在校招求职的浪潮中,有些故事总是让人唏嘘不已。比如最近在社交平台上广泛讨论的一个话题:“4月阿里offer被毁,我该怎么进字节?”这不仅反映了当下职场的变动性,也映射了求职者在面对突如其来的变故时的无助与挣扎。
时间回溯到2021年7月至9月,一个年轻的实习生在阿里巴巴拿到了转正的offer,这无疑是对他能力的认可,也是职业生涯的一个美好开始。然而,好景不长,2022年4月,正当他完成了毕业论文,满怀期待准备提前入职,却突然被告知部门调整,原本的业务线团队不幸被裁,他的转正offer也随之化为泡影。
然而面对这样的打击,他没有选择沉溺于绝望,而是迅速调整心态,开始了新一轮的求职之旅。经过不懈努力,他最终拿到了字节跳动、商汤科技以及**研究所的offer,并在2022年7月选择加入了字节跳动,开始了新的职业生涯。
这个故事的主人公,通过自己的经历,向我们展示了三个重要的观点:自我约束才是最大的束缚;留下的笔记和经验是逆境中的宝贵资本;人生总是向前看,折腾不息,生命不止。
他的故事激励着许多人,无论是在求职的路上,还是在职场的挑战中,都要有一颗不屈不挠的心。现在,让我们一起跟随他的脚步,探索在技术面试中如何展示自己的才华和实力,看看字节的面试到底是什么难度。
面试官: 你好,小明。欢迎来到字节跳动的面试。首先,你能跟我解释一下OSI七层模型吗?
求职者: 当然,OSI七层模型是一个国际标准化组织ISO制定的网络通讯模型,它从下到上依次是物理层、数据链路层、网络层、传输层、会话层、表示层和应用层。每一层都有其特定的功能,比如物理层负责传送电信号,数据链路层负责在直接连接的节点之间传输帧,网络层负责在多个网络之间传输数据包,以此类推。
面试官: 很好的概述,那么在传输层中,TCP和UDP的区别是什么?
求职者: **TCP(传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层协议。它提供了数据的顺序传输、重发控制、流量控制、拥塞控制等机制,确保数据可靠传输。而UDP(用户数据报协议)**是一种无连接的协议,它不保证数据的顺序、不保证数据的可靠传输,也没有流量控制和拥塞控制,但是它的传输效率比TCP高,适用于对实时性要求高的应用,如视频会议和在线游戏。
面试官: 接下来,谈谈你对**MVCC(多版本并发控制)**的理解?
求职者: MVCC是一种用于实现数据库并发控制的技术。它通过为每个写入生成数据的新版本,而不是直接覆盖旧数据,来保证读操作可以无锁访问。这意味着读操作可以访问之前的数据版本,从而提高了并发性能,因为读写操作不会直接互相阻塞。
面试官: 很好,那么让我们深入一点,Redis缓存击穿和雪崩问题是什么,如何解决?
求职者: 缓存击穿是指高并发下,某个热点key突然失效(比如过期),导致大量请求直接落到数据库上,可能会对数据库造成巨大压力。解决方案通常是设置热点数据永不过期或使用互斥锁来控制数据库访问。 缓存雪崩是指在某一个时间段内,大量的缓存同时失效,导致所有请求都转发到数据库,同样可能造成数据库压力过大。解决方案包括使用不同的过期时间来避免同时过期,以及设置缓存的备份机制。
面试官: 明白了。对于消息队列的作用及使用场景有什么看法?
求职者: 消息队列提供了异步通信机制,允许不同的服务组件在不直接调用对方的情况下进行通信。这对解耦系统组件、提高系统的伸缩性和容错性非常有帮助。常见的使用场景包括解耦服务间的依赖、流量削峰、日志处理等。
面试官: 明白。那你了解Kafka的底层实现吗?
求职者: 抱歉,我对Kafka的底层实现不是很了解。
面试官: 没关系,那我们来谈谈单体架构和微服务架构的区别吧?
求职者: 单体架构是将所有的服务功能集成在一个应用中,这使得应用容易开发和部署,但随着业务的增长,应用变得庞大而复杂,难以维护和扩展。微服务架构将应用拆分成一组小的服务,每个服务运行在自己的进程中,并通过轻量级的通信机制(如HTTP RESTful API)进行交互,这使得应用更加模块化,易于理解、开发和测试,也更容易进行扩展。
面试官: 说得很好,那你知道Redis的过期键删除策略有哪些吗?
求职者: Redis的过期键删除策略主要包括定期删除和惰性删除。定期删除是指Redis会定期随机检查一些键,如果发现过期则删除。惰性删除是指当客户端请求某个键时,Redis会检查该键是否已过期,如果过期则删除。
面试官: 好的,你没有提到定时删除。假设Redis没有这个策略,你会如何自己实现一个定时删除的机制?
