前言
- SQLAIchemy 异步DBManager封装-01入门理解
- SQLAIchemy 异步DBManager封装-02熟悉掌握
在前两篇文章中,我们详细介绍了SQLAlchemy异步DBManager的封装过程。第一篇文章帮助我们入门理解了整体的封装结构和思路,第二篇文章则帮助我们更加熟悉和掌握了这个封装的使用。我们已经介绍了添加和查询操作,并且对整体的封装思路有了深入的了解。
在本文中,我将继续扩展封装,介绍如何进行更新和删除操作。同时,我将演示如何执行原生的SQL语句,并介绍在异常情况下如何进行事务回滚的场景。这些内容将帮助我们更全面地应对各种数据库操作的需求。
更新封装
from sqlalchemy import Result, column, delete, func, select, text, update@with_session
async def update(self,values: dict,*,orm_table: Type[BaseOrmTable] = None,conds: list = None,session: AsyncSession = None,
):"""更新数据Args:values: 要更新的字段和对应的值,字典格式,例如 {"field1": value1, "field2": value2, ...}orm_table: ORM表映射类conds: 更新条件列表,每个条件为一个表达式,例如 [UserTable.username == "hui", ...]session: 数据库会话对象,如果为 None,则在方法内部开启新的事务Returns: 影响的行数cursor_result.rowcount"""orm_table = orm_table or self.orm_tableconds = conds or []values = values or {}if not values:returnsql = update(orm_table).where(*conds).values(**values)cursor_result = await session.execute(sql)return cursor_result.rowcount@with_session
async def update_or_add(self,table_obj: [T_BaseOrmTable, dict],*,orm_table: Type[BaseOrmTable] = None,session: AsyncSession = None,**kwargs,
):"""指定对象更新or添加数据Args:table_obj: 映射类实例对象 or dict,e.g. UserTable(username="hui", age=18) or {"username": "hui", "v": 18, ...}orm_table: ORM表映射类session: 数据库会话对象,如果为 None,则在方法内部开启新的事务Returns:"""orm_table = orm_table or self.orm_tableif isinstance(table_obj, dict):table_obj = orm_table(**table_obj)return await session.merge(table_obj, **kwargs)
- update 方法通过 sqlaichemy 的 update 来组织sql语句进行条件更新
- update_or_add 则是指定对象进行更新或新增操作,有主键id则更新,没有则添加,具体是使用 session.merge 方法进行操作。入参的 table_obj 可以是库表映射类实例对象、dict,字典形式则是通过 Manager 下的orm_table 进行转换成映射类实例对象来操作。
class UserFileTable(BaseOrmTable):"""用户文件表"""__tablename__ = "user_file"filename: Mapped[str] = mapped_column(String(100), default="", comment="文件名称")creator: Mapped[int] = mapped_column(default=0, comment="文件创建者")file_suffix: Mapped[str] = mapped_column(String(100), default="", comment="文件后缀")file_size: Mapped[int] = mapped_column(default=0, comment="文件大小")oss_key: Mapped[str] = mapped_column(String(100), default="", comment="oss key(minio)")is_del: Mapped[int] = mapped_column(default=0, comment="是否删除")deleted_at: Mapped[datetime] = mapped_column(nullable=True, comment="删除时间")class UserFileManager(DBManager):orm_table = UserFileTableasync def update_demo():ret = await UserFileManager().update(values={"filename": "hui"}, conds=[UserFileTable.id == 1])print("update ret", ret)# 添加user_file_info = {"filename": "huidbk", "oss_key": uuid.uuid4().hex}user_file: UserFileTable = await UserFileManager().update_or_add(table_obj=user_file_info)print("update_or_add add", user_file)# 更新user_file.file_suffix = "png"user_file.file_size = 100user_file.filename = "hui-update_or_add"ret: UserFileTable = await UserFileManager().update_or_add(table_obj=user_file)print("update_or_add update", ret)
删除封装
@with_session
async def bulk_delete_by_ids(self,pk_ids: list,*,orm_table: Type[BaseOrmTable] = None,logic_del: bool = False,logic_field: str = "deleted_at",logic_del_set_value: Any = None,session: AsyncSession = None,
):"""根据主键id批量删除Args:pk_ids: 主键id列表orm_table: orm表映射类logic_del: 逻辑删除,默认 False 物理删除 True 逻辑删除logic_field: 逻辑删除字段 默认 deleted_atlogic_del_set_value: 逻辑删除字段设置的值session: 数据库会话对象,如果为 None,则通过装饰器在方法内部开启新的事务Returns: 删除的记录数"""orm_table = orm_table or self.orm_tableconds = [orm_table.id.in_(pk_ids)]return await self.delete(conds=conds,orm_table=orm_table,logic_del=logic_del,logic_field=logic_field,logic_del_set_value=logic_del_set_value,session=session,)@with_session
async def delete_by_id(self,pk_id: int,*,orm_table: Type[BaseOrmTable] = None,logic_del: bool = False,logic_field: str = "deleted_at",logic_del_set_value: Any = None,session: AsyncSession = None,
):"""根据主键id删除Args:pk_id: 主键idorm_table: orm表映射类logic_del: 逻辑删除,默认 False 物理删除 True 逻辑删除logic_field: 逻辑删除字段 默认 deleted_atlogic_del_set_value: 逻辑删除字段设置的值session: 数据库会话对象,如果为 None,则通过装饰器在方法内部开启新的事务Returns: 删除的记录数"""orm_table = orm_table or self.orm_tableconds = [orm_table.id == pk_id]return await self.delete(conds=conds,orm_table=orm_table,logic_del=logic_del,logic_field=logic_field,logic_del_set_value=logic_del_set_value,session=session,)@with_session
