一、概述
在多模态领域中,主要存在两个核心问题:一致性对齐问题和交互融合问题。一致性对齐问题主要指不同模态的信息匹配,例如实体对齐、语义对齐,例子有:文本中的“男人”与图片中男子指代一个人。交互融合问题指不同模态的信息如何进行合理的融合。
本文提出一种新型的将新闻文本和图像两种模态进行融合的方法,以提升对虚假新闻的检测。
二、原理
首先可以知道,MRHFR所使用的多模态数据是:新闻图像、新闻文章和用户对新闻的评论。主要处理的就是图像信息和文本信息。其中,图像使用vgg-19来提取特征,文本(包括新闻文章和评论)使用Bert来提取,两个模型都是使用预训练好的模型。
在将新闻图像和新闻文章相互融合过程,文章提出三种融合方法,分别是Glimpse-Text&Read-Image、Read-Text&Glimpse-Image和Read-Text&Read-Image。其分别表示3种人类阅读习惯:粗看(瞥一眼)文章&细看(阅读)图片、细看文章&粗看图片、细看文章&细看图片。(编者注:感觉这3个习惯挺无厘头的,但是最后确实起到了效果)三种融合的特征会一并使用到最后的新闻检测中
其中,还需要使用用户评论去判修正三种融合特征向量,即给三个向量赋予权重,确定哪个更为重要。
三、模型架构
MRHFR的模型架构如下所示:

按照上面原理所讲, 其训练过程分4步,第一步是提取图像和文本的基础特征(Feature Representations,特征表征),第二步是将新闻文本特征和新闻图像特征分三种方法进行融合(Cognition-aware Fusion Layer,认知感知融合层),同时基于相似度选取最具综合性的几条评论以作下一步的备用。第三步是使用评论信息去约束融合特征,然后计算粗看特征与细看特征之间的差异,使用该差异再去设置3个特征之间的权重(CCR,一致性约束推理)。最后到第四步进行拼接检测(Task Learning,任务学习)。
1.特征表征
这一块并没啥需要细讲的,其中获取图像的VGG-19的结果后,作者直接使用一层全连接层和sigmoid激活函数将多通道信息汇总到一块。
![]()
公式如上,W是全连接层参数,是VGG-19得到的图像信息,
是sigmoid函数。
2.(评论)选择机制
由于一个新闻的评论区有许多评论,搜集到的评论也有很多,需要从中筛选最具代表性的几条评论。其使用的方法也是简单的,先使用全连接层对所有评论进行处理,得到每条评论的特征向量,再根据评分向量点乘计算任意两条评论的差异性,选择差异性最大的k条评论。公式如下:
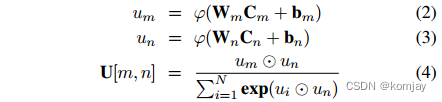
其中是第m条评论的Bert提取后的特征矩阵(每个单词是一个向量),W和b是全连接的层的参数,
并没有说明是哪个具体激活函数。u是一条评论的特征向量,
是点乘符号。U是相似度矩阵,越高说明相似度越高。
3.认知感知融合层(CFU)
在融合之前,文章在Encoding中针对模态不同,设置了不同的编码方法。
其中,对文本部分,使用了自注意力网络(相当于transformer中的一个encode块)。在一个注意力头中,其设置QKV设置成了同样的参数(这是一个很奇怪的点,可能是为了方便后续计算),多头注意力网络得到的结果通过一个全连接层汇总到一起。公式如下:
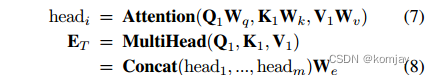
其中,、
和
是一个注意力头中的参数,Q、K、V是一个注意力头得到的关于一个文本的综合信息矩阵,
是全连接层的参数。
是最后的细看新闻文章编码。
对于图像部分,其使用离散余弦变换(discrete cosine transform,DCT)技术将图片的特征矩阵(只有一个)拓展成64个矩阵,将这64个矩阵再通过CNN(有不同大小的卷积核)和全连接层,又重新得到一个矩阵,作为细看新闻图片的编码。
而粗看的编码,就是第一步特征表征得到的V和T。
在真正的融合的块中(Co-Attn),这里只举Read-Text&Glimpse-Image的计算过程(即文本特征用,图像特征用V),首先,有将图片信息加到文本中和将文本信息加到图片中2个步骤,公式如下:
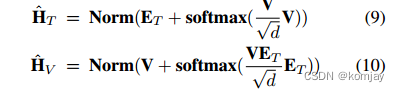
然后再进行2个融合:将信息融合到
中,和将
融合到
中(文章没写这条)。公式如下:
![]()
最后,将和
拼接在一块作为最后的融合特征:
![]()
其中,Norm函数是归一化函数,d是特征维度数 ,FFN函数是前馈网络。(FFN和MLP一般是同义词,这里应该也是,至于为啥这里用FNN,后面又用MLP,不太清楚)
4.一致性约束推理(CCR)
为了将评论的特征矩阵约束融合特征,需要将两个特诊矩阵统一到一样大小的维度,这里就又是一个全连接层,激活函数选择tanh(在NLP中常用tanh,CV用sigmoid),公式如下:

其中,是评论集合,
是拼接了三个融合特征后的总特征矩阵。 这里以评论-多模态约束块(Comment-Multimodal coherence)举例。如果是别的块(另外两个块只有单模态的信息),则将
换成
或
即可。
然后设计出一个q-k对,其中评论作为query,融合特征作为key:
其中,W是全连接参数。有了q-k后,可以计算二者之间的注意力,通过注意力将
、
两个特征进行融合,得到融合评论后的信息特征
:
![]()
在最后,使用最大池化层处理上面的信息特征:
![]()
而在约束策略块(Constraint Strategy)中,则是计算单模态与多模态特征的差异性(约束信息),其中新闻文本特征和新闻多模态之间的差异计算公式如下:
![]()
然后拼接两个约束信息,通过一个多层感知机处理到一块:
![]()
最后,将单模态信息、多模态信息、约束信息汇总,得到最终的特征向量:
![]()
5.任务学习
在最后的推理阶段,就是一个简单二分类问题了,将上面得到的IM特征向量通过全连接层得到2*1的向量,通过softmax函数得到该新闻在两个类别上的概率值,损失函数是简单的对数算是函数:
![]()
四、实验与结果分析
文章使用的数据集有两个,一个是Khattar搜集的Twitter数据集,另一个是Jin等人搜集的Weibo的数据集。其过滤掉其中有视频、缺少图片、缺少文本的新闻。设置twitter数据集的新闻文本长度为30,微博文本长度为160。图片大小设置为1024*1024,评论长度设置为100。文本编码大小为768,选取的评论数为5。
在第二步CFU中的注意力头数量为6,第三步CCR中的注意力头数量为4,注意力头的dropout为0.5,训练120轮,0.001的学习率,batch大小为256。训练结果如下:
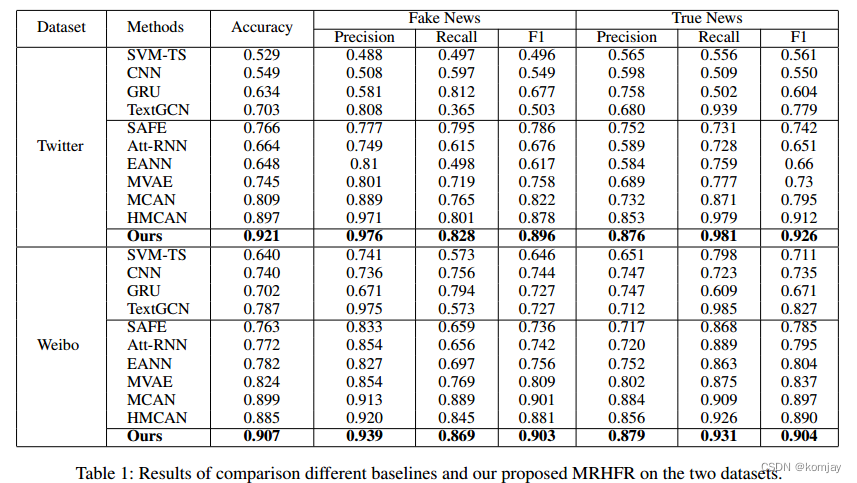
消融实验结果如下:
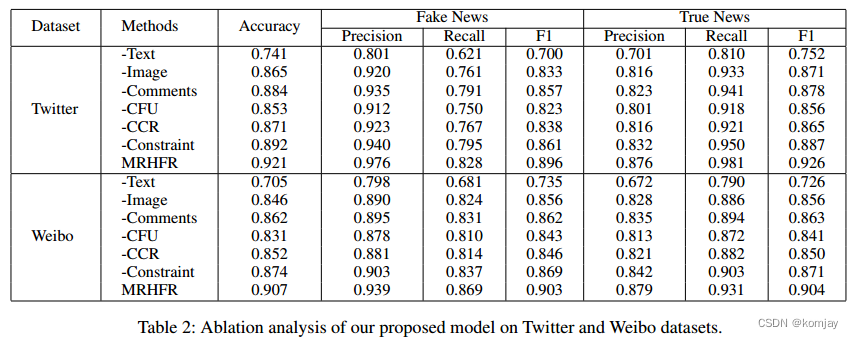
其中,在引入图像信息(image)和汇总所有信息(MRHFR) 的提升率最大。可以证明该方法的合理性。
此外,研究团队还做了三个小实验:
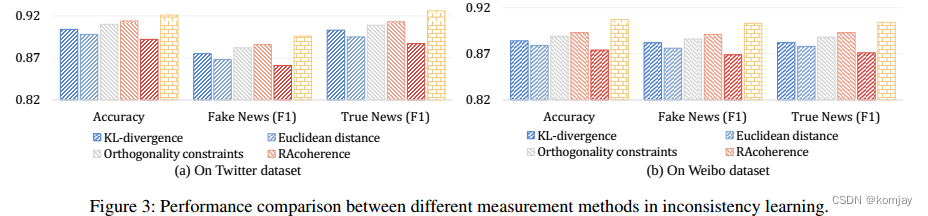
1.对CCR步骤中的差异性计算使用的距离函数进行不同对比,文章最后选用的是cos,其他的距离函数有KL距离、欧式距离、正交性约束和RA一致性,实验结果如下:(红色斜杠柱是不用约束信息,黄色砖柱是使用cos距离)
2.对比CFU和其他共注意力网络的区别,CFU能关注到更深层的语义信息:

3.对比CCR在有无关联约束策略下的区别,结果是,在有关联约束策略下,模型能关注到语义连贯性。

五、总结
本文虽然只使用了文本和图像的信息融合, 但是这种结合方法似乎可以运用到更多种模态的融合当中,这种混合使用各种模型,以一定逻辑组合在一起的模态融合方法似乎是一个很主流的研究方向。