目录
前言
安全开发专栏
个人介绍
编写详情
1.1 了解结构
1.2 发起请求
1.2.1 请求头
1.2.2 进行请求
1.2.3 提取数据,并进行存储
方式一:
方式二:
1.3 完整代码(爬取一页)
1.4 突破注册会员限制批量采集(爬取指定数量页面)
总结
前言
主要还是围绕渗透测试的流程进行开发,一般在信息收集后,在渗透测试后,在发现通用型漏洞时,我们为了节省时间,可以通过写批量脚本来信息收集,然后使用poc来进行批量验证.
作为一个fofa工程师,那么我们当然是使用fofa进行信息搜集喽,刚好也借着这个机会熟悉一下fofa的API文档,为后面写利用工具做好铺垫,当然目前还是用不到API的,问就是用不起,所以只能写脚本突破注册会员限制进行信息爬取.
这里我们需要选定一个目标,这里就用我没有复现过的漏洞作为案例来写CVE-2019-2725 weblogic 未授权远程代码执行漏洞,选择目标后,我们如何对目标进行信息收集呢
安全开发专栏
安全开发实战![]() http://t.csdnimg.cn/Ba4Ru
http://t.csdnimg.cn/Ba4Ru
个人介绍
不知名普通本科院校软件大二入坑网络安全
刚入坑教育SRC不到两个月
获得过两张985,211的漏报送证书,和一张教育部的证书
参加过多个渗透实战项目,并取得不错的成绩
获得过CNVD原创事件型漏洞证书,多个cnvd编号
编写详情
如果只想使用脚本的师傅,可以直接点击目录1.4跳转到突破注册会员的脚本.
1.1 了解结构
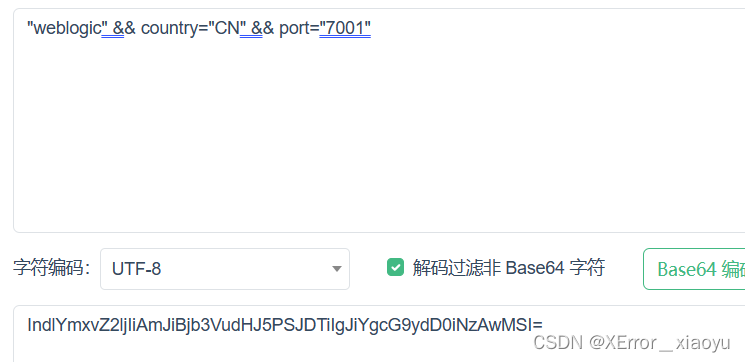
我们使用fofa进行搜索资产时,在返回结果页面,我们进行观察,首先是发现url处有信息返回,确定请求方式为get请求,其次,熟悉不熟悉编码方式的都没关系,都提示给你了,是base64,其中%3D其实是=号
那么就确定了,我们需要构造一下这个,当然不构造也可以,等后面直接把下图的url直接在请求中,我的目的是为了后续的通用,所以这么写.
import base64
fofa_url = 'https://fofa.info/result?qbase64=' # 基础
search_worlds = '"weblogic" && country="CN" && port="7001"' # fofa语法
search_worlds_base64 = base64.b64encode(search_worlds.encode('utf-8')).decode('utf-8') # 将字节进行以utf-8编码,然后进行解码,最后转为base64
url = str(fofa_url + search_worlds_base64)
# print(url)
当然,因为%3D是=号,需要改一下

1.2 发起请求
这里有个问题就是fofa在请求时,需要登录,所以需要在登录后添加cookie,来确保是登录状态,如图所示在登录后,在页面使用F12的网络中,进行刷新页面,就会出现cookie,其中User-Agent是为了避免网站的反爬机制,告诉反爬我们不是机器是人在访问,cookie代表我们是登录状态.