async def delete(self,*,conds: list = None,orm_table: Type[BaseOrmTable] = None,logic_del: bool = False,logic_field: str = "deleted_at",logic_del_set_value: Any = None,session: AsyncSession = None,
):"""通用删除Args:conds: 条件列表, e.g. [UserTable.id == 1]orm_table: orm表映射类logic_del: 逻辑删除,默认 False 物理删除 True 逻辑删除logic_field: 逻辑删除字段 默认 deleted_atlogic_del_set_value: 逻辑删除字段设置的值session: 数据库会话对象,如果为 None,则通过装饰器在方法内部开启新的事务Returns: 删除的记录数"""orm_table = orm_table or self.orm_tableif logic_del:# 执行逻辑删除操作logic_del_info = dict()logic_del_info[logic_field] = logic_del_set_value or datetime.now()delete_stmt = update(orm_table).where(*conds).values(**logic_del_info)else:# 执行物理删除操作delete_stmt = delete(orm_table).where(*conds)cursor_result = await session.execute(delete_stmt)# 返回影响的记录数return cursor_result.rowcount
- 通过主键ID单个删除,组织
conds = [orm_table.id == pk_id],调用 delete 方法 - 通过主键ID列表批量删,组织
conds = [orm_table.id.in_(pk_ids)]调用 delete 方法
这两种删除操作都是通过调用 delete 方法实现的。默认情况下,这些操作执行的是物理删除。对于一些重要的数据,我们也可以选择执行逻辑删除。在逻辑删除中,默认使用 deleted_at 字段来记录删除时间。我们也可以指定具体的逻辑删除字段 logic_field,以及逻辑字段的赋值情况 logic_del_set_value,然后进行一个更新操作来实现逻辑删除。
如下是删除前的数据
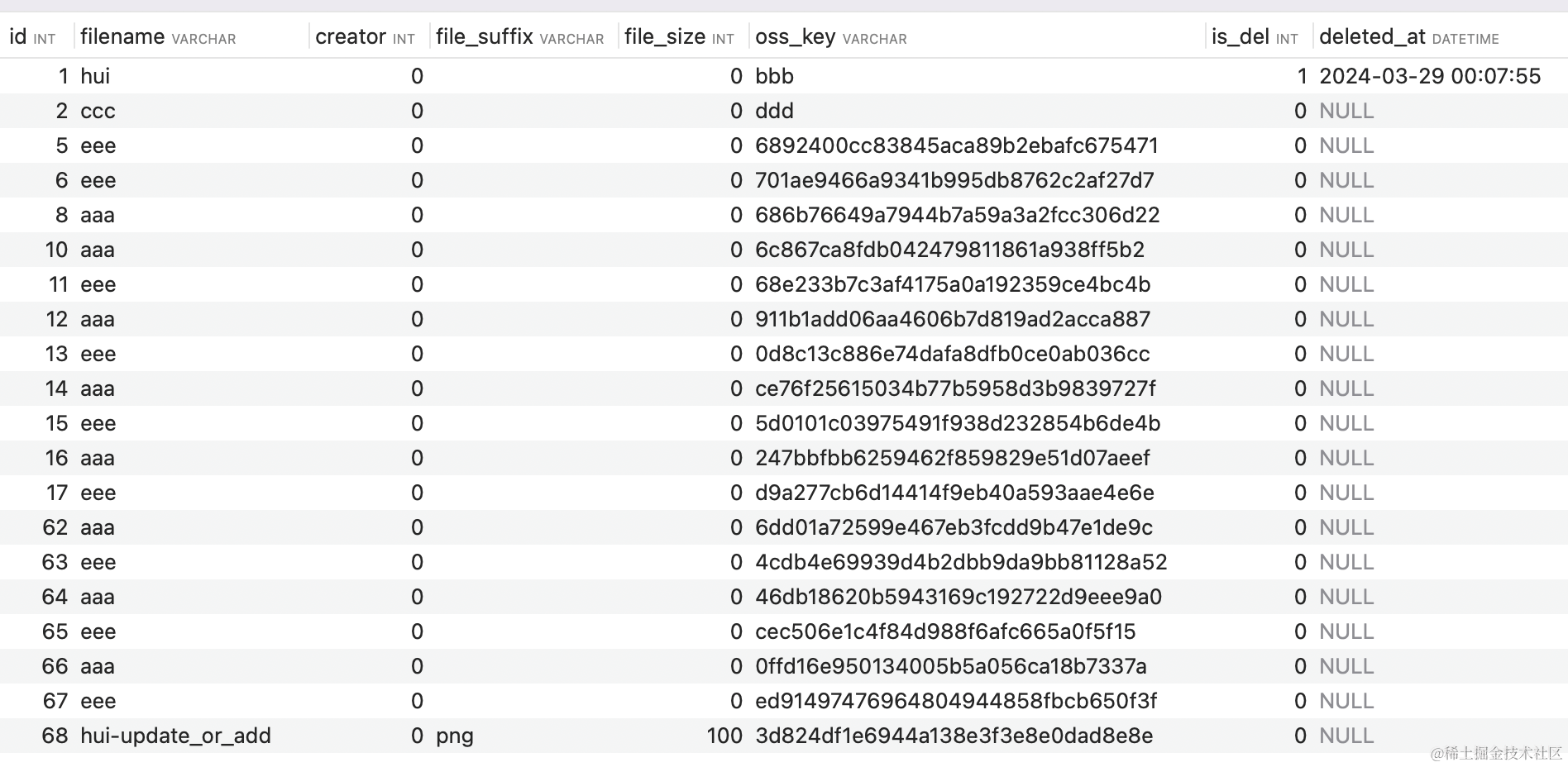
async def delete_demo():file_count = await UserFileManager().query_one(cols=[func.count()], flat=True)print("file_count", file_count)ret = await UserFileManager().delete_by_id(file_count)print("delete_by_id ret", ret)ret = await UserFileManager().bulk_delete_by_ids(pk_ids=[10, 11, 12])print("bulk_delete_by_ids ret", ret)ret = await UserFileManager().delete(conds=[UserFileTable.id == 13])print("delete ret", ret)ret = await UserFileManager().delete(conds=[UserFileTable.id == 5], logic_del=True)print("logic_del ret", ret)ret = await UserFileManager().delete(conds=[UserFileTable.id == 6], logic_del=True, logic_field="is_del", logic_del_set_value=1)print("logic_del set logic_field ret", ret)
