0.理解Linux文件权限
0.1 Linux安全性
用户的权限是通过创建用户时分配的用户ID(UID)来追踪的,UID是个数值,每个用户都有一个唯一的UID
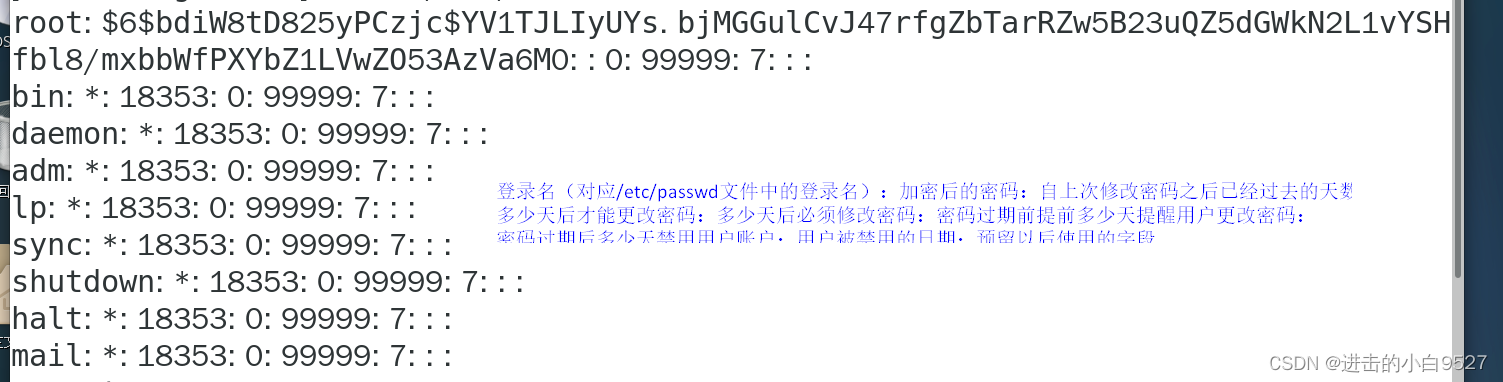
0.1.1 /etc/passwd文件
Linux系统使用一个专门的文件/etc/passwd来匹配登录名与对应的UID值,该文件包含一些用户相关的信息。root用户账户是Linux系统的管理员,为其固定分配的UID是0.linux系统会为各种各样的功能创建不同的用户账户,而这些账户并非真实的人类账户,我们称之为系统账户,它们是系统中运行各种服务进程访问资源时使用的特殊账户。
Linux为系统账户预留了500以下的UID.有些服务甚至要用特定的UID才能正常工作。为普通用户创建账户时可能从500/100开始。

0.1.2 /etc/shadow文件
现在绝大多数的linu系统将用户密码都保存在单独的文件中shadow文件,/etc/shaodw。只有root用户才能访问/etc/shadow文件。这样使得与/etc/passwd相比要安全的多。
有了shadow密码系统之后,linux系统可以更好的控制用户的密码了,比如控制用户多久更改一次密码,密码未更新什么时候禁用账户。
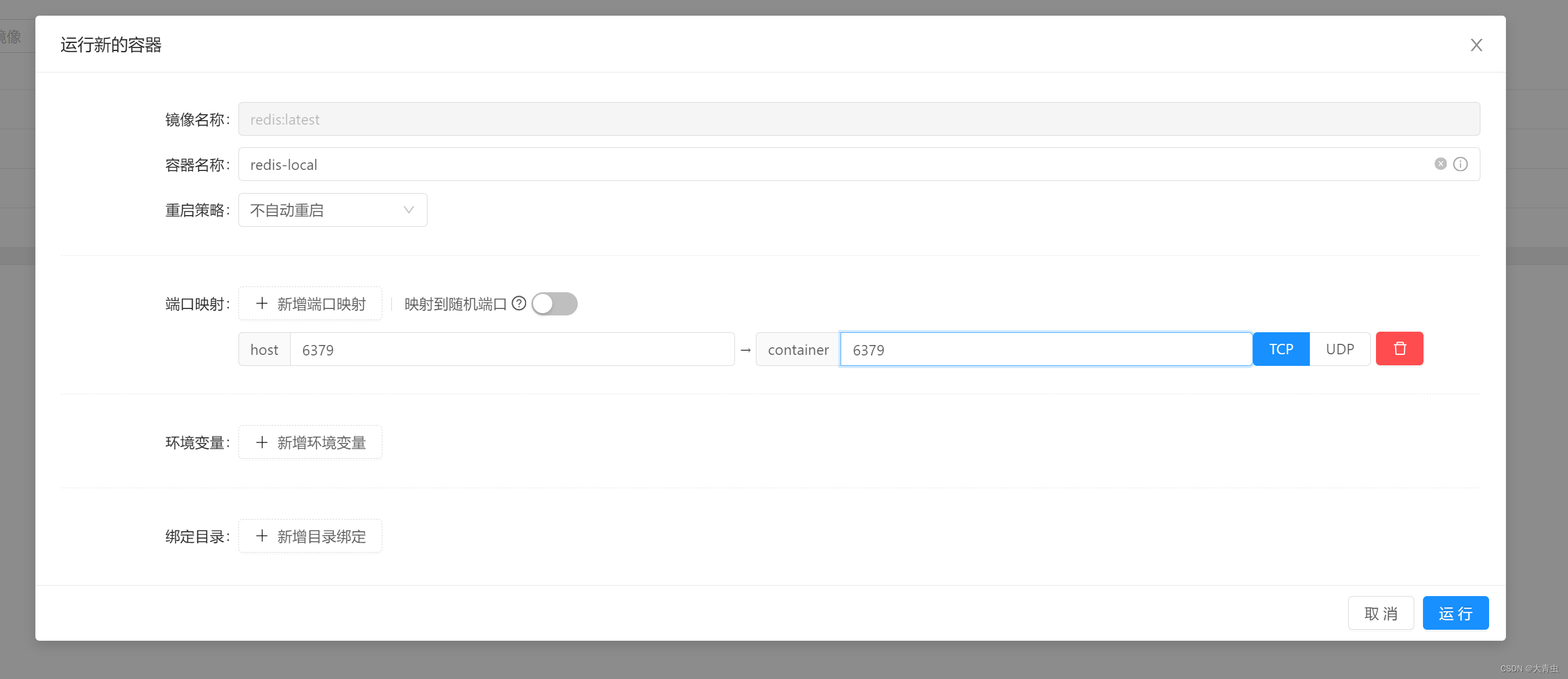
0.1.3 添加新用户
用来向Linux系统添加新用户的主要工具是useradd.-D选项显示了在命令行中创建新用户账户时,如果不明确指明具体值,useradd命令所使用的默认值。
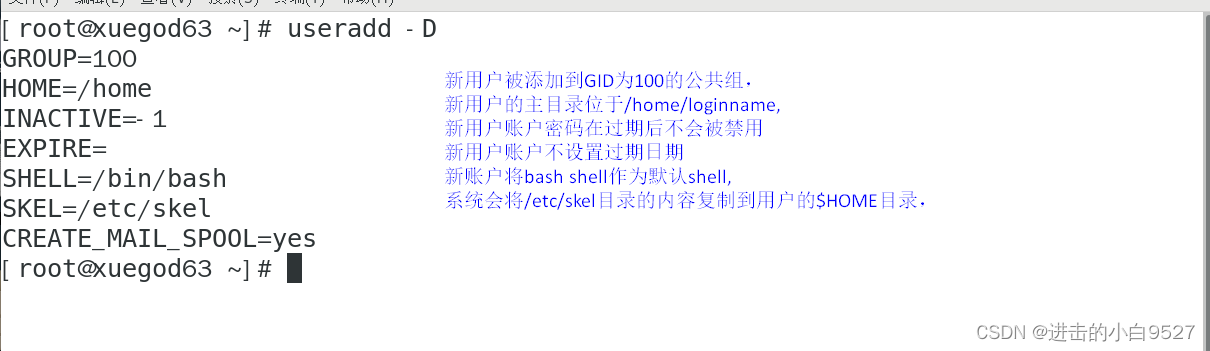
useradd命令允许管理员创建默认的$HOME目录配置,然后将其作为创建新用户$HOME目录的模板。这样就能在每个新用户的$HOME目录里面放置默认的系统文件了。 系统会在自动将一下212文件复制到创建出来的每个用户的$HOME目录

可以使用useradd -m test,-m命令行选项会使其创建$HOME目录。useradd命令创建了新的$HONME目录,并将/etc/skel目录中的文件复制了过来。
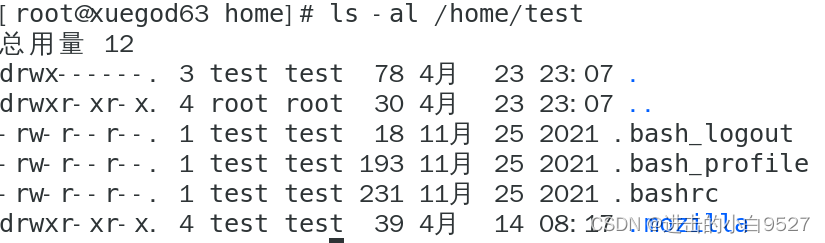
useradd的命令行选项
-b, --base-dir BASE_DIR 新账户的主目录的基目录-c, --comment COMMENT 新账户的 GECOS 字段-d, --home-dir HOME_DIR 新账户的主目录-D, --defaults 显示或更改默认的 useradd 配置-e, --expiredate EXPIRE_DATE 新账户的过期日期-f, --inactive INACTIVE 新账户的密码不活动期-g, --gid GROUP 新账户主组的名称或 ID-G, --groups GROUPS 新账户的附加组列表-h, --help 显示此帮助信息并推出-k, --skel SKEL_DIR 使用此目录作为骨架目录-K, --key KEY=VALUE 不使用 /etc/login.defs 中的默认值-l, --no-log-init 不要将此用户添加到最近登录和登录失败数据库-m, --create-home 创建用户的主目录-M, --no-create-home 不创建用户的主目录-N, --no-user-group 不创建同名的组-o, --non-unique 允许使用重复的 UID 创建用户-p, --password PASSWORD 加密后的新账户密码-r, --system 创建一个系统账户-R, --root CHROOT_DIR chroot 到的目录-P, --prefix PREFIX_DIR prefix directory where are located the /etc/* files-s, --shell SHELL 新账户的登录 shell-u, --uid UID 新账户的用户 ID-U, --user-group 创建与用户同名的组-Z, --selinux-user SEUSER 为 SELinux 用户映射使用指定 SEUSER
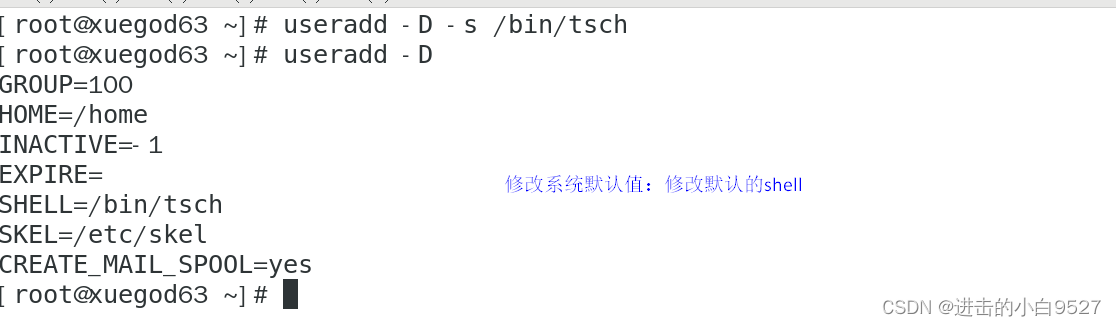
0.1.4 删除用户
可以使用userdel从系统中删除用户,userdel默认情况下只是会删除/etc/passwd和/etc/shadow文件中的用户信息,属于该账户的文件会被保留。但是如果加入了-r选项, userdel会删除用户$HOME目录以及邮件目录

1.构建基础脚本
1.1 创建shell脚本
1.1.1 第一行需要指定使用的shell
# 用作注释行.shell并不会处理脚本中的注释行,但是第一行的注释,会告诉shell使用哪个shell来运行脚本.
#!/bin/bash1.1.2 让shell找到你的脚本
直接运行脚本会提示-bash: a.sh: command not found.因为shell会通过PATH环境变量来查找命令,但是很明显PATH里面不存在我们的脚本路径

