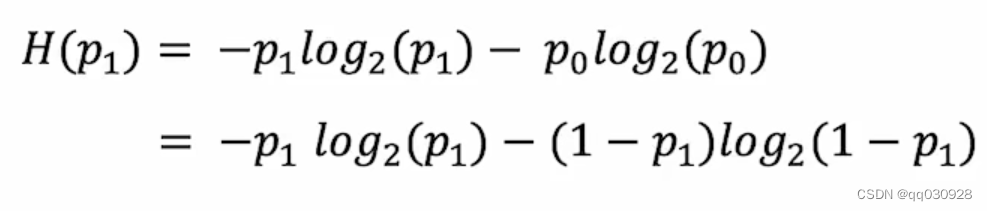一、决策树模型(Decision Tree Model)
 椭圆形代表决策节点(decison nodes),矩形节点代表叶节点(leaf nodes),方向上的值代表属性的值,
椭圆形代表决策节点(decison nodes),矩形节点代表叶节点(leaf nodes),方向上的值代表属性的值,
构建决策树的学习过程:
第一步:决定在根节点上的特征(也就是第一个分开样本的特征)
第二步:决定在内部节点上的特征(第二个、第三个分开样本的特征)
第三步:顺着特征写出特定的值的输出值
第一个问题:如何选择在每个节点上使用划分的特征呢?
尽量要保持最大的纯度(Maximize purity),纯度代表说,尽可能能直接完成分类(也就是尽量把这几个类的子集分开)
第二个问题:什么时候停止划分?
1. 当一个节点能百分百判断一个类的时候
2.当划分节点将会导致树超过最大深度时
3. 想避免过拟合时
二、测量纯度(Measuring purity)
熵:对一组数据不纯度的衡量
熵函数一般用H(p_1)表示

可以看到,当样本集是五五开的时候,这条曲线是最高的,也就是熵最大。
相反,如果样本集里都是猫或者都是狗的话,熵为0.
熵函数的方程: