:`" + escapedLabel + "` {name: $name}) RETURN p.name").withParameters(Map.of("name", "Alice")).withConfig(QueryConfig.builder().withDatabase("neo4j").build()).execute(); - 另一种避免字符串连接的解决方法是使用APOC过程,例如apoc.merge.node,它支持动态标签和属性键。
// 使用apop .merge.node创建一个带有动态标签/属性键的节点import org.neo4j.driver.QueryConfig;String propertyKey = "name"; String label = "Person";var result = driver.executableQuery("CALL apoc.merge.node($labels, $properties)").withParameters(Map.of("labels", List.of(label), "properties", Map.of(propertyKey, "Alice"))).withConfig(QueryConfig.builder().withDatabase("neo4j").build()).execute();如果你在Docker中运行Neo4j, APOC需要在启动容器时启用。参见Docker安装APOC
3.6.响应式流控制结果流
在响应式流中,消费者规定他们从查询中消费记录的速率,而驱动程序反过来管理从服务器请求记录的速率。
- 一个示例用例是一个应用程序从Neo4j服务器获取记录,并对每个记录进行一些非常耗时的后处理。如果允许服务器在有记录可用时立即将记录推送到客户端,那么客户端可能会因为大量条目而超载,而其处理仍然滞后。响应式API确保接收端不会被迫缓冲任意数量的数据。
- 驱动的响应式实现位于
reactivesreams子包中,依赖于Project Reactor的Reactor -core包。
对于那些已经在响应式编程风格中工作的应用程序,以及那些只有响应式工作流才能满足需求的应用程序,建议使用响应式API。对于所有其他情况,建议使用sync和async api。
3.6.1.安装依赖
要使用响应式特性,你需要首先将相关的依赖项添加到你的项目中
- 添加dependencyManagement:
<dependencyManagement><dependencies><dependency><groupId>io.projectreactor</groupId><artifactId>reactor-bom</artifactId><version>2023.0.2</version><type>pom</type><scope>import</scope></dependency></dependencies> </dependencyManagement> - 添加依赖包
<dependency><groupId>io.projectreactor</groupId><artifactId>reactor-core</artifactId> </dependency>
3.6.2.响应式查询
驱动程序的基本概念与同步情况相同,但是查询是通过一个ReactiveSession运行的,与查询相关的对象有一个响应的对应物和前缀。
-
具有响应式会话的管理事务
package demo;import java.util.List;import reactor.core.publisher.Flux; import reactor.core.publisher.Mono;import org.neo4j.driver.AuthTokens; import org.neo4j.driver.Driver; import org.neo4j.driver.GraphDatabase; import org.neo4j.driver.Record; import org.neo4j.driver.SessionConfig; import org.neo4j.driver.Value; import org.neo4j.driver.reactivestreams.ReactiveResult; import org.neo4j.driver.reactivestreams.ReactiveSession;public class App {public static void main(String... args) {final String dbUri = "<URI for Neo4j database>";final String dbUser = "<Username>";final String dbPassword = "<Password>";try (var driver = GraphDatabase.driver(dbUri, AuthTokens.basic(dbUser, dbPassword))) {driver.verifyConnectivity();Flux<Record> records = Flux.usingWhen( ①Mono.just(driver.session( ②ReactiveSession.class, ③SessionConfig.builder().withDatabase("neo4j").build())),rxSession -> Mono.fromDirect(rxSession.executeRead( ④tx -> Mono.fromDirect(tx.run("UNWIND range (1, 5) AS x RETURN x")) ⑤.flatMapMany(ReactiveResult::records) ⑥)),ReactiveSession::close ⑦);// block for demonstration purposesList<Value> values = records.map(record -> record.get("x")).collectList().block(); ⑧System.out.println(values);}} }① Flux. usingWhen(resourceSupplier, workerClosure, cleanupFunction)用于创建一个新会话,使用它运行查询,最后关闭它。
它将确保资源在需要的时间内处于活动状态,并允许指定在最后进行的清理操作。
②.usingWhen()以Publisher的形式接受一个资源提供者,因此会话创建被封装在Mono.just()调用中,该调用从任何值生成一个Mono。
③ session创建类似于异步情况,并且应用相同的配置方法。不同之处在于第一个参数必须是ReactiveSession.class,返回值是一个ReactiveSession对象。
④ reactivessession.executeread()方法运行一个read事务,并返回一个带有被调用者返回值的Publisher, Mono.fromDirect()将其转换为一个Mono。
⑤方法txt .run())返回一个Publisher<ReactiveResult>, mono.romdirect()将其转换为一个Mono。