要让shell找到a.sh脚本有两种方法
1)将放置shell脚本的目录添加到PATH环境变量中 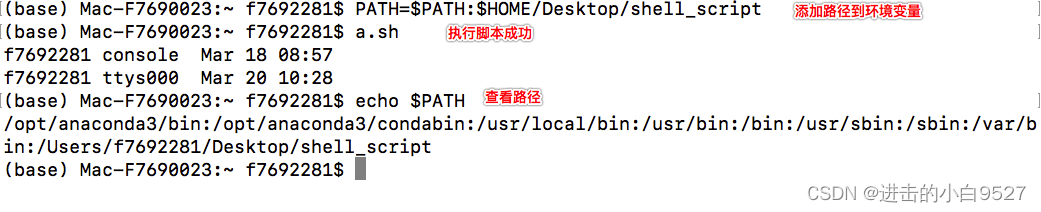
2)在命令行中间使用绝对或是相对路径来引用shell脚本
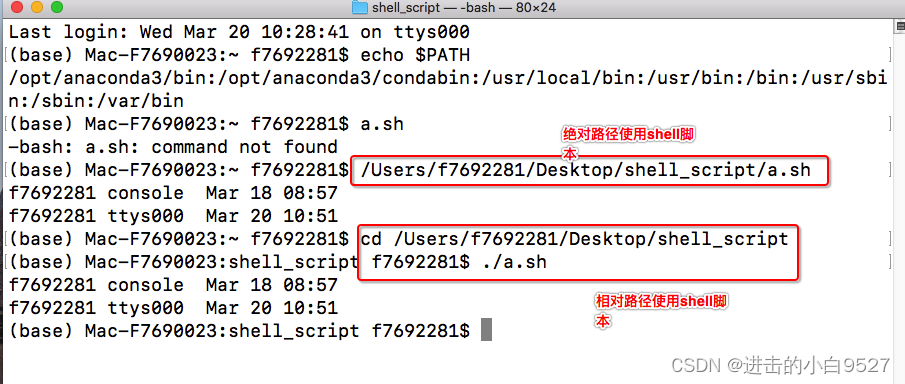
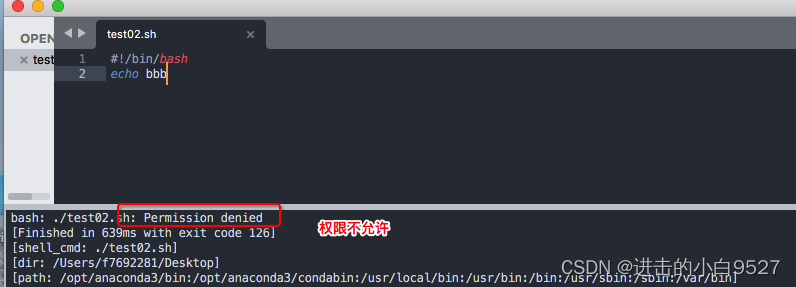
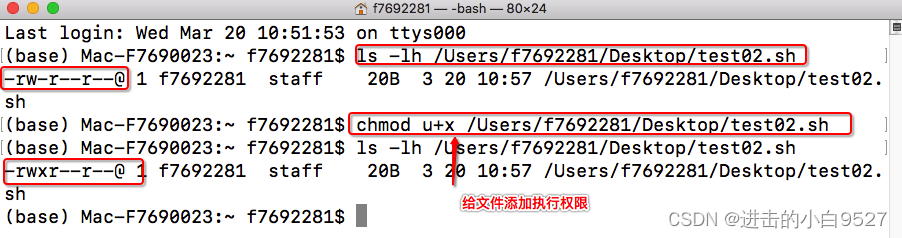
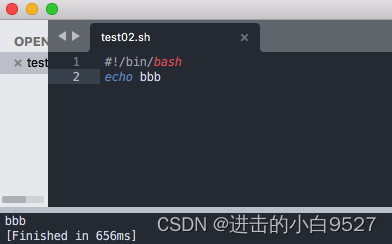
1.1.3 给shell脚本赋予执行权限
因为umask的默认值为022,所以创建出来的文件权限是644,文件没有执行权限,所以需要添加执行权限
1.2 echo 显示消息
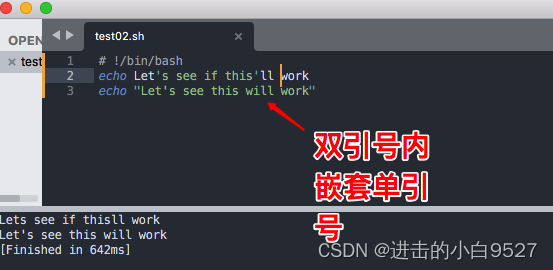
1) echo + 字符串,就会显示这个字符串,使用单双引号的不同嵌套方式来实现显示字符串里面存在引号
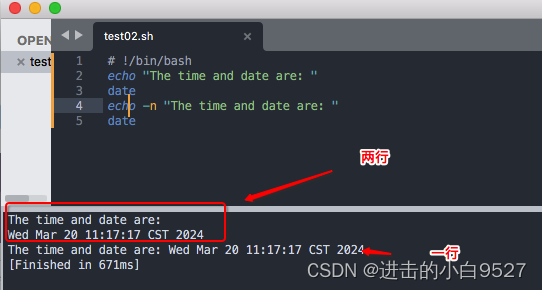
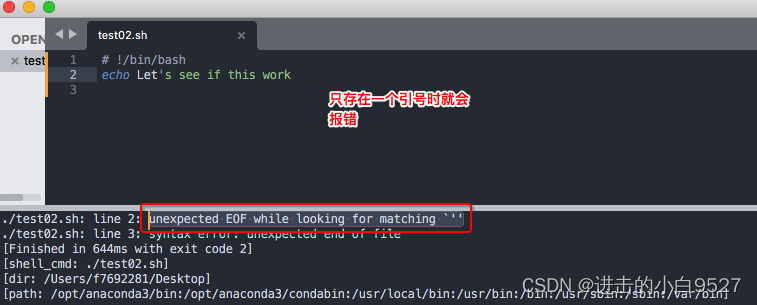 2)echo -n将字符串和命令输出在同一行
2)echo -n将字符串和命令输出在同一行
1.3 使用变量2==
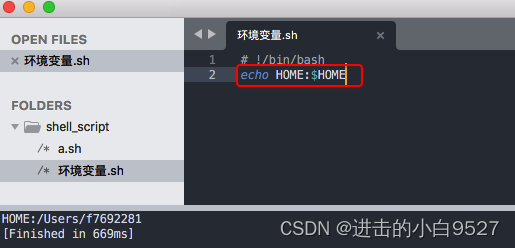
1.3.1 环境变量
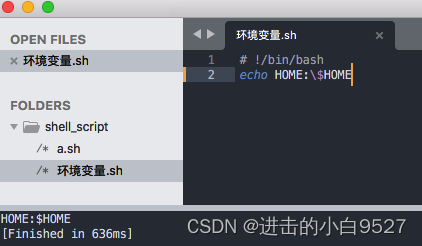
环境变量包括全局环境变量和局部环境变量,全局使用printenv查看,set可以查看所有环境变量.在脚本中间可以在环境变量名前加$来使用他们,但是在shell中间看到$就以为在引用变量,要显示$的话,就需要反斜线来实现转义.
1.3.2 用户自定义变量
自定义变量可以数字字母下划线组成,变量名区分大小写.重要的是变量名=值,三者之间没有空格. 赋值时变量不需要加$,引用时前面需要加$.
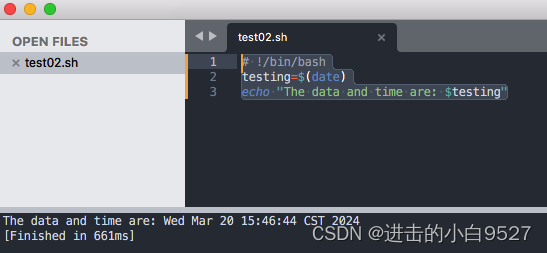
1.3.3 命令替换
shell脚本中可以从命令输出中提取信息并将其赋值给变量.将输出赋值给变量之后,就可以在脚本中随意使用了.
有两种方法可以将命令输出给变量:
1) 反引号
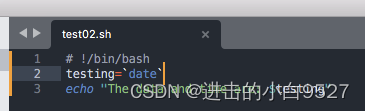
2) $()
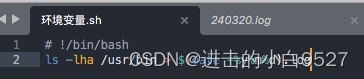
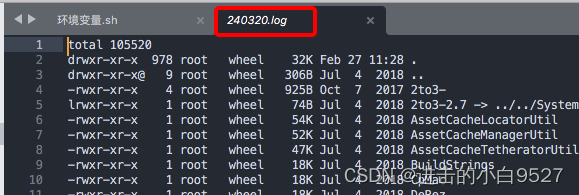
将/usr/bin文件夹下面的的内容,写入到.log文件中,文件名按照当前日期 来进行命名.
+%y%m%d会将日期显示为两位数字的年月日.
1.4 重定向输入和输出
1.4.1 输出重定向
格式: command > outputfile
会将命令的输出发送至文件里面.重定向运算符会创建新的文件(使用默认的umask设置),如果文件已存在,就会用新数据覆盖已有数据.
格式:command >> outputfile
如果文件已经存在就进行追加而不是覆盖.
1.4.2 输入重定向
格式: command < inputfile
会将文件的内容重定向至命令.
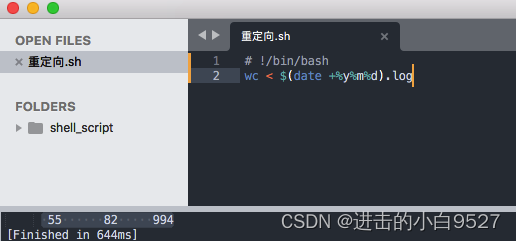
wc命令可以统计数据中的文本,默认输出3个值,文本的行数,文本的单词数,文本的字节数.
输出的内容为55行,82个单词,994个字节
1.4.3 内联输入重定向
格式:command << marker
data
marker
无需使用文件进行重定向,只需要在命令行中间指定用于输入重定向的数据即可.这个marker作为文本的起止符号.
# !/bin/bash
wc << EOF
test string 1
test string 2
test string 3
EOF
1.4.4 输入和输出重定向结合使用
格式: command > outputfile <<marker
data
marker
将执行command的输出放入到重定向的文件里面
# !/bin/bash
cat > $(date +%y%m%d).log << EOF
test string 1
test string 2
test string 3
EOF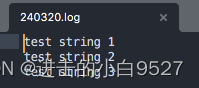
1.5 管道
格式: command1 | command2
将第一个命令产生的输出传给第二个命令
1.6 执行数学运算
在bash中将运算结果赋值给变量可以使用$[operation],但是bash shell只是支持整数运算,使用浮点数进行计算时就会报错syntax error: invalid arithmetic operator (error token is ".2+2")
# !/bin/bash
# 加法
var=$[1+2]
echo "这是加法:$var"
# 乘法
var1=$[1*2]
echo "这是乘法:$var1"
# 除法
var2=$[4/2]
echo "这是除法:$var2"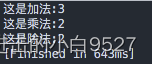
# 浮点数加法
var=$[1.2+2]
echo "这是加法:$var"
1.7 浮点数解决方案
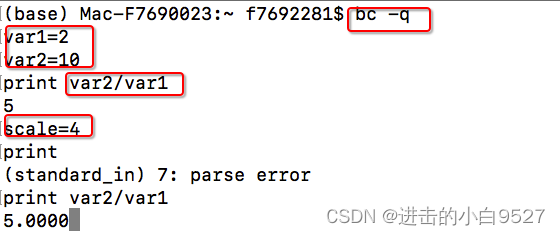
1.7.1 bc计算器
最常见的用法是使用内建的bash计算器bc.bash计算器实际上是一种编程语言,允许命令行中间输入浮点数表达式,然后解释并计算该表达式,最后返回结果.bash计算器可以识别以下内容:
1)数字(整数和浮点数)
2)变量(简单的变量和数组)
3)注释(#或是c语言的/**/开始的行
4)表达式
5)编程语句(if-then)
6)函数
支持识别浮点数,使用quit退出bc计算器.

