若该文为原创文章,转载请注明原文出处。
基于TACO数据集,使用YOLOv8分割模型进行垃圾检测和识别,并在ATK-RK3568上部署运行。
一、环境
1、测试训练环境:AutoDL.
2、平台:rk3568
3、开发板: ATK-RK3568正点原子板子
4、环境:buildroot
5、虚拟机:正点原子提供的ubuntu 20
二、测试
个人电脑没有GPU,在AutoDL租了服务器,配置如下:将在上面测试并训练。
PyTorch 1.8.1
Python 3.8(ubuntu18.04)
CUDA 11.0
三、环境安装
1、使用conda创建虚拟环境
conda create -n yolov8 python=3.8
conda activate yolov82、 安装YOLOv8
# 拉取代码
git clone https://github.com/ultralytics/ultralytics
cd ultralyticspip install -e .三、下载TACO数据集
TACO 是一个包含在不同环境下(室内、树林、道路和海滩) 拍摄的垃圾图像数据集。
下载地址:
git clone https://github.com/pedropro/TACO.git进入TACO目录
运行脚本下载图像数据,默认下载官方数据集(annotations.json)是1500张。
python download.py下载成功后会在data目录下看到很多数据集
在TACO目录下创建demo_test.py,内容如下,可以查看数据集的相关信息:
# 参考demo.ipynb,查看官方数据集整体信息
# demo_test.py
import json
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()dataset_path = './data'
anns_file_path = dataset_path + '/' + 'annotations.json'# Read annotations
with open(anns_file_path, 'r') as f:dataset = json.loads(f.read())categories = dataset['categories']
anns = dataset['annotations']
imgs = dataset['images']
nr_cats = len(categories)
nr_annotations = len(anns)
nr_images = len(imgs)# Load categories and super categories
cat_names = []
super_cat_names = []
super_cat_ids = {}
super_cat_last_name = ''
nr_super_cats = 0
for cat_it in categories:cat_names.append(cat_it['name'])super_cat_name = cat_it['supercategory']# Adding new supercatif super_cat_name != super_cat_last_name:super_cat_names.append(super_cat_name)super_cat_ids[super_cat_name] = nr_super_catssuper_cat_last_name = super_cat_namenr_super_cats += 1print('Number of super categories:', nr_super_cats)
print('Number of categories:', nr_cats)
print('Number of annotations:', nr_annotations)
print('Number of images:', nr_images)在运行测试前先安装一些文件
pip install requirements.txt安装后执行python demo_test.py
执行后输出
总共1500张图像,有60个类别,4784个标注。
四、数据集处理
TACO数据集标注信息和COCO格式一样,我们需要将数据集划分,并转换成YOLO格式。
利用TACO仓库提供的detector/split_dataset.py,我们将TACO数据集的标注信息annotations.json划分成三份 train, val, test,生成对应的json文件。
python detector/split_dataset.py --dataset_dir ./data --test_percentage 5 --val_percentage 10 --nr_trials 1在TACO目录下执行上面命令, 将在data目录下生成annotations_0_train.json,annotations_0_val.json,annotations_0_test.json三个文件, 并且划分测试集占5%,评估数据占10%,剩下的是训练集数据。
由于YOLOv8分割模型训的标注格式如下:
<id> <x_1> <y_1> ... <x_n> <y_n>
具体的形式,可以参考yolov8-seg测试数据 COCO8-Seg数据集 。
所以使用下面代码把前面将划分的数据集的json文件,然后转换成yolo数据集要求的格式
在TACO目录 下创建taco2yolo.py,内容如下:
import os
from pycocotools.coco import COCO
import numpy as np
import tqdm
import argparse
import shutildef arg_parser():parser = argparse.ArgumentParser()parser.add_argument('--annotation_path', type=str,default='./data/annotations.json', help='dataset annotations')parser.add_argument('--save_path', type=str, default='./taco')parser.add_argument('--subset', type=str, default='train', required=False, help='which subset(train, val, test)')args = parser.parse_args()return argsif __name__ == '__main__':args = arg_parser()annotation_path = args.annotation_pathyolo_image_path = args.save_path + '/images/' + args.subsetyolo_label_path = args.save_path +'/labels/' + args.subsetos.makedirs(yolo_image_path, exist_ok=True)os.makedirs(yolo_label_path, exist_ok=True)data_source = COCO(annotation_file=annotation_path)# 类别IDcatIds = data_source.getCatIds()# 获取类别名称categories = data_source.loadCats(catIds)categories.sort(key=lambda x: x['id'])# 保存类别class_path = args.save_path + '/classes.txt'with open(class_path, "w") as file:for item in categories:file.write(f"{item['id']}: {item['name']}\n")#遍历每张图片img_ids = data_source.getImgIds()for index, img_id in tqdm.tqdm(enumerate(img_ids)):img_info = data_source.loadImgs(img_id)[0]file_name = img_info['file_name'].replace('/', '_')save_name = file_name.split('.')[0]height = img_info['height']width = img_info['width']save_label_path = yolo_label_path + '/' + save_name + '.txt'with open(save_label_path, mode='w') as fp:annotation_id = data_source.getAnnIds(img_id)if len(annotation_id) == 0:fp.write('')shutil.copy('data/{}'.format(img_info['file_name']), os.path.join(yolo_image_path, file_name))continueannotations = data_source.loadAnns(annotation_id)for annotation in annotations:category_id = annotation["category_id"]seg_labels = []for segmentation in annotation["segmentation"]:points = np.array(segmentation).reshape((int(len(segmentation) / 2), 2))for point in points:x = point[0] / widthy = point[1] / heightseg_labels.append(x)seg_labels.append(y)fp.write(str(category_id) + " " + " ".join([str(a) for a in seg_labels]) + "\n")shutil.copy('data/{}'.format(img_info['file_name']), os.path.join(yolo_image_path, file_name))执行下面生成各种数据集:
1、 测试集数据
python taco2yolo.py --annotation_path ./data/annotations_0_test.json --subset test运行出错:ModuleNotFoundError: No module named 'pycocotools'
安装:pip install pycocotools