⑥在返回最终结果之前,Mono.flatMapMany()从结果中检索记录,并将它们作为新的Flux返回。
⑦最后清理关闭session
⑧为了显示响应性工作流的结果,.block()等待流程完成,以便可以打印值。在实际的应用程序中,您不会阻止记录发布者,而是将其转发给您选择的框架,该框架将以有意义的方式处理它们。可以在同一个响应性会话中通过调用workerClosure中的executeRead/Write()来运行多个查询。
-
带有响应式会话的隐式事务
package demo;import java.util.List;import reactor.core.publisher.Flux; import reactor.core.publisher.Mono;import org.neo4j.driver.AuthTokens; import org.neo4j.driver.Driver; import org.neo4j.driver.GraphDatabase; import org.neo4j.driver.Record; import org.neo4j.driver.SessionConfig; import org.neo4j.driver.Value; import org.neo4j.driver.reactivestreams.ReactiveResult; import org.neo4j.driver.reactivestreams.ReactiveSession;public class App {// 此示例与前面的示例非常相似,只是它使用了隐式事务。public static void main(String... args) {final String dbUri = "<URI for Neo4j database>";final String dbUser = "<Username>";final String dbPassword = "<Password>";try (var driver = GraphDatabase.driver(dbUri, AuthTokens.basic(dbUser, dbPassword))) {driver.verifyConnectivity();Flux<Record> records = Flux.usingWhen(Mono.just(driver.session(ReactiveSession.class,SessionConfig.builder().withDatabase("neo4j").build())),rxSession -> Mono.fromDirect(rxSession.run("UNWIND range (1, 5) AS x RETURN x")).flatMapMany(ReactiveResult::records),ReactiveSession::close);// block for demonstration purposesList<Value> values = records.map(record -> record.get("x")).collectList().block();System.out.println(values);}} }
3.6.3.总是推迟会话创建
重要的在响应式编程中,直到Subscriber附加到Publisher上,Publisher才会出现。Publisher只是异步流程的抽象描述,但只有订阅行为才会触发整个链中的数据流。
出于这个原因,请始终注意将会话创建/销毁作为该链的一部分,而不要将会话创建与查询Publisher链分开。这样做可能会导致许多打开的会话,没有一个在工作,所有会话都在等待发布者使用它们,这可能会耗尽应用程序的可用会话数量。前面的例子使用
Flux.usingWhen()来解决这个问题。
ReactiveSession rxSession = driver.session(ReactiveSession.class);
Mono<ReactiveResult> rxResult = Mono.fromDirect(rxSession.run("UNWIND range (1, 5) AS x RETURN x"));
// until somebody subscribes to `rxResult`, the Publisher doesn't materialize, but the session is busy!
3.7.性能建议
3.7.1.始终指定目标数据库
使用.withdatabase()方法在所有查询中指定目标数据库,无论是在Driver.executableQuery()调用中还是在创建新session时。如果没有提供数据库,驱动程序必须向服务器发送一个额外的请求,以确定默认数据库是什么。对于单个查询,开销是最小的,但是对于数百个查询,开销会变得很大。
- 良好的实践:
driver.executableQuery("<QUERY>").withConfig(QueryConfig.builder().withDatabase("<DB NAME>").build()).execute();driver.session(SessionConfig.builder().withDatabase("<DB NAME>").build()); - 不好的实践:
driver.executableQuery("<QUERY>").execute();driver.session();
3.7.2.注意事务的成本
当通过.executablequery()或.executeread /Write()提交查询时,服务器自动将它们包装到一个事务中。这种行为确保数据库始终以一致的状态结束,而不管在事务执行期间发生了什么(断电、软件崩溃等)。
围绕大量查询创建一个安全的执行上下文显然会产生开销,如果驱动程序只是向服务器发送查询并希望它们能够通过,则不会出现这种开销。这种开销很小,但是会随着查询数量的增加而增加。由于这个原因,如果您的用例更看重吞吐量而不是数据完整性,那么您可以通过在单个(自动提交)事务中运行所有查询来获得进一步的性能。为此,您可以创建一个会话,并使用
session.run()运行所需的查询。
- 吞吐量高于数据完整性:
try (var session = driver.session(SessionConfig.builder().withDatabase("neo4j").build())) {for (int i=0; i<1000; i++) {session.run("<QUERY>");} } - 数据完整性优先于吞吐量:
for (int i=0; i<1000; i++) {driver.executableQuery("<QUERY>").execute();// or session.executeRead/Write() calls }
3.7.3.将读查询路由到集群readers
在集群中,将读查询路由到备用节点,你可以这样做:
- 使用
Driver.executableQuery()调用中的.withRouting(RoutingControl.READ)方法- 使用
Session.executeRead()代替Session.executeWrite()(用于托管事务)- 在创建新会话(用于显式事务)时使用.
