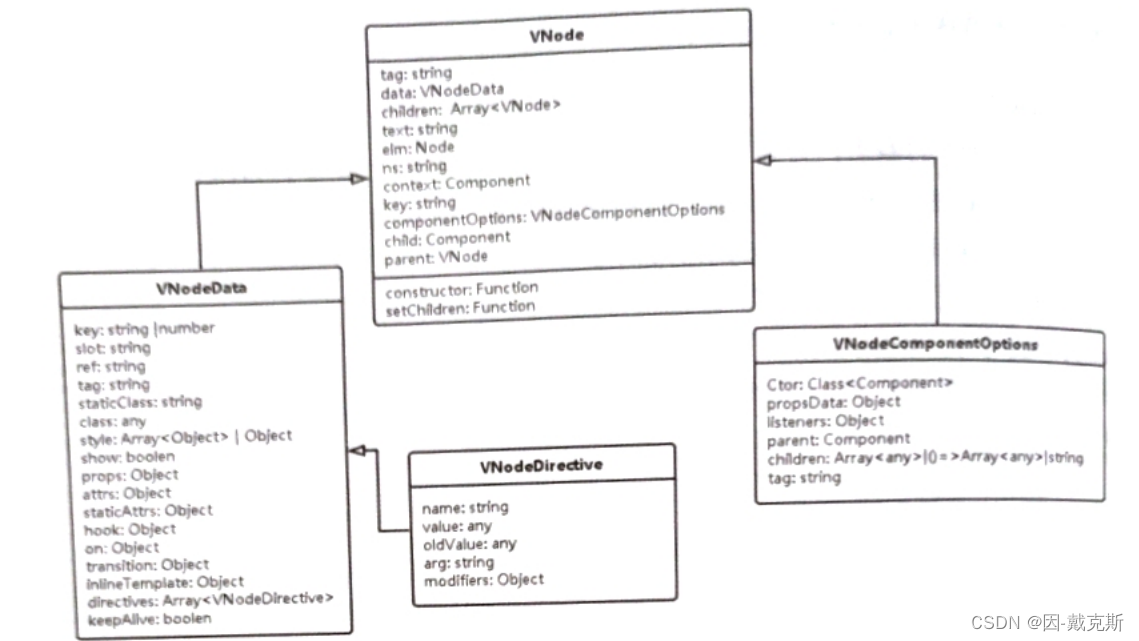
0. 文件结构
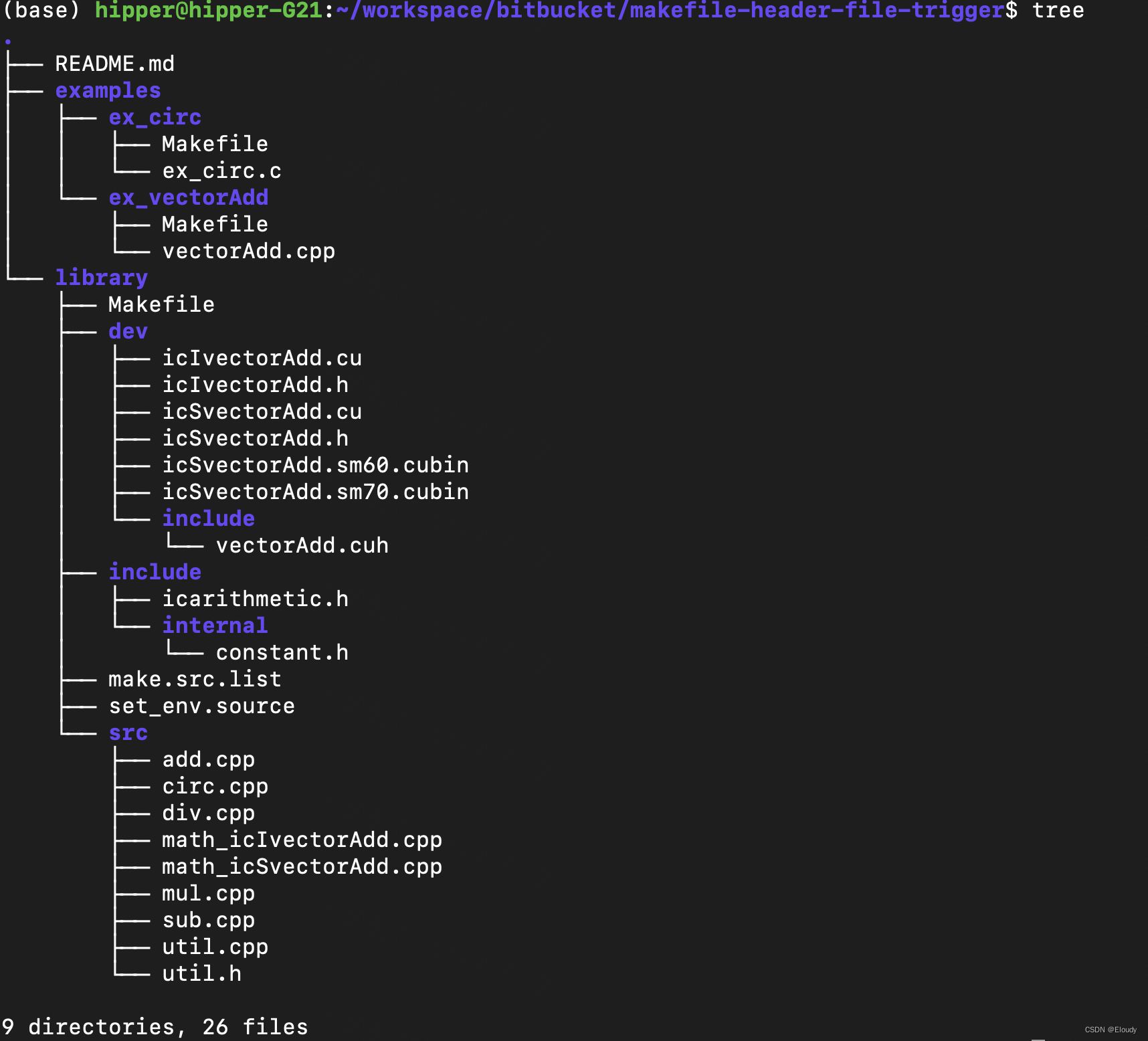
device 模版函数放在 library/dev/include/*.cuh
模版的实例化和调用封装在 library/dev/*.cu
针对主机代码调用dev 函数而提供的头文件放在 library/dev/*.h, 也就是*.cu中主机函数的声明;
业务逻辑放置在 lib/src/*.cpp中,调用library/dev/*.cu中的函数实现加速,并dafault visible 出去,供第三方调用(#define API_ __attribute__((visibility("default"))));
一个 cuda shared library 的通用Makefile
1,源码
library/Makefile
TARGET := libicarithmetic.soDEBUG_FLAGS := -O3
#DEBUG_FLAGS := -g -gz -ggdb
HEADER_FLAGS := -MD -MF $*.d -MP all: $(TARGET)include make.src.listOBJ_CPP := $(SRC_CPP:.cpp=.cpp.o)
DEP_CPP := $(SRC_CPP:.cpp=.cpp.d)OBJ_CU := $(SRC_CU:.cu=.cu.o)
DEP_CU := $(SRC_CU:.cu=.cu.d)CPP_FLAGS := $(DEBUG_FLAGS) -fPIC -fvisibility=hidden -fvisibility-inlines-hidden -Wno-unused-result -Werror=vla
INC_CPP := -I./include/internal
LD_FLAGS := -L/usr/local/cuda/lib64 -lcudart -lcudadevrt# -Werror=vla -fvisibility=hidden -fvisibility-inlines-hidden -Wno-unused-result
CU_FLAGS := -Xcompiler -fPIC
INC_CU :=
GPU_ARCH ?= -gencode arch=compute_60,code=sm_60 -gencode arch=compute_70,code=sm_70 -gencode arch=compute_75,code=sm_75 -gencode arch=compute_80,code=sm_80 -gencode arch=compute_80,code=compute_80#-arch=sm_70
#CPP compiler