浮点数运算是由内建变量scale来控制的,控制计算结果的小数位.并且bc计算器支持变量,可以使用print打印变量和数字.同时使用bc -q,可以跳过冗长的欢迎信息.
1.7.2 在脚本中使用bc计算器
可以使用命令替换的方式来执行bc命令,将输出结果赋值给变量
格式:
variable=$(echo "options;expression"|bc)
options表示要设置的变量,这个变量可以是多个,用;来分隔它们.expression定义了要执行的数学表达式.
# !/bin/bash
# bc计算器
res=$(echo "scale=4;var1=20;var2=10.0;var3=3.5;var1/var2+var3"|bc)
echo $res
expression表达式可以使用shell当中的变量,当然bc计算器里面的变量.仅是在bc中间起到效果.但是此时调用变量就要按照shell的语法规则行事,$变量名
# !/bin/bash
var1=20
var2=10.0
var3=3.5
# bc计算器
res=$(echo "scale=4;$var1/$var2+$var3"|bc)
echo $res 
如果存在大量的计算,一个命令行中间列出多个表达式容易让人感觉头晕.就可以使用内联输入重定向来解决这个问题.
格式:
variable=$(bc<<EOF
options
statements
expressions
EOF)
# !/bin/bash
# bc计算器之内联重定向
var1=20
var2=10.0
var3=3.5
res=$(bc<<EOF
var4=3.6
scale=4
a1=$var1/$var2
b1=$var3+var4
a1+b1
EOF)
echo "bc计算器输出结果为: $res"
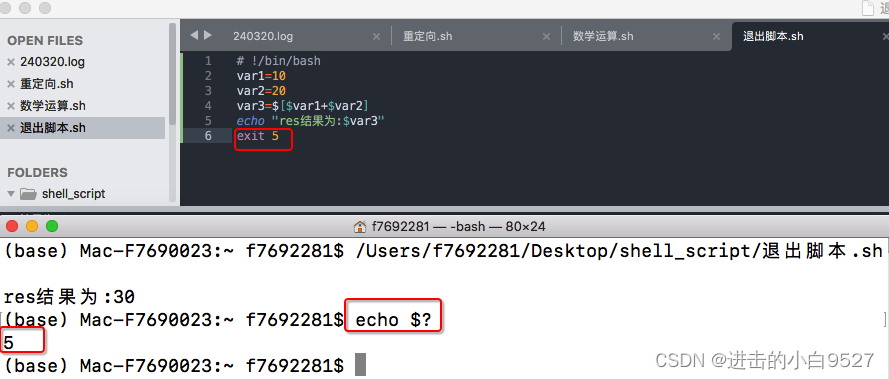
1.8 退出脚本
1.8.1 查看退出状态码
shell中每个命令都是用退出状态码来告诉shell自己已经运行完毕.退出状态码是0~255的整数值.命令结束时会传递给shell,并且可以获取到这个值在脚本中使用.$?中间存储着最后一个已执行命令的退出状态码.成功的命令,退出状态码是0,错误结束的命令,退出状态码是个整数.
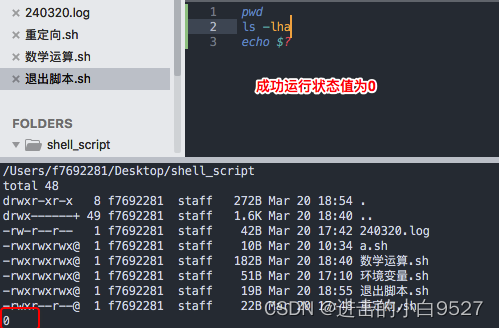
1.8.2 exit命令
exit命令允许脚本结束时指定一个退出状态码 ,退出状态码是在0~255之间,如果退出状态码超过这个范围,结果就是为值/256得到的余数.
1.9 实战
编写一个shell脚本计算两个日期之间的天数,允许用户以date命令能识别的任何形式来指定日期.
mac系统和linux系统的形式并不相同,使用date -d "2024-02-21"无法执行,使用下面形式进行替换.
# !/bin/bash
# 编写一个shell脚本计算两个日期之间的天数,允许用户以date命令能识别的任何形式来指定日期
date1="2024-02-21"
date2="2024-03-21"
time=$(date -j -f "%Y-%m-%d" "$date1" +%s)
time2=$(date -j -f "%Y-%m-%d" "$date2" +%s)
echo $time
echo $time2
time3=$[$time2-$time]
echo "两个时间差额的秒数: $time3"
day=$(echo "$time3/24/60/60"|bc)
echo $day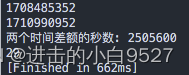
2.结构化命令
2.1 if-then语句
格式:
if command
then
commands
fi
格式2:
if command;then
commands
fi
# !/bin/bash
if pwd &> /dev/null;
thenecho "it worked"
fi2.2 /dev/null
if后面的command成功运行,退出状态码为0,就会执行then语句,在这里使用了&>/dev/null,
/dev/null是一个特殊的设备文件,它会丢弃所有写入它的数据,读取它会立即返回文件结束(EOF)
2.2.1 丢弃命令的标准输出:
command > /dev/null2.2.2 同时丢弃命令的标准输出和标准错误:
command &> /dev/null2.2.3 只丢弃命令的标准错误
command 2> /dev/null2.3 if-then-else语句
格式:
if command;then
comamnds
else
commands
fi
# !/bin/bash
if grep root /etc/passwd;thenecho root用户存在
elseecho root用户不存在
fi
2.4 ls使用选项
2.4.1 只显示目录不显示目录内容
ls -d2.4.2 文件长列表中不显示属主
ls -g2.4.3 文件长列表中不显示属组
ls -o2.5 elif形式
if command1;then
commands
elif command2;then
commands
fi
虽然两个条件都是满足的,但是只会执行第一个if.所以bash shell会依次执行if语句,只有第一个返回退出状态码为0的语句中的then部分会被执行.
# !/bin/bash
if grep root /etc/passwd;thenecho root用户存在
elif pwd;thenecho root用户不存在
fi
2.6 test命令
2.6.1 test命令基础
bash shell中可以使用test命令在if-then语句中测试不同的条件.如果test中列出的条件成立,那么test命令就会退出并返回退出状态码0.所以测试命令使用的仍是退出状态码作为判断条件.
如果不写test命令的condition部分,就会按照非0的退出状态码来执行.
格式:
if test condition;then
commands
fi
# !/bin/bash
my_var="abb"
if test $my_var;thenecho "var has content: $my_var"
elseecho "var don't have content"
fi![]()
# !/bin/bash
my_var="abb"
if test;thenecho "var has content: $my_var"
elseecho "var don't have content"
fi![]()
2.7 条件测试之[ condition ]
bash shell提供了另外一种条件测试方式,无需test,如下:
格式:
if [ condition ];then
commands
fi
方括号内部定义了测试条件.注意第一个方括号之后和第二个方括号之前必须留空格.
数值比较运算符
* `-eq`:等于
* `-ne`:不等于
* `-gt`:大于
* `-lt`:小于
* `-ge`:大于等于
* `-le`:小于等于test命令和测试条件可以判断3类条件
1)数值比较
2)字符串比较
3)文件比较
2.7.1 数值比较
数值比较时,只可以处理整数,如果是浮点数在条件测试下是无法正常工作的.
报错: binary operator expected
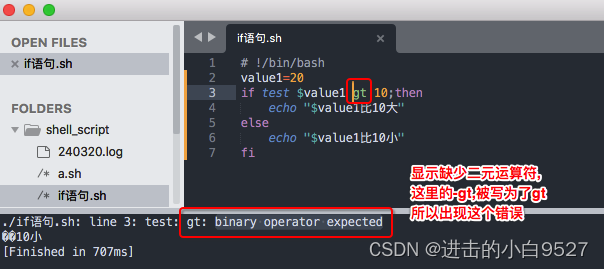
输出错误:$value1无法被正确解析,解析出来的结果是??
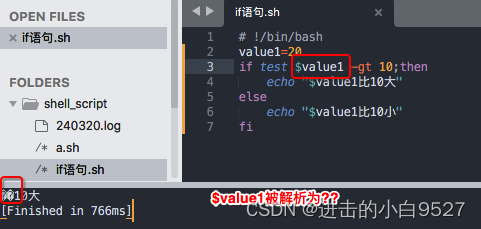
为了让变量名可以被正确的解析不受到其他内容的影响可以使用${变量名}

使用[ ]进行条件测试
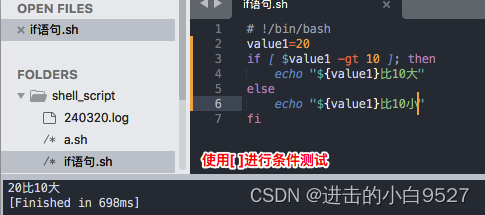
报错: integer expression expected
 2.7.2 字符串比较
2.7.2 字符串比较
字符串比较运算符
=:判断两个字符串是否相等。
!=:判断两个字符串是否不相等。
>:比较字符串大小
<:比较字符串大小
-z:判断字符串长度是否为0。
-n:判断字符串长度是否非0。特性:
1) 在比较字符串相等性时,会将所有的标点和大小写情况考虑在内.
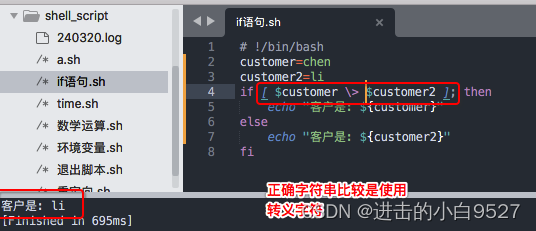
2) 使用条件测试的大于或是小于功能时,大小写必须转义,否则会被视为重定向符,字符串的值当做文件名

3)大于小于的顺序与sort命令的采用的不相同,比较时使用的是比较字符的Unicode的编码值.而sort命令使用的是系统的语言环境设置中定义的顺序.对于英语,语言环境设置了指定在排序中,小写字母在大写字母之前.
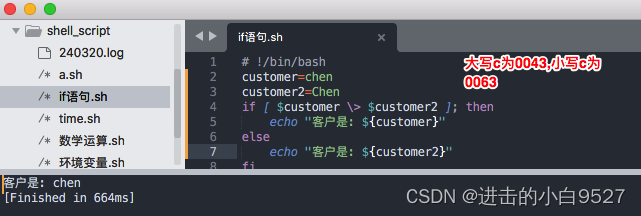
unicode 编码表
英文字母的Unicode编码从U+0041开始,到U+005A结束,分别对应大写英文字母A到Z;小写英文字母的Unicode编码从U+0061开始,到U+007A结束,分别对应小写英文字母a到z。以下是具体的编码表:大写英文字母(A-Z):A:U+0041
B:U+0042
C:U+0043
D:U+0044
E:U+0045
F:U+0046
G:U+0047
H:U+0048
I:U+0049
J:U+004A
K:U+004B
L:U+004C
M:U+004D
N:U+004E
O:U+004F
P:U+0050
Q:U+0051
R:U+0052
S:U+0053
T:U+0054
U:U+0055
V:U+0056
W:U+0057
X:U+0058
Y:U+0059
Z:U+005A
小写英文字母(a-z):a:U+0061
b:U+0062
c:U+0063
d:U+0064
e:U+0065
f:U+0066
g:U+0067
h:U+0068
i:U+0069
j:U+006A
k:U+006B
l:U+006C
m:U+006D
n:U+006E
o:U+006F
p:U+0070
q:U+0071
r:U+0072
s:U+0073
t:U+0074
u:U+0075
v:U+0076
w:U+0077
x:U+0078
y:U+0079
z:U+007A
这些编码是Unicode标准中固定的,用于全球范围内的字符表示和交换。如果你需要查询其他字符的Unicode编码,可以使用在线的Unicode编码查询工具或参考更完整的Unicode编码表。4) 空变量和未初始化的变量会对shell脚本测试造成灾难性的影响.所以如果不确定变量的内容,在进行数值或是字符串比较之前通过-n,-z来测试变量是否为空.使用-n不是符合预期的暂时忽略.
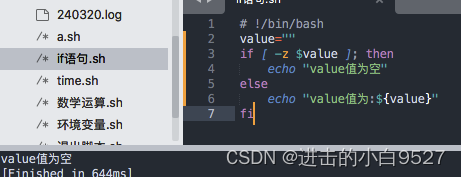
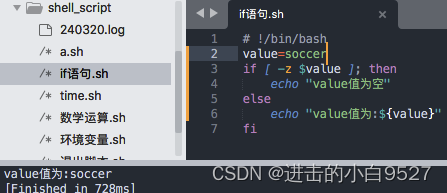
2.7.3 文件比较
-e FILE:检查文件是否存在。
-f FILE:检查文件是否是普通文件。
-d FILE:检查文件是否是目录。
-s FILE:检查文件是否存在且大小非零。
-r FILE:检查文件是否可读。
-w FILE:检查文件是否可写。
-x FILE:检查文件是否可执行。
FILE1 -nt FILE2:检查FILE1是否比FILE2新。
FILE1 -ot FILE2:检查FILE1是否比FILE2旧。
FILE1 -ef FILE2:检查FILE1和FILE2是否指向相同的设备和inode号。检查目录是否存在 -d file
但是双引号内的~,不会被解释为用户家目录,可以使用$HOME
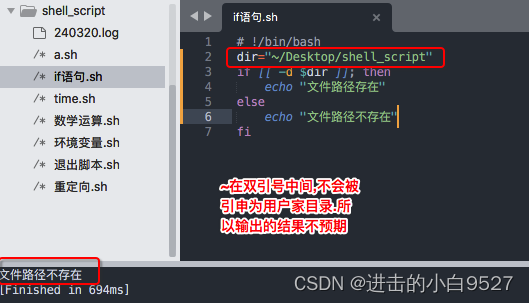
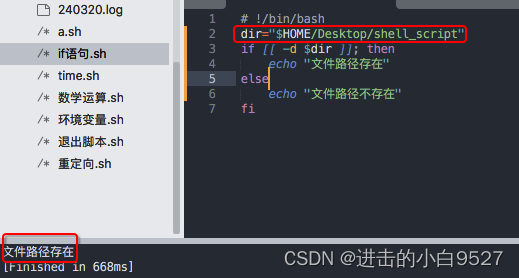
检查路径是否存在 -e path
测试条件是 -e,它会检查 $dir 指定的路径是否存在,无论是文件还是目录
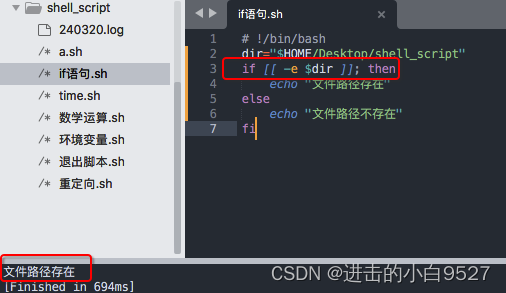
检查文件是否存在 -f file
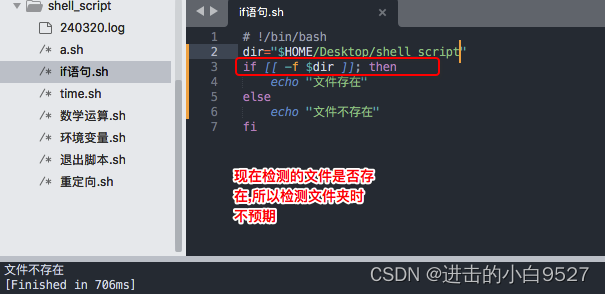
2.8 复合条件测试
&& 和 || 是用于控制命令执行流程的逻辑操作符,它们分别表示“与”和“或”的逻辑关系.
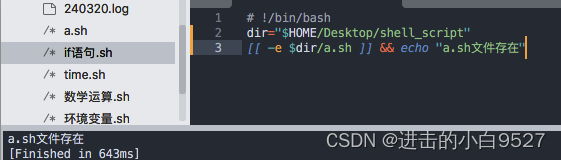
2.8.1 && (与)
&& 操作符用于连接两个命令,表示只有当第一个命令成功执行(返回值为0)时,才执行第二个命令。如果第一个命令执行失败(返回值非0),则不会执行第二个命令。
2.8.2 || (或)
|| 也用于连接两个命令,但与&&相反,它会在第一个命令失败(返回值非0)时执行第二个命令。 如果第一个命令执行成功就不会执行第二个命令
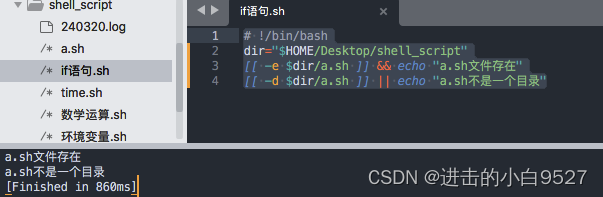
2.8.3 复合条件
格式:
[[ condition1 ]] && [[ condition2 ]]
[[ condition1 ]] || [[ condition2 ]]
1) 在使用&&运算符时,两个条件都必须满足,才会执行then后面的语句,因为只有此时的退出状态码才能是0.
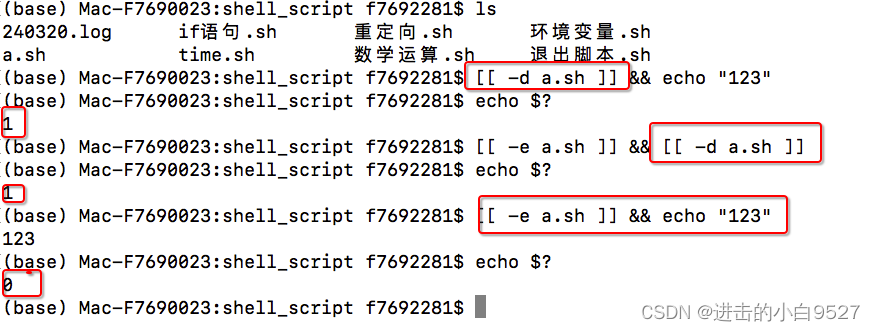
 2) 在使用||运算符时,任一条件为真那么then部分的命令就会执行.因为此时的退出状态码就是为0
2) 在使用||运算符时,任一条件为真那么then部分的命令就会执行.因为此时的退出状态码就是为0