2、评估集
python taco2yolo.py --annotation_path ./data/annotations_0_val.json --subset val
3、训练集
python taco2yolo.py --annotation_path ./data/annotations_0_train.json --subset train

会在当前目录下生成TACO目录结构如下:

五、模型训练
需要添加两个文件,数据集配置文件和模型配置文件。
1、新增数据集配置文件
在 ultralytics/cfg/datasets/下创建一个名称为taco-seg.yaml的文件,内容如下:
path: /root/TACO-master/taco # dataset root dir
train: images/train # train images (relative to 'path')
val: images/val # val images (relative to 'path')
test: images/test # test images (optional)# Classes
names:0: Aluminium foil1: Battery2: Aluminium blister pack3: Carded blister pack4: Other plastic bottle5: Clear plastic bottle6: Glass bottle7: Plastic bottle cap8: Metal bottle cap9: Broken glass10: Food Can11: Aerosol12: Drink can13: Toilet tube14: Other carton15: Egg carton16: Drink carton17: Corrugated carton18: Meal carton19: Pizza box20: Paper cup21: Disposable plastic cup22: Foam cup23: Glass cup24: Other plastic cup25: Food waste26: Glass jar27: Plastic lid28: Metal lid29: Other plastic30: Magazine paper31: Tissues32: Wrapping paper33: Normal paper34: Paper bag35: Plastified paper bag36: Plastic film37: Six pack rings38: Garbage bag39: Other plastic wrapper40: Single-use carrier bag41: Polypropylene bag42: Crisp packet43: Spread tub44: Tupperware45: Disposable food container46: Foam food container47: Other plastic container48: Plastic glooves49: Plastic utensils50: Pop tab51: Rope & strings52: Scrap metal53: Shoe54: Squeezable tube55: Plastic straw56: Paper straw57: Styrofoam piece58: Unlabeled litter59: Cigarette需要注意人的是PATH: 训练集路径
2、新增修改模型配置文件
在目录ultralytics/cfg/models/v8/ 下创建文件yolov8n-seg-taco.yaml,内容如下:
# Ultralytics YOLO 馃殌, AGPL-3.0 license
# YOLOv8-seg instance segmentation model. For Usage examples see https://docs.ultralytics.com/tasks/segment# Parameters
nc: 60 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-seg.yaml' will call yolov8-seg.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024]s: [0.33, 0.50, 1024]m: [0.67, 0.75, 768]l: [1.00, 1.00, 512]x: [1.00, 1.25, 512]# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Segment, [nc, 32, 256]] # Segment(P3, P4, P5)接下来使用命令训练模型:
yolo segment train data=taco-seg.yaml model=yolov8n-seg-taco.yaml epochs=100 batch=16 imgsz=640 yolo segment val model=runs/segment/train/weights/last.pt等待训练结束,会在runs/segment/train/weights目录下生成pt模型文件。
对训练的模型进行评估:
六、模型导出
部署到 ATK-RK3568用的是RKNN模型,需要先把pt模型转成ONNX在转成RKNN.
使用RK提供的airockchip/ultralytics_yolov8 仓库转换并导出。
拉取仓库:
在root目录下,拉取airockchip/ultralytics_yolov8
git clone https://github.com/airockchip/ultralytics_yolov8.git
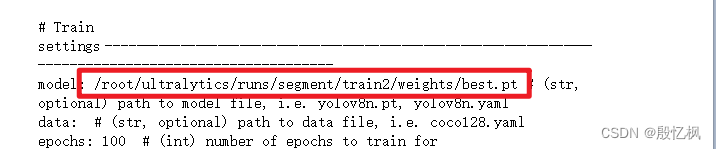
cd ultralytics_yolov8修改ultralytics/cfg/default.yaml文件:
修改这个文件主要是修改模型的地址
1、导出ONNX模型
先执行命令,主要是切换路径
export PYTHONPATH=./执行命令导出
python ultralytics/engine/exporter.py出错:ModuleNotFoundError: No module named 'onnx'
处理:pip install onnx