求职者: 如果要实现定时删除,我会考虑使用一个优先队列来存储键和对应的过期时间。然后,启动一个后台线程定期检查队列中的最早过期的键,如果当前时间大于或等于键的过期时间,则从Redis和队列中删除该键。这样可以确保过期的键能够及时被删除。
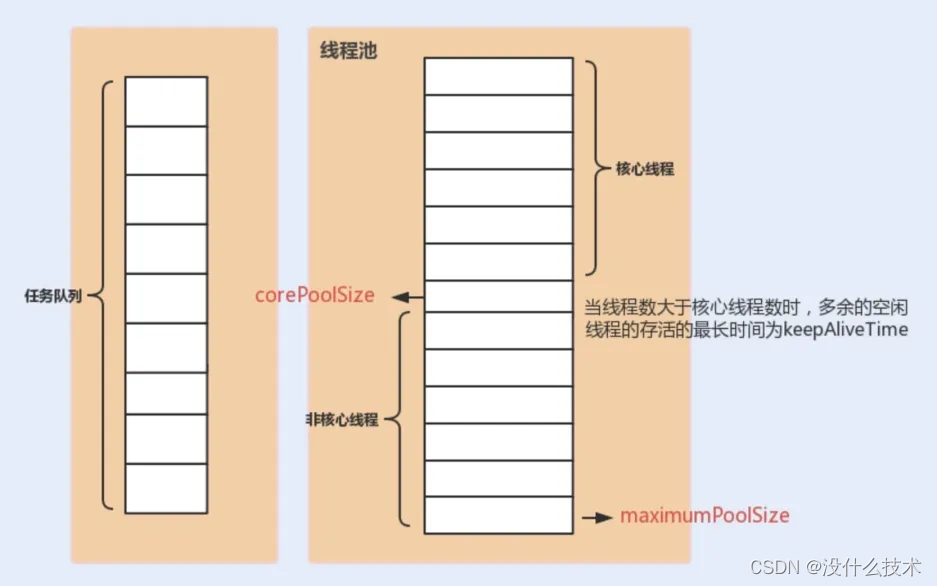
面试官: 很有创意的方法。那你能简述一下如何实现一个线程池吗?
求职者: 实现一个线程池的基本思路是先初始化一定数量的工作线程,并将它们放入空闲队列。当有新任务提交时,如果有空闲线程,则分配一个线程来执行任务;如果没有空闲线程,则将任务加入任务队列。当一个线程完成任务后,它会检查任务队列,如果有等待的任务,则取出来继续执行,否则返回到空闲队列。
面试官: 那对于Go语言中channel的底层原理,你有什么了解吗?
求职者: 在Go语言中,channel是一种用于在不同goroutine之间进行通信的机制。底层原理上,channel由一些基本结构组成,如channel本身的数据结构、goroutine队列等。当一个goroutine尝试发送数据到channel时,如果channel内有等待的接收者,则直接传递数据,如果没有,则发送者goroutine会被挂起,并放入等待队列。当接收者到来时,会从等待队列中唤醒一个发送者goroutine。
面试官: 那么,这个channel读协程如何感知到阻塞的写协程并进行唤醒呢?
求职者: 当一个读协程尝试从channel读取数据时,如果channel中没有数据,它会阻塞。如果此时有一个写协程尝试写入数据到channel,写操作会检查是否有阻塞的读协程。如果有,写协程会直接将数据传递给读协程,并唤醒它。这通常是通过在channel的数据结构中维护一个等待读取的协程队列来实现的。
面试官: 好的,让我们换个话题。在数据通信过程中,IP头部哪些字段会发生变化?
求职者: 在IP头部中,**TTL(Time To Live)**字段会在每经过一个路由器时减一,以避免数据包在网络中无限循环。如果TTL值减到0,数据包会被丢弃。此外,校验和字段可能也会因为在路由器中重新计算而发生变化。
面试官: 最后一个关于底层的问题,你对epoll的底层实现有所了解吗?
求职者: epoll是Linux内核提供的一种I/O事件通知机制,它比传统的select和poll更加高效,因为它不需要每次调用都重复传递所有监视的文件描述符集合。epoll使用一组内核维护的数据结构来跟踪每个文件描述符的状态,并且当状态发生变化时,只需要对那些发生变化的文件描述符进行操作。这是通过在内核中维护一个事件表来实现的,应用程序可以向这个事件表注册感兴趣的事件,并且当这些事件发生时得到通知。
面试官: 非常好,那我们来讨论一些算法问题。你能描述一下如何在LeetCode上解决450题,删除二叉搜索树中的一个节点吗?