2.9 if-then的高级特性
2.9.1 在子shell中执行命令的单括号()
格式:
(command)
在bash shell执行command之前,会先创建一个子shell,在其中执行命令
# !/bin/bash
echo $BASH_SUBSHELL
if (pwd;echo $BASH_SUBSHELL);thenecho "The subshell has operation"
elseecho "not success"
fi 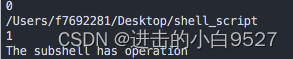
2.9.2 用于数学表达式的双括号(())
双括号命令允许在比较过程中使用高级数学表达式,test命令在进行比较时只能使用简单的算数操作.只要括号中的运算符、表达式符合C语言运算规则,都可以在 (( exp )) 中使用,甚至包括三目运算符,但是(())并不支持浮点数.
格式:
((expression))
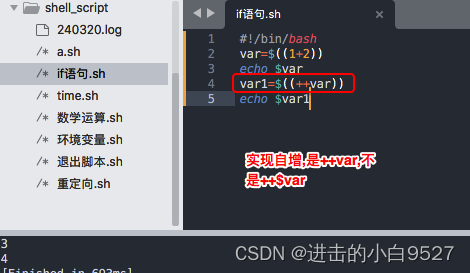
1) 变量自增/自减,
这就是++val自增再参与运算,和val++先运算再自增的区别,但是无论如何val的值其实都是发生了改变
| val++ | 后增 |
| val-- | 后减 |
| ++val | 先增 |
| --val | 先减 |