withrouting (RoutingControl.READ)方法。
-
良好的实践:
import org.neo4j.driver.RoutingControl;driver.executableQuery("MATCH (p:Person) RETURN p").withConfig(QueryConfig.builder().withDatabase("neo4j").withRouting(RoutingControl.READ) // mark-line.build()).execute();try (var session = driver.session(SessionConfig.builder().withDatabase("neo4j").build())) {session.executeRead(tx -> { // mark-linevar result = tx.run("MATCH (p:Person) RETURN p");return result.list();}); } -
不好的实践:
// defaults to routing = writers driver.executableQuery("MATCH (p:Person) RETURN p").withConfig(QueryConfig.builder().withDatabase("neo4j").build()).execute();// don't ask to write on a read-only operation try (var session = driver.session(SessionConfig.builder().withDatabase("neo4j").build())) {session.executeWrite(tx -> {var result = tx.run("MATCH (p:Person) RETURN p");return result.list();}); }
3.7.4.创建索引
为经常过滤的属性创建索引。
例如:
如果您经常通过name属性查找Person节点,那么在Person.name上创建索引是有益的。可以使用create INDEX Cypher子句为节点和关系创建索引。
driver.executableQuery("CREATE INDEX person_name FOR (n:Person) ON (n.name)").execute();
3.7.5.分析查询
也就是使用EXPLAIN和PROFILE做查询分析,使用区别可参照本节3.2
- 使用PROFILE
对查询进行概要分析,以定位可以改进其性能的查询。可以通过在查询前加上profile来分析查询。服务器输出可以通过ResultSummary(本节3.2)对象的.profile()方法获得。var result = driver.executableQuery("PROFILE MATCH (p {name: $name}) RETURN p") // mark-line.withParameters(Map.of("name", "Alice")).withConfig(QueryConfig.builder().withDatabase("neo4j").build()).execute(); var queryPlan = result.summary().profile().arguments().get("string-representation"); // mark-line System.out.println(queryPlan);// 返回结果 /* Planner COST Runtime PIPELINED Runtime version 5.0 Batch size 128+-----------------+----------------+----------------+------+---------+----------------+------------------------+-----------+---------------------+ | Operator | Details | Estimated Rows | Rows | DB Hits | Memory (Bytes) | Page Cache Hits/Misses | Time (ms) | Pipeline | +-----------------+----------------+----------------+------+---------+----------------+------------------------+-----------+---------------------+ | +ProduceResults | p | 1 | 1 | 3 | | | | | | | +----------------+----------------+------+---------+----------------+ | | | | +Filter | p.name = $name | 1 | 1 | 4 | | | | | | | +----------------+----------------+------+---------+----------------+ | | | | +AllNodesScan | p | 10 | 4 | 5 | 120 | 9160/0 | 108.923 | Fused in Pipeline 0 | +-----------------+----------------+----------------+------+---------+----------------+------------------------+-----------+---------------------+Total database accesses: 12, total allocated memory: 184 */- 使用EXPLAIN
如果某些查询非常慢,以至于您甚至无法在合理的时间内运行它们,则可以在它们前面加上EXPLAIN而不是PROFILE。这将返回服务器将用于运行查询的计划,但不执行它。服务器输出可以通过ResultSummary对象的.plan()方法获得。
var result = driver.executableQuery("EXPLAIN MATCH (p {name: $name}) RETURN p") // mark-line.withParameters(Map.of("name", "Alice")).withConfig(QueryConfig.builder().withDatabase("neo4j").build()).execute(); var queryPlan = result.summary().plan().arguments().get("string-representation"); // mark-line System.out.println(queryPlan);// 返回结果 /* Planner COST Runtime PIPELINED Runtime version 5.0 Batch size 128+-----------------+----------------+----------------+---------------------+ | Operator | Details | Estimated Rows | Pipeline | +-----------------+----------------+----------------+---------------------+ | +ProduceResults | p | 1 | | | | +----------------+----------------+ | | +Filter | p.name = $name | 1 | | | | +----------------+----------------+ | | +AllNodesScan | p | 10 | Fused in Pipeline 0 | +-----------------+----------------+----------------+---------------------+Total database accesses: ? */ - 使用EXPLAIN