导出的onnx模型保存在best.pt模型路径下,名称为best.onnx,使用 Netron 查看下该模型的输出:
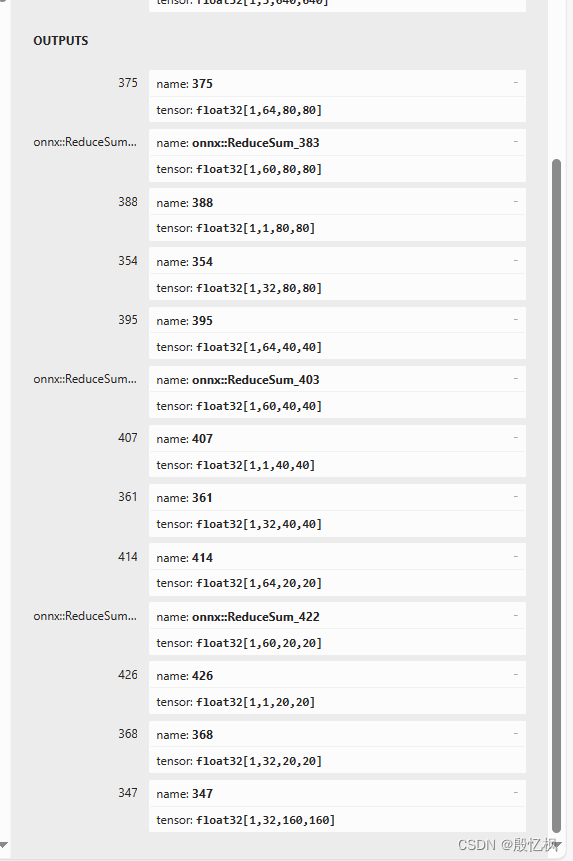
经过ultralytics_yolov8仓库导出的onnx模型,输入是13x640x640,输出总共13个,分为三个特征图相关(12个)和一个分割掩码(132x160x160)
以特征图8080为例,相关的输出为164x80x80、160x80x80、11x80x80、132x80x80。
-
第一个164x80x80与检测框坐标相关,经过相关后处理得到框的坐标(x1, y1, w, h);
-
第二个160x80x80,“80x80”表示检测框数量,“60”表示60个类别的置信度;
-
第三个11x80x80,表示检测框的60个类别的置信度的总和,用于在后处理加速过滤框;
-
第四个132x80x80是和分割掩码相关的权重。
2、转成RKNN
rknn模型是通过 toolkit2 转换的。环境搭建自行搭建。
参考简单的转换例程onnx2rknn.py
import os
import sys
import numpy as np
from rknn.api import RKNNDATASET_PATH = '../dataset/coco_subset_20.txt'
DEFAULT_QUANT = Truedef parse_arg():if len(sys.argv) < 3:print("Usage: python3 {} [onnx_model_path] [platform] [dtype(optional)] [output_rknn_path(optional)]".format(sys.argv[0]));print(" platform choose from [rk3562,rk3566,rk3568,rk3588]")print(" dtype choose from [i8, fp]")print("Example: python onnx2rknn.py ./yolov8n.onnx rk3588")exit(1)model_path = sys.argv[1]platform = sys.argv[2]do_quant = DEFAULT_QUANTif len(sys.argv) > 3:model_type = sys.argv[3]if model_type not in ['i8', 'fp']:print("ERROR: Invalid model type: {}".format(model_type))exit(1)elif model_type == 'i8':do_quant = Trueelse:do_quant = Falseif len(sys.argv) > 4:output_path = sys.argv[4]else:output_path = "./model/yolov8_seg_"+platform+".rknn"return model_path, platform, do_quant, output_pathif __name__ == '__main__':model_path, platform, do_quant, output_path = parse_arg()# Create RKNN objectrknn = RKNN(verbose=False)# Pre-process configprint('--> Config model')rknn.config(mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]], target_platform=platform)print('done')# Load modelprint('--> Loading model')ret = rknn.load_onnx(model=model_path)#ret = rknn.load_pytorch(model=model_path, input_size_list=[[1, 3, 640, 640]])if ret != 0:print('Load model failed!')exit(ret)print('done')# Build modelprint('--> Building model')ret = rknn.build(do_quantization=do_quant, dataset=DATASET_PATH)if ret != 0:print('Build model failed!')exit(ret)print('done')# Export rknn modelprint('--> Export rknn model')ret = rknn.export_rknn(output_path)if ret != 0:print('Export rknn model failed!')exit(ret)print('done')# 精度分析,,输出目录./snapshot#print('--> Accuracy analysis')#ret = rknn.accuracy_analysis(inputs=['./subset/000000052891.jpg'])#if ret != 0:# print('Accuracy analysis failed!')# exit(ret)#print('done')# Releaserknn.release()执行下面命令转成RKNN模型
python onnx2rknn.py best.onnx rk3568 i8七、部署测试
对yolov8-seg模型的后处理参考 rknn_model_zoo 的部署例程。
推理程序大致步骤是:
-
读取图像,初始化模型,图像预处理
-
模型推理
-
后处理(boxes解码和NMS以及mask的处理)
-
结果可视化或者保存到图像
测试参考前面文章自行测试。
测试结果

如有侵权,或需要完整代码,请及时联系博主。

![[html]一个动态js倒计时小组件](https://img-blog.csdnimg.cn/direct/8fdfcb8e781e406f914a686d4724b5b0.png)


![[Algorithm][双指针][查找总价格为目标值的两个商品][三数之和][四数之和]详细解读 + 代码实现](https://img-blog.csdnimg.cn/direct/0e89a206f7734d9196e5f423765aa3bc.png)