一、基本介绍
雪花算法是一种生成分布式ID的算法。此种算法由Twitter创建,并应用于推文的ID。
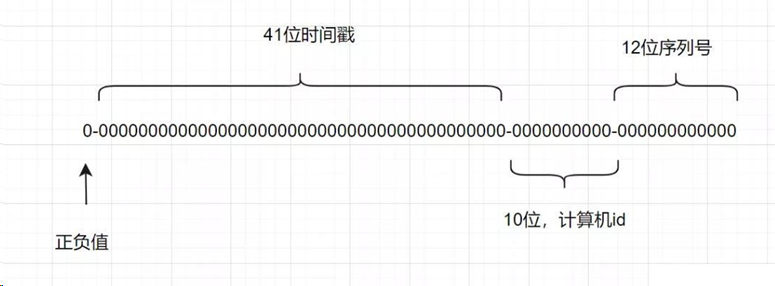
一个SnowFlake有64位:
• 符号位(1) :正数0,负数1。一般生成的ID 都为正数,所以默认为0.
• 时间戳(41):表示毫秒值。
• 数据编码(5) + 机器编码(5):计算机ID,防冲突
• 序列号(12):每台机器生成的ID序列号。
理论上,当机器编码和数据编码不变的情况下,可以生成2^53个ID,达到千万亿级别。
二、实现代码
public class SnowFlake {/*** 起始的时间戳*/private final static long START_STMP = 1480166465631L;/*** 每一部分占用的位数*/private final static long SEQUENCE_BIT = 12; //序列号占用的位数private final static long MACHINE_BIT = 5; //机器标识占用的位数private final static long DATACENTER_BIT = 5;//数据中心占用的位数/*** 每一部分的最大值*/private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);/*** 每一部分向左的位移*/private final static long MACHINE_LEFT = SEQUENCE_BIT;private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;private long datacenterId; //数据中心private long machineId; //机器标识private long sequence = 0L; //序列号private long lastStmp = -1L;//上一次时间戳public SnowFlake(long datacenterId, long machineId) {if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) {throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0");}if (machineId > MAX_MACHINE_NUM || machineId < 0) {throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");}this.datacenterId = datacenterId;this.machineId = machineId;}/*** 产生下一个ID** @return*/public synchronized long nextId() {long currStmp = getNewstmp();if (currStmp < lastStmp) {throw new RuntimeException("Clock moved backwards. Refusing to generate id");}if (currStmp == lastStmp) {//相同毫秒内,序列号自增sequence = (sequence + 1) & MAX_SEQUENCE;//同一毫秒的序列数已经达到最大if (sequence == 0L) {currStmp = getNextMill();}} else {//不同毫秒内,序列号置为0sequence = 0L;}lastStmp = currStmp;return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分| datacenterId << DATACENTER_LEFT //数据中心部分| machineId << MACHINE_LEFT //机器标识部分| sequence; //序列号部分}private long getNextMill() {long mill = getNewstmp();while (mill <= lastStmp) {mill = getNewstmp();}return mill;}private long getNewstmp() {return System.currentTimeMillis();}public static void main(String[] args) {SnowFlake snowFlake = new SnowFlake(2, 3);for (int i = 0; i < (1 << 12); i++) {System.out.println(snowFlake.nextId());}}
}
三、扩展改造:兼容JS短位数的53bit分布式ID生成器
使用原生的雪花算法其默认生成的是64bit长整型, 如果以ID和前端的JS进行交互时会出现精度丢失(最后两位数字变成00) 而导致最终系统报错: 找不到ID。究其原因是因为JS的Number类型精度最高只有53bit, 导致JS其最大安全值只有2^53 = 9007199254740992 。雪花算法生成的18位数字也就会超标了;
解决方法: 将返回的ID由Long类型转换为String:
- 使用@JsonSerialize注解,在相关类的属性上分别添加
- 配置消息转换器MappingJackson2HttpMessageConverter,将此消息转换器进行扩展
由于上两种方案都不满足当前系统的要求(前端会进行计算),所以不能使用上两种方案。
主动适配前端JS的number类型的最大精度,将原来由雪花算法生成的64bit的ID截取为53bit的ID。
对于前后台传参Long类型而言,JS内置有32位整数,而number类型的安全整数是53位。如果超过53位,则精度会丢失。如果后台传来一个64位的Long型整数,因为超过了53位,所以后台返回的值和前台获取的值会不一样。