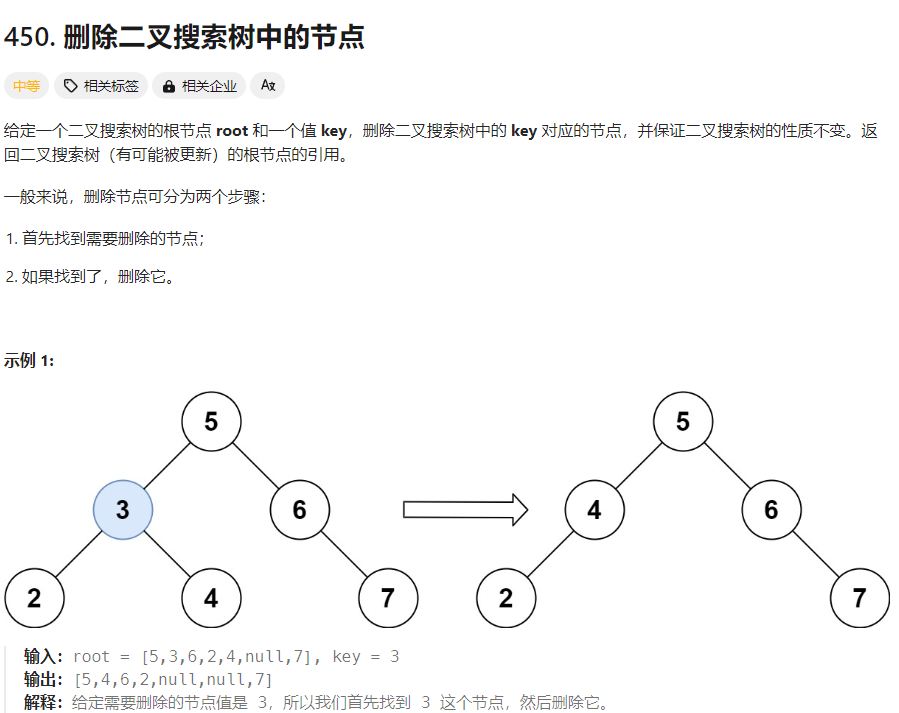
求职者: 删除二叉搜索树中的一个节点需要考虑几种情况。如果被删除的节点没有子节点,我们可以直接删除它;如果只有一个子节点,我们可以用它的子节点替代它;如果有两个子节点,我们需要找到它右子树中的最小节点(或左子树中的最大节点)来替代,并删除那个最小节点。代码大致如下:
public TreeNode deleteNode(TreeNode root, int key) {if (root == null) return null;if (key < root.val) {root.left = deleteNode(root.left, key);} else if (key > root.val) {root.right = deleteNode(root.right, key);} else {if (root.left == null) return root.right;if (root.right == null) return root.left;TreeNode minNode = findMin(root.right);root.val = minNode.val;root.right = deleteNode(root.right, root.val);}return root;
}private TreeNode findMin(TreeNode node) {while (node.left != null) node = node.left;return node;
}
面试官: 很全面的解答。那么K个一组反转链表的问题呢?
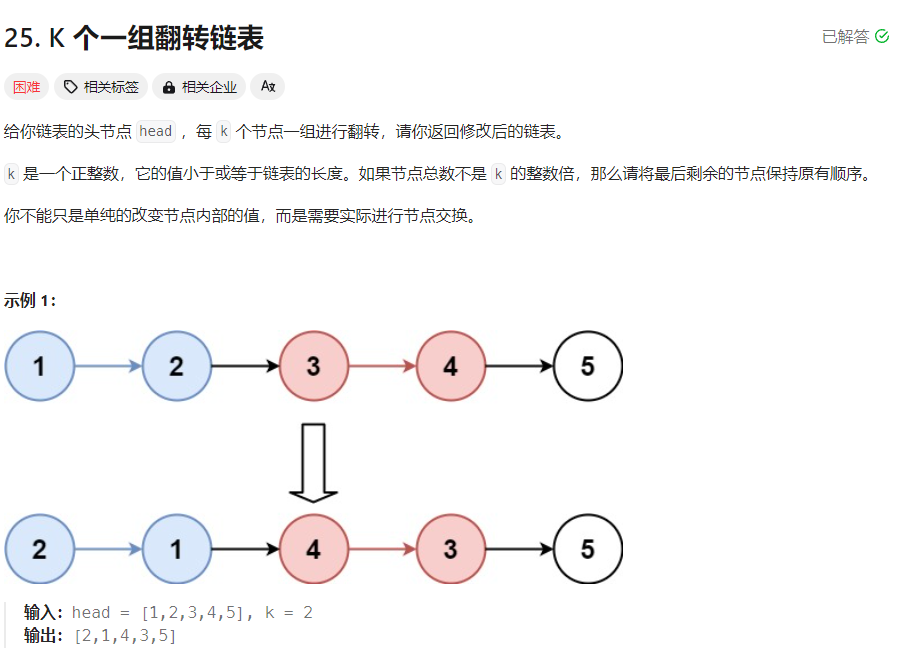
求职者: K个一组反转链表是一个比较经典的问题。我们可以通过迭代的方式来实现。首先遍历链表,每K个节点为一组进行反转,如果最后一组不足K个,则不反转。我们可以定义一个辅助函数来实现链表的局部反转,然后使用这个函数来按顺序反转所有的K个节点组。代码大致如下:
public ListNode reverseKGroup(ListNode head, int k) {ListNode dummy = new ListNode(0);dummy.next = head;ListNode pre = dummy;ListNode end = dummy;while (end.next != null) {for (int i = 0; i < k && end != null; i++) end = end.next;if (end == null) break;ListNode start = pre.next;ListNode next = end.next;end.next = null;pre.next = reverse(start);start.next = next;pre = start;end = pre;}return dummy.next;
}private ListNode reverse(ListNode head) {ListNode pre = null;ListNode curr = head;while (curr != null) {ListNode next = curr.next;curr.next = pre;pre = curr;curr = next;}return pre;
}
面试官: 好的,最后一个算法问题,如何输出和为K的所有子数组?