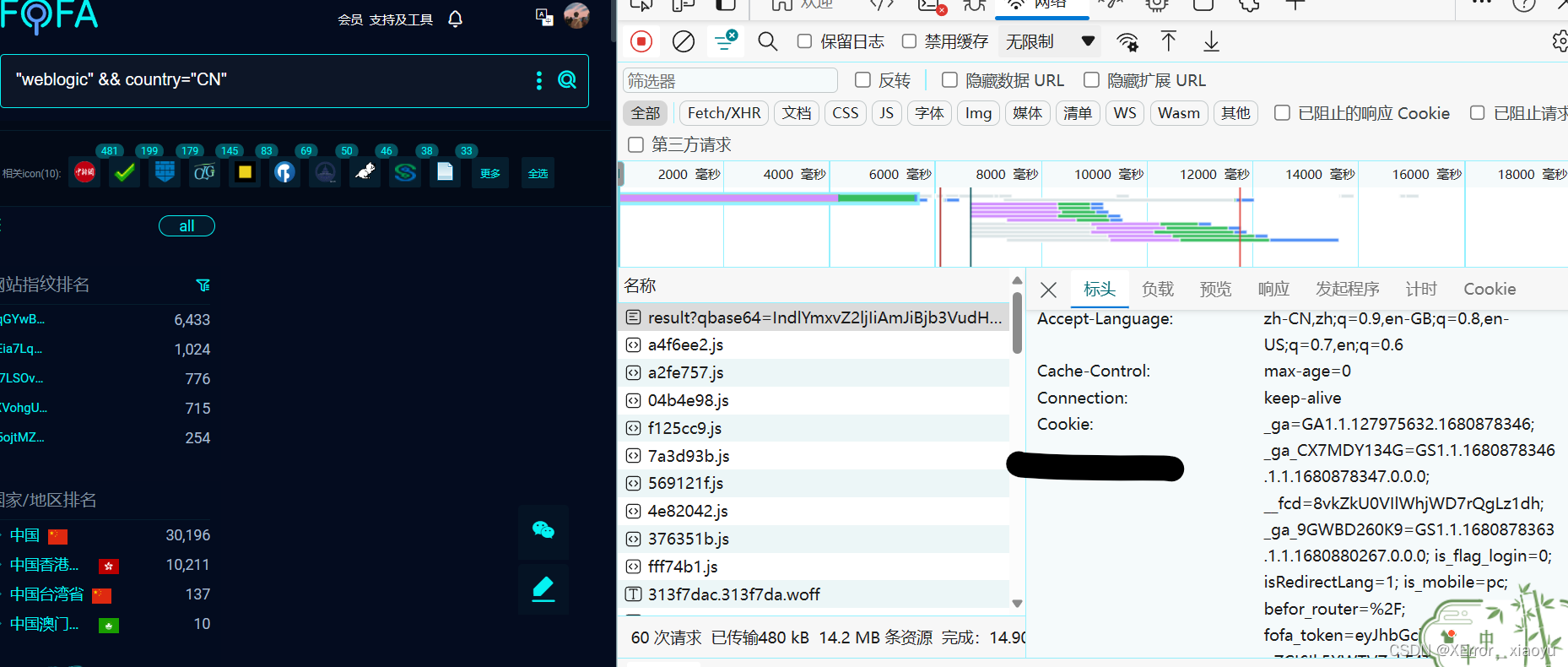
1.2.1 请求头
# 使用verify=false会出现waring警告,去掉警告用下面这条语句
requests.packages.urllib3.disable_warnings()
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0','Cookie': ''
}1.2.2 进行请求
这里在请求返回的数据中,出现了问题,以utf-8的方式进解码,返回的数据,但是会出现显示gbk错误,于是使用下面的方式进行解决,因为我们获取的数据和中文无关,所以中文乱不乱码无所谓.
