NL2SQL基础系列(2):主流大模型与微调方法精选集,Text2SQL经典算法技术回顾七年发展脉络梳理
- Text-to-SQL(或者Text2SQL),顾名思义就是把文本转化为SQL语言,更学术一点的定义是:把数据库领域下的自然语言(Natural Language,NL)问题,转化为在关系型数据库中可以执行的结构化询语言(Structured Query Language,SQL),因此Text-to-SQL也可以被简写为NL2SQL。
- 输入:自然语言问题,比如“查询表t_user的相关信息,结果按id降序排序,只保留前10个数据”
- 输出:SQL,比如“SELECT * FROM t_user ORDER BY id DESC LIMIT 10”

1.常见大模型

-
Llama [paper] [code] [model]
- 2023年2月,Meta AI提出开源大模型Llama,有7b、13b、33b、65b共4种规模。
-
ChatGLM [paper] [code] [model]
- 2023年3月,清华大学提出了开源的双语大模型ChatGLM,基于GLM框架,参数规格为6b。
-
Alpaca [paper] [code] [model]
- 2023年3月,斯坦福大学提出基于Llama 7b模型微调的开源大模型Alpaca,有7b共1种规格,训练更简单和便宜。
-
Vicuna [paper] [code] [model]
- 2023年3月,UC伯克利大学联合CMU、斯坦福大学提出的开源大模型Vicuna,有7b、13b共2种规格。
-
WizardLM [paper] [code] [model]
- 2023年4月,北京大学和微软提出进化指令大模型WizardLM,有7b、13b、30b共3种规格,2023年6月,提出了数学领域的大模型WizardMath,2023年8月提出了代码领域的大模型WizardCoder。
-
Falcon [paper] [code] [model]
- 2023年6月, 阿联酋提出了大模型Falcon,这是一种仅在网络数据集上训练的开源大模型,具有 1b、7b、40b和180b四个参数规范。值得注意的是,其中Falcon 40B的性能超过了LLaMA 65B。
-
ChatGLM2[paper] [code] [model]
- 2023年6月,清华大学提出了ChatGLM的第二代版本ChatGLM 2,规范为6b,具有更强的性能、更长的上下文、更高效的推理和更开放的许可。
-
Baichuan-7b [code] [model]
- 2023年6月,百川智能提出Baichuan-7B,这是一个基于Transformer架构的开源大规模预训练语言模型,包含70亿个参数,训练了约1.2万亿个tokens。支持中文和英文,上下文窗口长度为4096。
-
Baichuan-13b [code] [model]
- 2023年7月,百川智能继Baichuan-7B之后,提出开源、可商用的大规模语言模型Baichuan-13B,有预训练版本(Baichuan-13B-Base)和对齐版本(Baichuan-13B-Chat)。
-
InternLM [paper] [code] [model]
- 2023年7月,上海人工智能实验室和商汤科技等提出了InternLM,开源了针对实际场景量身定制的7b和20b参数模型和聊天模型以及训练系统。
-
Llama 2 [paper] [code] [model]
- 2023年7月,Meta AI提出第二代Llama系列开源大模型Llama 2,和Llama 1相比,训练数据多40%,上下文长度翻倍,模型有7b、13b、34b、70b共4种规格,但是34b没有开源。
-
Code Llama [paper] [code] [model]
- 2023年8月,Meta AI 在 Llama 2 的基础上提出 Code LLama。Code Llama 在多个代码基准测试中达到了开放模型中最先进的性能。有基础模型 (Code Llama)、Python 专业化 (Code Llama - Python) 和指令跟踪模型(instruction-following models),每个模型都有 7B、13B 和 34B 参数。2024年1月,Meta AI开源CodeLLama-70b、CodeLLama-70b-Python和CodeLLama-70b-Instruct。
-
Qwen [paper] [code] [model]
- 2023年8月,阿里云提出大语言模型系列Qwen-7B(简称通义千问),在海量数据上进行预训练,包括网页文本、书籍、代码等,开源了两个版本Qwen-7B和Qwen-7B-Chat。 2023年9月,阿里云更新了Qwen-7B和Qwen-7B-Chat,并开源了Qwen-14B和Qwen-14B-Chat。2023年11月, 他们开源了Qwen-1.8B,Qwen-1.8B-Chat,Qwen-72B以及Qwen-72B-Chat.
-
Baichuan 2 [paper]
[code] [model]- 2023年9月,百川智能提出新一代开源大语言模型Baichuan 2,在2.6万亿个tokens的高质量语料上训练,有7B和13B的基础版和聊天版,以及4bits量化版聊天模型。

-
Phi-1.5 [paper] [model]
- 2023年9月,微软研究院提出开源语言模型phi-1.5,一个拥有1.3b个参数的Transformer,使用与phi-1相同的数据源进行训练,增加了由各种NLP合成文本组成的新数据源。当根据测试常识、语言理解和逻辑推理的基准进行评估时,phi-1.5在参数少于10b的模型中表现出近乎最先进的性能。2023年12月,他们提出了Phi-2,一个 2.7b参数的语言模型,展示了出色的推理和语言理解能力,展示了参数少于13b的基础语言模型中最先进的性能。
-
Mistral-7B [paper]
[code]
[model]- 2023年10月,Mistral-AI 公司提出开源 LLM Mistral 7B,这是一个具有7b参数的语言模型,旨在实现卓越的性能和效率。Mistral 7B 在所有评估基准中均优于开源的llama2 13B,在推理、数学和代码生成方面优于llama1-34B模型。他们还提供了一个经过微调以遵循指令的模型Mistral 7B–Instruct,该模型在人类和自动化基准测试上都超越了Llama2-13B-Chat。2023年12月,他们提出了开源LLM Mixtral-8x7B,一种预训练的生成式稀疏专家混合物,在大多数基准测试上优于Llama2 70B。
-
Deepseek [paper]
[code]
[model]- 2023年11月, DeepSeek-AI公司提出了开源LLM deepseek,它是在包含2万亿个中英文token的庞大数据集上从头开始训练的。同样,deepseek LLM主要有base和chat两大类,分别有7b和67b两种参数格式。论文中的数据显示,deepSeek LLM 67b 在一系列基准测试中都超越了LLaMA2 70b,特别是在代码、数学和推理领域。 此外,与GPT-3.5相比,DeepSeek LLM 67B Chat 表现出卓越的性能。
-
MiniCPM [paper]
[code]
[model]- 2024年2月, 面壁智能与清华大学自然语言处理实验室开源了大模型MiniCPM,这是一个系列端侧大模型,主体语言模型 MiniCPM-2B 仅有 24亿(2.4B)的非词嵌入参数量, 总计2.7B参数量。值得注意的是,经过 SFT 后,MiniCPM 在公开综合性评测集上,MiniCPM 与 Mistral-7B相近(中文、数学、代码能力更优),整体性能超越 Llama2-13B、MPT-30B、Falcon-40B 等模型。
MiniCPM是一系列端侧语言大模型,主体语言模型MiniCPM-2B具有2.4B的非词嵌入参数量。在综合性榜单上与Mistral-7B相近(中文、数学、代码能力更优),整体性能超越Llama2-13B、MPT-30B、Falcon-40B等模型。在当前最接近用户体感的榜单MTBench上,MiniCPM-2B也超越了Llama2-70B-Chat、Vicuna-33B、Mistral-7B-Instruct-v0.1、Zephyr-7B-alpha等众多代表性开源大模型。
我们将完全开源MiniCPM-2B的模型参数供学术研究和有限商用,以及训练过程中的所有Checkpoint和大部分非专有数据(需要一定时间准备)给模型机理研究。
- 基于MiniCPM-2B的指令微调与人类偏好对齐的MiniCPM-2B-SFT/DPO。
- 基于MiniCPM-2B的多模态模型MiniCPM-V,能力超越基于Phi-2的同参数级别多模态模型**。**
- MiniCPM-2B-SFT/DPO的Int4量化版MiniCPM-2B-SFT/DPO-Int4。
- 基于MLC-LLM、LLMFarm开发的MiniCPM手机端程序,文本及多模态模型均可在手机端进行推理。

局限性:
- 受限于模型规模,模型可能出现幻觉性问题。其中由于DPO模型生成的回复内容更长,更容易出现幻觉。我们也将持续进行MiniCPM模型的迭代改进;
- 为了保证在学术研究用途上模型的通用性,我们未对模型进行任何身份认同训练。同时由于我们用ShareGPT开源语料作为部分训练数据,模型可能会输出类似GPT系列模型的身份认同信息;
- 受限于模型规模,模型的输出受到提示词(prompt)的影响较大,可能多次尝试产生不一致的结果;
- 受限于模型容量,模型的知识记忆较不准确,后续我们将结合RAG方法来增强模型的知识记忆能力。
更多内容见官网
2.微调-大模型
-
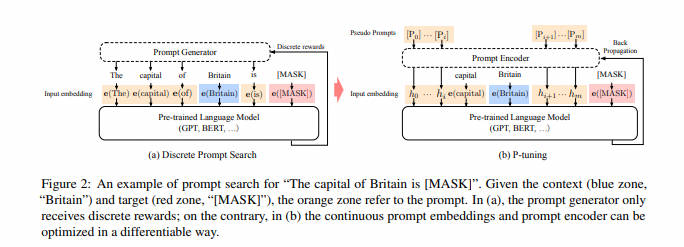
P-Tuning [paper] [code]
- 2021年3月,清华大学等提出了针对大模型微调方法P-Tuning,采用可训练的连续提示词嵌入,降低了微调成本。
-
LoRA [paper] [code]
- 2021年6月,微软提出的针对大模型微调的Low-Rank Adaptation(LoRA)方法,冻结预训练权重。
-
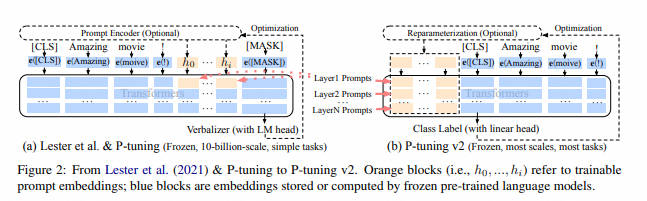
P-Tuning V2 [paper] [code]
- 2021年10月,清华大学提出了P-Tuning的改进版本P-Tuning V2,性能更优。
-
RLHF [paper] [code]
- 2022年12月,OpenAI使用RLHF方法训练ChatGPT,利用人类反馈信号直接优化语言模型,表现优异。
-
RRHF [paper] [code]
- 2023年4月,阿里巴巴提出了一种新的学习范式称为RRHF(Rank Responses to Align Language Models with Human Feedback without tears),可以像微调一样轻松调整并实现PPO算法在HH数据集中的性能。