CXX := g++
#device code compiler
DXX := nvcc-include $(DEP_CPP)
-include $(DEP_CU)%.cpp.o: %.cpp$(CXX) $(CPP_FLAGS) $(INC_CPP) $< -c -o $@ -MMD -MF $*.cpp.d -MP #-MMD --generate-nonsystem-dependencies-with-compile
#-MF --dependency-output
#-MP --generate-dependency-targets
%.cu.o: %.cu$(DXX) $(GPU_ARCH) $(CU_FLAGS) $(INC_CU) $< -c -o $@ -MMD -MF $*.cu.d -MP#--generate-nonsystem-dependencies-with-compile --dependency-output $*.cu.d --generate-dependency-targets# -MD -MF $*.cu.d -MPdev/icSvectorAdd_link.cu.o: dev/icSvectorAdd.cu.onvcc -Xcompiler -fPIC $(GPU_ARCH) -dlink -o $@ $< $(LD_FLAGS)$(TARGET): $(OBJ_CPP) $(OBJ_CU) dev/icSvectorAdd_link.cu.o$(CXX) -shared $^ -o $@.PHONY: clean
clean:rm -rf $(OBJ_CPP) $(OBJ_CU) $(TARGET) $(DEP_CPP) $(DEP_CU) dev/icSvectorAdd_link.cu.o#$(SRC_C:.c=.d)2,用法
同一份shared lib 支持多种架构的编译方式:
make#ormake GPU_ARCH="-gencode arch=compute_60,code=sm_60 -gencode arch=compute_70,code=sm_70"3,扩展
上述Makefile可以为同一份cuda 代码分别生成不同的架构的二进制文件,但是如果想为每个架构使用不同的cuda代码,这个Makefile就做不到了。
这时需要使用 nvcc编译器内置的宏:
__CUDA_ARCH__
比如,为 sm_70写的代码
#if __CUDA_ARCH__ == 700x = x+y;#endif参考:CUDA_Compiler_Driver_NVCC
某种意义上类似于做了如下分开的编译:
nvcc -cubin -arch=sm_70 -D__CUDA_ARCH__=700 icSvectorAdd.cu -o icSvectorAdd.sm70.cubin