删除结果展示
file_count 20
delete_by_id ret 0
bulk_delete_by_ids ret 3
delete ret 1
logic_del ret 1
logic_del set logic_field ret 1
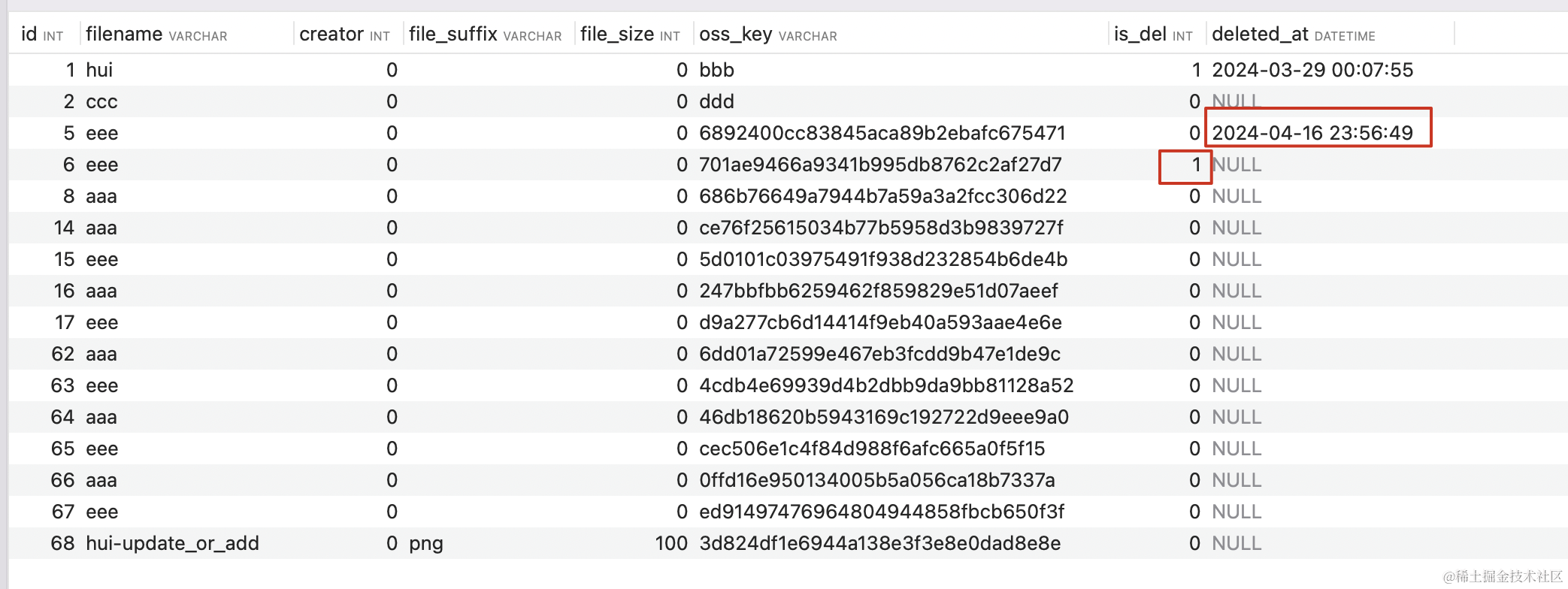
主键id 为5、6的被逻辑删除了,10,11,12,13 被物理删除了。
执行原生sql
@with_session
async def run_sql(self, sql: str, *, params: dict = None, query_one: bool = False, session: AsyncSession = None
) -> Union[dict, List[dict]]:"""执行并提交单条sqlArgs:sql: sql语句params: sql参数, eg. {":id_val": 10, ":name_val": "hui"}query_one: 是否查询单条,默认False查询多条session: 数据库会话对象,如果为 None,则通过装饰器在方法内部开启新的事务Returns:执行sql的结果"""sql = text(sql)cursor_result = await session.execute(sql, params)if query_one:return cursor_result.mappings().one() or {}else:return cursor_result.mappings().all() or []
内部执行sql时需要通过 sqlaichemy 的 text 函数转一下,然后根据 query_one 的值来确定查询单条还是多条。
async def run_raw_sql_demo():"""运行原生sql demo"""count_sql = "select count(*) as total_count from user_file"count_ret = await UserFileManager().run_sql(count_sql, query_one=True)print("count_ret", count_ret)data_sql = "select * from user_file where id > :id_val and file_size >= :file_size_val"params = {"id_val": 20, "file_size_val": 0}data_ret = await UserFileManager().run_sql(data_sql, params=params)print("dict data_ret", data_ret)data_sql = "select * from user_file where id > :id_val"data_ret = await UserFileManager().run_sql(sql=data_sql, params={"id_val": 4})print("dict data_ret", data_ret)# 连表查询data_sql = """selectuser.id as user_id,username,user_file.id as file_id,filename,oss_keyfrom user_filejoin user on user.id = user_file.creatorwhere user_file.creator = :user_id"""data_ret = await UserFileManager().run_sql(data_sql, params={"user_id": 1})print("join sql data_ret", data_ret)
需要注意的执行原生sql,sql参数的展位符是 :param_name 冒号后面接参数名称,然后参数对应的值则是字典形式组织。
查询结果如下
