论文地址:https://arxiv.org/abs/2311.04917
1.概论
尽管大量的研究致力于虚假新闻检测,这些研究普遍存在两大局限性:其一,它们往往默认所有新闻文本均出自人类之手,忽略了机器深度改写乃至生成的真实新闻日益增长的现象;其二,它们倾向于将所有机器制造的新闻一概视作虚假信息,未能细致区分其中的真实性与欺骗性。 因此,论文对在各种场景下训练的假新闻探测器进行了深度研究。得出以下重要结论:
- 针对人类所写的文章进行训练的探测器在检测机器生成的假新闻方面表现出色,但反之不成立
- 由于检测器对机器生成文本的偏差(Su et al.,2023a),它们应该在比测试集更低的机器生成新闻比率的数据集上进行训练。
2.方法

为了模拟人写内容和机器生成内容之间的动态变化,考虑三种实验设置:
- 人类遗产阶段:在这一阶段,所有真实新闻训练数据都是人类编写的,而假新闻训练数据则逐渐引入机器生成的比例,从0%增加到100%。
- 过渡共存阶段:在此阶段,真实新闻的训练数据包括由人类和机器生成的内容。假新闻训练数据也是如此,以反映新闻生成环境的实际变化。
- 机器主导阶段:在这一阶段,所有真实新闻训练数据都是机器生成的,探索完全由机器控制的新闻生成未来的情形。
3.实验
(1)实验设计与方法:
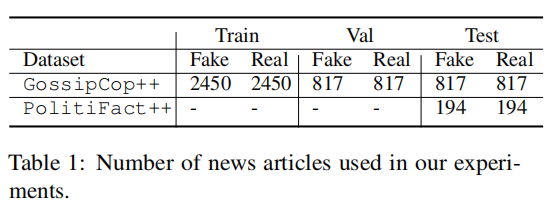
- 数据集:研究使用了两个主要数据集:GossipCop++和PolitiFact++。这些数据集包括机器仿写的真实新闻(MR)、机器生成的假新闻(MF)、人类编写的真实新闻(HR)和假新闻(HF)。
- 模型和方法:采用了基于Transformer的模型,如BERT、RoBERTa、ELECTRA、ALBERT和DeBERTa。这些模型在不同的数据组合和不同的新闻生成阶段(人类遗产阶段、过渡共存阶段、机器主导阶段)进行训练和测试。
(2)主对比实验
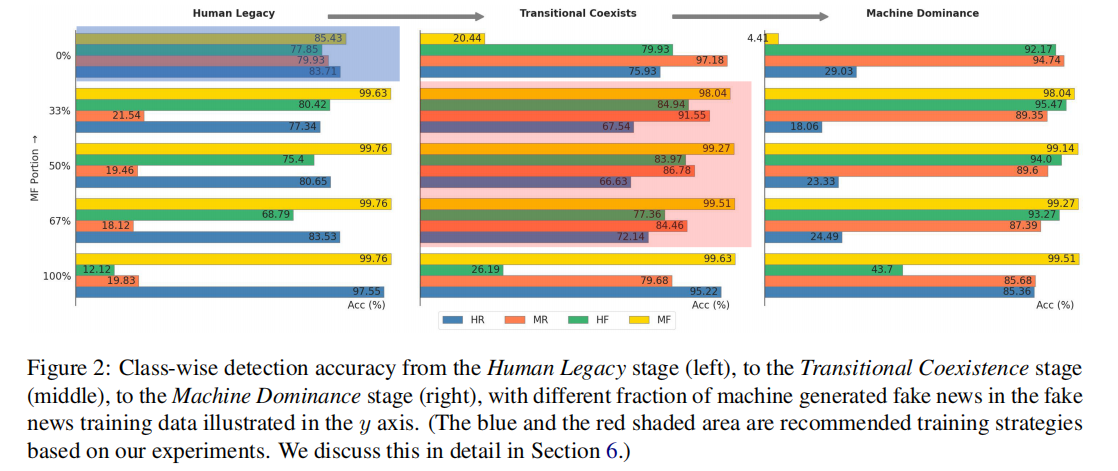
- 人类遗产阶段:在人类遗产阶段中,当训练数据中假新闻的机器生成比例为0%,即全部由人类编写时,检测器能够在域内测试集(GossipCop++)上平衡地检测各个子类。当机器生成假新闻(MF)的比例逐渐增加时,检测器对MF的检测准确性显著提高,但对机器仿写的真实新闻(MR)的检测准确性下降。这表明,尽管检测器在检测机器生成的内容方面表现出高效性,但它们可能过度依赖于特定于机器生成文本的特征,从而影响了对MR的判断。
-
过渡共存阶段:在过渡共存阶段中,真实新闻和假新闻的训练数据包括了人类编写和机器生成的内容。结果显示,当MF占假新闻训练数据的较大比例时,检测器能够高效地识别机器生成的假新闻(MF),但对人类编写的假新闻(HF)的检测准确性显著降低。这一现象可能由于检测器在训练时学习到将机器生成的文本特征与假新闻关联的倾向,导致它在没有见过足够多人类编写的假新闻样本时,难以准确识别。
-
机器主导阶段:在机器主导阶段中,所有真实新闻训练数据都是机器生成的,这一设置是为了模拟一个未来可能出现的由机器主导新闻生成的场景。在这种设置下,检测器在域内数据集上对机器生成假新闻(MF)的检测准确性非常高,但同样地,对人类编写的假新闻(HF)的检测准确性较低。这进一步证实了检测器可能过度适应机器生成文本的特征,而忽略了内容的真实性。