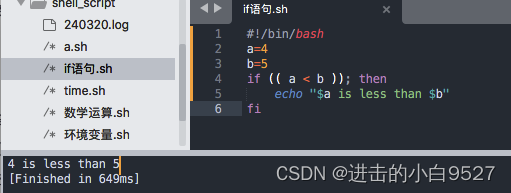
2) 条件判断
用于条件判断中,>和<不需要再次使用转义字符
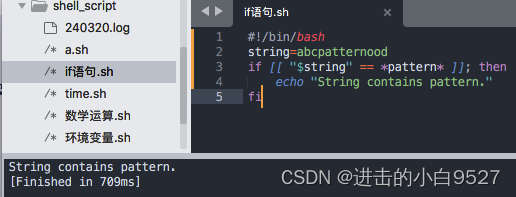
2.9.3 用于高级字符串处理的[[]]
格式:
[[ expression ]]
expression可以使用test命令中的标准字符串比较.除此之外,它还提供了模式匹配.可以使用通配符或是正则表达式来匹配字符串
当双括号中使用的是==或是!=时,运算符的右边被视为通配符,如果使用的是=~,运算符的右边被视为正则表达式
1) 通配符
2)正则表达式
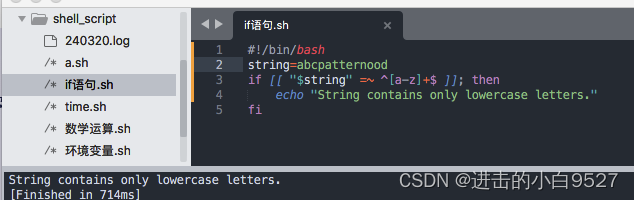
3)字符串提取
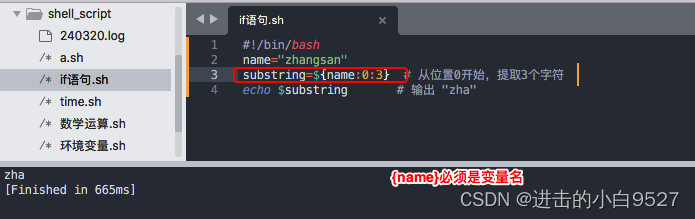
${string:position:length}
 2.10 case命令
2.10 case命令
case命令会采用列表格式来检查变量的多个值
case variable in
pattern1 | patter2) commands1;;
pattern3) commands2;;
*) default commands;;
esac
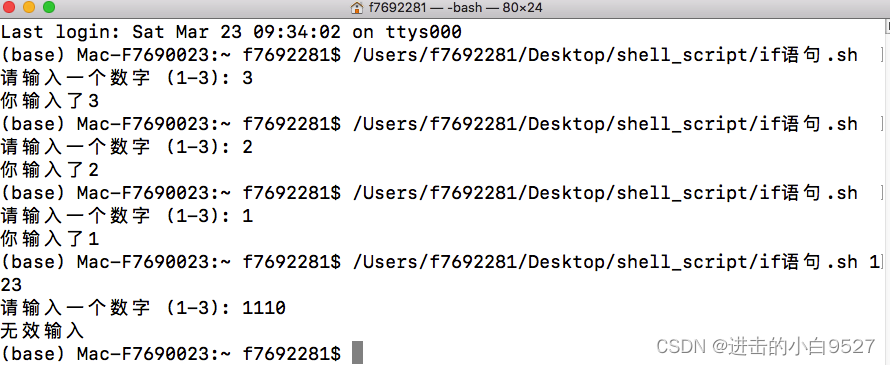
#!/bin/bashread -p "请输入一个数字 (1-3): " num case $num in 1) echo "你输入了1" ;; 2) echo "你输入了2" ;; 3) echo "你输入了3" ;; *) echo "无效输入" ;;
esac
3.更多结构化命令
3.1 for命令
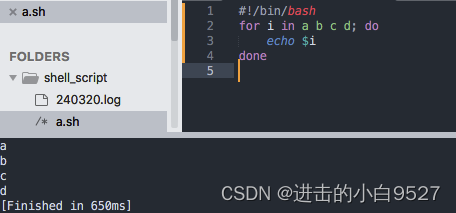
格式:
for var in list;do
commands
done
3.1.1 for命令特点
1) 需要提供一系列值作为list参数,每次遍历时会将list中的下一个值复制给$var变量.
2) 在最后一次迭代结束之后,$var的值依然有效,它会保持最后一次迭代时的值.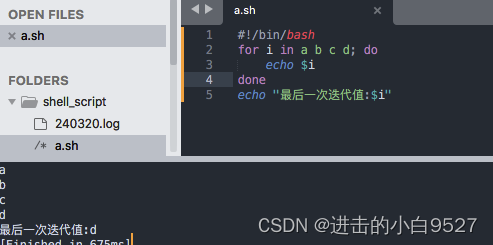
3) for命令默认是使用空格来划分列表中的值.如果值中包含空格,必须将其放入到双引号中,如果列表值中存在单引号,可以也使用单引号包裹,或是使用转义符号
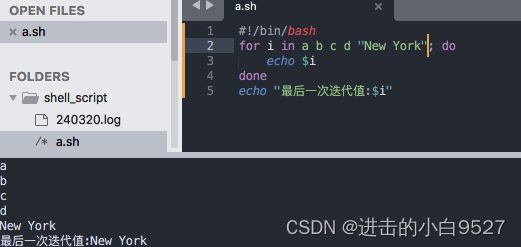
3.1.2 从数组中读取列表
#!/bin/bash # 定义数组,注意每个元素都用双引号括起来,以处理空格和特殊字符, 不然" New York"其实是没有办法处理的
list=("a" "b" "c" "d" "New York") # 向数组中进行尾部添加
list+=("e")# 获取list数组里面的所有变量 => a b c d New York e
echo "数组中所有元素:${list[@]}"# 迭代数组
for i in "${list[@]}"; do echo "$i"
done # 数组的长度
echo "数组长度:${#list[@]}"# 获取数组长度并计算最后一个元素的索引
last_index=$(( ${#list[@]} - 1 )) # 输出最后一次迭代的值,此为索引取值
echo "最后一次迭代值:${list[$last_index]}"echo "索引取值:${list[0]}"
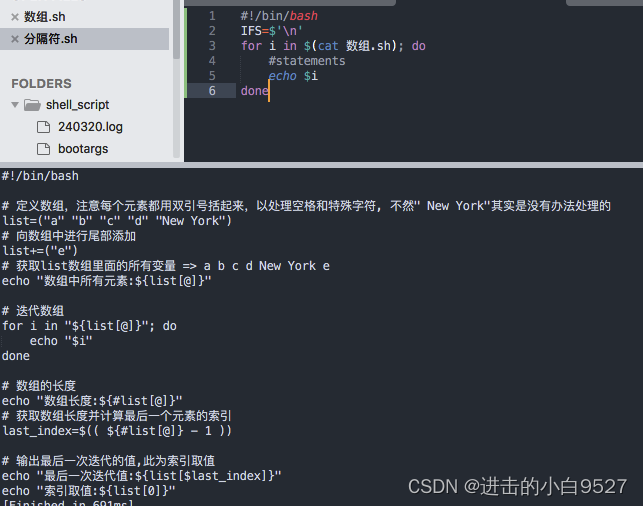
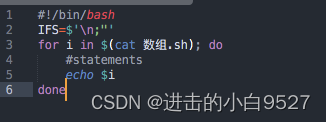
3.1.3 更改字段分隔符
IFS(internal field separator,内部字段分隔符),IFS环境变量定义了bash shell用作字段分隔符的一系列字符(空格,制表符,换行符),如果要指定多个IFS字符,只需要在赋值语句中将这些字符写在一起即可.
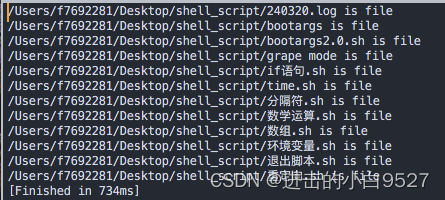
3.1.4 使用通配符读取目录
for命令可以用来自动遍历目录中的文件
#!/bin/bash
cd $(dirname $0)
dir=$(pwd)
for i in $dir/*; doif [[ -d $i ]];thenecho "$i is directory"elif [[ -f $i ]]; thenecho "$i is file"fi
done
3.2 C语言风格的for命令
格式
for ((variable assignment;condition;iteration process ))
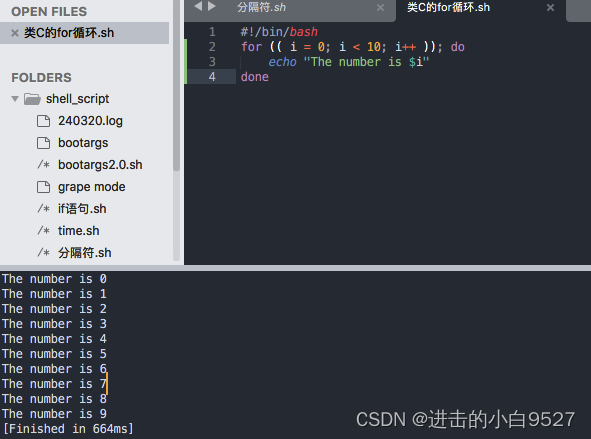
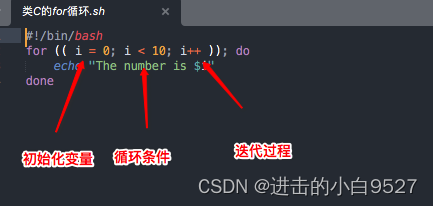
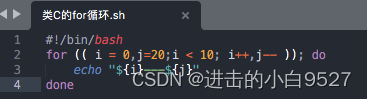
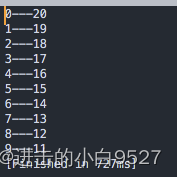
3.2.1 使用多个变量
迭代允许使用多个变量,循环会处理每个变量,可以给每个变量设置不同的迭代过程,但是迭代条件只能有一种.
3.2 while命令
格式
while test command;do
other commands
done
while命令在执行时,必须修改测试条件中使用到的变量,否则就会陷入死循环.while命令允许在while语句行中定义多个测试命令.只有最后一个测试命令的退出状态码会被用于决定是否结束循环.需要注意的是指定多个测试命令时,要把每个测试命令都单独放在一行.
#!/bin/bash
i=30
while echo "test-${i}"[[ $i -gt 20 ]]; do((i--))echo $i
done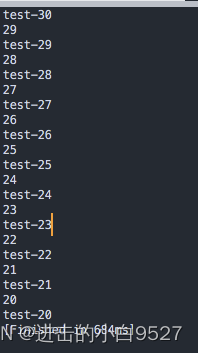
3.3 until 命令
格式:
until test commands;do
other commands
done
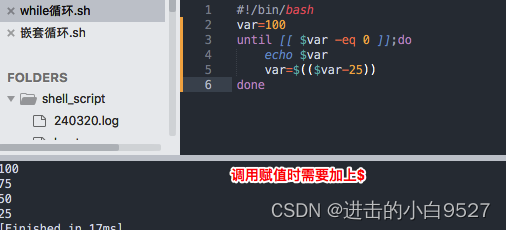
3.4 嵌套循环
until嵌套for循环
#!/bin/bash
var1=3
until [[ $var1 -eq 0 ]]; doecho "outerside:${var1}"var2=1while [[ var2 -lt 5 ]]; dovar3=$(echo "scale=4;$var1/$var2"|bc) # bc计算器自定义变量不需要$,引用外层变量需要$echo "inside:${var3}"((var2++))done((var1--))
done3.5 循环处理文件数据
需要注意的是分隔符是使用单引号而不是使用双引号.
#!/bin/bash
IFS_OLD=$IFS
IFS=$'\n'
for line in $(cat /etc/passwd);doecho "${line}"echo "----------line分隔符----------"IFS=$':'for item in ${line};doecho "${item}"done
done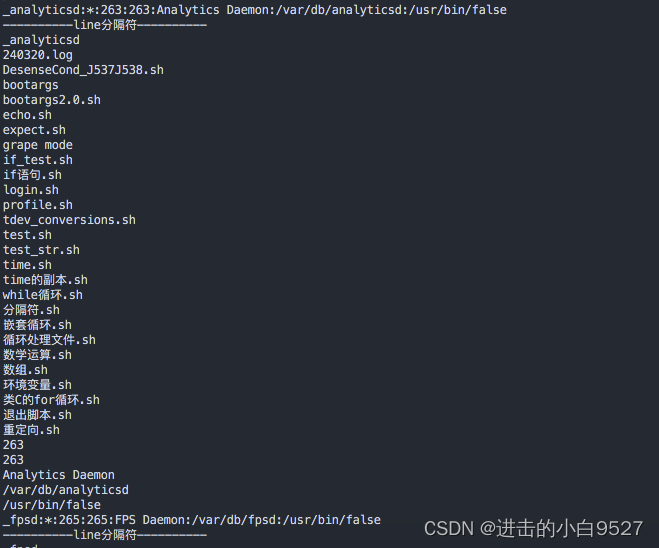
3.6 break 命令
break的使用方式和C语言的用法并无不同,在处理多层循环时,会自动结束你所在的最内层的循环.
但是它可以使用break n,用n指定要跳出的循环层级.
跳出内层循环
#!/bin/bash
for (( i = 0; i < 4; i++ )); doecho "outside loop ${i}"for (( j = 0; j < 5; j++ )); doif [[ $j -eq 3 ]];then breakfiecho "inside loop test ${j}"done
done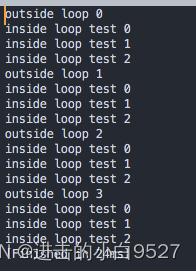
跳出多层循环
#!/bin/bash
for (( i = 0; i < 4; i++ )); doecho "outside loop ${i}"for (( j = 0; j < 5; j++ )); doif [[ $j -eq 3 ]];then break 2fiecho "inside loop test ${j}"done
done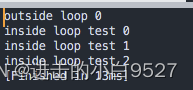
3.7 continue 命令
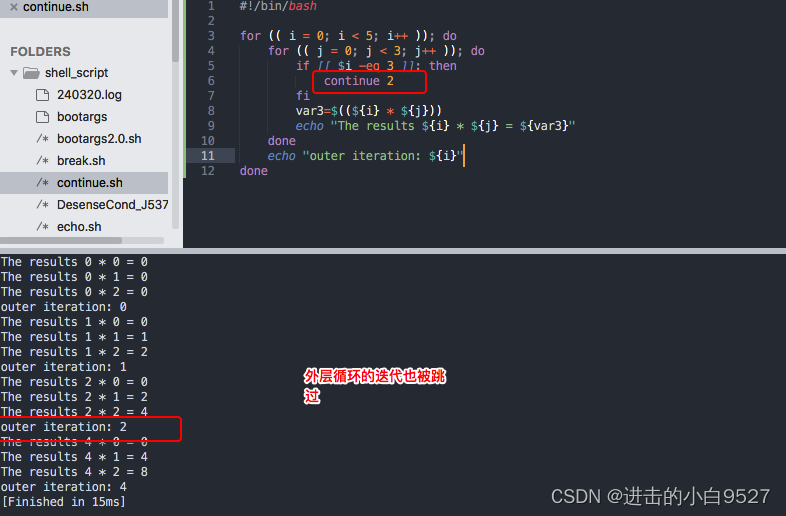
continue命令可以提前终止某次循环,但不会结束整个循环.同样可以使用continue n来指定要继续执行哪一级循环.
#!/bin/bashfor (( i = 0; i < 5; i++ )); dofor (( j = 0; j < 3; j++ )); doif [[ $i -eq 3 ]]; thencontinuefivar3=$((${i} * ${j}))echo "The results ${i} * ${j} = ${var3}"doneecho "outer iteration: ${i}"
done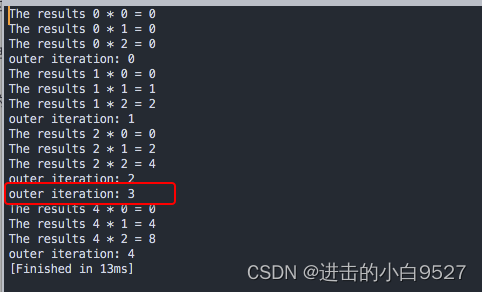
 3.8 处理循环的输出
3.8 处理循环的输出
在shell脚本中,可以对循环输出使用管道或是重定向.可以通过在done命令之后添加处理命令来实现
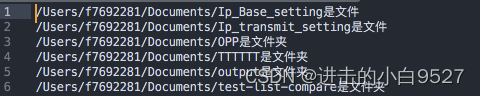
#!/bin/bash
for file in $HOME/Documents/*;doif [[ -d ${file} ]];thenecho "${file}是文件夹"elif [[ -f ${file} ]];thenecho "${file}是文件"fi
done>>123.txt
3.9 创建多个用户账户
将数据放到CSV里面文件格式为loginname,name;CSV文件是按照逗号进行分隔值的.
read命令用于从标准输入(通常是键盘)读取一行数据,并将其赋值给一个或多个变量。-r选项是read命令的一个选项,用于禁止反斜杠(\)的转义功能
#!/bin/bash
input="$HOME/Desktop/user.csv"while IFS=',' read -r userid name; doecho "${userid}-${name} "
done<"${input}"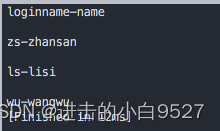
4.处理用户输入
很多时候,编写的脚本必须与使用者交互.bash shell提供了不同的方法来从用户处获取数据,包括命令行参数(添加在命令后的数据).命令行选项(可改变命令行为的单个字母)以及直接从键盘读取输入.
4.1 传递参数
4.1.1 读取参数
bash shell会将所有的命令行参数都指派给位置参数.$0为脚本名,$1对应第一个命令行参数,$2对应第二个命令行参数....被传递的参数可以数字/字符串,但是字符串之间如果有空格的话,将要使用引号引起来
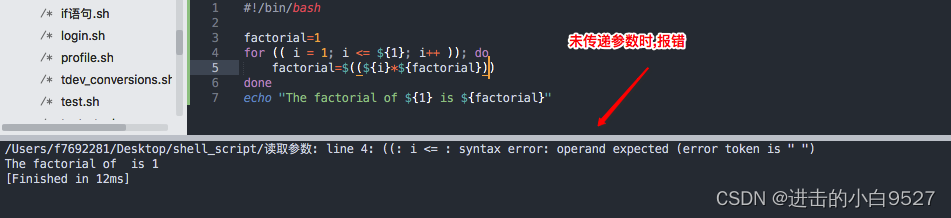
但是仍然存在一个隐患,就是如果运行脚本时,并没有传递参数,那么就会报错,所以在执行脚本前,一定要判断传递的参数是否为空.
#!/bin/bashfactorial=1
for (( i = 1; i <= ${1}; i++ )); do# 赋值时务必将$加上,使用$(())factorial=$((${i}*${factorial}))
done
echo "The factorial of ${1} is ${factorial}"![]()
#!/bin/bashif [[ -n $1 ]]; thenfactorial=1for (( i = 1; i <= ${1}; i++ )); dofactorial=$((${i}*${factorial}))doneecho "The factorial of ${1} is ${factorial}"
elseecho "你没有传递任何参数"
fi4.1.2 读取脚本名
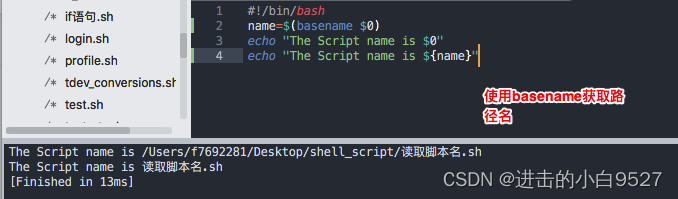
在脚本里面使用$0,使用bash命令来执行脚本时是OK的,但是切换到相对路径或是绝对路径时,获取的就是相对路径和绝对路径了.
所以可以使用basename命令,它可以返回不包含路径的脚本名.
4.2 特殊参数变量
4.2.1 参数统计
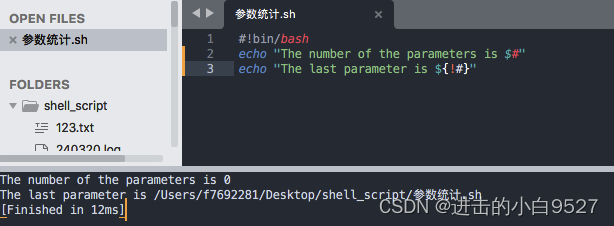
$#可以统计脚本运行时携带的命令行参数的个数
${!#}会返回最后一个命令行参数,即使$#的值为0,它也会返回命令行中的脚本名