-
QLoRA [paper] [code]
- 2023年5月,华盛顿大学基于冻结的4bit量化模型,结合LoRA方法训练,进一步降低了微调门槛。

-
RLTF [paper] [code]
- 2023年7月,腾讯提出了RLTF(Reinforcement Learning from Unit Test Feedback),这是一种新颖的online强化学习框架,具有多粒度的单元测试反馈,用于细化code LLMs。

-
RRTF [paper]
- 2023年7月,华为提出RRTF(Rank Responses toalign Test&Teacher Feedback)。与 RLHF 相比,RRHF可以有效地将语言模型的输出概率与人类偏好对齐,调优期间只需要1-2个模型,并且在实现、超参数调优和训练方面比PPO更简单。

-
RLAIF [paper]
- 2023年9月,谷歌提出了RLAIF(来自AI反馈的强化学习RL),这是一种由现成的LLM代替人类来标记偏好的技术。他们发现RLHF和 RLAIF方法在摘要任务上取得了相似的结果。

3.经典小模型
- (2023-arXiv, None) MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL
[paper]
[code]

- (2023-arXiv, None) DBCᴏᴘɪʟᴏᴛ: Scaling Natural Language Querying to Massive Databases
[paper]
[code]

- (2023-arXiv, None) Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation
[paper]
[code]
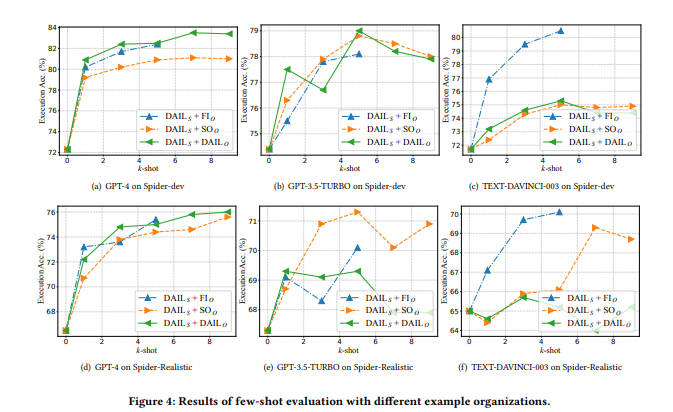
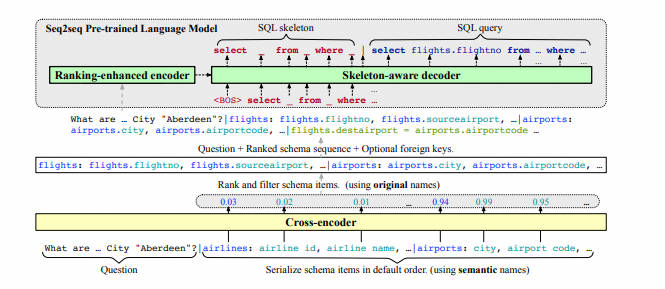
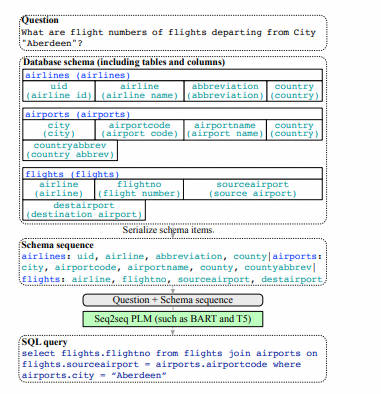
- (2023-AAAI 2023, CCF-A) RESDSQL: Decoupling Schema Linking and Skeleton Parsing for Text-to-SQL
[paper]
[code]
-
(2023-arXiv, None) Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs
[paper]
[code] -
(2023-arXiv, None) DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction
[paper]
[code] -
(2023-arXiv, None) A comprehensive evaluation of ChatGPT’s zero-shot Text-to-SQL capability
[paper]
[code] -
(2023-ICLR, CCF-A) Binding Language Models in Symbolic Languages
[paper]
[code] -
(2023-SIGMOD, CCF-A) Few-shot Text-to-SQL Translation using Structure and Content Prompt Learning
[paper]
[code] -
(2023-ICASSP, CCF-B) T5-SR: A Unified Seq-to-Seq Decoding Strategy for Semantic Parsing
[paper] -
(2022-ACL, CCF-A) S2SQL: Injecting Syntax to Question-Schema Interaction Graph Encoder for Text-to-SQL Parsers
[paper] -
(2022-NAACL, CCF-B) SeaD: End-to-end Text-to-SQL Generation with Schema-aware Denoising
[paper] -
(2022-EMNLP, CCF-B) STAR: SQL Guided Pre-Training for Context-dependent Text-to-SQL Parsing
[paper]
[code] -
(2022-EMNLP, CCF-B) RASAT: Integrating Relational Structures into Pretrained Seq2Seq Model for Text-to-SQL
[paper]
[code] -
(2022-EMNLP, CCF-B) CQR-SQL: Conversational Question Reformulation Enhanced Context-Dependent Text-to-SQL Parsers
[paper] -
(2022-ACL, CCF-A) HIE-SQL: History Information Enhanced Network for Context-Dependent Text-to-SQL Semantic Parsing
[paper] -
(2022-arXiv, None) Importance of Synthesizing High-quality Data for Text-to-SQL Parsing
[paper] -