最后我们根据目前的业务数据量发现,53bit的ID足够当下的使用。所以我们尝试改造雪花算法,缩短其长度。
改造后的雪花算法组成部分:符号位(1)+ 时间戳(41)+机器编码(5)+ 序列号(7)
理论上,当机器编码不变的情况下可以生成0-2^53个ID,百万亿级别。
四、缩短版雪花算法
public class ShortenSnowFlake {/*** 起始的时间戳*/private final static long START_STMP = 1480166465631L;/*** 每一部分占用的位数*/private final static long SEQUENCE_BIT = 7; //序列号占用的位数private final static long MACHINE_BIT = 5; //机器标识占用的位数/*** 每一部分的最大值*/private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);/*** 每一部分向左的位移*/private final static long MACHINE_LEFT = SEQUENCE_BIT;private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;private final static long TIMESTMP_LEFT = DATACENTER_LEFT;private long machineId; //机器标识private long sequence = 0L; //序列号private long lastStmp = -1L;//上一次时间戳public ShortenSnowFlake(long machineId) {if (machineId > MAX_MACHINE_NUM || machineId < 0) {throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");}this.machineId = machineId;}/*** 产生下一个ID** @return*/public synchronized long nextId() {long currStmp = getNewstmp();if (currStmp < lastStmp) {throw new RuntimeException("Clock moved backwards. Refusing to generate id");}if (currStmp == lastStmp) {//相同毫秒内,序列号自增sequence = (sequence + 1) & MAX_SEQUENCE;//同一毫秒的序列数已经达到最大if (sequence == 0L) {currStmp = getNextMill();}} else {//不同毫秒内,序列号置为0sequence = 0L;}lastStmp = currStmp;return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分| machineId << MACHINE_LEFT //机器标识部分| sequence; //序列号部分}private long getNextMill() {long mill = getNewstmp();while (mill <= lastStmp) {mill = getNewstmp();}return mill;}private long getNewstmp() {return System.currentTimeMillis();}public static void main(String[] args) {ShortenSnowFlake snowFlake = new ShortenSnowFlake(3);for (int i = 0; i < (1 << 7); i++) {System.out.println(snowFlake.nextId());}}
}
五、项目配置
由于在不同的业务场景下需要的雪花算法位数也不同,为了更加灵活使用,我们采用配置的形式。
①Nacos新增配置
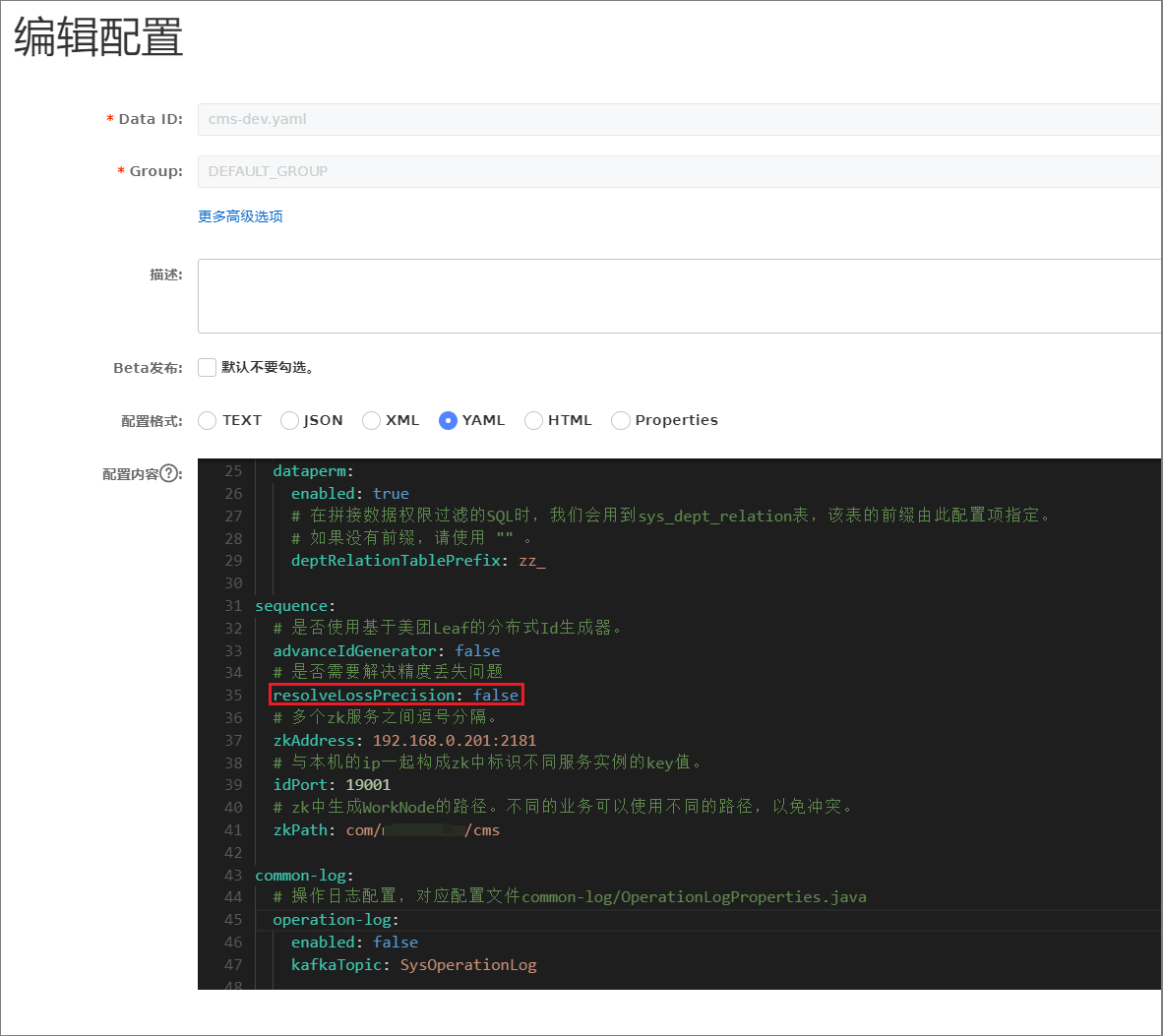
②绑定文件中新增属性
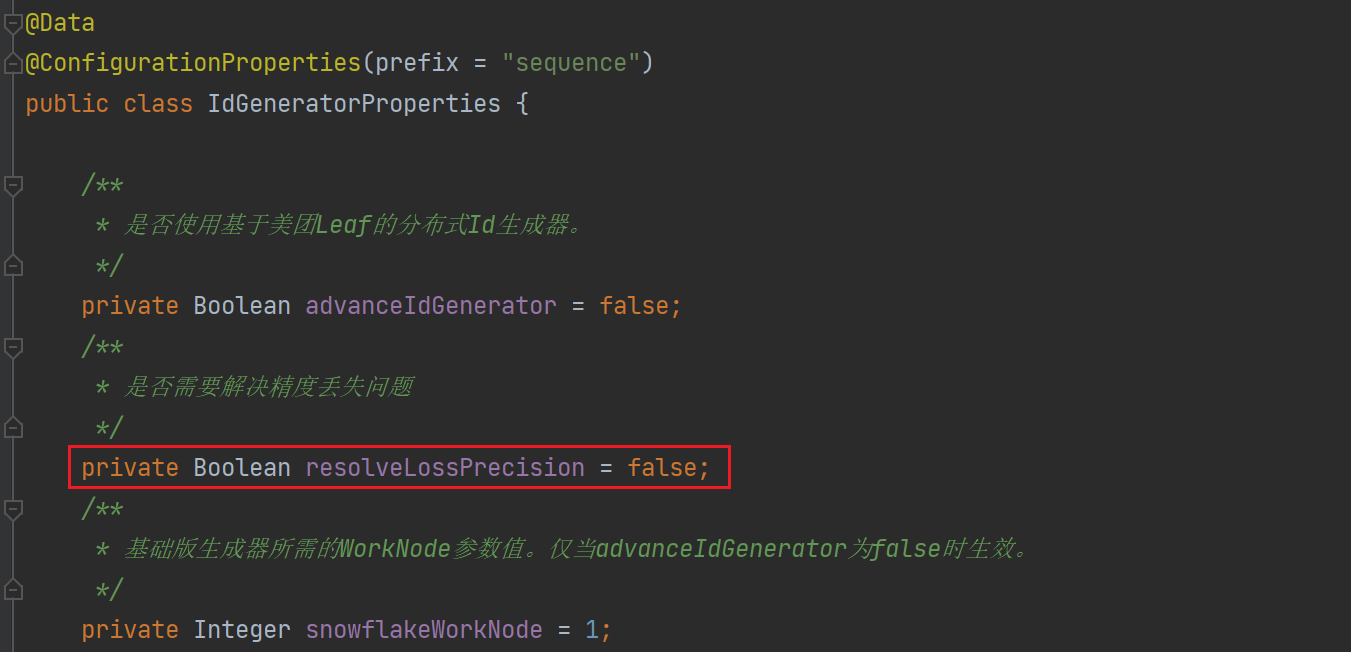
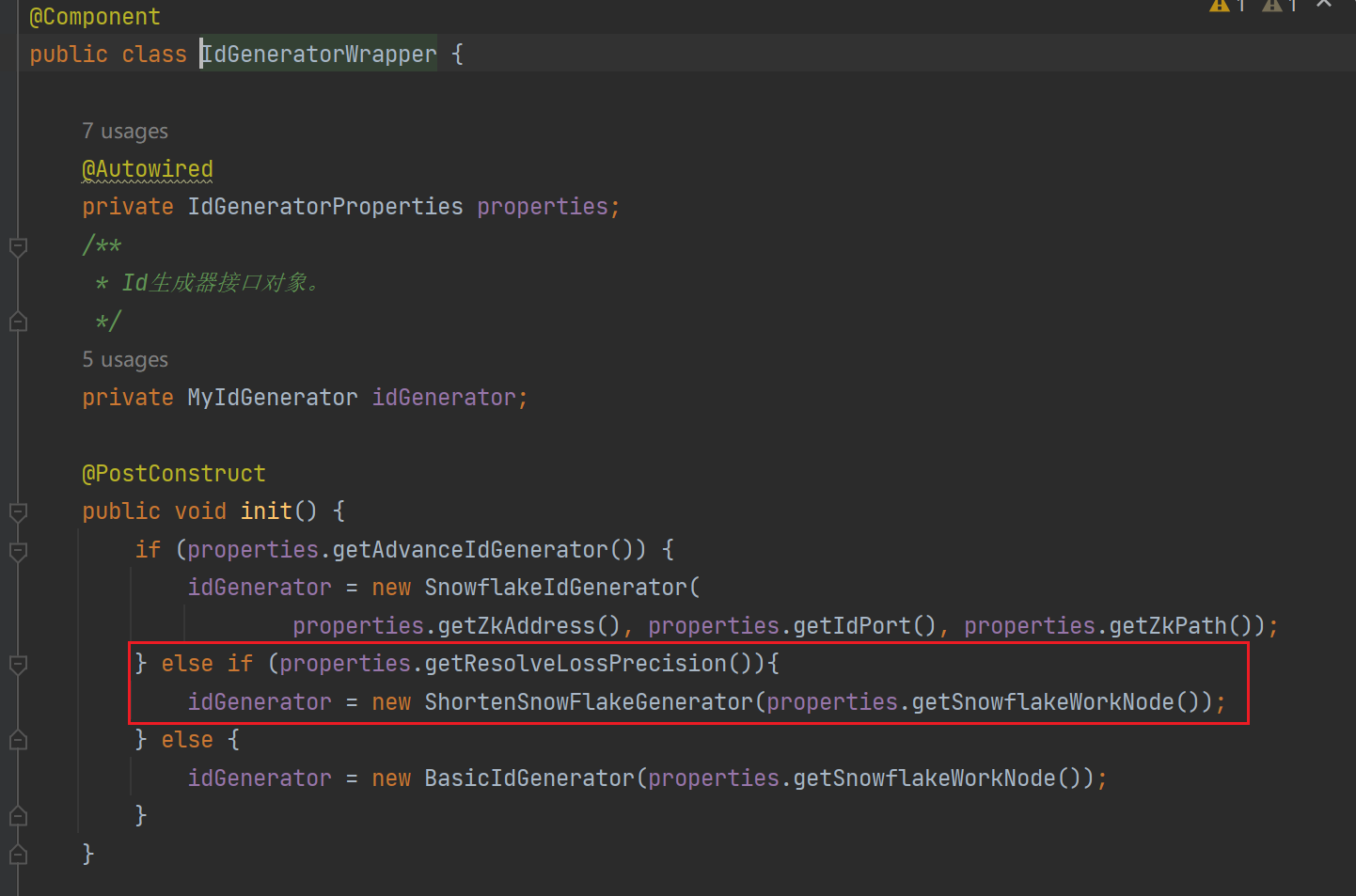
③自定义缩短版雪花算法生成器
public class ShortenSnowFlakeGenerator implements MyIdGenerator {private final ShortenSnowFlake shortenSnowFlake;/*** 构造函数。** @param workNode 工作节点。*/public ShortenSnowFlakeGenerator(Integer workNode) {shortenSnowFlake = new ShortenSnowFlake(workNode);}/*** 获取基于Snowflake算法的数值型Id。* 由于底层实现为synchronized方法,因此计算过程串行化,且线程安全。** @return 计算后的全局唯一Id。*/@Overridepublic long nextLongId() {return this.shortenSnowFlake.nextId();}/*** 获取基于Snowflake算法的字符串Id。* 由于底层实现为synchronized方法,因此计算过程串行化,且线程安全。** @return 计算后的全局唯一Id。*/@Overridepublic String nextStringId() {return this.shortenSnowFlake.nextIdStr();}
}
④改造初始化逻辑
参考资料
• java 雪花算法,同时解决超过前端 js 数字上限的问题
• Twitter雪花算法SnowFlake改造: 兼容JS截短位数的53bit分布式ID生成器
• 分布式主键生成设计策略