4.2.2 获取所有数据
$*和$@他们包含了所有的命令行参数, $*和$@都可以输出所有命令行的参数.
$*会将所有的命令行参数组成一个整体,每个参数之间是以IFS变量值的第一个字符分割
$@会将参数视为一个字符串里面多个独立的单词.
#!/bin/bash
IFS=":"
echo "\$* is $*"
echo "\$@ is $@"
count=1
for i in "$*";doecho "\$* parameter #${count} = ${i}"((count++))
donecount=1
for i in "$@";doecho "\$@ parameter #${count} = ${i}"((count++))
done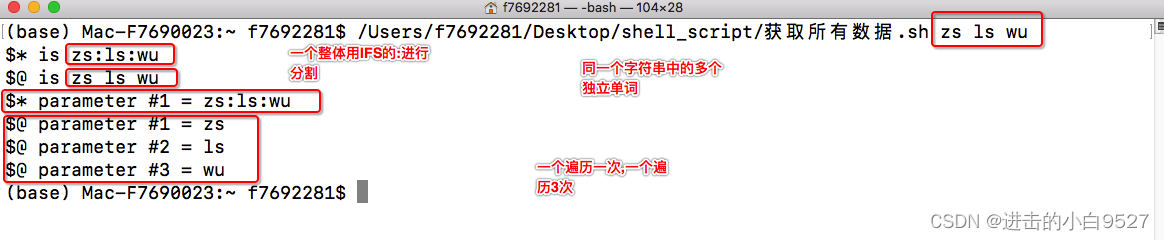
4.3 移动参数
bash shell里面使用shift命令来操作命令行参数.默认情况下会将每个位置的变量值都向左移动一个位置.也就是说$3的值会移入$2,$2的值移入$1,$1的值直接被删除,$0是脚本名,不会发生改变.这是遍历命令行参数的另外一种好方法,尤其是在不知道到底有多少参数的时候,只需要操作第一个位置变量,移动参数,然后继续处理该变量
可以使用shift + 参数,指明要移动的位置数,所以可以使用shif命令轻松跳过不需要的参数.
#!/bin/bash
count=1
while [[ -n $1 ]]; doecho "parameter #$count = $1"((count++))shift
done
4.4 处理选项
选项是在连字符(-)或是(--)之后出现的单个字母,能够改变命令的行为.
4.4.1 处理简单选项
在提取单个参数时,使用case语句来判断某个参数是否为选项.
#!/bin/bashwhile [[ -n $1 ]]; do # -n 是进行判断字符串长度是否非0case "$1" in-a ) echo "found -a option";;-b ) echo "found -b option";;-c ) echo "found -c option";;* ) echo "$1 is not an option";;esacshift
done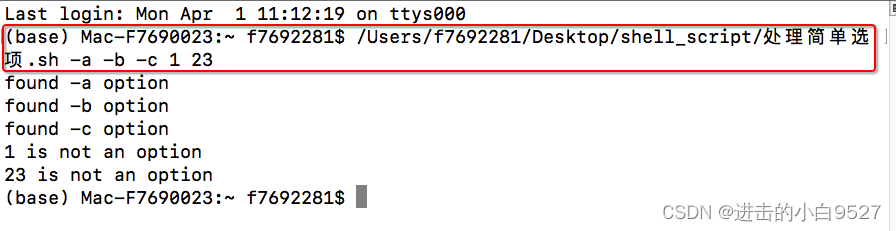
4.4.2 分离参数和选项
在linux中使用双连字符(--)表明选项部分的结束.
#!/bin/bashwhile [[ -n $1 ]]; docase "$1" in-a ) echo "found -a option";;-b ) echo "found -b option";;-c ) echo "found -c option";;-- ) shift break;;* ) echo "$1 is not an option";;esacshift
donecount=1
for i in $@; do # $@是多个独立,$*是单个整体echo "Paramter #${count}: $i" ((count++))
done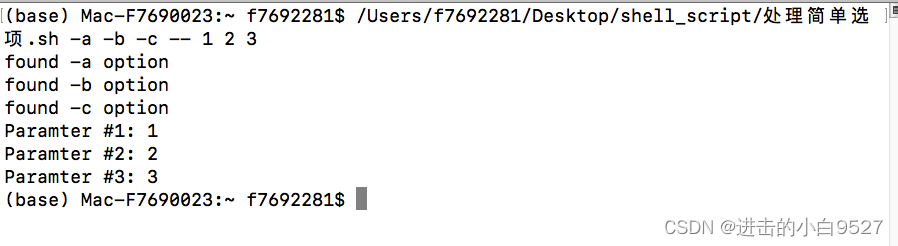
4.4.3 处理含值选项
当选项要求额外的参数时,脚本必须能够检测到并正确处理.
#!/bin/bashwhile [[ -n $1 ]]; docase "$1" in-a ) echo "found -a option";;-b ) param=$2echo "found -b option with Paramter value: $2"shift;;-c ) echo "found -c option";;-- ) shift break;;* ) echo "$1 is not an option";;esacshift
donecount=1
for i in $@; do # $@是多个独立,$*是单个整体echo "Paramter #${count}: $i" ((count++))
done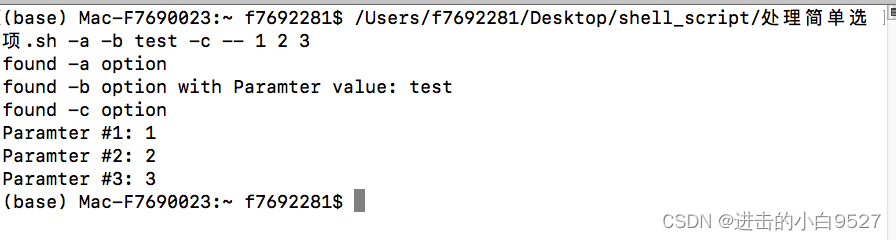
4.5 使用getopt命令
格式:
getopt optstring parameters
optstring中列出了要在脚本中用到的每个命令行选项字母.然后在每个需要参数值的选项字母后面加一个冒号.
当getopt运行时,会检查参数列表(-a -b BValue -cd test1 test2).它会将-cd分成两个单独的选项,并插入双连字符来分隔命令行中额外的参数.
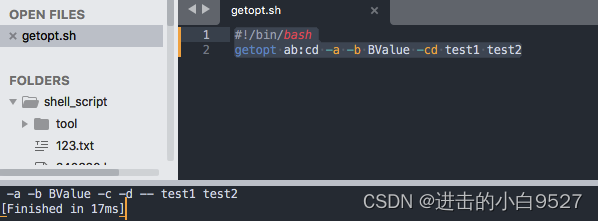
我们可以在脚本中使用getopt命令来格式化脚本所携带的任何命令行选项或参数.但是得通过set命令,set命令有一个选项是双连字符(--),可以将位置变量的值替换成为set命令所指定的值.
4.7 获取用户输入
4.7.1 基本读取
read命令会从标准输入键盘或另一个文件描述符中接受输入.获取输入后将数据存入变量,
也可以使用-p选项,直接指定提示符
如果指定多个变量,那么输入的每个数据值都会分配给指定的不同变量,如果变量的数量不够,剩下的数据都会分配给最后一个变量
如果不指定任何变量read命令会将接收到的所有数据存储在环境变量REPLY当中.
#!/bin/bash
echo -n "Enter your name:"
read name
echo "Hello $name, welcom to my script"
exit
#!/bin/bash
read -p "Please enter your age:" age
days=$((age*365))
echo "you are over $days days"
#!/bin/bash
read -p "Please enter your age sex:" age sex
echo "年龄:$age,性别:$sex"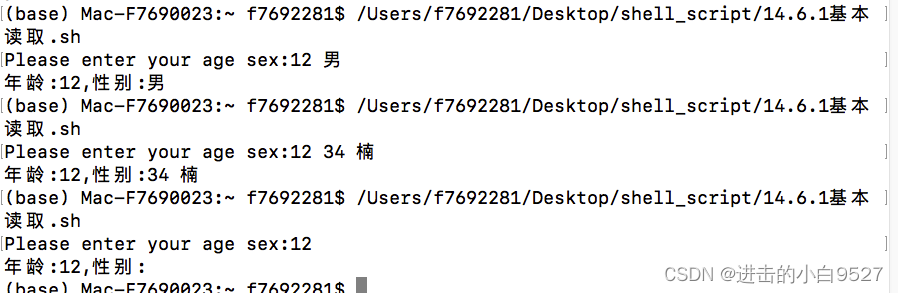
#!/bin/bash
read -p "Please enter your age sex:"
echo "年龄:$REPLY"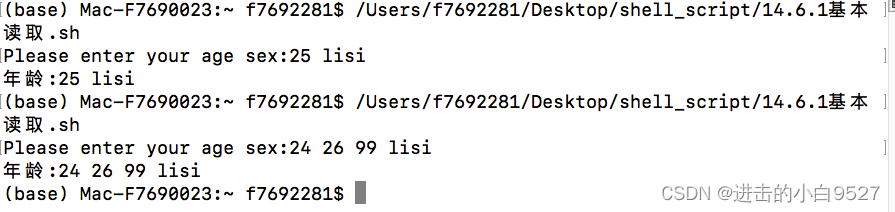
4.7.2 超时
使用read命令时,不输入内容脚本会一直等待用户输入.所以可以使用-t来指定一个定时器,会指定等待的秒数.如果计数器超时,则read命令会返回退出状态码.
read也可以使用-n来统计输入的字符数,如果字符数达到预设值时,就自动退出.
#!/bin/bash
if read -t 5 -p "enter your name:" name;thenecho "hello $name, welcom to my script"
elseecho "sorry, no longer wating for name"
fi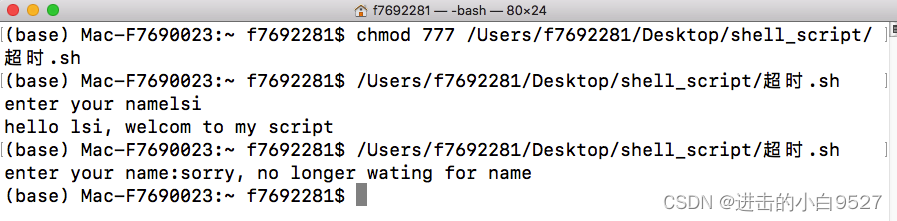
输入两个echo是为了换行
#!/bin/bash
read -n 1 -p "Do you want to continue [Y/N]?" answer
case $answer inY|y ) echoecho "OKey.Continue on ....";;N|n ) echoecho "OKey, goodby";;
esac
4.7.3 无显示读取
使用-s选项可以避免在read命令中输入的数据出现在屏幕上(其实数据还是会被显示,只不过read命令将文本颜色设置成为和背景色一样的)
4.7.4 从文件中读取
可以使用read命令读取文件.每次调用read命令都会从指定文件中读取一行文本.当文件中没有内容可读时,read命令会退出并返回非0退出状态码.但是麻烦的地方是将文件数据传给read命令.常见的方法是对文件使用cat命令,将结果通过管道传给含有read命令的while命令.
while循环会持续通过read命令处理文件中的各行,直到read命令以非0退出状态码退出 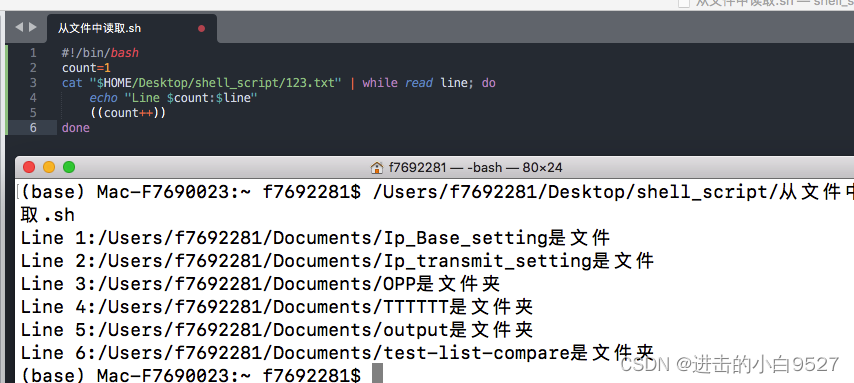
需要再看看!!!
5.呈现数据
5.1 标准文件描述符
linux系统会将每个对象当做文件来处理,包括输入和输出.Linux用文件描述符来标识每个文件对象.
-
STDIN (标准输入): 文件描述符为0。它通常用于从键盘读取输入,但在重定向或管道中也可以从其他来源读取。
-
STDOUT (标准输出): 文件描述符为1。它用于向屏幕输出信息,但也可以重定向到其他文件或设备。
-
STDERR (标准错误): 文件描述符为2。它用于输出错误信息,通常与STDOUT分开,以便在重定向或管道中单独处理
9.sed和gawk
9.1 sed编辑器
流编辑器是根据事先设计好的一组规则编辑数据流.这些命令要么从命令行中输入,要么保存在文本文件中.sed编辑器可以执行下列操作
1)从输入中读取一行数据
2)根据提供的编辑器命令匹配数据
3)按照命令修改数据流中的数据
4)将新的数据输出到STDOUT.
在流编辑器匹配并针对一行数据执行所有命令之后,会读取下一行数据并重复这个过程.在流编辑器处理完数据流中的所有行后,就结束运行.
由于命令是按顺序逐行执行的,因此sed编辑器只需对数据流处理一遍(one pass through)即可完成编辑操作.这使得sed编辑器要比交互式编辑器快得多,并可以快速完成对于数据的自动修改.
格式:
sed options script file
| -e commands | 在处理输入时,加入额外的sed命令 |
| -f file | 在处理输入时,将file中指定的命令添加到已有的命令中 |
| -n | 不产生命令输出,使用p(print)命令完成输出 |
script参数指定了应用于流数据中的单个命令.如果需要多个命令,要么使用-e选项在命令行中指定,要么使用-f选项在单独文件中指定.
9.1.1 在命令行中定义编辑器命令
在sed编辑器中使用了替换(s)命令.替换命令会用斜线间指定的第二个字符串替换第一个字符串.这里就是使用big test替换test
#!/bin/bash
echo "this is a test" | sed 's/test/big test/'![]()
9.1.2 在命令行中替换多行
#!/bin/bash
cat data1.txtecho
echo "----------------------------------------"sed 's/dog/cat/' data1.txt
9.1.3 在命令行中使用多个编辑器命令
可以使用-e选项,在sed命令行中执行多行命令 ,如果两个命令都应用于文件的每一行数据.命令之间必须以分号;分隔,在命令末尾和分号之间不能出现空格.
#!/bin/bash
cat data1.txtecho
echo "----------------------------------------"sed -e 's/brown/red/; s/dog/cat/' data1.txt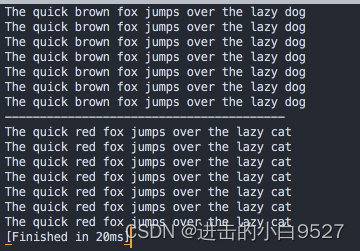
9.1.4 从文件中读取编辑器命令
如果有大量要执行sed命令,那么将其放入到单独文件里面.可以使用-f选项来指定文件.不用在每一条命令后面加分号,sed命令知道每一行都是单独的命令.当然为了避免sed编辑器脚本文件与bash shell文件混淆.可以使用.sed作为sed脚本文件的扩展名.
!/bin/bash
cat script1
echo
echo "---------------------------------"sed -f script1 data1.txt
9.2 gawk编辑器
gawk是unix中最初的awk的GNU版本.它提供了一种编程语言,而不仅仅是编辑器命令.在gwak编程语言中,可以实现下列操作.
1) 定义变量来保存数据
2) 使用算术和字符串运算符来处理数据
3)使用结构化编程概念为数据处理添加处理逻辑
4)提取文件中的数据将其重新排列组合,最后生成格式化报告.
gawk的报告生成能力多应用于从大文件中提取数据并将其格式化成可读性报告
9.2.1 命令格式
gawk options program file
| -F fs | 指定行中划分数据字段的字段分隔符 |
| -f file | 从指定文件中读取gawak脚本代码 |
| -v var=value | 定义gawk脚本中的变量及其默认值 |
| -L[keyword] | 指定gawk的兼容模式或是警告级别 |
9.2.2 从命令行读取gawk脚本
gawk脚本用一对花括号来定义.必须将脚本命令放到一对花括号之间