3.7.6.指定节点标签
在所有查询中指定节点标签, 这会让查询规划器更有效地工作,并在可用的情况下利用索引。要了解如何组合标签,请参见Cypher→Label expressions。
- 良好的实践:
driver.executableQuery("MATCH (p:Person|Animal {name: $name}) RETURN p").withParameters(Map.of("name", "Alice")).withConfig(QueryConfig.builder().withDatabase("neo4j").build()).execute();try (var session = driver.session(SessionConfig.builder().withDatabase("neo4j").build())) {session.run("MATCH (p:Person|Animal {name: $name}) RETURN p", Map.of("name", "Alice")); } - 不好的实践:
driver.executableQuery("MATCH (p {name: $name}) RETURN p").withParameters(Map.of("name", "Alice")).withConfig(QueryConfig.builder().withDatabase("neo4j").build()).execute();try (var session = driver.session(SessionConfig.builder().withDatabase("neo4j").build())) {session.run("MATCH (p {name: $name}) RETURN p", Map.of("name", "Alice")); }
3.7.7.批量数据创建
在使用WITH和UNWIND Cypher子句创建大量记录时进行批处理查询,可以提高插入性能。
-
良好的实践: 提交一个包含所有节点的创建
// Generate a sequence of numbers int start = 1; int end = 10000; List<Map> numbers = new ArrayList<>(end - start + 1); for (int i=start; i<=end; i++) {numbers.add(Map.of("value", i)); }driver.executableQuery("""UNWIND $numbers AS nodeCREATE (:Number {value: node.value})""").withParameters(Map.of("numbers", numbers)).withConfig(QueryConfig.builder().withDatabase("neo4j").build()).execute(); -
不好的实践: 提交许多个单个创建
for (int i=1; i<=10000; i++) { driver.executableQuery("CREATE (:Number {value: $value})").withParameters(Map.of("value", i)).withConfig(QueryConfig.builder().withDatabase("neo4j").build()).execute(); }
将大量数据首次导入到新数据库的最有效方法是使用neo4j-admin数据库导入命令。
3.7.8.使用查询parameters
始终使用查询parameters(本节2.3),而不是硬编码或将值连接到查询中。除了防止Cypher注入之外,这还允许更好地利用数据库查询缓存。
-
良好的实践:
driver.executableQuery("MATCH (p:Person {name: $name}) RETURN p").withParameters(Map.of("name", "Alice")).withConfig(QueryConfig.builder().withDatabase("neo4j").build()).execute();try (var session = driver.session(SessionConfig.builder().withDatabase("neo4j").build())) {session.run("MATCH (p:Person {name: $name}) RETURN p", Map.of("name", "Alice")); } -
不好的实践:
driver.executableQuery("MATCH (p:Person {name: 'Alice'}) RETURN p").withConfig(QueryConfig.builder().withDatabase("neo4j").build()).execute(); // or String name = "Alice"; driver.executableQuery("MATCH (p:Person {name: '" + name + "'}) RETURN p").withConfig(QueryConfig.builder().withDatabase("neo4j").build()).execute();try (var session = driver.session(SessionConfig.builder().withDatabase("neo4j").build())) {session.run("MATCH (p:Person {name: 'Alice'}) RETURN p");// orString name = "Alice";session.run("MATCH (p:Person {name: '" + name + "'}) RETURN p"); }
3.7.9.并发
使用异步查询。(可参照本机3.3)
如果在应用程序中并行处理复杂且耗时的查询,这可能会对性能产生更大的影响,但如果运行许多简单的查询,则影响不大。
3.7.10.仅在需要时使用MERGE进行创建
Cypher子句MERGE对于数据创建很方便,因为当存在给定模式的精确克隆时,它允许避免重复数据。但是,它需要数据库运行两个查询:首先需要MATCH模式,然后才能CREATE模式(如果需要)。
如果已经知道要插入的数据是新的,请避免使用
MERGE而直接使用CREATE——这实际上可以减少数据库查询的数量。
3.7.11.过滤通知
过滤通知能加大执行性能,具体请参照本节3.2.3