(2021-ACL, CCF-A) Decoupled Dialogue Modeling and Semantic Parsing for Multi-Turn Text-to-SQL
[paper] -
(2021-arXiv, None) Pay More Attention to History: A Context Modelling Strategy for Conversational Text-to-SQL
[paper]
[code] -
(2021-ICLR, CCF-A) SCORE: Pre-training for Context Representation in Conversational Semantic Parsing
[paper] -
(2021-DASFAA, CCF-B) An Interactive NL2SQL Approach with Reuse Strategy
[paper] -
(2021-NAACL, CCF-B) Structure-Grounded Pretraining for Text-to-SQL
[paper] -
(2021-EMNLP, CCF-B) PICARD:Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models
[paper]
[code] -
(2021-ICLR, CCF-A) GraPPa: Grammar-Augmented Pre-Training for Table Semantic Parsing
[paper]
[code] -
(2021-ACL, CCF-A) LGESQL: Line Graph Enhanced Text-to-SQL Model with Mixed Local and Non-Local Relations
[paper]
[code] -
(2020-EMNLP, CCF-B) Bridging Textual and Tabular Data for Cross-Domain Text-to-SQL Semantic Parsing
[paper]
[code] -
(2020-ACL, CCF-A) TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data
[paper]
[code] -
(2020-ACL, CCF-A) RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers
[paper]
[code] -
(2020-EMNLP, CCF-B) Mention Extraction and Linking for SQL Query Generation
[paper] -
(2020-EMNLP, CCF-B) IGSQL: Database Schema Interaction Graph Based Neural Model for Context-Dependent Text-to-SQL Generation
[paper]
[code] -
(2020-arXiv, None) Hybrid Ranking Network for Text-to-SQL
[paper]
[code] -
(2019-arXiv, None) X-SQL: reinforce schema representation with context
[paper] -
(2019-EMNLP, CCF-B) Global Reasoning over Database Structures for Text-to-SQL Parsing
[paper]
[code] -
(2019-EMNLP, CCF-B) Editing-Based SQL Query Generation for Cross-Domain Context-Dependent Questions
[paper]
[code] -
(2019-ACL, CCF-A) Representing Schema Structure with Graph Neural Networks for Text-to-SQL Parsing
[paper]
[code] -
(2019-ACL, CCF-A) Towards Complex Text-to-SQL in Cross-Domain Database with Intermediate Representation
[paper]
[code] -
(2018-EMNLP, CCF-B) SyntaxSQLNet: Syntax Tree Networks for Complex and Cross-DomainText-to-SQL Task
[paper]
[code] -
(2018-NAACL, CCF-B) TypeSQL: Knowledge-based Type-Aware Neural Text-to-SQL Generation
[paper]
[code] -
(2017-arXiv, None) SQLNet: Generating Structured Queries From Natural Language Without Reinforcement Learning
[paper]
[code]
-
参考链接
-
Awesome Text2SQL:https://github.com/eosphoros-ai/Awesome-Text2SQL/blob/main/README.zh.md
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。