# 使用get 请求,指定url ,请求头
result = requests.get(url, headers=headers, verify=False)
# data = result.content.decode('utf-8')
# 虽然还是会导致出现的返回的文本中出现乱码,但是没有影响
data = result.content.decode('gbk', errors='ignore')
# print(data)如图所示,请求返回的数据非常多也,非常杂乱,但是都在一个个标签中,我们要想解决,就需要我们从标签中将数据提取出来

1.2.3 提取数据,并进行存储
这里就需要利用xpath这种方式进行提取和利用了,当然也可以使用其他的方式,个人因为使用java和python常用xml所以选用了这个.
XPath(XML Path Language)是一种在XML文档中定位信息的语言,它提供了能在XML文档中查找信息的一种灵活方式。当然看不明白,没关系,用实例来帮助理解就可以了
| 语法 | 描述 |
|---|---|
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
| /bookstore/book[1] | 选取属于bookstore子元素的第一个book元素 |
| /bookstore/book[last()] | 选取属于bookstore子元素的最后一个book元素 |
| /bookstore/book[position()<3] | 选取属于bookstore子元素的前两个book元素 |
| //title[@lang] | 选取所有拥有名为lang的属性的title元素 |
| //title[@lang='eng'] | 选取所有title元素,且这些元素拥有值为'eng'的lang属性 |
| * | 匹配任何元素节点 |
| @* | 匹配任何属性节点 |
html = etree.HTML(data)
# IPaddrs = html.xpath('//div[@class="hsxa-meta-data-item"]/div[@class="hsxa-clearfix hsxa-meta-data-list-revision-lv1"]/div[@class="hsxa-fl hsxa-meta-data-list-lv1-lf"]/span[@class="hsxa-host"]/text()')
IPaddrs = html.xpath('//span[@class="hsxa-host"]/text()')
print(IPaddrs)
with open('CVE-2019-2725_domain.txt', 'a+', encoding='utf-8') as w:for ipaddr in IPaddrs:print(ipaddr)ipaddr = ipaddr.rstrip() # 去掉换行符w.write(ipaddr+'\n')如下图所示,我们需要采集的是,需要验证的url,那么看以看出,我们需要的url在div这个表签中,其中的class是data-item中,熟悉fofa的都知道,返回的数据一般就是10条,那么就是10个这个data-item,我们要做匹配的话,只看其中一个结构就可以了,那么就是div-->div-->div-->span 这个结构,dic嵌套div下面的继续嵌套div

上面的表格也就重点看这几句
//全局匹配,/根节点匹配 直接把title替换div,lang替换为class,本质上是一致的
| / | 从根节点选取(当前匹配的位置下选择) |
|---|---|
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置(全局) |
| //title[@lang] | 选取所有拥有名为lang的属性的title元素 |
|---|---|
| //title[@lang='eng'] | 选取所有title元素,且这些元素拥有值为'eng'的lang属性 |
方式一:
//div[@class="hsxa-meta-data-item"] 匹配第一个div/div[@class="hsxa-clearfix hsxa-meta-data-list-revision-lv1"] 匹配当前根节点下的div/div[@class="hsxa-fl hsxa-meta-data-list-lv1-lf"]/span[@class="hsxa-host"]/text() 这个就是最后匹配的了,此时匹配的是标签中的文本,所以是/text()代表根节点下的文本方式二:
使用熟悉后,可以直接使用这个进行匹配
//span[@class="hsxa-host"]/text()全局匹配span这个标签中包含class为hsxa-host的根节点下的文本

1.3 完整代码(爬取一页)
当然这个只能爬取第一页面,并且因为线程的原因爬取速度比较慢
# -*- coding: utf-8 -*-
import requests
import base64
from lxml import etreefofa_url = 'https://fofa.info/result?qbase64='
search_worlds = '"weblogic" && country="CN" && port="7001"'
search_worlds_base64 = base64.b64encode(search_worlds.encode('utf-8')).decode('utf-8')
url = str(fofa_url + search_worlds_base64)
# print(url)
# 使用verify=false会出现waring警告,去掉警告用下面这条语句
requests.packages.urllib3.disable_warnings()headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0','Cookie': ''