count_ret {'total_count': 16}dict data_ret [{'id': 62, 'filename': 'aaa', 'creator': 0, 'file_suffix': '', 'file_size': 0, 'oss_key': '6dd01a72599e467eb3fcdd9b47e1de9c', 'is_del': 0, 'deleted_at': None}, ..]dict data_ret [{'id': 5, 'filename': 'eee', 'creator': 0, 'file_suffix': '', 'file_size': 0, 'oss_key': '6892400cc83845aca89b2ebafc675471', 'is_del': 0, 'deleted_at': datetime.datetime(2024, 4, 16, 23, 56, 49)}, ...]join sql data_ret [{'user_id': 1, 'username': 'hui', 'file_id': 1, 'filename': 'hui', 'oss_key': 'bbb'}]
事务回滚操作
async def create_and_transaction_demo():async with UserFileManager.transaction() as session:await UserFileManager().bulk_add(table_objs=[{"filename": "aaa", "oss_key": uuid.uuid4().hex}], session=session)user_file_obj = UserFileTable(filename="eee", oss_key=uuid.uuid4().hex)file_id = await UserFileManager().add(table_obj=user_file_obj, session=session)print("file_id", file_id)ret: UserFileTable = await UserFileManager().query_by_id(2, session=session)print("query_by_id", ret)# 异常回滚a = 1 / 0ret = await UserFileManager().query_one(cols=[UserFileTable.filename, UserFileTable.oss_key],conds=[UserFileTable.filename == "ccc"],session=session)print("ret", ret)
这里通过 transaction() 获取事务会话 session,让后面的数据库操作都指定 session 参数,with_session 装饰器就不会再次构造,实现了共用一个 session,事务内的操作要么都成功要么都失败。
整体封装总结
-
SQLAIchemyManager 设计
- 用于初始化数据库配置信息
-
BaseOrmTable、TimestampColumns、BaseOrmTableWithTS 设计
- 通用库表映射类,一些主键id,时间戳字段让子类继承共享,以及 to_dict 方法将对象属性转成字典
-
transaction 上下文管理器(事务会话)
- 便捷的进行事务处理
-
with_session 装饰器
- 复用开启事务会话 session 操作,减少冗余代码,没有 session 则动态的构造 session,兼容整体事务会话
-
orm_table 设计
- 让继承DBManager的子类指定 orm_table ,数据库操作时明确知道具体库表,减少参数传递
-
DBManager 设计
- 封装了通用的CRUD方法,让子类可以共享和复用这些方法,推荐子类进行常用业务数据查询封装,实现业务逻辑的复用和灵活性。
-
查询扁平化 flat
- 查询结果可以直接使用,不需要额外处理,简化了操作流程。
-
字典与库表映射类实例
- 一些方法的入参,同时支持字典与库表映射类实例,提高了方法的通用性和灵活性。
-
分页查询
- 指定页码、每页大小查询出总数与分页数据
-
逻辑删除
- 支持默认的
deleted_at字段 or 指定逻辑字段进行逻辑删除,保留重要数据
- 支持默认的
-
执行原生sql
- 一些复杂sql操作,不使用 orm 组织,推荐使用原生 sql 进行操作
到这就结束了,希望这些封装,可以满足各种复杂业务场景下的需求,提高数据库操作的灵活性和适用性,从而提高我们的开发效率。让代码变得更简单。
Github源代码
源代码已上传到了Github,里面也有具体的使用Demo,欢迎大家一起体验、贡献。
HuiDBK/py-tools: 打造 Python 开发常用的工具,让Coding变得更简单 (github.com)