9.2.3 使用数据字段变量
gawk主要特性之一是处理文本文件中的数据.它会自动为每一行的各个数据元素分配一个变量.gawk会将下列变量分配给文本行中的数据字段.
文本行中的数据字段是通过字段分隔符来划分的.在读取一行文本时,gwak会用预先定义好的分隔符划分各个数据字段.默认情况下,字段分隔符是任意空白字符(比如空格或制表符)
1) $0代表整个文本行
2) $1代表文本行中的第一个数据字段
3) $2代表文本行中的第二个数据字段
4) $n代表文本行中的第n个数据字段
读取文本文件,只显示第一个数据字段的值
#!/bin/bash
cat data2
echo
echo "-----------------------"
awk '{print $1}' data2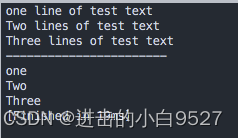
可以使用-F选项指定其他的字段分隔符
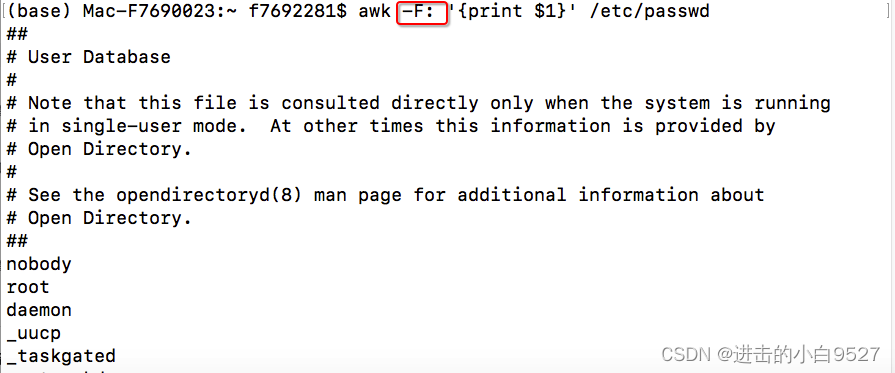
9.2.4 在脚本中使用多条命令
gawk编程语言允许将多条命令组成一个常规的脚本.要在命令行中指定的脚本中使用多条命令,只需要命令之间加入分号即可.
#!/bin/bash
echo "My name is Rich" | awk '{$4="Christine";print $0}'![]()
和sed编辑器一样,awk允许将脚本保存在文件中,可以使用-f指定引用的脚本
#!/bin/bash
cat script2
echo
echo "---------------------------"
awk -F: -f script2 /etc/passwd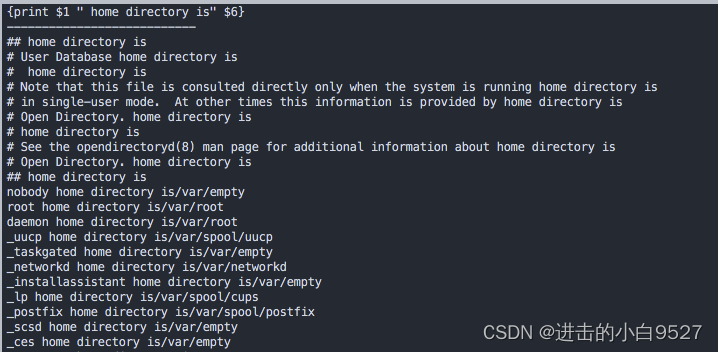
9.2.5 在处理数据前运行脚本
gawk还允许指定脚本何时运行.在默认情况下,gawk会从输入中读取一行文本,然后对这一行的数据执行脚本.但是有时候需要在处理数据前先运行脚本,所以需要用到BEGIN关键字
#!/bin/bashawk 'BEGIN {print "The data2 File Contents:"} {print $0}' data2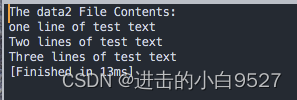
9.2.6 在处理数据后运行脚本
#!/bin/bashawk 'BEGIN {print "The data2 File Contents:"} {print $0} END {print "End of file"}' data2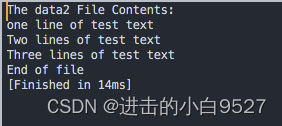
9.3 sed编辑器基础命令
9.3.1 更多的替换选项
9.3.1.1 替换标志
替换命令在替换多行文本中的文本时也可以正常工作,但在默认情况下它只能替换每行中出现的第一处匹配文本.要想替换每行中所有的匹配文本,必须使用替换标志.替换标志在替换命令字符串之后设置.
格式:
s/pattern/replacement/flag
有4种可用的替换标志
1)数字,指明新文本将替换行中的第几处匹配
2)g,指明新文本将替换行中所有的匹配
3)p,指明打印出替换后的行
4)w file,将替换的结果写入文件
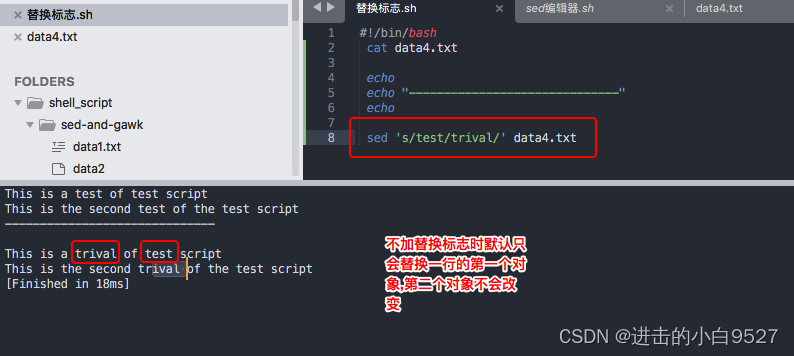
#!/bin/bashcat data4.txtechoecho "------------------------------"echosed 's/test/trival/' data4.txtechoecho "--------------替换第2个----------------"echosed 's/test/trival/2' data4.txtechoecho "--------------替换所有----------------"echosed 's/test/trival/g' data4.txt
替换标志p会打印出包含替换命令中指定匹配模式的文本行.该标志通常和sed的-n选项配合使用.-n会抑制sed编辑器的输出,而替换标志p会输出替换后的行.将两者配合使用就是只是输出被替换命令修改过的行.
替换标志w会产生同样的输出,不过会将输出保存到指定文件中.sed编辑器的正常输出会被保存在STDOUT中,只有那些包含匹配模式的行才会被保存在文件中
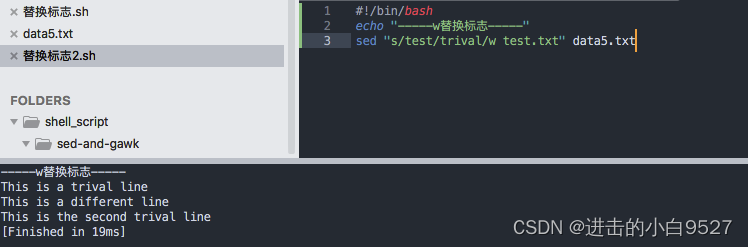
#!/bin/bash
echo "-----only p选项-----"
sed "s/test/trival/p" data5.txt
echo "-----n + p选项-----"
sed -n "s/test/trival/p" data5.txt
9.3.1.2 替代字符
在字符串中遇到一些不太方便在替换模式中使用的字符,linux常见的是正斜线(/),由于正斜线被用作替换命令的分隔符,因此它在匹配模式和替换文本出现时,必须使用反斜线(\)来转义.这很容易造成混乱和错误.所以在sed编辑器中允许选择其他字符作为替换命令的替代分隔符.
#!/bin/bashgrep /bin/bash /etc/passwd# 使用反斜线(\)进行转义
sed -n "s/\/bin\/bash/\/bin\/csh/p" /etc/passwd# 使用!用作替换命令的分隔符
sed -n "s!/bin/bash!/bin/csh!p" /etc/passwd