}result = requests.get(url, headers=headers, verify=False)
# data = result.content.decode('utf-8')
# 虽然还是会导致出现的返回的文本中出现乱码,但是可以进行处理
data = result.content.decode('gbk', errors='ignore')
# print(data)
html = etree.HTML(data)
IPaddrs = html.xpath('//div[@class="hsxa-meta-data-item"]/div[@class="hsxa-clearfix hsxa-meta-data-list-revision-lv1"]/div[@class="hsxa-fl hsxa-meta-data-list-lv1-lf"]/span[@class="hsxa-host"]/text()')
IPaddrs = html.xpath('//span[@class="hsxa-host"]/text()')
print(IPaddrs)
with open('CVE-2019-2725_domain.txt', 'a+', encoding='utf-8') as w:for ipaddr in IPaddrs:print(ipaddr)ipaddr = ipaddr.rstrip() # 去掉换行符w.write(ipaddr+'\n')

1.4 突破注册会员限制批量采集(爬取指定数量页面)
建议需要的师傅直接用就可以了,其实代码本身不难,主要是方法,需要学的师傅可以分析一下进行学习.
如果需要爬取指定的信息需要师傅进行更改xpath的匹配内容
突破fofa注册用户限制只能显示五页的数据的情况,并使用了线程,添加了爬取速度
为什么搞这个呢,高级会员学生党确实用不起,能白嫖就尽量白嫖吧,有钱的话还是尽量支持一下,当然冲着会员爬的话,那就是心安理德了.
# -*- coding: utf-8 -*-
import requests
import base64
import time
from lxml import etree
import threadingdef fofa_search(search_data, page_data):# 必须要有cookieheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0','Cookie': ''}lock = threading.Lock() # 创建线程锁def process_page(page):url = 'https://fofa.info/result?qbase64='search_worlds_base64 = str(base64.b64encode(search_data.encode("utf-8")), "utf-8")urls = url + search_worlds_base64 + '&page=' + str(page) + '&page_size=10'# print(urls) # 打印请求的URLtry:retry_count = 3while retry_count > 0:try:result = requests.get(url=urls, headers=headers, timeout=10).textbreak # 请求成功,跳出重试循环except requests.RequestException as e:print("请求发生异常:", e)retry_count -= 1if retry_count == 0:print("请求重试次数已达上限,放弃请求")return # 放弃当前页面的处理print("正在提取第" + str(page) + "页")# print(result)soup = etree.HTML(result, etree.HTMLParser()) # 初始化生成一个XPath解析对象ipaddr = soup.xpath('//span[@class="hsxa-host"]/text()')print(ipaddr)ipaddr = '\n'.join(ipaddr)print(ipaddr)with lock: # 使用线程锁保证写入文件的互斥性with open(r'CVE-2019-2725_domain.txt', 'a+') as f:print("写入文件中")# f.write('页面:'+str(page)+'\n'+ipdata + '\n')f.write(ipaddr + '\n')f.close()time.sleep(0.5) # 防止速度过快导致部分数据被略过except Exception as e:print("异常:", e)max_threads = 2 # 设置最大线程数量为2,超过2会导致页面爬取内容为空threads = []for page in range(1, page_data + 1):while len(threads) >= max_threads:# 等待当前线程数量降到允许的最大值以下time.sleep(1)threads = [t for t in threads if t.is_alive()]t = threading.Thread(target=process_page, args=(page,))threads.append(t)t.start()for t in threads:t.join()print("*********数据提取完成*********")if __name__ == '__main__':# fofa语句, 采集页面数# fofa_search('"weblogic"', 10) # 示例fofa_search('', 10)
 总结
总结
本篇主要是对在进行渗透测试中发现通用型漏洞时需要进行信息收集,因此写下这篇fofa的收集,刚好也复习一下使用爬虫时的xpath匹配,也为自己在后续写工具做好铺垫.