求职者: 要输出和为K的所有子数组,我们可以使用双指针技术或者哈希表来辅助计算。以哈希表为例,我们可以使用一个哈希表来存储从数组开始到当前位置为止的所有前缀和出现的次数。然后,我们遍历数组,计算每个位置的前缀和,并在哈希表中查找是否存在前缀和等于当前前缀和减去K的值,如果存在,则找到了一个和为K的子数组。代码大致如下:
public List<List<Integer>> findSubarraysWithSumK(int[] nums, int k) {List<List<Integer>> result = new ArrayList<>();Map<Integer, List<Integer>> sumIndexMap = new HashMap<>();int sum = 0;sumIndexMap.put(0, new ArrayList<>(Arrays.asList(-1))); // 起始前缀和for (int i = 0; i < nums.length; i++) {sum += nums[i];if (sumIndexMap.containsKey(sum - k)) {for (int start : sumIndexMap.get(sum - k)) {result.add(getSubarray(nums, start + 1, i));}}sumIndexMap.putIfAbsent(sum, new ArrayList<>());sumIndexMap.get(sum).add(i);}return result;
}private List<Integer> getSubarray(int[] nums, int start, int end) {List<Integer> subarray = new ArrayList<>();for (int i = start; i <= end; i++) {subarray.add(nums[i]);}return subarray;
}
面试官: 接下来,我们讨论一个与Go语言相关的问题。你能解释一下channel的底层原理,以及channel读协程如何感知到阻塞的写协程并进行唤醒吗?
求职者: Go语言的channel是一种强大的并发同步机制,它允许在不同的goroutine之间进行通信。底层上,channel是通过一个双向链表实现的队列,这个队列用于存储发送到channel的数据。当一个goroutine尝试从channel中读取数据时,如果channel为空,它会被阻塞并加入到一个等待队列中。相反,当一个goroutine尝试向channel写入数据时,如果channel已满,它也会被阻塞并加入到另一个等待队列中。 当一个写协程向channel中写入数据时,它会检查是否有读协程正在等待。如果有,那么这个写协程会直接将数据传递给等待的读协程,并将该读协程从等待队列中移除并唤醒它。这个过程是通过底层的调度器和同步机制实现的,以确保数据的安全传递和协程的正确唤醒。
面试官: 那关于IP头部在传输中哪些字段发生变化的问题,你只提到了TTL。还有其他字段会变化吗?
求职者: 是的,除了TTL字段外,在IP数据包传输过程中,还有其他一些字段可能会发生变化。例如,**校验和字段(Checksum)也会在每一跳中重新计算和更新,以确保数据包在传输过程中没有被损坏。此外,如果发生IP分片,则标识字段(Identification)和片偏移字段(Fragment Offset)**也会根据分片过程进行相应的修改。
面试官: 很好,我们再来谈谈epoll的底层实现。你对这个有什么了解吗?
求职者: epoll是Linux操作系统中高效的I/O事件通知机制。它的底层实现主要基于一个事件表,这个事件表是在内核中维护的。当应用程序调用epoll_create函数时,内核会创建这样一个事件表。应用程序可以通过epoll_ctl函数向事件表中添加、修改或删除关注的文件描述符以及相应的事件。当这些文件描述符上发生了关注的事件时,应用程序可以通过调用epoll_wait函数来获取这些事件。 epoll的高效之处在于,它使用了一种称为“事件驱动”的机制,只有那些真正发生了事件的文件描述符才会被返回给用户空间,这大大减少了应用程序在用户空间和内核空间之间的数据拷贝,提高了事件通知的效率。
面试官: 感谢你的参与,很不错,等通知吧。
(备注:这个学生真的很厉害)