9.3.2 使用地址
在默认情况下,在sed编辑器中使用的命令会应用于所有的文本行.如果只想命令应用于特定的某一行或是某些行,则必须使用行寻址.
在sed编辑器中有两种形式的行寻址.
1)以数字形式表示的行区间
2)匹配行内文本的模式
格式:
[address] command
针对特定地址的多个命令分组,sed命令会将指定的各个命令应用于匹配指定地址的文本行
address {
command1
command2
command3
}
9.3.2.1 数字形式的寻址
在使用行寻址时,可以使用行号来引用文本流中的特定行.sed编辑器会将文本流中的第一行编号为1,第二行编号为2,以此类推.在命令中指定的行地址既可以单行号,也可以使用起始行号,逗号以及结尾行号指定的区间.行区间是顾前顾后的,如果要将某行到结尾行,可以使用$作为结尾符号.但是此时最好使用单引号,防止$被shell解释器解释
#!/bin/bash
cat data1.txt
echo
echo "---------------只是替换第2行-----------------"
sed "2s/dog/cat/" data1.txt
echo
echo "---------------修改2,3行区间(顾前顾后)-----------------"
sed "2,3s/dog/cat/" data1.txt
echo
echo "---------------修改2,结尾区间-----------------"
sed '2,$s/dog/cat/' data1.txt
9.3.2.2 使用文本过滤模式过滤
sed编辑器允许指定文本模式来过滤出命令所应用的行,sed编辑器在文本模式中引入了正则表达式来创建匹配效果更好的模式.
格式:
/pattern/command
#!/bin/bash
cat data2
echo
echo "-------------文本模式过滤--------------"
sed /^one/s/test/trival/ data2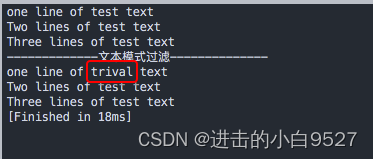
9.3.2.3 命令组
如果需要在单行中执行多条命令,可以使用{}将其组合在一起,sed编辑器会执行匹配地址中列出的所有命令.
#!/bin/bash
cat data1.txt
echo
echo "------------------命令组------------------"sed "2{s/fox/toad/s/dog/cat/
}" data1.txtecho
echo "------------------在命令行中使用多个编辑命令------------------"
sed -e "2s/fox/toad/;2s/dog/cat/" data1.txt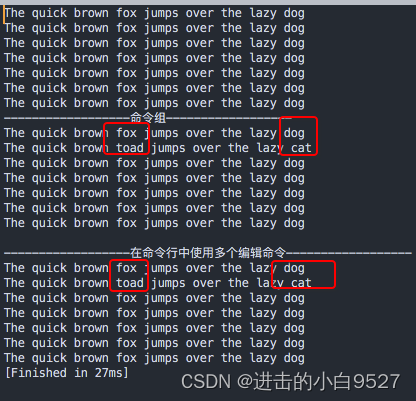
9.3.3 删除行
如果要删除文本流中特定的行,可以使用(d)命令.
删除命令会删除匹配指定模式的所有行,但是如果忘记加入寻址模式,流中的所有文本行都会被删除.当和指定地址一起使用时,删除命令可以发挥最大的效果.可以从数据流中删除特定的文本行,这些文本行可以通过行号指定,也可以通过特定的行区间指定
#!/bin/bash
cat data6.txt
echo
echo "------------行号---------------"
sed "3d" data6.txt
echo
echo "------------行区间---------------"
sed "1,3d" data6.txt
echo "------------行区间,\$结尾---------------"
sed '3,$d' data6.txt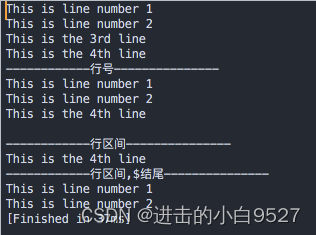
sed编辑器的模式匹配特性也适用于删除命令,sed编辑器会删掉与指定模式想匹配的文本行.也可以使用两个文本模式来删除某个区间内的行.但是注意,指定的第一个模式会启用行删除功能,第二个模式会关闭行删除功能.sed编辑器会删除两个指定行之间的所有行.
模式匹配:/pattern/command
#!/bin/bashcat data6.txt
echo
echo "------------删除行只模式匹配---------------"sed "/number/d" data6.txt
echo
echo "------------删除行只模式匹配删除区间---------------"sed "/number/,/3rd/d" data6.txt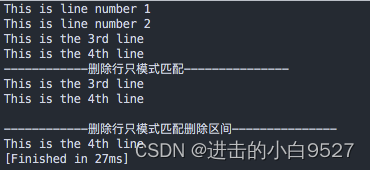
sed编辑器在数据流中匹配到开始模式,就会启用删除功能,这可能会导致意外的结果.
删除1,3之间的所有行之后,再次匹配到了This is line number 1 again; we want to keep it,因为没有找到停止模式,所以数据流中的剩余文本全部都被删除了.
#!/bin/bashcat data6.txt
echo
echo "-----------------意外的删除--------------------"sed "/1/,/3/d" data6.txt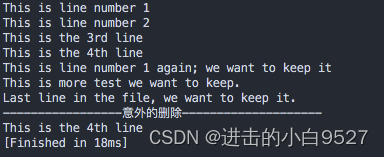
9.3.4 插入和附加文本
sed编辑器可以向数据流中插入和附加文本行.有两种操作:
插入(i)在行前增加一行
附加(a)命令在指定行后增加一行.
这两条命令不能在单个命令行中使用,必须指定是行插入还是附加到另一行
使用 sed 的 i\ 命令来在每一行之前插入文本时,你需要确保 \ 后面直接跟随换行符。由于命令行中不能直接包含换行符,你需要使用一些技巧来让 sed 命令正确解析
格式:
sed '[address] command\
new line'
$'\n' 是 Bash 中的 ANSI-C 风格的字符串,它允许你在字符串中包含一个真正的换行符。\\ 是为了转义 sed 命令中的反斜杠,因为 Bash 会首先解释 $'\n' 中的反斜杠。
#!/bin/bash
echo "-------------第一种方式--------------"
echo "Test line 2" | sed $'i\
Test line 1\\\n'echo "-------------第二种方式--------------"
echo "Test line 2" | sed $'1i\\\nTest line 1\\\n'echo "-------------尾部追加--------------"
echo "Test line 2" | sed $'1a\\\nTest line 1\\\n'
要向数据流内部插入或是附加数据.用这些命令时只能指定行地址,使用行号或是文本模式都可以,但是不能使用行区间
9.3.5 修改行
修改(c)命令允许修改数据流中整行文本的内容.它和插入和附加命令的工作机制一样,必须在sed命令中单独指定一行
#!/bin/bash
cat data7.txt
echo
echo "----------------修改行内容----------------"
sed $'2c\
This is a changed line of text\\\n' data7.txtecho
echo "----------------可以使用文本模式进行匹配----------------"sed $'/2/c\\\nThis is a changed line of text\\\n' data7.txt
9.3.6 转换命令
转换(y)命令是唯一可以处理单个字符的sed编辑器命令.转换命令会对inchars和outchars进行一对一映射.但是转换命令是一个全局命令,它会对文本中匹配到的所有指定字符进行转换,不会考虑字符出现的位置.
格式:
[address]y/inchars/outchars
#!/bin/bash
cat data9.txt
echo
echo "------转换命令-----------"
sed "y/123/789/" data9.txt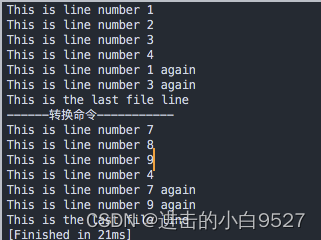
9.3.7 再探打印
1)打印(p)命令用打印文本行
和替换命令中的p标志类似,打印命令用于打印sed编辑器输出中的一行.常见的用法就是打印包含匹配文本模式的行.
#!/bin/bashecho "This is a test" | sed "p"
echo
echo "---------data7.txt--------"
cat data7.txt
echo
echo "---------打印包含匹配文本模式的行--------"
sed -n "/3/p" data7.txtecho
echo "---------打印数据流中部分行--------"
sed -n "2,3p" data7.txt
2)等号(=)命令用于打印行号
等号命令会打印文本行在数据流中的行号.行号由数据流中的换行符决定.数据流中每出现一个换行符,sed编辑器就会就会认为一行文本结束了.
#!/bin/bash
cat data1.txt
echo
echo "-----打印行号-----"
sed '=' data1.txtecho
echo "-----输出文本6-----"
cat data6.txt
echo
echo "-----查特定文本-----"
sed -n '/test/{
=
p
}' data6.txt
echo
echo "-----更常见用法-----"
awk '/test/ {print NR;print}' data6.txt
3)列出(l)命令用于列出行
列出命令可以打印数据流中的文本和不可打印字符.在显示不可打印字符的时候,要么在其八进制前加一个反斜线,要么使用标准的C语言命令规范
#!/bin/bash
cat data10.txt
echo
echo "----------列出行-----------------"sed -n 'l' data10.txt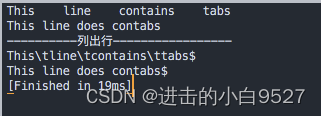
9.3.8 使用sed处理文件
9.3.8.1写入文件
使用w命令来向文件写入行,filename可以是相对路径也可以是绝对路径,不管是哪一种,运行sed编辑器的用户都必须具备文件的写权限。地址可以是sed支持的任意寻址方式,比如单个行号,文本模式,行区间或是文本模式区间。
格式:
[address]w filename

如果不想再STDOUT中显示文本行,可以使用sed的-n选项。如果要根据一些公用的文本值,从主文件中创建一份数据,则写入命令会非常方便

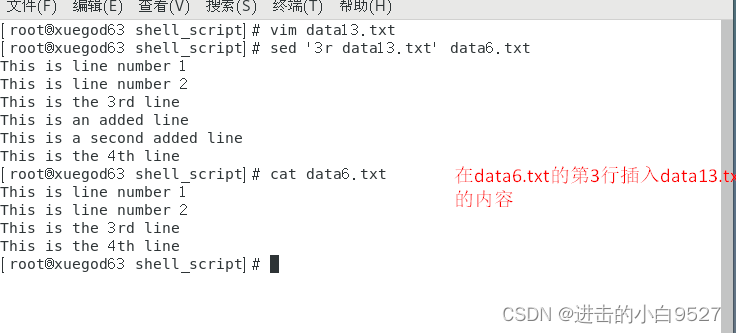
9.3.8.2 读文件
r命令允许将一条独立文件中的数据插入数据流
filename指定了数据文件的相对或是绝对路径。读取命令中无法使用地址区间,只能指定单个行号或是文本模式地址。sed编辑器会将文件的内容插入到指定地址之后。当然是将数据文件中的所有内容都插入数据流
读取命令还有一种很酷的用法,和删除命令一起使用,利用另一个文件中的数据来替换文本文件中的占位符
格式:
[address]r filename

 9.3.9 实战演练
9.3.9 实战演练
......
10.正则表达式
10.1正则表达式基础
10.1.1 定义
正则表达式是一种可供Linux工具过滤文本的自定义模板Linux工具会在读取数据时使用正则表达式对数据进行模式匹配.
10.1.2 正则表达式类型
正则表达式是由正则表达式引擎来实现的,这是一种底层软件,负责解释正则表达式并用这些模式进行文本匹配.最流行的正则表达式引擎有两种:
POSIX基础正则表达式(basic regular expression,BRE)
POSIX扩展正则表达式(extended regular expression,ERE)
10.2 定义BRE模式
10.2.1 普通文本
sed的格式:
s/pattern/replacement/flag
#!/bin/bash# 模式匹配到
echo "This is a test" | sed -n '/test/p'
# 模式匹配不到
echo "This is a test" | sed -n '/trival/p'
# 模式匹配到
echo "This is a test" | awk '/test/{print $0}'
# 模式匹配不到
echo "This is a test" | awk '/trival/{print $0}'
# 区分大小写
echo "This is a test" | awk '/this/{print $0}'
# 无须匹配整个单词.定义的文本在数据流中即可
echo "The books is expensive" | sed -n '/book/p'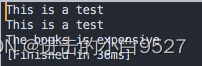
10.2.2 特殊字符
特殊字符是.*[]^${}\+?|(),不能在匹配普通文本的模式中单独使用这些字符.如果要将特殊字符视为普通字符,必须将字符进行转义\.
使用替代字符替换正斜线/,是在替换命令中可以实现,但是在正则表达式的模式匹配是会报错的

#!/bin/bash
echo "---------data2内容---------"
cat data2.txt
echo
echo "---------特殊字符\$---------"
sed -n '/\$/p' data2.txt
echo
echo "---------特殊字符\---------"
echo "\ is a special character" | sed -n '/\\/p'
echo
echo "---------/---------"
# 正斜线/不属于正则表达式的特殊字符,但是出现在sed或是awk正则表达式中就会报错
echo "hhh/buswu" | sed -n '/\//p'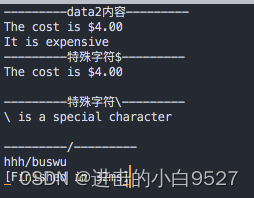
10.2.3 锚点字符
^锚定行首,当然此字符只有在正则表达式的开头才能锚定行首,放在其他地方就是普通字符.同时作为特殊字符,^后面还有其他字符的话就需要使用转义字符\
#!/bin/bash
cat data.txtecho
echo "-----锚定行首----------"
sed -n '/^this/p' data.txtecho
echo "-----^作为普通字符----------"
sed -n '/\^is/p' data.txt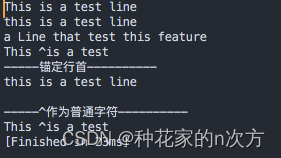
$锚定行尾