 (3)Class-wise Accuracy as a Function of the Proportion of MF Examples
(3)Class-wise Accuracy as a Function of the Proportion of MF Examples
论文评估假新闻检测器在不同比例的机器生成假新闻(MF)比例下的表现。总结如下:
- 随着MF比例的增加,检测器对机器生成假新闻(MF)的识别准确性普遍提高,显示出对机器文本特征的敏感性。
- 对人类编写的假新闻(HF)的检测准确性随MF比例的增加而降低,暗示检测器可能过度适应机器生成文本的特征。
- 对机器仿写的真实新闻(MR)的检测准确性在MF比例增加时通常会下降,这可能是由于检测器将MR与MF混淆,因为两者都是机器生成的。
- 对人类编写的真实新闻(HR)的检测准确性在MF比例增加时可能会提高,由于HR与MF在风格和特征上的明显差异。
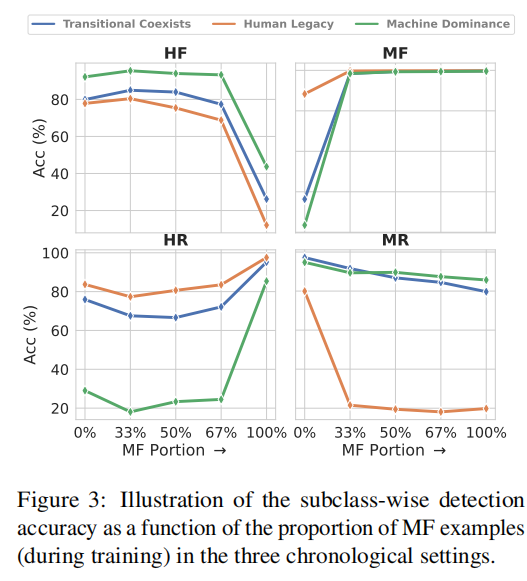
论文还分析了不同阶段的变化:
- 人类遗产阶段:在无机器生成内容的训练数据中,检测器能较好地平衡各子类的检测准确性。
- 过渡共存阶段:反映了新闻来源的多样化,其中检测器对机器生成假新闻(MF)的识别性能提高,但对人类编写假新闻(HF)的识别性能降低。
- 机器主导阶段:几乎所有新闻都由机器生成时,检测器对机器生成假新闻(MF)的检测性能极高,但对人类编写内容的检测性能较低。
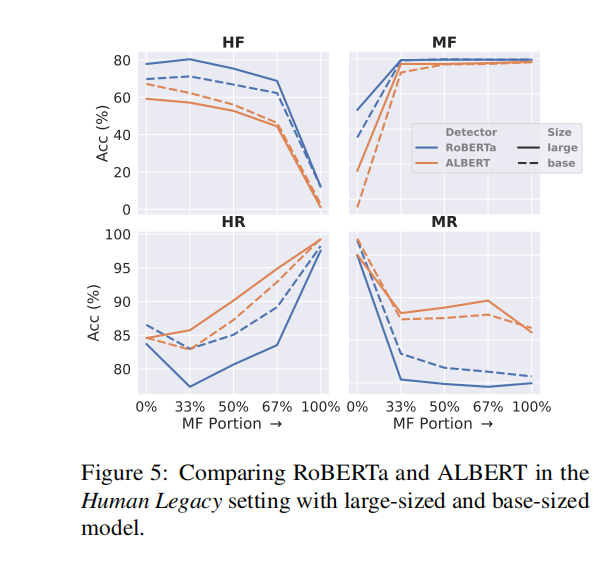
(4)不同检测器以及模型大小的分析
- 模型比较:不同模型在识别各类假新闻方面表现出显著差异。例如,RoBERTa在某些设置中对人类假新闻(HF)和机器生成假新闻(MF)的检测准确性较高,而其他模型可能在检测真实新闻(HR)方面表现更优。
- 模型偏好:这些差异可能反映了内在的模型偏好或训练时的特性,例如某些模型可能更倾向于将文章分类为真或假,这影响了它们在复杂数据集上的泛化能力。
-
模型大小的影响:模型的大小(大型与基本型号)对其在处理假新闻检测任务中的表现有明显影响。较大的模型通常能更好地处理更多的信息和更复杂的特征,从而可能在识别机器生成的假新闻(MF)等复杂情况中表现更佳。而较小的模型可能在某些情况下因为模型较为简单,不易过拟合,而在特定子类别如人类编写的真实新闻(HR)上表现更好。
(5)跨域检测
- 性能下降:在域外数据集上,大多数检测器的性能普遍下降,尤其是在没有足够代表性的训练数据时。
- MF比例的影响:增加机器生成假新闻(MF)的比例能够帮助缓解跨域检测准确性的差距,尽管这可能会牺牲对某些子类(如HF和MR)的检测准确性。
4.总结
- 训练数据的平衡:研究建议在训练假新闻检测器时使用多样化的数据源,尤其是在不确定测试数据分布的情况下,应包含不同来源的真假新闻。
- 跨域性能的优化:通过在训练集中增加机器生成内容的比例,可以改善检测器在不同域上的泛化能力,从而减少在域内和域外检测准确性之间的差距。